










 本文介绍了循环神经网络(RNN)及其特殊类型LSTM在处理时间序列数据,如语言模型和序列预测问题中的作用。LSTM通过其特殊的结构解决了RNN的长期依赖问题,能够有效地学习和保留长期信息。文章以北京空气质量数据为例,展示了如何使用LSTM进行PM2.5浓度的预测,包括数据预处理、模型构建、训练和评估。
本文介绍了循环神经网络(RNN)及其特殊类型LSTM在处理时间序列数据,如语言模型和序列预测问题中的作用。LSTM通过其特殊的结构解决了RNN的长期依赖问题,能够有效地学习和保留长期信息。文章以北京空气质量数据为例,展示了如何使用LSTM进行PM2.5浓度的预测,包括数据预处理、模型构建、训练和评估。
目录
前言
传统的前馈神经可以比较好的处理回归、分类问题,CNN可以很好的处理图像数据,这些数据处理方法都只考虑当前时刻(样本)的特征。而时间序列数据、语音识别、语言建模,翻译等问题,不仅与当前时刻相关还与前n个时刻相关。
RNN循环神经网络
其中为t时刻的输入,
为t时刻的输出,循环使得信息一步步向下一时刻传递。

Recurrent Neural Networks have loops.
RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。如果将这个循环展开:
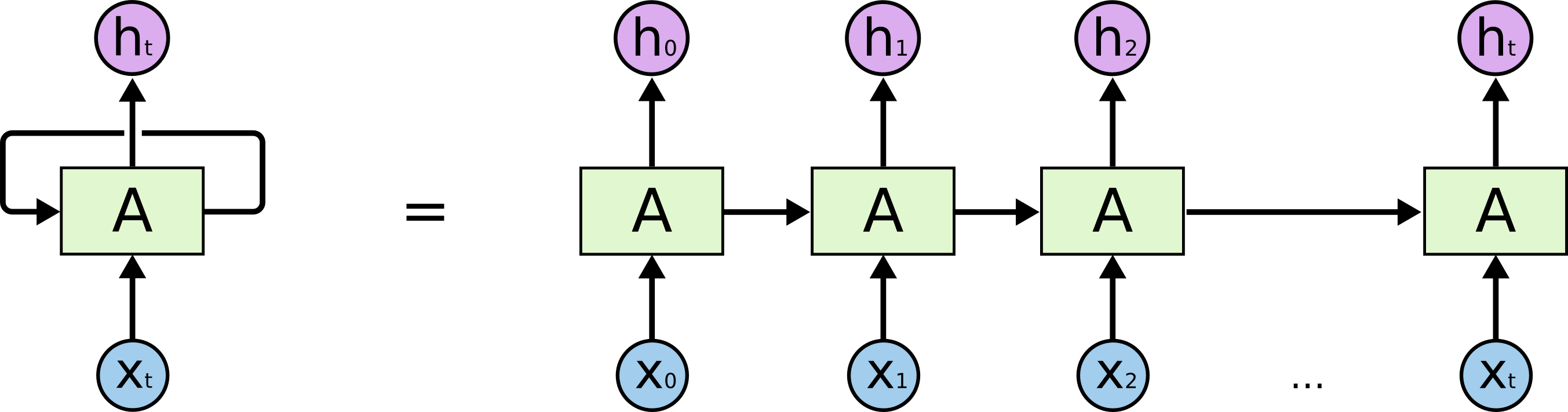
An unrolled recurrent neural network.
