







 本文探讨了机器学习的可解释性的重要性,区分了可解释性和模型强度之间的权衡。通过实例解释了局部解释性(如Saliency Map及其局限性)和全局解释性,包括filter检测、可视化和探针技术。同时,文章指出可解释AI技术的潜在弊端,提出了Local Interpretable Model-Agnostic Explanations (LIME)作为解释复杂模型的一种方法。
本文探讨了机器学习的可解释性的重要性,区分了可解释性和模型强度之间的权衡。通过实例解释了局部解释性(如Saliency Map及其局限性)和全局解释性,包括filter检测、可视化和探针技术。同时,文章指出可解释AI技术的潜在弊端,提出了Local Interpretable Model-Agnostic Explanations (LIME)作为解释复杂模型的一种方法。
目录
改进Saliency Map——noisy gradient与SmoothGrad
Saliency Map局限性:gradient saturation(梯度饱和)
Local Interpretable Model-Agnostic Explanations (LIME)
为什么需要机器学习的可解释性?
1、我们需要知道机器做决策的背后理由,否则谁敢真正应用于实际,例如
- 银行判断要不要贷款给某一个客户,但是根据法律的规定,银行作用机器学习模型来做自动的判断,它必须要给出一个理由
- 机器学习未来也会被用在医疗诊断上,但医疗诊断人命关天的事情,需要给出诊断的理由
- 机器学习的模型帮助法官判案,帮助法官自动判案说,一个犯人能不能够被假释,
- 自驾车突然急剎的时候需要了解它急剎的理由
这些都直接作用于人类,搞清楚能决策成功的原因很重要。
2、我们可以通过这个解释性来修正我们的模型,提升模型的性能。
Interpretable VS Powerful
有一些模型在本质上是可以解释的,例如线性模型(从权重能知道特征的占比重要性),但是效果却并不厉害。深度神经网络很难解释其操作机制,因为它是黑箱,但是他却比线性模型的效果更好,我们应该努力去研究其机制的可解释性,而不是逃避黑箱模型。
那有没有一种模型同时具有可解释性和强劲力呢?决策树,一棵树能同时具备上述两个要素。决策树有很多的节点,每一个节点都会问一个问题,让你决定向左还是向右,最终当你走到 Leaf Node 的时候就可以做出最终的决定,因為在每一个节点都有一个问题,看那些问题以及答案就可以知道整个模型是如何做出最终的决断。但是在实际训练中,我们往往会用到很多棵树,这种情况也很难解释其机制。
什么叫做好的 Explanation
做机器学习的可解释性,做到什么程度?我们其实没有那麼在乎网络是怎么运行的,只要做出来的解释性是能够让人认同就行。其实对人而言,也许一个东西能不能让我们放心,能不能够让我们接受,理由是非常重要的。

好的 Explanation就是人能接受的 Explanation,人就是需要一个理由让我们觉得高兴,而到底是让谁高兴呢

explainable ML的分类
分为局部可解释性和全局可解释性,局部可解释性是针对一个特定的输入进行回答,为什么这张图片就是一只猫呢。全局可解释性是根据模型参数本身分析原因,不涉及某一具体的图片,对一个 Classifier 而言,什么样的图片叫做猫,一隻猫长什麼样子?
