







论文: End-to-End Object Detection with Transformers
代码:官方代码
视频:DETR 论文精读【论文精读】_哔哩哔哩_bilibili
本文参考:
DETR(DEtection TRansformer)是2020年5月发布在Arxiv上的一篇论文,可以说是近年来目标检测领域的一个里程碑式的工作。从论文题目就可以看出,DETR其最大创新点有两个:end-to-end(端到端)和 引入Transformer。
目标检测任务,一直都是比图片分类复杂很多,因为需要预测出图片中物体的位置和类别。以往的主流的目标检测方法都不是端到端的目标检测,不论proposal based的方法(R-CNN系列),anchor based 的方法(YOLO系列),还是non anchor based方法(利用角点/中心点定位),都会生成大大小小很多的预测框,需要nms(非极大值抑制)等后处理的方法去除冗余的bbox(bounding box)。正是因为需要很多的人工干预、先验知识(Anchor)还有NMS,所以整个检测框架非常复杂,难调参难优化,并且部署困难(不是所有硬件都支持NMS,普通的库不一定支持NMS需要的算子)。所以说,一个端到端的目标检测是大家一直以来梦寐以求的。
DERT很好的解决了上述问题,利用Transformer全局建模的能力,把目标检测看成集合预测的问题,不需要proposal和anchors。而且由于Transformer全局建模的能力,DETR不会输出太多冗余的边界框,输出直接对应最后bbox,不需要nms进行后处理,大大简化了模型的训练和部署。
摘要
DETR有两个创新点
- 一是新的目标函数,通过二分图匹配的方式,强制模型对每个物体生只生成一个预测框
- 二是使用Transformer的编码器解码器架构
- 使用可学习的object query替代了生成anchor的机制。DETR可以将learned object query和全局图像信息结合起来,通过不停的做注意力操作,从而使得模型直接输出最后的预测框。
- 并行预测框。因为图像中目标没有依赖关系,并行输出使得速度更快。
DETR最主要的优点就是非常简单;性能也不错,在COCO数据集可以在精度、内存、速度上和Faster RCNN基线网络打平。另外,DETR可以非常简单的拓展到其他任务上。
1.引言
end-to-end
目标检测说白了就是一个集合预测问题,然而现在都是用间接的方式,如proposal的方式(Faster R-CNN、Mask R-CNN、Cascade R-CNN),anchors方式(YOLO、Focal loss),还有no anchor based 的方法(用物体中心点的Center Net、FCOS)。这些方法会生成冗余框,就会使用nms,性能很大受制于nms操作。
DETR利用Transformer这种全局建模的能力,直接把目标检测视为集合预测问题(即给定一张图像,预测图像中感兴趣物体的集合),把之前不可学习的东西(anchor、NMS)变成可学的东西,删掉了这些依赖先验知识的部分,从而得到了一个简单有效的端到端的网络。所以DETR不需要费尽心思的设计anchor,不需要NMS后处理,也就没有那么多超参需要调,也不需要复杂的算子。
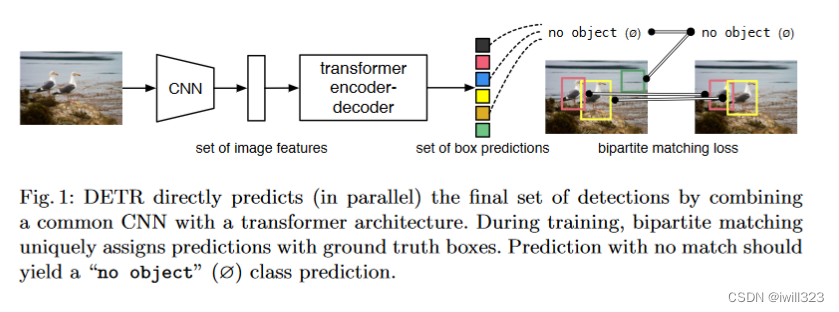
DETR训练过程
- 使用CNN网络提取图片特征
- 学习全局特征ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









