






在李纪为博士的毕业论文中提到,基于生成的闲聊机器人中,seq2seq是一种很常见的技术。例如,在法语-英语翻译中,预测的当前英语单词不仅取决于所有前面的已翻译的英语单词,还取决于原始的法语输入;另一个例子,对话中当前的response不仅取决于以往的response,还取决于消息的输入。其实,seq2seq最早被用于机器翻译,后来成功扩展到多种自然语言生成任务,如文本摘要和图像标题的生成。本文将介绍几种常见的seq2seq的模型原理,seq2seq的变形以及seq2seq用到的一些小trick。
我们使用x={x1,x2,…,xn}代表输入的语句,y={y1, y2, …, yn}代表输出的语句,yt代表当前输出词。在理解seq2seq的过程中,我们要牢记我们的目标是:
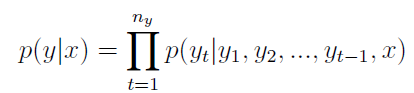 (1)
(1)
即输出的yt不仅依赖之前的输出{y1, y2, …, yt−1},还依赖输入语句x,模型再怎么变化都是在公式(1)的约束之下。
seq2seq最初模型
最早由bengio等人发表在computer science上的论文:Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation。对于RNN来说,x={x1,x2,…,xt}代表输入,在每个时间步t,RNN的隐藏状态
ht
由公式(1)更新:
其中,f代表一个非线性函数。这时 ht 就是一个rnn_size的隐含状态。然后需要通过一个矩阵W将其转成一个symbol_size的输出,并通过softmax函数将其转化为概率,然后筛选出概率最大的symbol为输出symbol。
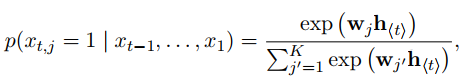 (3)
(3)
以上是rnn的基本原理,接下来介绍论文中的seq2seq模型:
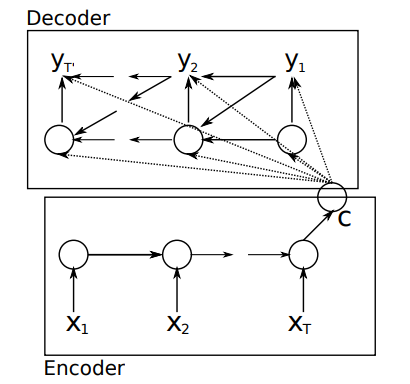
模型包括encoder和decoder两个部分。首先在encoder部分,将输入传到encoder部分,得到最后一个时间步长t的隐藏状态C,这就是RNNcell的基本功能。其次是decoder部分,从上述模型的箭头中可以看出,decoder的隐藏状态
ht
就由
ht−1
,
yt−1
和C三部分构成。即:
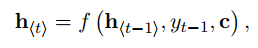 (4)
(4)
由此我们的到了decoder的隐藏状态,那么最后的输出
yt从图中也可以看得出来由三部分得到,
h_{t}
,
y_{t-1}$和C,即:
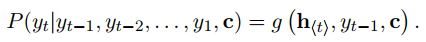 (5)
(5)到现在为止,我们就实现了我们的目标(1)。
seq2seq的改进模型
改进模型介绍2014年发表的论文Sequence to Sequence Learning with Neural Networks。模型图:
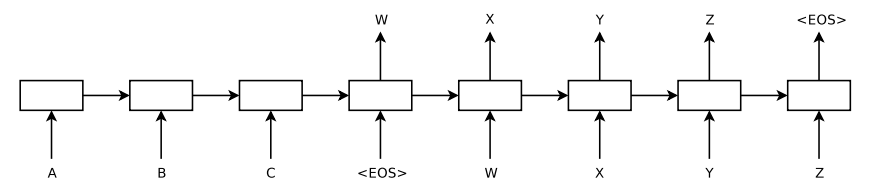
可以看到,该模型和第一个模型主要的区别在于从输入到输出有一条完整的流:ABC为encoder的输入,WXYZ为decoder的输入。将encoder最后得到的隐藏层的状态ht输入到decoder的第一个cell里,就不用像第一个模型一样,而一个decoder的cell都需要ht,因此从整体上看,从输入到输出像是一条“线性的数据流”。本文的论文也提出来,ABC翻译为XYZ,将encoder的input变为“CBA”效果更好。即A和X的距离更近了,更有利于seq2seq模型的交流。
具体来说,encoder的过程如下图。这和我们之前的encoder都一样。
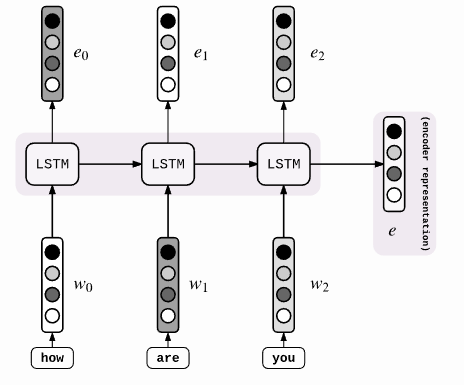
不同的是decoder的阶段:
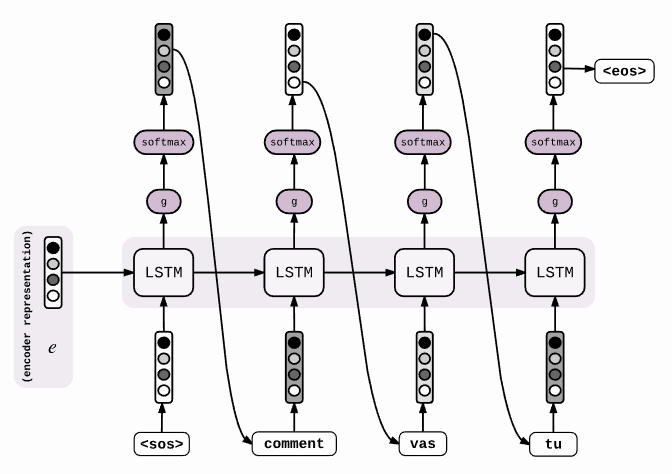
得到了encoder represention,即encoder的最后一个时间步长的隐层ht以后,输入到decoder的第一个cell里,然后通过一个激活函数和softmax层,得到候选的symbols,筛选出概率最大的symbol,然后作为下一个时间步长的输入,传到cell中。这样,我们就得到了我们的目标(1)。
seq2seq with attention