RNN链式的结构,揭示了 RNN 本质上是与序列数据相关的。RNN是处理这类数据最好的神经网络架构。
RNN 的关键点之一就是可以接收先前的信息用到当前的时刻。
有时候,我们仅仅需要知道先前的很少几个时刻的信息就可以确定当前的输出。
例如,我们有一个语言模型用来基于先前的词来预测当前词。如果我们试着推测 “the clouds are in the ?” 最后的词,我们不需要任何其他的上下文 (仅这个句子就够)—— 这个词很显然就应该是 sky。在这样的场景中,相关的信息和预测的词位置之间的间隔是非常小的
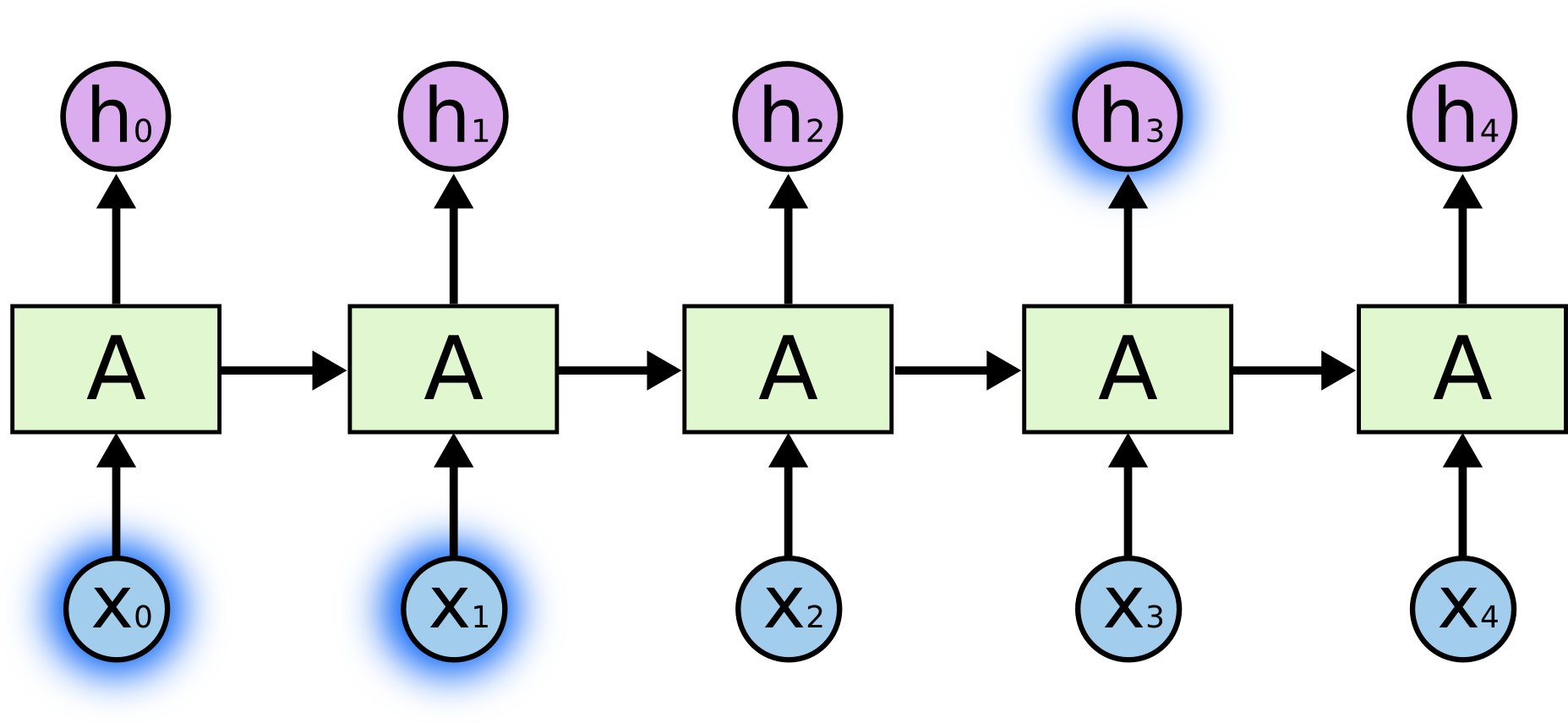
但是同样会有一些更加复杂的场景。假设我们试着去预测“I grew up in France... I speak fluent ?”最后的词。当前的信息建议下一个词可能是一种语言的名字,但是如果我们需要弄清楚是什么语言,我们是需要先前提到的离当前位置很远的 France 的上下文的。这说明相关信息和当前预测位置之间的间隔就肯定变得相当的大。
不幸的是,在这个间隔不断增大时,基本的RNN 会丧失学习到连接如此远的信息的能力。
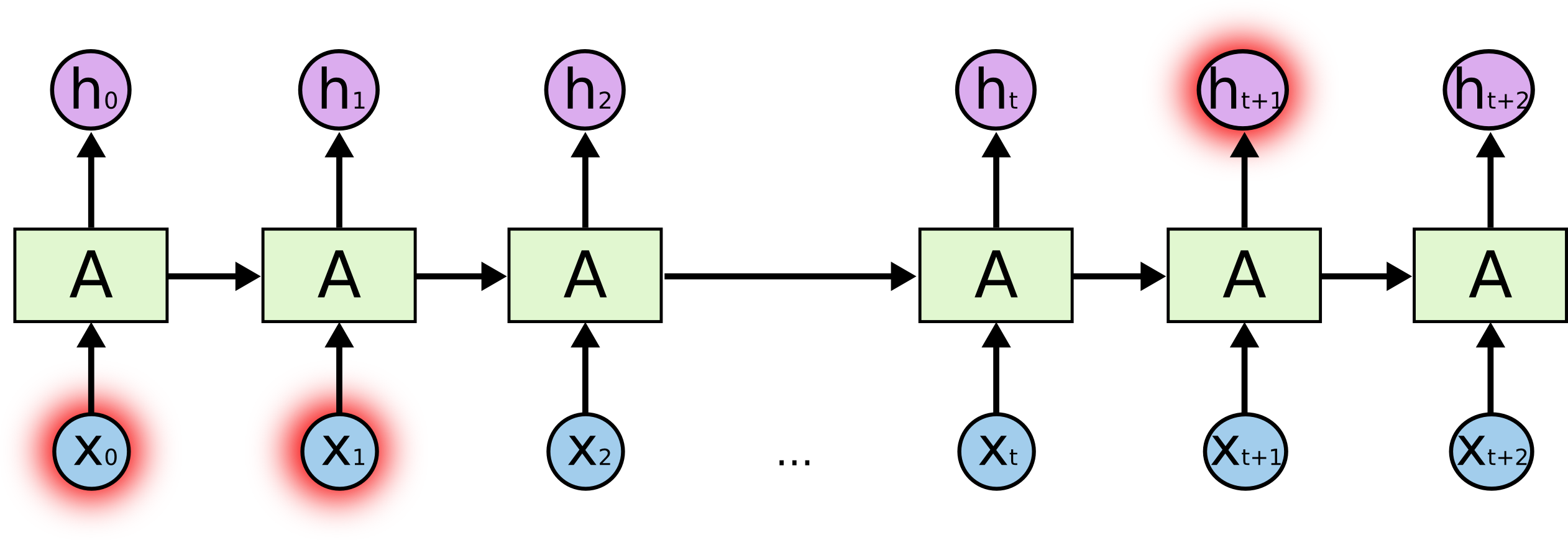
LSTM 并没有这个问题!
LSTM
