







 Swin Transformer是一种使用移动窗口的层级式Vision Transformer,旨在解决Transformer在视觉任务中的计算复杂度问题。它通过W-MSA(Window Multi-Self-Attention)降低计算量,同时引入移动窗口操作实现跨窗口交互,达到类似CNN的多尺度特征提取。论文表明,Swin Transformer在分类、检测和分割等任务上表现出色,证明了其作为通用骨干网络的潜力。
Swin Transformer是一种使用移动窗口的层级式Vision Transformer,旨在解决Transformer在视觉任务中的计算复杂度问题。它通过W-MSA(Window Multi-Self-Attention)降低计算量,同时引入移动窗口操作实现跨窗口交互,达到类似CNN的多尺度特征提取。论文表明,Swin Transformer在分类、检测和分割等任务上表现出色,证明了其作为通用骨干网络的潜力。
论文地址:Swin transformer: Hierarchical vision transformer using shifted windows
代码:官方源码
视频:Swin Transformer论文精读【论文精读】_哔哩哔哩_bilibili
本文注意参考:Swin Transformer论文精读【论文精读】 - 哔哩哔哩
目录
Patch Embedding:切出patch并做Embedding
Patch Merging:把临近的小 patch合并成一个大 patch
Swin Transformer是 ICCV 21的最佳论文,它之所以能有这么大的影响力主要是因为在 ViT 之后,Swin Transformer通过在一系列视觉任务上的强大表现,进一步证明了Transformer是可以在视觉领域取得广泛应用
题目和摘要
Swin Transformer是一个用了移动窗口的层级式的Vision Transformer
- Swin:来自于 Shifted Windows,Swin Transformer这篇论文的主要贡献
- 层级式 Hierarchical: Swin Transformer像卷积神经网络一样,也能够分成几个 block,做层级式的特征提取,使得提出来的特征有多尺度
这篇论文提出了一个新的 Vision Transformer 叫做 Swin Transformer,它可以被用来作为一个计算机视觉领域一个通用的骨干网络。
直接把Transformer用到视觉领域有一些挑战,主要来自于两个方面:
- 多尺度问题:比如一张图片里的代表同样一个语义的词(即物体)有非常不同的尺寸,NLP中没有这个问题。
- 分辨率太大:如果将图片的每一个像素值当作一个token直接输入Transformer,计算量太大。之前的工作要么用后续的特征图来当做Transformer的输入,要么把图片打成 patch 减少这个图片的 resolution,要么把图片画成一个一个的小窗口,然后在窗口里面去做自注意力,所有的这些方法都是为了减少序列长度
基于这两个挑战,本文提出了 hierarchical Transformer,通过一种叫做移动窗口的方式学习特征,即只在滑动窗口内部计算自注意力,所以称为W-MSA(Window Multi-Self-Attention)。
- 通过Shiting(移动)的操作可以使相邻的两个窗口之间进行交互,也因此上下层之间有了cross-window connection,从而变相达到了全局建模的能力。
- 分层结构使得模型可以提取各个尺度的特征信息
- 计算复杂度与图像大小呈线性关系,这样模型就可以处理更大分辨率的图片(为作者后面提出的Swin V2铺平了道路)。
- Vision Transformer:进行MSA(多头注意力)计算时,任何一个patch都要与其他所有的patch都进行attention计算,只要窗口大小是固定的,那么计算量与图片的大小成平方增长。
- Swin Transformer:采用了W-MSA,只对window内部计算MSA,当图片大小增大时,计算量仅仅是呈线性增加。
因为 Swin Transformer 拥有了像卷积神经网络一样分层的结构,能够提取出多尺度的特征,所以很容易使用到下游任务里。ImageNet-1K 上准确度达到87.3%;在 COCO mAP刷到58.7%(比之前最好的模型提高2.7);在ADE上语义分割任务也刷到了53.5(提高了3.2个点 )
