






DevOps 与数据和机器学习相遇
可直接在橱窗里购买,或者到文末领取优惠后购买:
你是否曾经在微博上点赞某件事,然后几乎立刻在动态中看到相关内容?或者在 Google 上搜索某件事,然后几分钟后就会收到大量与该事相关的广告?这些都是日益自动化的世界的症状。在幕后,它们是先进的 MLOps 管道的结果。我们来看看 MLOps 以及有效部署机器学习模型需要什么。
我们首先讨论 DevOps 的一些关键方面。然后我们解释引入数据和模型如何颠覆标准实践。这导致了 MLOps 的出现。现有实践(如 CI/CD 管道)需要调整。引入新实践(如持续训练)。最后,我们讨论受监管环境中的 MLOps 以及它与模型可解释性的关系。
DevOps
DevOps 是一套最佳实践、工具和公司文化,旨在提高软件开发、测试、部署和监控的效率。你可以拥有一个专门的 DevOps 团队来实施最佳实践。然而,它需要许多团队之间的参与和有效沟通。每家公司对 DevOps 的方法都不同。目标始终是相同的 - 快速部署优质软件。
CI/CD 管道
所有软件在使用之前都需要开发、彻底测试和部署。DevOps 试图通过构建和自动化 CI/CD 管道来提高此过程的效率。持续集成 (CI) 涉及开发软件的流程。持续部署/交付 (CD) 涉及将软件转移到生产环境的流程。最佳实践和文化嵌入在这些管道的管理中。
让我们考虑如何处理第一个方面,即持续集成。通常,这要求开发人员定期将代码更改推送到远程存储库。然后,运行自动单元和集成测试以立即识别代码中的任何问题。 DevOps 将定义实施这些步骤的最佳实践。我们使用 git 等工具来推送更改或使用 junit 来运行单元测试来实现它们。要做到这一点,需要形成定期提交代码的文化。这对大多数人来说并不自然。
监控
一旦软件投入使用,我们就需要确保它运行良好。这涉及根据系统延迟数据创建指标。DevOps 旨在自动化此过程,并使开发人员可以轻松访问这些指标。它还可以涉及使用预定义的指标截止值创建自动警告。最终目标是建立一个持续的监控系统。这将实时提供所有应用程序的指标。

沟通
传统上,开发人员和运营团队是孤立的。在这种情况下,开发人员将合作开发软件。完成后,他们会将其交给运营团队进行部署。开发和生产环境并不相同。这可能会导致交接过程中出现大量问题。最糟糕的情况是,你可能会发现软件根本无法部署。DevOps 旨在打破这些团队之间的隔阂,建立一种沟通文化。
MLOps = DevOps + 数据 + 模型
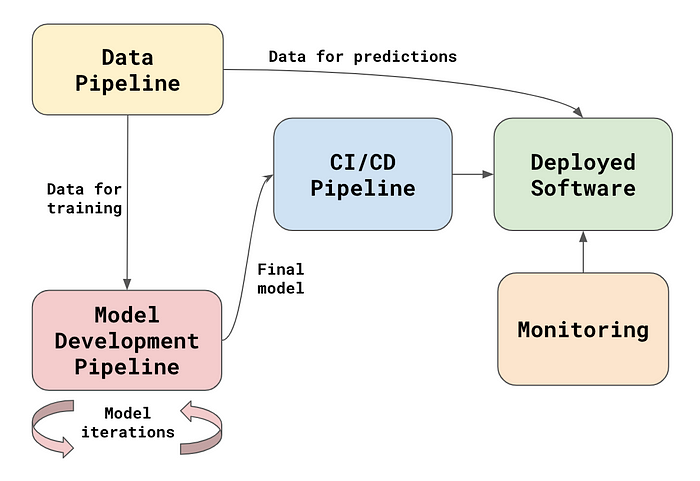
MLOps 源于 DevOps。上面讨论的许多方面都会延续下来。关键的区别在于,对于机器学习应用程序,我们需要数据和模型。这意味着我们不能再依赖现有的实践和工具。在图 1 中,你可以看到数据和模型如何与现有的 DevOps 管道相适应的概述。我们将讨论这些新方面以及它们如何影响现有的 DevOps 实践。
数据和模型开发
没有数据,就没有机器学习。数据需要在正确的时间出现在正确的位置。对于数据科学家来说,这意味着需要有足够的历史数据来训练模型。我们还需要更多最新数据来做出预测。在极端情况下,我们可能需要实时数据。数据工程师负责管理数据流入数据仓库。使用 MLOps,可以使用 CI/CD 数据管道来完成此操作。数据工程师将需要新工具来开发这些工具。
数据为生产工作流程添加了新元素。同样,开发模型不同于开发软件。在确定最终模型之前,通常需要进行数千次迭代。我们在模型开发流程中进行这些迭代。该流程应使数据科学家能够轻松评估模型。它还应有助于跟踪所有不同的模型版本。应该很容易比较模型以决定最佳模型。
CI/CD 管道
模型可能看起来像一个神秘的东西,但一旦训练完成,它就与普通代码没有什么不同。它是一组指令,可以接受输入(即数据)并给出输出(即预测)。开发完成后,我们可以将最终模型推送到主 CI/CD 管道。然后运行自动单元测试和集成测试,以确保新模型没有问题。
CI/CD 管道的设计使得如果新代码出现问题,我们可以轻松恢复到旧版本。同样,我们应该能够恢复到模型的旧版本。如果我们发现模型的表现不如预期,我们就会这样做。也就是说,如果它在新数据上表现不佳或做出有偏差的预测。为了保护公司和客户,我们必须能够快速恢复到旧模型。
监控
对于计算资源,监控模型类似于监控软件。我们需要确保模型按预期使用 CPU、RAM、带宽和磁盘空间。模型预测不应产生任何延迟问题。大多数这些挑战都已通过现有的 DevOps 实践得到解决。监控模型准确性方面的性能带来了新的挑战。
与软件不同,模型会退化。模型捕获的底层关系会随着时间的推移而变化。这将导致模型的预测不太准确。我们需要引入新的指标来监控数据和模型准确性的变化。与典型的系统指标不同,最终用户将是数据科学家。他们将使用这些指标来帮助决定我们何时需要重新开发模型。
持续训练(CT)
一旦我们标记一个模型需要重新开发,数据科学家就会介入。通常,会有一个手动过程来收集训练数据、创建特征并重新训练模型。在某些情况下,这个过程可以完全自动化。这让我们回到了文章开头的反问。没有人参与更新你的微博动态。当你喜欢新内容时,支持你推荐帖子的模型会自动更新。
这被称为持续训练。在这里,MLOps 不仅寻求自动化模型的部署,还寻求自动化模型的训练。某些事件将启动模型的重新开发。这可能是因为有新数据可用,或者模型性能可能下降。在这种情况下,CI/CD 管道看起来可能非常不同。我们不再只是部署代码。我们正在部署另一项服务(即模型)的系统(即 ML 管道)。
沟通
与 DevOps 一样,我们无法仅使用花哨的工具来实现有效的 MLOps。这也不是单个团队的责任。它需要许多团队之间的协作。这些团队包括领域专家、数据科学家、数据工程师、软件开发人员和 DevOps 团队。使用 MLOps,现在有更多的团队参与其中。这会使有效沟通更具挑战性。