长短期记忆(Long short-term memory)—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多领域,LSTM 都取得成功,并得到了广泛的使用。
LSTM 专门设计来避免长期依赖问题。记住长期的信息是 LSTM 的基本功能。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
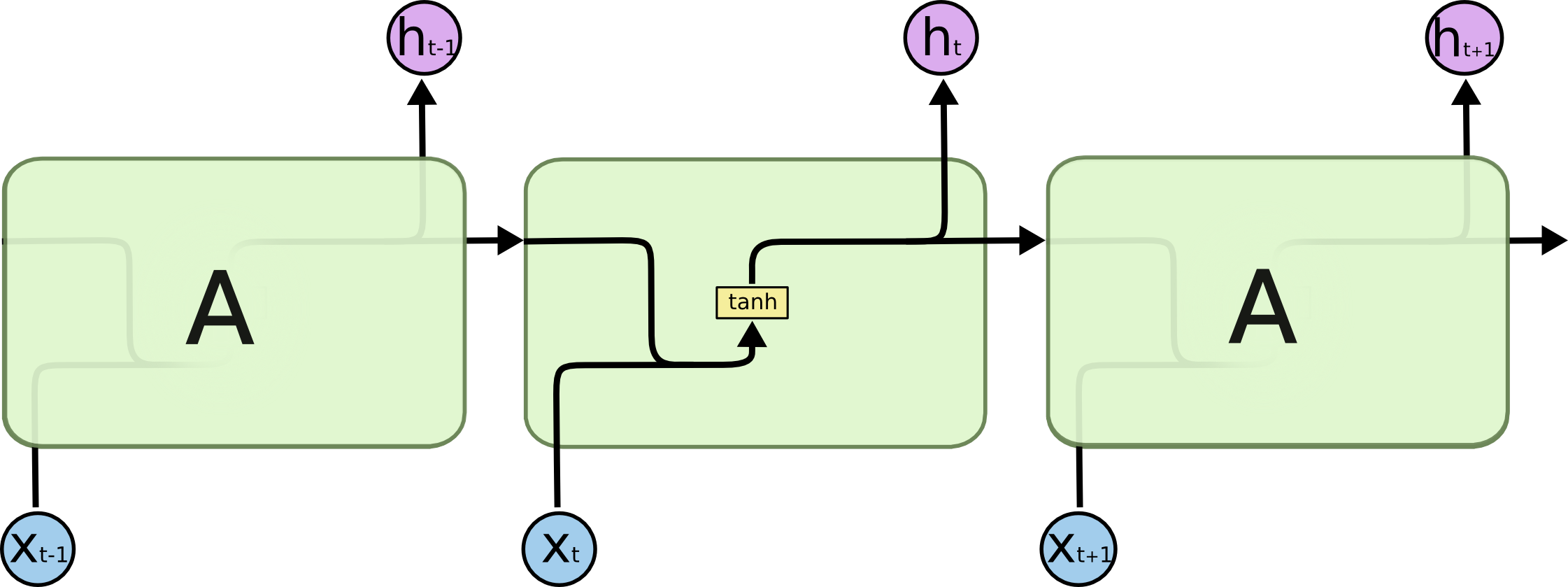
标准的 RNN
LSTM的结构要比标准的RNN复杂得多。
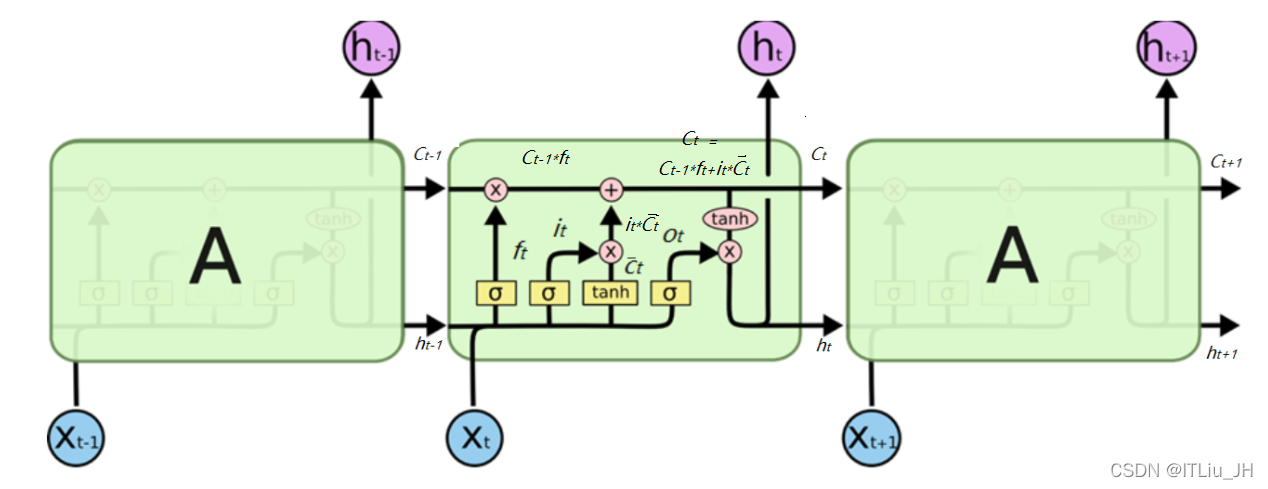
LSTM
其中
为上一时刻的输入,
为当前t时刻的输入,
下一时刻的输入;
为上一时刻的cell状态,
为当前时刻的cell状态,
为下一时刻的cell状态
c为LSTM 的关键cell状态(保存过去的信息),水平线在图上方,向下一时刻传送信息。通过遗忘门决定多少过去的信息会保留,多少被遗忘。
通过输入门决定多少现在的信息会传送到下一时刻。
为遗忘门,控制
多少进入当前时刻,当
为0时全部遗忘,当其为1时,全部进入当前时刻。
为输入门,控制多少输入信息以及多少上一时刻的输出进入当前时刻。
为上一时刻的输出,
为当前t时刻的输出,
下一时刻的输出;
为输出门,控制
多少信息会被输出。
应用案例
这里使用北京空气质量数据集,该数据集记录了北京某段时间每小时的气象情况和污染程度。
根据前几个小时的记录预测下一小时PM2.5的浓度。
该数据集包括日期时间、PM2.5浓度、露点、温度、风向、风速等字段,具体如下:
- No:样本编号
- year:该行记录的年
- month:该行记录的月
- day:该行记录的日
- hour:该行记录的小时
- pm2.5: PM2.5浓度
- DEWP:露点
- TEMP:温度
- PRES:大气压力
- cbwd:组合风向
- lws:累计风速
- ls:累计小时下雪量
- lr:累计小时下雨量
尽管只采用单一维度的PM2.5变化的时间序列,也可以预测下一时刻PM2.5的浓度,考虑其它维度对预测的精度有帮助,本案例使用的多维度的数据进行PM2.5的预测。
导入必要的模块
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline设置使用的GPU
print(tf.test.gpu_device_name())
"""
Returns the name of a GPU device if available or a empty string.
