







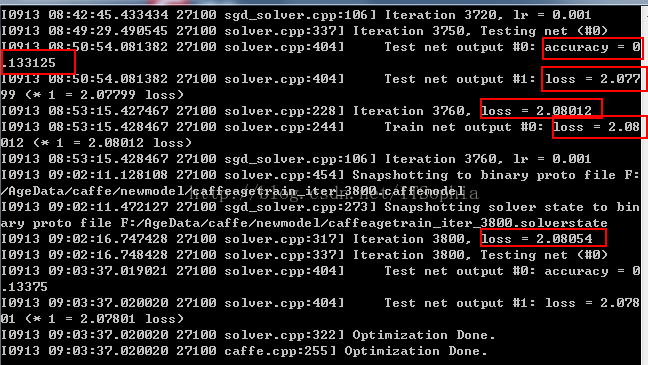
从训练的输出可以看出,accuracy非常低,loss一直不收敛,所以使用这个训练出来的模型的分类结果都一样,因为训练过程中,机器根本没有学到东西~~
两种原因:
1、网络结构参数不对或者缺少 2、数据量太少
我使用了相同的网络去训练不同量的数据,10000+数据迭代10000次的效果好了很多,5000的数据量迭代4000次就没学到东西~
从训练的输出可以看出,accuracy非常低,loss一直不收敛,所以使用这个训练出来的模型的分类结果都一样,因为训练过程中,机器根本没有学到东西~~
两种原因:
1、网络结构参数不对或者缺少 2、数据量太少
我使用了相同的网络去训练不同量的数据,10000+数据迭代10000次的效果好了很多,5000的数据量迭代4000次就没学到东西~
 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























