







第一次写博客,好激动啊,哈哈。之前看了许多东西但经常是当时花了好大功夫懂了,但过一阵子却又忘了。现在终于决定追随大牛们的脚步,试着把学到的东西总结出来,一方面梳理思路,另一方面也作为备忘。接触机器学习不久,很多东西理解的也不深,文章中难免会有不准确和疏漏的地方,在这里和大家交流,还望各位不吝赐教。
先从基础的开始写起吧。这是学习Andrew Ng的课程过程中的一些笔记,慢慢总结出来和大家交流。
(又加了一部分代价函数的概率解释——2016.4.10)
房价预测问题
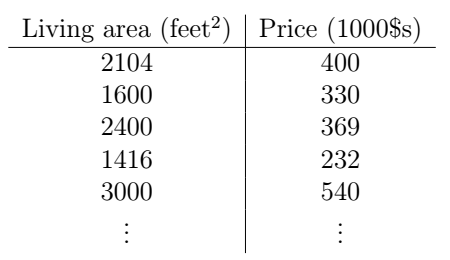
还是经典的预测房价的例子。假如我们收集了这么一组数据,描述了某一地区房子大小与价格的信息:
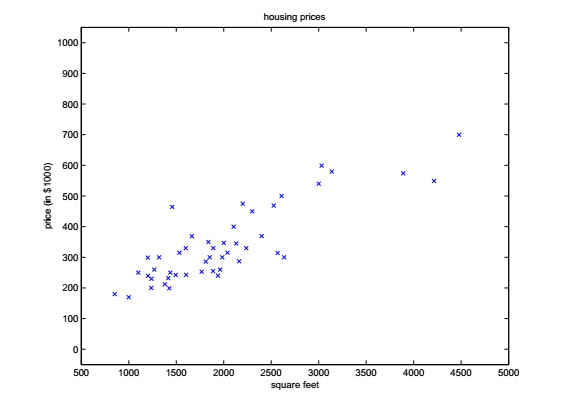
我们把它在坐标系中画出来,就是这个样子:
好了,现在问题来了,如今楼市价格突飞猛进,而你刚刚搜集了一些这个地区其它房子的面积信息,并想要以此预测一下它们的价格,你该怎么做?
为了表述清晰,我们先来约定一下符号表示。我们用
x(i)
表示输入变量(也就是房子的大小),这也被称作特征。
y(i)
表示输出,或者叫目标变量,也就是我们想要预测的变量(价格)。这么一对输入输出
(x(i),y(i))
被称作训练样本,我们用来学习预测方法的数据集包含了m个训练样本,它们被称作训练集。注意,这里的上标(i)与幂没有半毛钱关系,它只是代表了训练集中样本的编号或索引(index)。
我们用
X
和
Y
分别表示输入和输出的变量空间。在上面的房价预测问题中,输入和输出变量都是一维的,因此我们有
X=Y=R
。
好了,说完这些繁琐的符号,我们回到房价预测的问题上。我们来理一下思路,为了能够对一个新的样本进行预测,我们首先要从已有的样本中发现其中的“规律”,然后把这个“规律”应用到新的样本中,我们就可以得到一个预测。好了,我们的目标就很明确了,我们首先要根据训练集学习一个函数
h:X→Y
,它把输入变量从空间
X
映射到空间
Y
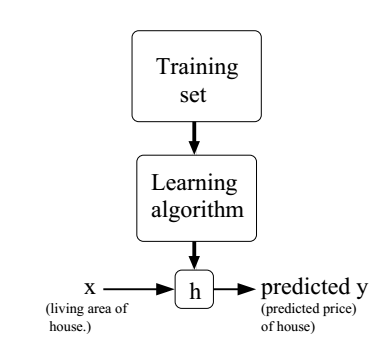
,得到输出变量。由于历史的原因,人们常常把函数h称为假设(hypothesis)。这里,我们的训练样本都是有标签的,也就是我们的训练样本包含了x和y,这被称为有监督学习。还有另外一种情况,训练样本是无标签的,也就是只包含x,被称为无监督学习。下面这张图说明了我们的预测流程:
如果我们要预测的变量是连续的,就像上面的房价问题,那么我们称这种学习问题为回归(regression)问题,如果是离散的(比如我们想要预测这是一个别墅还是公寓),那就被称为分类(classification)问题。
线性回归
实际上我们收集到的房子的特征可能不止一个,假设我们又收集到了有关房屋卧室数量的信息,显然这也会对房子的价格有影响。好,我们的表格就变成了这样:

现在,x就是一个二维的向量了,
x∈R2
. 现在,我们假设函数h是x的线性函数:
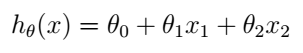
θi
是线性函数的参数(也叫权值),大家发现上式多了一项
θ0
,它是
x0
的系数,我们习惯上令
x0=1
,这被称为截距项。上式写为向量形式:
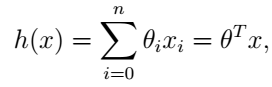
这里我们省略了h的下标
θ
。
梯度下降法
有了线性模型,我们现在的任务就是想办法求出h(x),也就是求出参数
θ
。我们对假设函数h(x)有什么要求呢?当然是希望它能尽量准确地预测出y的值。换句话说,对于训练集中的样本,我们希望选取的
