






在实际生产环境中,全链路跟踪框架如果对每个请求都开启跟踪,必然会对系统的性能带来一定的压力。与此同时,庞大的数据量也会占用大量的存储资源,使用全量采样的场景很有限,大部分应用接入链路跟踪的初衷是错误异常分析或者样本查看。
为了消除全量采样给系统带来的影响,设置采样率是一个很好的办法。采样率通常是一个概率值,取值在0到1之间,例如设置采样率为0.5的话表示只对50%的请求进行采样。在之前的采样算法之蓄水池算法,描述了一种常用的采样算法实现。
但是采用固定采样率的算法仍然有2个明显的问题:
应用无法很好的评估采样率。从中间件的角度来说,这个对于应用最好能做到透明
应用在不同的时间段,流量或者负载等会有很大的差别。如果采用统一的采样率,可能导致样本不均衡或者不充足
所以,比较理想的方式是提供自适应采样。最初的思想可追溯到Dapper的Coping with aggressive sampling。
QPS-采样数-采样率函数
首先,我们拟根据应用qps作为变量来构建qps-每秒采样数函数,从而可算出采样率,即每秒采样数/qps。
接着,我们需要确定一些目标值,根据对这些值的逼近来得出我们的最终函数。
最小阈值。为了对低流量的应用尽可能公平,保证样本的充分,我们约定小于等于最小阈值qps的时候,采样率为百分百。假定最小阈值为10,即qps<10时,每秒采样数即为qps,采样率为百分百。
业务目标值。一般在Metrics系统中,例如Prometheus,都会有记录业务应用的日常qps均值。假定业务应用的单机qps均值为200,并且希望在上线自适应采样后存储成本能够降低百分之四十,那么就是在qps为200的时候,需要对应的每秒采样数为120。
极大值。在qps很大的情况下,其实只需保证一个较大的固定每秒采样数就可以满足保留足够请求样本的初衷了,而不需要随着qps的增加无限制的增加每秒采样数,这样的话对机器IO的压力也会较大。那么在qps达到极大值的情况下,qps-每秒采样数的函数导数应为0,而大于极大值的时候保持每秒采样数不变。例如可假定qps极大值为2000。
如果我们基于以上这些值,并且设定qps-每秒采样数为一段二次函数,即每秒采样数=aqps^2+bqps+c,可以得到以下关系:100a+10b+c=10
40000a+200b+c=120
4000a+b=0
最终得到函数为每秒采样数= -0.00015qps^2+0.611qps+3.905。在实际应用中,可以根据业务的具体情况对参数做相应的调整。
那么qps-每秒采样数的函数大致如下: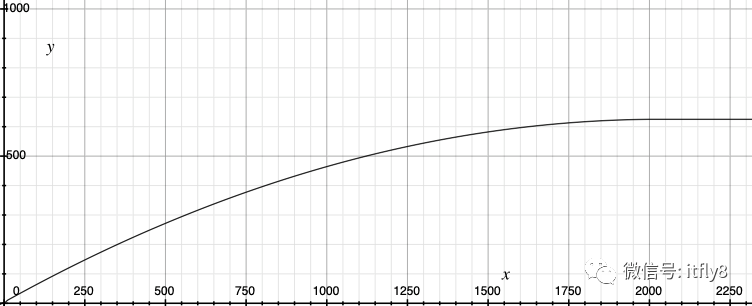
相应的qps-采样率的函数如下: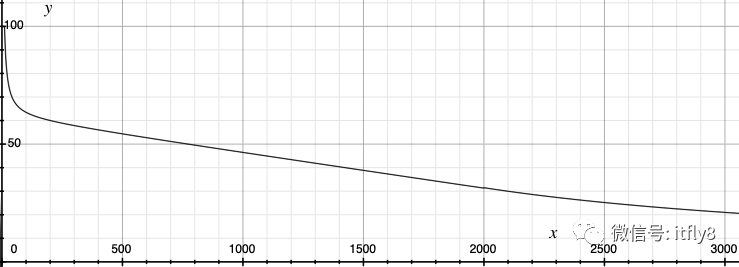
计算QPS
考虑到之前我们的固定采样率算法使用的是蓄水池算法,简单来说是利用了一个100大小的BitSet,根据采样概率为之填充了相应的0或1,并每过一百次请求后进行循环复用。
那么其实计算QPS也可以直接复用该BitSet而不用额外构造数据结构了。每当请求来到第一百次的时候都会记录一个值time,每100个请求循环末time值与前次循环的time值之差作为时间间隔interval。那么显而易见QPS即为100/interval。
应用采样率
根据上述分析,在每次循环BitSet,当计数来到99的时候,都会为下一次100请求循环生成一个新的采样率。根据每秒采样数-qps函数计算出对应采样率后,需要将其应用到BitSet中,即生成一个新的100大小的BitSet。
在实际应用过程中,有一些需要问题仍需关注
预热
所谓预热,其实是假"预热"。对于当前情况来说,最初的BitSet生成时并不知应该采用什么采样率,因为这时候qps值也没有算出来。目前策略是刚开始生成的BitSet统一设置采样率为1,即最初的100个请求会被百分比采样。其实这样,也更方便了记录开发或者测试的调试请求。
QPS滞后
当前计算QPS的方式是固定了样本数,通过消耗完样本数的时间来计算。而一般计算QPS的方式往往是固定间隔时间,通过间隔时间内记录的请求数进行计算。前者比较大的问题是QPS滞后的问题会更严重一些。
按照我们当前的计算方式,新的100大小的BitSet的采样率是根据前面100个样本的消耗时间计算出来的,也就是有所谓100个样本的QPS滞后。
