






国外AI发展的如火如荼,国内也不遑多让,但各家都有不同的侧重点和亮点,百花齐放很是精彩。其中,我比较喜欢的就是智谱了。就在最近,在智谱 BigModel开放平台使用的首个支持1M上下文长度(约150-200万字)的大模型GLM-4-Long,给了我很多惊喜,下面跟大家重点介绍一下这个新模型到底有多牛逼?
1
GLM-4-Long 简介
GLM-4-Long是智谱 BigModel开放平台(bigmodel.cn)推出的一款先进语言模型,适用于需要大规模文本生成的应用场景。
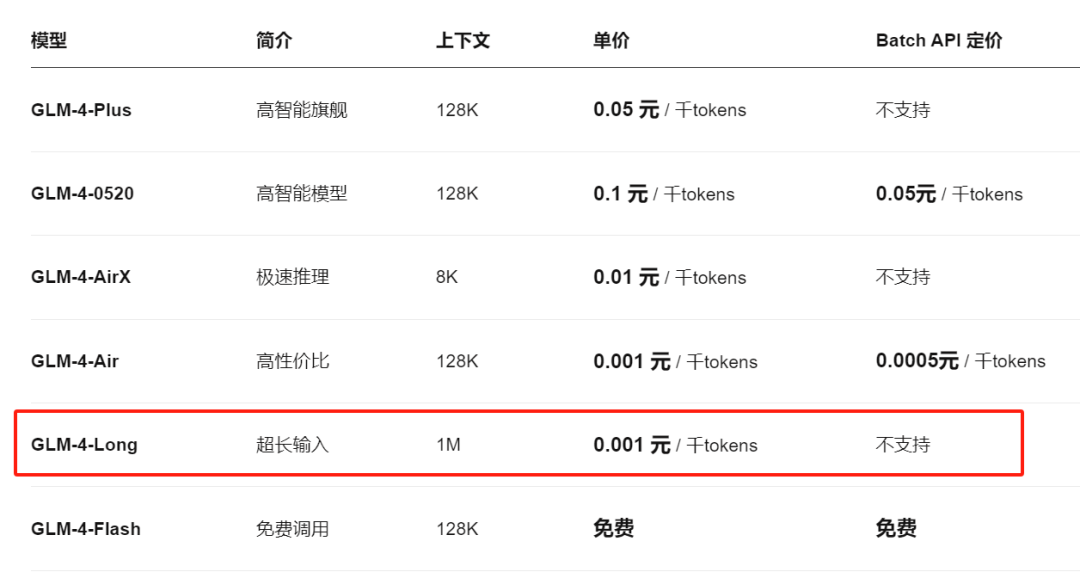
GLM-4-Long有很多的实际应用场景:比如说,解读企业年报、学习论文文献、公司财务报表、阅读长篇小说甚至是分析总结长视频。关键是价格非常亲民,100万 tokens 只需1元 ,这简直是白给了,良心定价 !
2
GLM-4-Long详解
1、GLM-4-Long如何使用 ?