对于 MLP 的架构,用 shift window 的方法也能提升,见MLP Mixer 这篇论文
引言
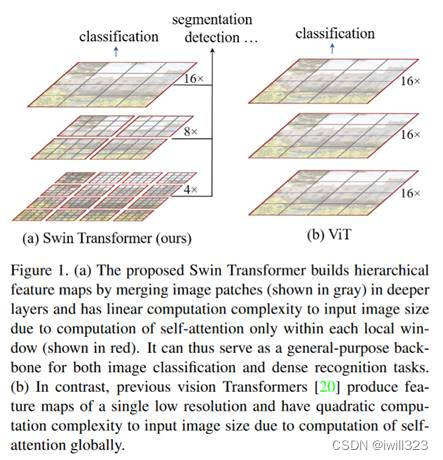
ViT在视觉领域应用面临的问题
- ViT 处理的特征都是单一尺寸。ViT把图片打成 patch,patch size 是16*16的,右图中的16×意味着16倍的下采样率,自始至终都是处理的16倍下采样率过后的特征,对多尺寸特征的把握就会弱一些
- 对于密集预测型的任务(检测、分割),有多尺寸的特征至关重要的。
- 比如目标检测的分层式的卷积神经网络FPN,每一个卷积层出来的特征的 receptive field (感受野)是不一样的,能抓住物体不同尺寸的特征,从而能够很好的处理物体不同尺寸的问题;
- 物体分割的 UNet,采用 skip connection 的方法,当一系列下采样做完以后,去做上采样的时候,不光是从模型的bottleneck 里去拿特征,还从之前每次下采样的输出中去拿特征,恢复高频率的图像细节
- 检测和分割领域常用的输入尺寸是800*800或者1000*1000,当图片变到这么大的时候,序列长度上千,使用ViT的话,计算复杂度难以承受的
W-MSA 特点和好处
- 使用窗口(Window)的形式将特征图划分成了多个不相交的区域,并且只在每个窗口内进行多头注意力计算,大大减少计算量。
- 这种设计利用了卷积神经网络里局部性的先验知识。同一个物体的不同部位或者语义相近的不同物体大概率出现在相连的地方,所以在一个小范围的窗口算自注意力是差不多够用的,对于视觉任务来说,全局计算自注意力其实是有点浪费资源的
- CNN是以滑动窗口的形式一点一点地在图片上进行卷积的,所以假设图片上相邻的区域会有相邻的特征,靠得越近的东西相关性越强。
- 将每49个patch划分为一个窗口,只在窗口内进行注意力计算,于是序列长度就只有49,解决了计算复杂度的问题。
- 使用patch merging把相邻的小 patch 合成一个大 patch,后者能看到之前四个小patch看到的内容,感受野就增大了,从而抓住多尺寸的特征。
- 卷积神经网络有多尺寸的特征,主要是因为池化能够增大每一个卷积核能看到的感受野,从而使得每次池化过后的特征抓住物体的不同尺寸。patch merging类似于池化
- 一旦有了4x、8x、16x的特征图,就可以通过FPN结构做检测,通过UNet结构就可以做分割了。
这就是作者反复强调的,Swin Transformer是能够当做一个通用的骨干网络的,不光是能做图像分类,还能做密集预测性的任务
移动窗口的操作
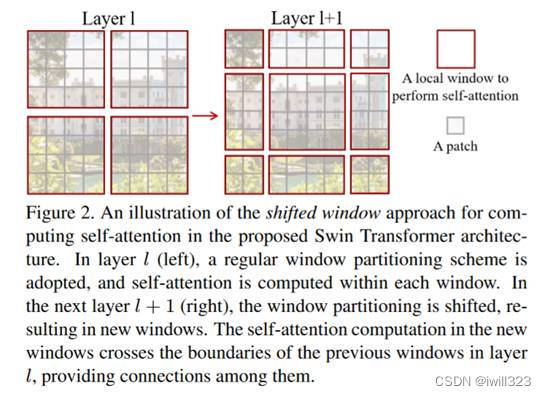
图中每一个灰色的patch 是最基本的元素单元,也就是图一中4*4的patch;每个红色的框是一个中型的计算单元,也就是一个窗口。在本论文里,一个小窗口默认有49个patch。
- 因为Transformer的初衷就是更好的理解上下文,如果窗口都是不重叠的,那自注意力就变成孤立自注意力,没有全局建模的能力
- 加上 shift 的操作,每个 patch就可以在新的窗口里与别的 patch就进行交互,而这个新的窗口里所有的 patch 其实来自于上一层别的窗口里的 patch,这也就是作者说的cross-window connection,即窗口和窗口之间交互
shift 操作就是往右下角的方向整体移两个 patch,然后在新的特征图里把它再次分成四方格。这样的好处是窗口与窗口之间可以互动。如果不使用shift,那么每次自注意力的操作都在同一个窗口里进行了,每个窗口里的 patch 就永远无法注意到别的窗口里的 patch 的信息,达不到使用 Transformer 的初衷
patch merging使得到 Transformer 最后几层的时候,每一个 patch 本身的感受野就已经很大了,能看到大部分图片信息,然后再加上移动窗口的操作,窗口内的局部注意力就变相等于全局自注意力操作。既省内存,效果也好
展望
作者坚信一个 CV 和NLP 之间大一统的框架是能够促进两个领域共同发展的
- Swin Transformer还是利用了一些视觉里的先验知识