我们前面提到,距离decoder的第一个cell越近的输入单词,对decoder的影响越大。但这并不符合常理,这时就提出了attention机制,对于输出的每一个cell,都检测输入的sequence里每个单词的重要性,即论文NEURAL MACHINE TRANSLATION
BY JOINTLY LEARNING TO ALIGN AND TRANSLATE。attention在NMT基于seq2seq的改进模型再进行改进,原理如下:
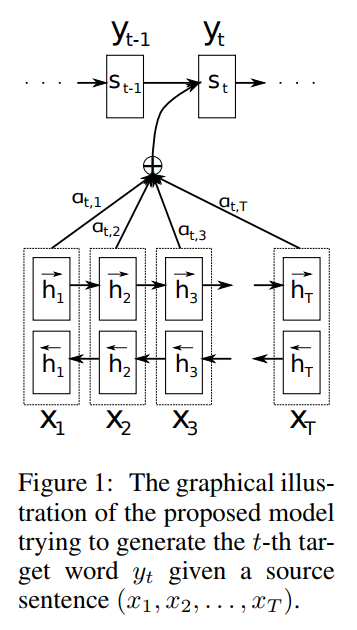
上图中,encoder和decoder都发生了变化。首先说encoder,使用了双向RNN,因为希望不仅能得到前向的词的顺序,还希望能够得到反向的词的顺序。使用
再说decoder。我们再来回顾一下我们的目标公式(1):
对于加入attention机制的seq2seq,每一个输出为公式(6)。即对于时间步i的输出yi,由时间步i的隐藏状态si,由attention计算得到的输入内容ci和上一个输出yi-1得到。
 (6)
(6)
其中si是对于时间步i的隐藏状态,由公式(7)计算。即对于时间步i的隐藏状态,由时间步i-1的隐藏状态si-1,由attention计算得到的输入内容ci和上一个输出yi-1得到。
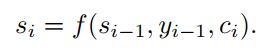 (7)
(7)
通过以上公式可以看出,加入attention的seq2seq比之前的seq2seq多了一个输入内容向量ci,那么这个ci是怎么得来的呢?和输入内容以及attention有什么关系呢?我们接着看公式(8):
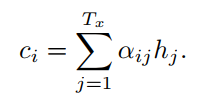 (8)
(8)
即,对于decoder的时间步长i的隐藏状态si,ci等于Tx个输入向量[1,Tx]与其权重 αij 相乘求和。这个权重 αij 由公式(9)得到:
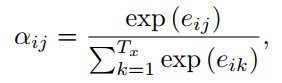 (9)
(9)
其中,eij由公式(10)得到:
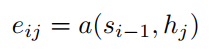 (10)
(10)
总结一下,对于时间步i的隐藏状态si,可以通过求时间步i-1的隐藏状态si-1、输入内容的编码向量ci和上一个输出yi-1得到。输入内容编码ci是新加入的内容,可以通过计算输入句子中每个单词的权重,然后加权求和得到ci。直观解释这个权重:对于decoder的si和encoder的hj的权重\alpha_{ij}$,就是上一个时间步长的隐藏状态si-1与encoder的hj通过非线性函数得到的。这样就把输入内容加入到解码的过程中,这和我们人类翻译的过程也是类似的,即对于当前输出的词,每一个输入给与的注意力是不一样的。
seq2seq with beam-search
在测试阶段,decoder的过程有两种主要的解码方式。第一种方法是贪婪解码,它将在上一个时间步预测的单词feed给下一步的输入,来预测本个时间步长的最有可能的单词。
但是,如果有一个cell解码错了词,那么错误便会一直累加。所以在工程上提出了beam-search的方法。即在decoder阶段,某个cell解码时不只是选出预测概率最大的symbol,而是选出k个概率最大的词(例如k = 5,我们称k=5为beam-size)。在下一个时间步长,对于这5个概率最大的词,可能就会有5V个symbols(V代表词表的大小)。但是,只保留这5V个symbols中最好的5个,然后不断的沿时间步长走下去。这样可以保证得到的decode的整体的结果最优。
参考文献:
(1)Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation
(2)Sequence to Sequence Learning with Neural Networks
(3)NEURAL MACHINE TRANSLATION
BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
(5) 从头实现一个深度学习对话系统–Seq-to-Seq模型详解
(6) seq2seq学习笔记

















 443
443





 到【灌水乐园】发言
到【灌水乐园】发言