监管与可解释性
有效的 MLOps 是一个目标。组织需要不断改进系统、工具和沟通才能实现这一目标。不同的组织将面临不同的挑战。较老的组织将不得不改进或替换现有流程。较新的组织具有能够立即实施最佳实践的优势。对于某些行业来说,不仅存在技术挑战,还存在法律和道德挑战。
例如,保险业和银行业都受到严格监管。在这种环境下开发的模型将受到严格审查。在部署模型之前,需要其他团队(例如合规团队)和外部监管机构的批准。你需要向这些团队报告并向他们解释模型。这将为模型开发过程添加手动步骤。最终,从技术上讲,自动化模型训练和部署可能是可行的,但这样做是违法的。

你可以使用的模型类型也可以进行监管。这会影响你自动化模型开发过程的能力。使用 XGBoost 和随机森林等模型更容易做到这一点。在这里,你可以通过调整超参数来自动化模型选择过程。在保险或银行业,你可能需要使用回归。要建立一个好的回归模型,你需要选择一组最好的 8 到 10 个不相关的特征。这个过程更难自动化,我们在文章 良好功能的特征中有详细讨论它。
对可解释性的需求通常是模型以这种方式进行监管的原因。如果你没有彻底解释你的模型,它们可能会产生意想不到的结果。同样,如果你没有进行彻底的算法公平性分析,它们可能会产生有偏见的结果。解释模型和公平性总是需要一些人工干预。对于影响较大的模型,自动化这些过程的好处被风险所抵消。
参考
M. Treveil, et. al., Introducing MLOps: How to Scale Machine Learning in the Enterprise (2020), https://www.oreilly.com/library/view/introducing-mlops/9781492083283/
AWS, What is DevOps?(2022), https://aws.amazon.com/devops/what-is-devops/
AWS, *What is Continuous Integration? (*2022), https://aws.amazon.com/devops/continuous-integration/
AWS, What is Continuous Delivery? (2022), https://aws.amazon.com/devops/continuous-delivery/
IBM, What Is the CI/CD Pipeline? (2021) https://www.ibm.com/cloud/blog/ci-cd-pipeline
RevDeBug, Unit Tests Vs. Integration Tests (2021) https://revdebug.com/blog/unit-tests-vs-integration-tests/
M. Anastasov, CD Pipeline: A Gentle Introduction (2022), https://semaphoreci.com/blog/cicd-pipeline
O. Itzary and L. Nahum, Continuous Training for Machine Learning — a Framework for a Successful Strategy (2021), https://www.kdnuggets.com/2021/04/continuous-training-machine-learning.html
「AI秘籍」系列课程:
















 184
184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











