









目录
PageRank
PageRank是google搜索引擎中根据网页之间相互的链接关系计算网页排名的技术。用来标识网页的等级或重要性的一种方法。其级别从1到10级,PR值越高说明该网页越受欢迎(越重要)。
互联网上的每一个网页除了包含文本、图片、视频等信息外,还包含了大量的链接关系,利用这些链接关系,能够发现某些重要的网页。
直观地看,某网页A链向网页B,则可以认为网页A觉得网页B有链接价值,是比较重要的网页。
某网页被指向的次数越多,则它的重要性越高;越是重要的网页,所链接的网页的重要性也越高。
PageRank 就是基于“从许多优质的网页链接过来的网页,必定还是优质网页”的回归关系,来判定所有网页的重要性。
把互联网上的各网页之间的链接关系看成一个有向图。对于任意网页Pi,它的PageRank值可表示为如下:其中Bi为所有链接到网页i的网页集合,Lj为网页j的对外链接数(出度)。


如图 11‑1,A的初始值是1,A有两个出链指向C和B,C、B分别分得A的1/2。
D的初始PR值为1,链出有三个, C、B和F分别分得D的0.3333C、B各有两个入链,此轮后,C、D的PR值为0.8333;F只有一个入链,F的PR值为0.3333。
初始所有网页都具有相同的PR值,经过多次循环传递,收敛后的网页的PR值为最终值进行排名。
案列1
针对以下连接关系
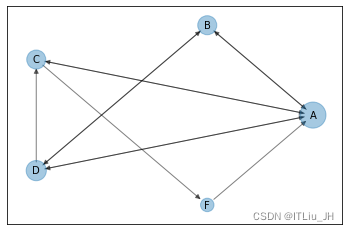
创建有向图
import networkx as nx
import numpy as np
# 创建有向图
G = nx.DiGraph()
# 有向图之间边的关系
edges = [("A", "B"), ("A", "C"), ("A", "D"), ("B", "A"),
("B", "D"), ("C", "A"), ("D", "B"), ("D", "C"),
("D","A"),("F","A"),("C","F")]
# 添加节点、边到有向图
for edge in edges:
G.add_edge(edge[0], edge[1])#计算PageRank
pagerank = nx.pagerank(G, alpha=1)
print("pagerank 值是:", pagerank)#设置边权重
ep=[[i,j,1] for i,j in edges]# 画网络图
def draw_graph(graph, layout='circular_layout'):
# 使用 Spring Layout 布局,类似中心放射状
if layout == 'circular_layout':
positions=nx.circular_layout(graph)
else:
positions=nx.spring_layout(graph)
# 设置网络图中的节点大小,大小与 pagerank 值相关,因为 pagerank 值很小所以需要 *2000
nodesize = [x['pagerank']*9000 for v,x in graph.nodes(data=True)]
# 设置网络图中的边长度
#edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)]
# 绘制节点
nx.draw(graph, positions, node_size=nodesize, alpha=0.4)
# 绘制边
nx.draw_networkx_edges(graph, positions, alpha=0.5)
# 绘制节点的 label
nx.draw_networkx_labels(graph, positions, font_size=10)nx.set_node_attributes(G, name = 'pagerank', values=pagerank)
nx.set_edge_attributes(G, name = 'weight', values=2)
G.edges(data=True)
draw_graph(G)
但PageRank会面临两个问题
•Rank leak (一般是因为存在网页没有出度)
•Rank sink (整个网页图中的一组紧密链接成环的网页如果没有外出的链接就产生Rank sink)
应用
- 学术论文的重要性排序
- 学术论文的作者的重要性排序
- 某作者引用了其它作者的文献,则该作者认为其它作者是“重要”的。
- 机场的重要性排名
- 城市的重要性排名
- 人物的重要性排名
- 关键词与句子的抽取(节点与边)
案例2
希拉里邮件门的人物关系(代码来源于网络)
import pandas as pd
import networkx as nx
import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt# 数据加载
emails = pd.read_csv("d:/datasets/PageRank/input/Emails.csv")
# 读取别名文件
file = pd.read_csv("d:/datasets/PageRank/input/Aliases.csv")
aliases = {}
for index, row in file.iterrows():
aliases[row['Alias']] = row['PersonId']
# 读取人名文件
file = pd.read_csv("d:/datasets/PageRank/input/Persons.csv")
persons = {}
for index, row in file.iterrows():
persons[row['Id']] = row['Name']# 画网络图
def show_graph(graph, layout='spring_layout'):
# 缺省Spring Layout 布局,星型
# circular_layout 布局,环型
if layout == 'circular_layout':
positions=nx.circular_layout(graph)
else:
positions=nx.spring_layout(graph)
# 设置网络图中的节点大小,大小与 pagerank 值相关,考虑此处 pagerank 值很小所以 *20000,根据实 际情况调整。
nodesize = [x['pagerank']*20000 for v,x in graph.nodes(data=True)]
# 设置网络图中的边长度
edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)]
# 绘制节点
nx.draw_networkx_nodes(graph, positions, node_size=nodesize, alpha=0.4)
# 绘制边
nx.draw_networkx_edges(graph, positions, alpha=0.5)
# 绘制节点的 label
nx.draw_networkx_labels(graph, positions, font_size=10)
# 针对别名进行转换
def unify_name(name):
# 姓名统一小写
name = str(name).lower()
# 去掉, 和 @后面的内容
name = name.replace(",","").split("@")[0]
# 别名转换
if name in aliases.keys():
return persons[aliases[name]]
return name# 将寄件人和收件人的姓名进行规范化
emails.MetadataFrom = emails.MetadataFrom.apply(unify_name)
emails.MetadataTo = emails.MetadataTo.apply(unify_name)
# 设置边的权重等于发邮件的次数
edges_weights_temp = defaultdict(list)
for row in zip(emails.MetadataFrom, emails.MetadataTo, emails.RawText):
temp = (row[0], row[1])
if temp not in edges_weights_temp:
edges_weights_temp[temp] = 1
else:
edges_weights_temp[temp] = edges_weights_temp[temp] + 1
# 转化格式 (from, to), weight => from, to, weight
edges_weights = [(key[0], key[1], val) for key, val in edges_weights_temp.items()]
# 创建一个有向图
graph = nx.DiGraph()
# 设置有向图中的路径及权重 (from, to, weight)
graph.add_weighted_edges_from(edges_weights)
# 计算每个节点(人)的 PR 值,并作为节点的 pagerank 属性
pagerank = nx.pagerank(graph)
# 将 pagerank 数值作为节点的属性
nx.set_node_attributes(graph, name = 'pagerank', values=pagerank)
# 画网络图
show_graph(graph)
#将完整的图谱进行精简
# 设置 PR 值的阈值,筛选大于阈值的重要核心节点
pagerank_threshold = 0.005
# 复制一份计算好的网络图
small_graph = graph.copy()
# 剪掉 PR 值小于 pagerank_threshold 的节点
for n, p_rank in graph.nodes(data=True):
if p_rank['pagerank'] < pagerank_threshold:
small_graph.remove_node(n)
# 画网络图, 采用 circular_layout 布局让筛选出来的点组成一个圆
show_graph(small_graph) #, 'circular_layout')
show_graph(small_graph, 'circular_layout')
















 4375
4375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