GLM-4-Long 现已在BigModel开放平台上开放API调用。
首先,我们先登录BigModel开放平台:
https://zhipuaishengchan.datasink.sensorsdata.cn/t/AF
注册登录账号,就可以 免费白嫖 领取2500万Tokens资源包 。不管你用不用,现在有看到免费的,不要白不要,你说呢 。

注册登录后,我们点击模型广场,可以看到很多个AI模型,我只截图了部分,往下拉还有很多 。
我们来实际测试一下吧,看看拥有1M上下文长度的GLM-4-Long表现究竟咋样~点击体验中心进去,选择模型是GLM-4-Long,就可以开始提问了。
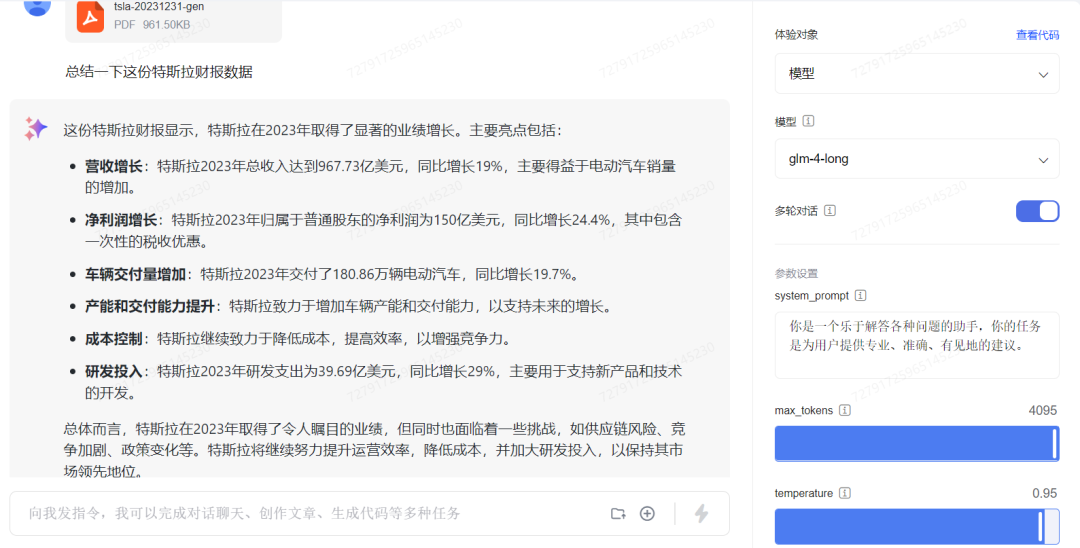
下面我上传了一份特斯拉2023年的年度财报英文文件,我让GLM-4-Long模型总结这份财报数据,可以发现它可以很快的总结出来主要的财报数据,并且我们可以针对财报中的具体问题进行追问,因为GLM-4-Long已经具备一定的推理和记忆能力,能够理解和回应复杂的问题,这简直是那些金融从业者的福音 。
2、如何使用模型API?
我们以Python代码为例,需要先导包,输入命令
pip install zhipuai
然后在BigModel平台中获取API密钥,这个密钥千万不要告诉给其他人,不然可能会被其他人盗刷tokens,如下图所示:
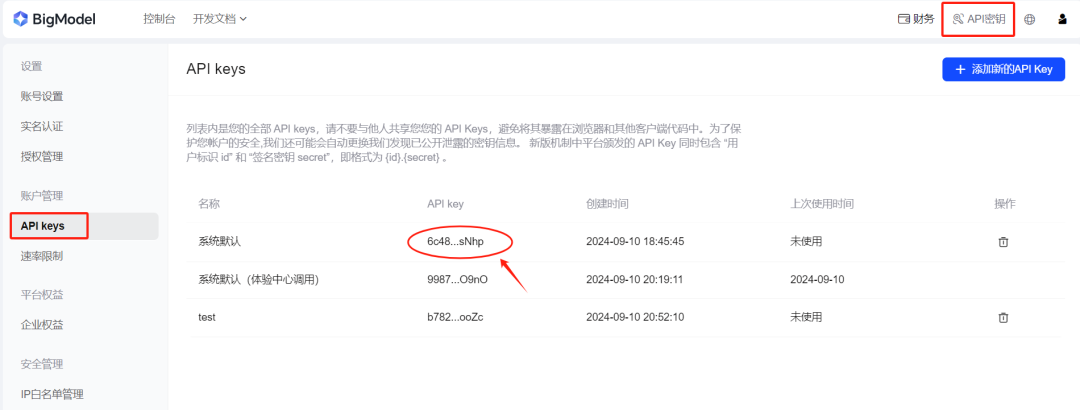
将获取到的API密钥填入代码中即可调用,这只是一个简单案例,大家可以根据这个案例去扩展 。
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="输入API密钥")
response = client.chat.completions.create(
model="glm-4-long",
messages=[
{
"role": "system",
"content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"
},
{
"role": "user",
"content": "你好,你是什么模型?"