"""
print(tf.config.list_physical_devices("GPU")) #default cpu&gpu
"""
Return a list of physical devices visible to the host runtime.
"""
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
读入数据
data = pd.read_csv('d:/datasets/PRSA_data_2010.1.1-2014.12.31.csv')查看数据
data.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 43824 entries, 0 to 43823 Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 No 43824 non-null int64 1 year 43824 non-null int64 2 month 43824 non-null int64 3 day 43824 non-null int64 4 hour 43824 non-null int64 5 pm2.5 41757 non-null float64 6 DEWP 43824 non-null int64 7 TEMP 43824 non-null float64 8 PRES 43824 non-null float64 9 cbwd 43824 non-null object 10 Iws 43824 non-null float64 11 Is 43824 non-null int64 12 Ir 43824 non-null int64 dtypes: float64(4), int64(8), object(1) memory usage: 4.3+ MB
共43824样本,明显pm2.5有缺失。
数据预处理
删除前面连续缺失的部分,中间少量的缺失不能删除样本(保证时间序列连续),采用填补的方法。
data[data['pm2.5'].isna()]
data = data.iloc[24:].copy()
data.fillna(method='ffill', inplace=True)删除没有意义的特征"No"
data.drop('No', axis=1, inplace=True)将年月日时转换为时间型索引
import datetime
data['time'] = data.apply(lambda x: datetime.datetime(year=x['year'],
month=x['month'],
day=x['day'],
hour=x['hour']),
axis=1)
data.set_index('time', inplace=True)
data.drop(columns=['year', 'month', 'day', 'hour'], inplace=True)data.head()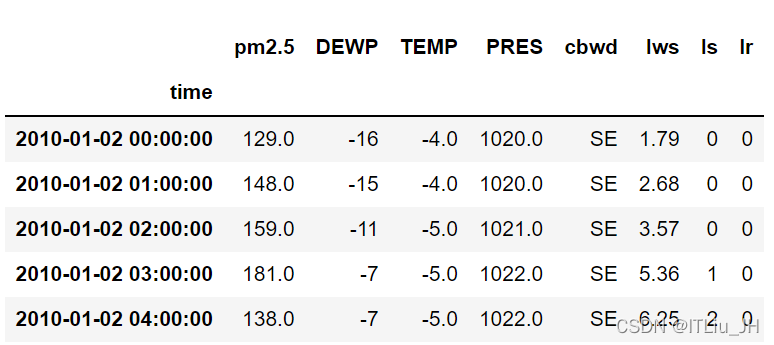
对cbwd为object型,需要对其编码
data = data.join(pd.get_dummies(data.cbwd))
del data['cbwd']data['pm2.5'].plot()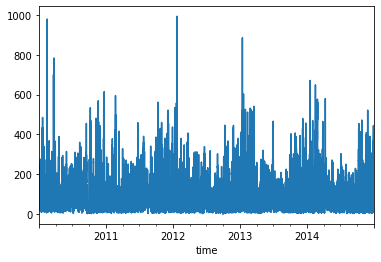
生成数据集
时间序列数据考虑的是前一些时刻的数据与当前时刻的输出相关。时间序列的数据要进行形式变换。
如用前5小时的数据预测1小时的,就要对数据按6小时,滑动窗格方式取出,其中前5小时为X,后1小时的为Y。
如0:5,1:6,2:7...,n-5:n,直到最后一个样本n,每次取6小时数据。
其中0:4共5小时为X,5为Y;1:5共5小时为第二个样本的X,6小时的为第二个样本Y。以此共n-4个样本。
sequence_length = 5*24 #预测使用的基础序列长度,可以根据预测结果调整
pred = 1 #预测长度,可调整
data_ = []
#连续重叠开窗分块数据(如0:5*24+1—1,1-5*24+1,2:5*24+2,...等),每一块是一个样本,得到LSTM需要的数据集。
for i in range(len(data) - sequence_length - pred):
data_.append(data.iloc[i: i + sequence_length + pred])
data_ = np.array([df.values for df in data_])
数据集划分
#乱序
np.random.shuffle(data_)
#基础数据序列与预测数据分离 (特征与标签分离)
x = data_[:, :-pred, :] # 基础数据序列,含所有特征。数据集X
y = data_[:, -pred:, 0] #预测数据,只包含pm2.5。数据集Y,前面的0:-pred数据序列,预测-delay:
#设置数据集划分的比例
split_0 = int(data_.shape[0] * 0.7)
split_1 = int(data_.shape[0] * 0.9)