- 在模型大一统上,也就是 unified architecture 上来说,其实 ViT 还是做的更好的,因为它什么先验信息都不加,把所有模态的输入直接拼接起来,当成一个很长的输入,直接扔给Transformer去做,而不用考虑每个模态的特性
结论
这篇论文提出了 Swin Transformer,它是一个层级式的Transformer,计算复杂度是跟输入图像的大小呈线性增长的
Swin Transformerr 在 COCO 和 ADE20K上的效果远远超越了之前最好的方法,希望 Swin Transformer 能够激发出更多更好的工作,尤其是在多模态方面
这篇论文里最关键的一个贡献就是基于 Shifted Window 的自注意力,它对很多视觉的任务,尤其是对下游密集预测型的任务是非常有帮助的,但是如果 Shifted Window 操作不能用到 NLP 领域里,其实在模型大一统上论据就不是那么强了,所以作者说接下来他们的未来工作就是要把 Shifted Windows用到 NLP 里面,而且如果真的能做到这一点,那 Swin Transformer真的就是一个里程碑式的工作了,而且模型大一统的故事也就讲的圆满了
方法
模型总览图如下图所示。整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野。
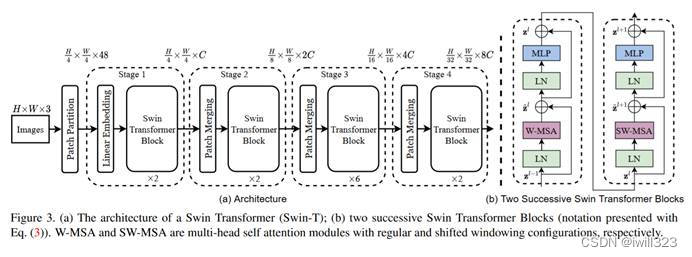
前向过程
假设输入图片尺寸是224*224*3(ImageNet 标准尺寸)
- patch partition:像 ViT 那样把图片打成 patch,patch size 是4*4,得到图片的尺寸是56*56*48。向量的维度48,因为4*4*3
- Linear Embedding:把向量的维度变成一个超参数c(对于 Swin tiny 网络,c 是96),尺寸就变成了56*56*96,拉直变成3136(56*56)长的序列,96是每一个token向量的维度
- Patch Partition 和 Linear Embedding相当于是 ViT 里的Patch Projection 操作,而在代码里也是用一次卷积操作就完成了,kernel size=4×4,stride=4,num_kernel=48
- swin-transformer有T、S、B、L等不同大小,其C的值也不同,比如Swin-Tiny中,C=96
- swin transformer block:将每49个patch划分为一个窗口,只在窗口内计算自注意力。swin transformer block的输入输出尺寸是不变的,所以stage1输出还是56*56*96
- 层级式的 transformer:通过四个Stage构建不同大小的特征图,从而掌握多尺寸的特征信息。后三个stage都是先通过一个Patch Merging层进行2倍的下采样,再通过一些 Swin Transformer block。([56,56,96]—>[28,28,192]—>[14,14,384]—>[7,7,768])
- 特征图的维度很像残差卷积网经,过每个残差阶段之后的特征图大小也是56*56、28*28、14*14,最后是7*7
- 如果是分类任务,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。[7,7,768]—>[1,768]—>[1,num_class]
- 为了和卷积神经网络保持一致,没有像 ViT 一样使用 CLS token,而是对最后的特征图使用global average polling全局池化
看完整个前向过程之后,就会发现 Swin Transformer 有四个 stage,还有类似于池化的 patch merging 操作,自注意力是在小窗口之内做的,以及最后用 global average polling,所以说 Swin Transformer 这篇论文把卷积神经网络和 Transformer 这两系列的工作完美的结合到了一起,是披着Tr
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1626
1626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