θ
满足使h(x)的输出与y的距离尽可能地小。于是我们可以定义如下的代价函数:
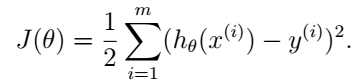
注意,这个代价函数是
θ
的函数,因为我们现在的任务是寻找
θ
,使预测误差最小。
那我们怎么才能找到使
J(θ)
最小的
θ
呢?想象一下,如果你站在一个山谷的某个坡上,你怎样才能最快到达山谷的谷底呢?当然是沿山坡下降最快的方向走下去。对!我们的最小化
J(θ)
的思路和这简直一毛一样!我们首先随机初始化
θ
的值,也就是我们先猜
θ
的值,对不对没关系,反正都是猜的,然后我们一步步地向使
J(θ)
最小的方向更新。使
J(θ)
最小的方向是什么?当然是它的梯度的反方向啊!好了,现在目标已经很明确了,我们要做的就是这样:
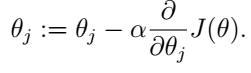
注意,这里的
:=
是赋值的意思。这个更新过程要对每一个
j
都过一遍。
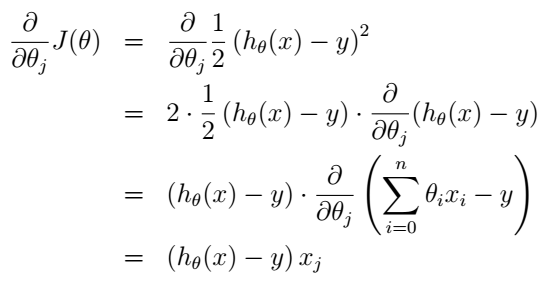
把式(5)代入式(4)我们就得到了更新规则:
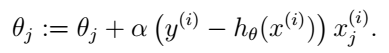
这个规则称为LMS更新规则(least mean squares),或者叫Widrow-Hoff learning rule。这个规则看起来也很直观:如果假设和样本偏差很小时我们就更新地幅度小一点,反之更新地幅度就大一点。
上面的LMS规则是针对单个样本的,我们有两种方法把它扩展到多个训练样本。一种是直接把单个样本代价函数的梯度换为多个样本代价函数的梯度。由于多个样本的代价函数是单个样本代价函数的线性加和,所以其梯度也是单个样本代价函数的梯度的加和,我们把它替换之后就得到如下算法:
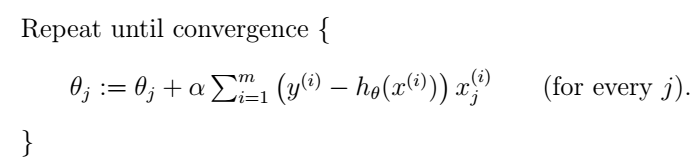
这种方法每次更新都遍历训练集中所有的样本,以它们的预测误差之和为依据更新,所以被称为batch gradient descent。其实梯度下降法是有可能收敛于一个局部最小值的,但是我们这里的线性回归问题只有一个全局最优解,不存在局部最小值,所以如果学习速率
α
不是过大,梯度下降法总是能够收敛。实际上,
J(θ)
是一个凸的平方函数。
上面讲的是batch gradient descent,还有另外一种梯度下降算法,效果也很好,叫做stochastic gradient descent (也叫incremental gradient descent),如下:
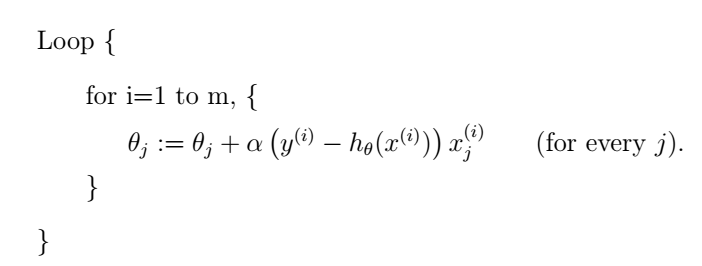
这种方法中我们同样也要遍历整个训练集,但和batch gradient descent不同的是,我们每次只使用单个训练样本来更新
α
,依次遍历训练集,而不是一次更新中考虑所有的样本。当训练样本数m很大时,batch gradient descent的每次更新都会是计算量很大的操作,而stochastic gradient descent 可以利用单个训练样本立即更新,因此stochastic gradient descent 通常是一个更快的方法。但stochastic gradient descent 也有一个缺点,那就是它的
α
可能不会收敛于最小值,而是在最小值附近振荡,但在实际中也都会得到一个足够好的近似。或者更通常的情况是,我们不用固定的学习速率,而是让它随着算法的运行逐渐减小到零,也就是在接近“谷底”的时候慢慢减小下降的“步幅”,换成用“小碎步”走,这样它就更容易收敛于全局最小值而不是围绕它振荡了。基于这些原因,特别是当训练集很大时,人们更加倾向于使用stochastic gradient descent。