}
],
top_p= 0.7,
temperature= 0.95,
max_tokens=4095,
tools = [{"type":"web_search","web_search":{"search_result":True}}],
stream=True
)
for trunk in response:
print(trunk)介绍了这么多,很多人不知道GLM-4-Long模型有哪些应用场景?接下来小猿会用2个实际案例带领大家更好的掌握这个模型 。
第1个案例:我先用这个模型来制作一个科幻小说内容自动生成器,你只需要告诉程序你的创意,他就能根据用户的创意去构思小说情节以及根据构思出来的情节去生成一个完整的长篇科幻小说内容 。
为什么选择长篇科幻小说这个方向呢?大家都知道一本小说的内容是非常长的,短篇小说字数也达到了十几万字,长篇小说可以达到百万字,这个就很适合使用智谱AI新出的 GLM-4-Long 大模型, 该模型支持1M上下文长度(约150-200万字)。
为了成功搞出一个小说自动生成器应用,我们的构思如下:
1、面向10~30岁的人群,根据用户给出的主题,小说构思由大模型产出 。
2、我们根据模型给出的小说构思,去完善整个小说章节内容 。
好了,根据上面的2个内容,我们直接用Python代码来实现 。
我们先让用户给出主题,比如:“外星人侵略地球”
def make_idea():
response = make_client().chat.completions.create(
model='glm-4-long',
messages=[
{'role': 'system', 'content': '你是一位擅长科幻小说的创意专家,你的任务是根据用户提供的主题,提供适合10岁到30岁的人阅读的、专业的、有见地的科幻小说内容创意。'},
{'role': 'user', 'content': '请以“外星人侵略地球”为主题,提供科幻小说内容创意。要求:情节要符合实际,故事要有情节。'},
],
stream=True,
)
# 流式输出
idea = ''
for chunk in response:
idea += chunk.choices[0].delta.content
return idea运行程序,他会自动根据用户给的这个主题,生成科幻小说的内容创意,包括小说的类型、基调、故事背景、人物介绍、情节概述,都罗列得很清楚 。
----------------------------- STRT:小说构思 -----------------------------
# 《异域入侵》
# 类型和基调
科幻小说,紧张刺激,探索人类与外星文明的冲突与共存
# 故事背景
公元2130年,人类在科技和宇宙探索方面取得了巨大突破,地球联合政府(UEG)成立,旨在统一全球资源,推动太空殖民和防御外星威胁。UEG的太空舰队在执行一项秘密任务时,意外发现了一艘神秘的外星飞船,随后引发了一系列超出人类认知的冲突。
# 人物介绍
- 李浩:UEG太空舰队指挥官,勇敢冷静,对未知充满好奇,但也深知人类的脆弱。
- 艾米丽:UEG科学家,专注于外星生物研究,聪明而敏感,对李浩有着复杂的情感。
- 罗伯特:UEG高级顾问,政治手腕高超,对李浩的决策持有怀疑态度。
- 外星领袖:一个神秘而强大的存在,其真实意图和身份对人类来说是个谜。
# 情节概述
## 第一章 - 神秘信号
李浩率领的太空舰队在执行常规巡逻任务时,接收到一个来自未知星域的神秘信号。经过分析,他们认为这可能是一艘外星飞船的求救信号。UEG决定派遣一艘侦察船前往信号来源地。