#测试集训练集划分
train_x = x[: split_0] #前面已乱序,取前70%为训练集,后30%为测试或验证数据
val_x=x[split_0:split_1] #20%为验证集
test_x = x[split_1:] #10%为测试集
train_y = y[: split_0]
val_y=y[split_0:split_1]
test_y = y[split_1:]
建模
activation="tanh"是LSTM使用cuDNN必要条件,可以不使用cuDNN。
cuDNN(CUDA Deep Neural Network library):是NVIDIA打造的针对深度神经网络的加速库,是一个用于深层神经网络的GPU加速库。
model = keras.Sequential()
model.add(layers.LSTM(32, input_shape=(train_x.shape[1:]),activation="tanh", return_sequences=True))
#注意return_sequences=True,确保下层的lstm输入为sequences
model.add(layers.LSTM(128,activation="tanh", return_sequences=True))
model.add(layers.LSTM(32,activation="tanh")) #下层为Dense,不需要return_sequences=True
model.add(layers.Dense(1)) #输出为实数,取值范围不限,不需要激活函数注:本质上数据集划分后,用前馈神经网络,CNN都可以,只是效果上的差异。
'''
model_D = keras.Sequential()
model_D.add(layers.Flatten(input_shape=(train_x.shape[1:]))) #拍平
model_D.add(layers.Dense(16, activation='relu'))
model_D.add(layers.Dense(4, activation='relu'))
model_D.add(layers.Dense(1))
model_D.compile(optimizer=keras.optimizers.Adam(), loss='mse')
history = model_D.fit(train_x, train_y,
batch_size = 128,
epochs=40,
validation_data=(val_x, val_y),
use_multiprocessing=True
)
'''编译
model.compile(optimizer=keras.optimizers.Adam(), loss='mae') #指定优化算法,损失函数训练
类似小学生做练习题。习题总数1000(训练样本总数),每次做128道题(batch_size=128),int(1000/128)次基本全部做完。但是只做一遍可能不够,需要反复训练,就要求把这1000道题做200遍(epochs=200)。每做一次可以采用验证集数据检验学习的效果(validation_data=(val_x, val_y))。
history = model.fit(train_x, train_y,
batch_size = 128, #每次训练的数据量,全部数据训练一轮需要训练int(样本总数/batch_size)次
epochs=200, #训练的轮数(样本重复使用的次数)
validation_data=(val_x, val_y))Epoch 1/200 273/273 [==============================] - 3s 8ms/step - loss: 88.4373 - val_loss: 82.3908 Epoch 2/200 273/273 [==============================] - 2s 7ms/step - loss: 80.1071 - val_loss: 77.2936
每次128(batch_size), 全部做完一遍需要做273次,总样本数大致为273*128。
可视化训练过程
plt.plot(history.epoch, history.history.get('loss'), 'y', label='Training loss')
plt.plot(history.epoch, history.history.get('val_loss'), 'b', label='Test loss')
plt.legend()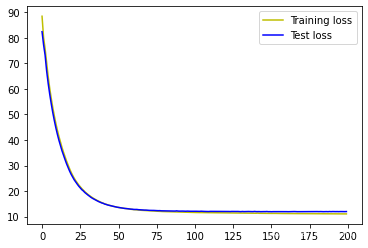
预测
pred_y=model.predict(test_x)评价
from sklearn.metrics import r2_score,mean_squared_error
print(r2_score(pred_y,test_y))
print(mean_squared_error(y_test,pred_y))

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