代价函数的概率解释
现在我们来讨论一下为什么我们选择这样的代价函数J。线性回归的代价函数看起来非常直观:我们希望最小化预测值与训练集中实际值之差的平方。这里面其实也是可以从概率的角度来解释的。
我们首先假设目标变量和输入之间有这样的关系:
ϵ(i) 代表了没有被线性模型捕捉到的一些因素的影响,比如一些我们没有发现的影响房价的潜在特征啊,随机噪声啊(甚至是卖房子的人当时开不开心啊(哈哈,不要在意这些细节))。我们假设 ϵ(i) 是 独立同分布的(independently and identically distributed,IID),它们符合 高斯分布(Gaussian distribution)(也叫 正态分布, Normal distribution),写作 ϵ(i)∼N(0,σ2) ,其中 σ2 是方差,均值为零,它的密度函数为:
注意,这个 ϵ 代表了y和x的线性模型之间的差,它符合高斯分布,也就是说在线性模型(由参数 θ 控制)确定的情况下,给定 x(i) , y(i) 的条件分布是这样的:
我们把所有的样本x写入一个矩阵,用X表示,相应的,所有的y也用向量 y→ 表示,那 y→ 的条件概率就可以写为 p(y→|X;θ) 。当 θ 固定的时候,它可以看做是 y→ (或X)的函数,但我们同样也可以把 θ 当做变量,把它看做是 θ 的函数,这时它被称为 似然函数(likelihood function):
前面我们说过了, ϵ 是独立同分布的,那么所有样本的概率就是每个样本概率之积:
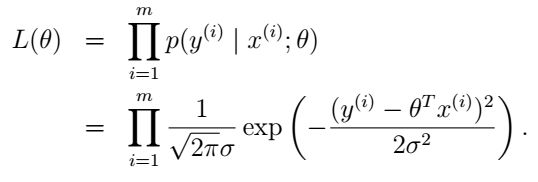
好,那我们怎么选择参数 θ 呢?这里,我们利用极大似然准则(the principal of maximum likelihood)。这是个什么准则呢,说的通俗一点,就是这一组样本既然被我们观测到了,那它就应该是概率最大的那个,不然没道理啊,如果你选的 θ 值使 L(θ) 的概率很小,你概率小怎么还让我观测到了呢?当然这只是一种通俗的解释,便于大家理解,想要更准确定义的同学可以自己补一下概率论相关的知识。所以我们下面的任务就是求出最大化 L(θ) 的 θ 。
这一串乘积看起来很难求最大值,那怎么办呢?如果是和的形式就好了,对吧。诶,好像的确有个操作可以把积变成和,对!就是对数函数log!log本身就是一个严格递增的函数,令L最大化的 θ 值。所以我们就用 对数似然(log likelihood)函数 ℓ(θ) 来代替L:
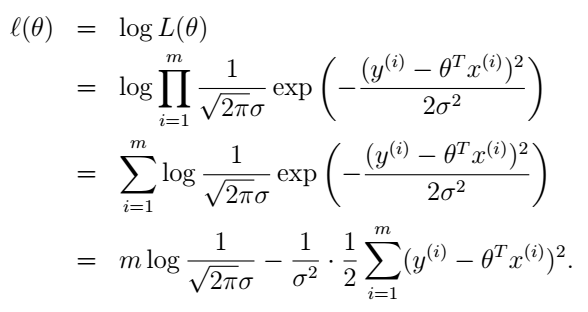
这个式子中其它值都是固定的,最大化 ℓ(θ) 就变成了最小化这一项:
看到了吧?这就是我们上面用到的 J(θ) !
所以我们的结论就是:在我们前面对数据的概率假设的条件下,最小平方回归其实就对应着寻找最大化似然函数的 θ 。
这里需要注意的一点是,我们最终并没有用到 σ2 ,实际上,即使 σ2 是未知的,我们依然可以得到同样的结果。
你可能要问了,这样的解释有什么用呢?我们一开始用直觉就猜出了同样的代价函数啊。但前面我们只讨论了线性回归模型,对于其它情况,我们并不是总能那么幸运,都可以猜出一个合适的代价函数的。比如后面我们要讨论的 逻辑回归问题,这种概率的方法将会帮助我们找到一个合适的代价函数。















 361
361

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