## 第二章 - 初次接触
侦察船抵达信号来源地,发现了一艘严重受损的外星飞船。李浩和艾米丽带领一支小队进入飞船内部,发现了一些外星生物的遗体,以及一些未知的科技装置。艾米丽对这些装置产生了浓厚的兴趣。
## 第三章 - 外星生物
在一次意外中,艾米丽激活了外星装置,释放出一种未知能量。这种能量与地球生物产生了奇异的共鸣,导致艾米丽和外星生物之间建立了某种联系。同时,外星飞船的控制系统被激活,飞船开始向地球发送信号。
## 第四章 - 外星领袖
UEG收到了外星飞船的信号,发现外星生物的母星正面临灾难。外星领袖通过心灵感应与李浩联系,请求人类的帮助。李浩面临着艰难的抉择:是帮助外星人,还是保护地球的安全。
## 第五章 - 人类的选择
UEG内部对是否援助外星人产生了分歧。罗伯特等人认为外星人的真实意图不明,可能对地球构成威胁。李浩和艾米丽则认为这是人类展现责任和同情心的机会。最终,UEG决定派遣一支救援队伍前往外星母星。
## 第六章 - 外星母星
救援队伍抵达外星母星,发现那里的环境已经变得极端恶劣。外星领袖向李浩展示了他们的文明和面临的困境,请求人类的技术援助。李浩意识到,外星人的科技远超地球,但他们的社会结构和情感与人类相似。
## 第七章 - 危机四伏
在救援过程中,外星母星的环境不断恶化,救援队伍面临着前所未有的挑战。李浩和艾米丽与外星领袖建立了信任,共同制定了一个拯救外星母星的计划。
## 第八章 - 生死抉择
救援行动进入关键阶段,李浩和艾米丽必须冒险进入外星母星的核心区域。在那里,他们发现了一个可以稳定外星母星环境的装置,但启动它需要牺牲大量的能量。李浩和艾米丽做出了艰难的决定。
## 第九章 - 和平的曙光
装置成功启动,外星母星的环境逐渐恢复稳定。外星领袖对人类的援助表示感激,并承诺不再对地球构成威胁。李浩和艾米丽带着外星人的感激和对未知的敬畏返回地球。
## 第十章 - 人类的未来
回到地球后,李浩和艾米丽的经历引发了全球的关注。UEG开始重新评估与外星文明的关系,人类开始探索与外星文明和平共处的可能性。李浩和艾米丽的冒险成为了人类历史上的一个转折点,预示着一个新的宇宙时代的到来。第二步,就是根据上面给出的科幻小说的内容创意,继续完善整个小说内容,代码如下:
def make_content(idea: str):
response = make_client().chat.completions.create(
model='glm-4-long',
messages=[
{'role': 'system',
'content': '你是一位擅长科幻小说内容编写专家,你编写的故事幽默有趣,特别适合适合10岁到30岁的人阅读,你的任务是根据用户提供的小说创意,完成编写的整个小说内容。'},
{'role': 'user',
'content': f'请根据科幻小说内容创意,完成编写整个小说内容。\n\n故事内容要求:\n故事内容分为10个小段,每个小段1000个汉字左右,故事总长度不少于10000个汉字。\n\n科幻小说创意:\n{idea}'},
],
stream=True,
)
# 流式输出
content = ''
for chunk in response:
content += chunk.choices[0].delta.content
return content我们来看一下运行的效果,发现使用GLM-4-Long生成的长篇小说内容还不错,比一些市面上现成的小说,内容还要更精彩 。到此,我们就完成了一个利用GLM-4-Long模型制作的小说自动生成器应用 。