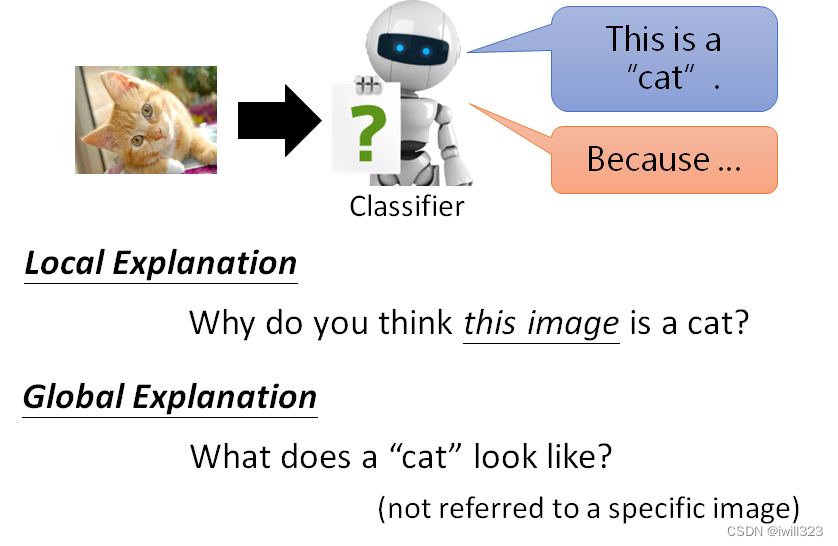
Local Explanation(局部可解释性)
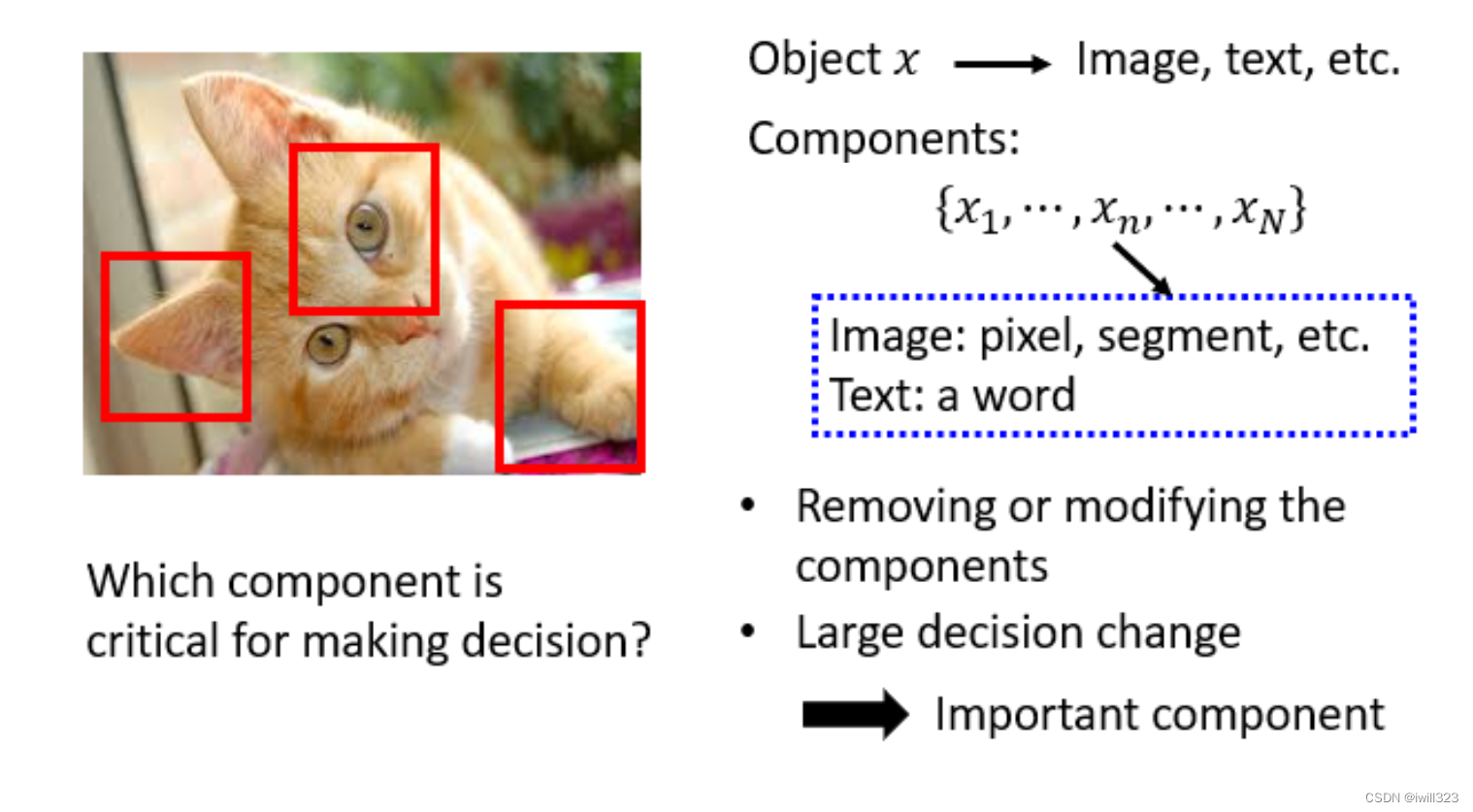
哪个元件最重要
给机器一张图片,它知道它是一只,到底是这个图片裡面的什么东西让模型觉得它是一只猫
判删除或者修改某一component,如果网络的输出发生了巨大的改变,影响最后决策结果,那么这个元件就是很重要的。
遮挡实验
研究一个影像裡面每一个区域的重要性的时候,在这个图片裡面不同的位置放上灰色的方块,当这个方块放在不同的地方的时候,Network 会 Output 不同的结果。