而相比固定间隔时间计算方式来说,这种情况会更严重一些。举个栗子说,当晚高峰过后,实际qps从1000骤降到0(忽略不计,100个样本延续了一晚),但后100个样本的采样率还是根据1000qps算出来的,并且如果这100个样本延续了一晚,那么其实QPS滞后了一晚。而对于固定间隔时间的计算方式来说,QPS最多只会滞后其间隔时间。
但好在计算QPS的应用场景是用于进行采样,那么滞后问题就不是问题了。不论是骤降还是骤升,对于采样的影响可以忽略不计,因为采样关注的是样本数而不是时间,100个样本的滞后对于整体的影响并不大。
并发问题
显然,在每次100个请求结束开始新的循环的时候,都需要做一些操作,计算采样率,创建BitSet,记录time值等。而这些操作为了防止并发问题都是需要加锁的,性能上来讲,每过100个请求才会加锁一次,并不用过于担心,何况从JDK6开始synchronized就已经在被不断优化了。
相关源码
相关的代码模拟如下:
public class AdvancedAdaptiveSampler extends Sampler {
private volatile AtomicInteger counter = new AtomicInteger(0);
private static BitSet sampleDecisions;
private long prevTime;
private static final int MIN_SAMPLE_LIMIT = 10;
private static final int MAX_SAMPLE_LIMIT = 2000;
public AdvancedAdaptiveSampler() {
int outOf100 = (int) (1 * 100.0f);
//蓄水池算法 见https://www.fredal.xin/reservoir-sampling
sampleDecisions = RandomBitSet.genBitSet(100, outOf100, new Random());
prevTime = System.currentTimeMillis();
}
@Override
protected boolean doSampled() {
boolean res = true;
int i;
do {
i = this.counter.getAndIncrement();
if (i < 99) {
res = sampleDecisions.get(i);
} else {
synchronized (this) {
if (i == 99) {
res = sampleDecisions.get(99);
int outOf100 = calAdaptiveRateInHundred(System.currentTimeMillis() - prevTime);
sampleDecisions = RandomBitSet.genBitSet(100, outOf100, new Random());
prevTime = System.currentTimeMillis();
this.counter.set(0);
}
}
}
} while (i > 99);
return res;
}
private int calAdaptiveRateInHundred(long interval) {
double qps = (double) (100 * 1000) / interval;
if (qps <= MIN_SAMPLE_LIMIT) {
return (int) (1 * 100.0f);
} else {
if (qps > MAX_SAMPLE_LIMIT) {
qps = MAX_SAMPLE_LIMIT;
}
double num = -0.00015 * Math.pow(qps, 2) + 0.611 * qps + 3.905;
return (int) Math.round((num / qps) * 100.0f);
}
}
}
出处:https://fredal.xin/adaptive-sampling-in-all-link-tracking















 470
470











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