第2个案例:小猿再带领大家搞一个 20 行以内的代码,手搓一个用于论文解读的 AI 助手。大家都知道一篇论文少则几千字,多则几万字,很多小模型都很难胜任,接下来我会用智谱AI的 GLM-4-Long 模型来看看效果,代码如下:
# 安装依赖 pip install -U --quiet zhipuai langchain pypdf
from langchain.document_loaders import PyPDFLoader
from zhipuai import ZhipuAI
import json
loader = PyPDFLoader("w25682.pdf")
pages = loader.load_and_split()
content = "\n".join([x.page_content for x in pages])
client = ZhipuAI(api_key="Your API key")
response = client.chat.completions.create(
model="glm-4-long",
messages=[
{"role": "system","content": "你是一个论文解读专家。step-by-step全面深入地解读论文,并依次回答以下问题:Q1 这篇论文试图解决什么问题?\Q2 这是一个新问题吗?\Q3 这篇论文试图验证什么科学假设?\Q4 有哪些相关研究?它们是如何分类的?在这个领域中有哪些值得注意的研究人员?\Q5 论文中提到的解决方案的关键是什么?\Q6 论文中的实验是如何进行设计的?\Q7 用于定量评估的数据集是什么?代码是开源的吗?\Q8 论文中的实验和结果是否很好地支持了需要验证的科学假设?\Q9 这篇论文的具体贡献点是什么?\Q10 下一步是什么?可以深入开展哪些工作?" },
{"role": "user","content": content}],
top_p= 0.7,
temperature= 0.95,
max_tokens=4095,
stream=False
)
print(json.loads(response.json())["choices"][0]["message"]["content"))运行程序以后,我先把一篇关于《AI和劳动力》的论文提交进去,看一下GLM-4-Long模型输出的效果,真的非常给力 。
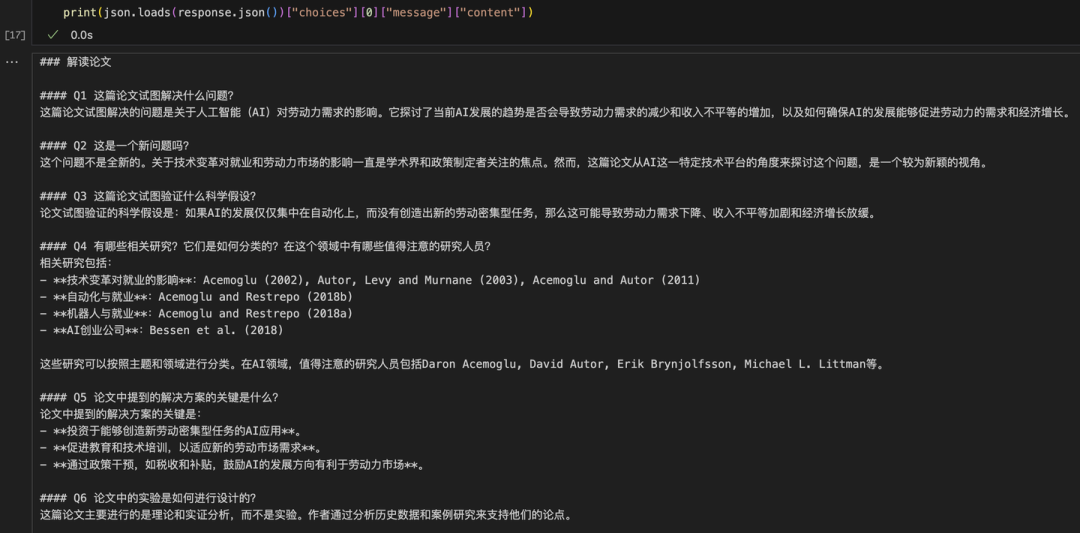
我对比了论文看了一下这些回答,基本上都能理解正确。以前会觉得读论文很麻烦,现在不论多长的论文都能在 AI 的帮助下快速理清思路,概括出论文的核心概念、论述脉络、实验过程和创新点。这是大模型最擅长的领域,也是对科研工作者来说最能直接提效的方法。
通过上面介绍,我们发现GLM-4-Long这个模型真心牛逼,在各种需要长文本理解上,该模型都展现出了非常卓越的性能,而且价格便宜。GLM-4-Long 作为百万级上下文模型性价比很高,推荐大家去体验一波!
GLM-4-Long接口文档:
https://bigmodel.cn/dev/api#glm-4
GLM-4-Long体验中心:
https://zhipuaishengchan.datasink.sensorsdata.cn/t/AF
最后,大家如果对智谱AI感兴趣的,欢迎扫描下方二维码加入「ZHIPUer技术社区」,分享最新案例,交流技术心得,还有更多内部测试、企业内推等机会等你解锁。

觉得内容还不错的话,给我点个“在看”呗



















 8430
8430

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