下图灰色方块放在“红色区域”时,对输出结果影响较小,输出原类别的概率高,放在“蓝色区域”时影响较大,输出原类别的概率低。
最右边的图,机器到底是真的看到了阿富汗猎犬,还是把人误认為狗呢,可以把这个灰色的方框在这个图片上移动,然后发现这个灰色的方框放在人的脸上的时候,机器仍然觉得它有看到阿富汗猎犬,但是当你把灰色的方框放到这个位置的时候,机器就觉得它没有看到阿富汗猎犬,所以它是真的知道这一只就是阿富汗猎犬,并不是把人误认為阿富汗猎犬。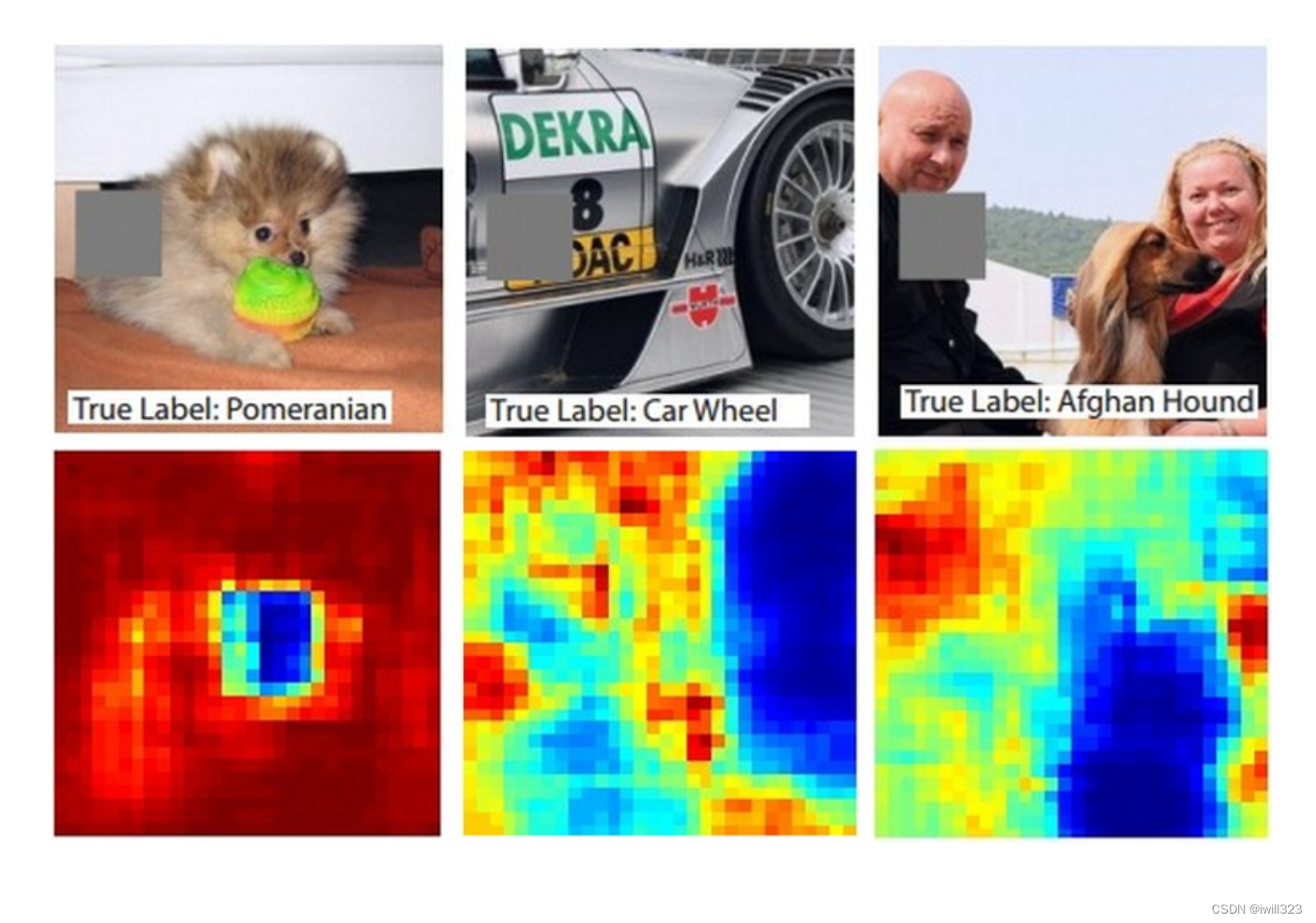
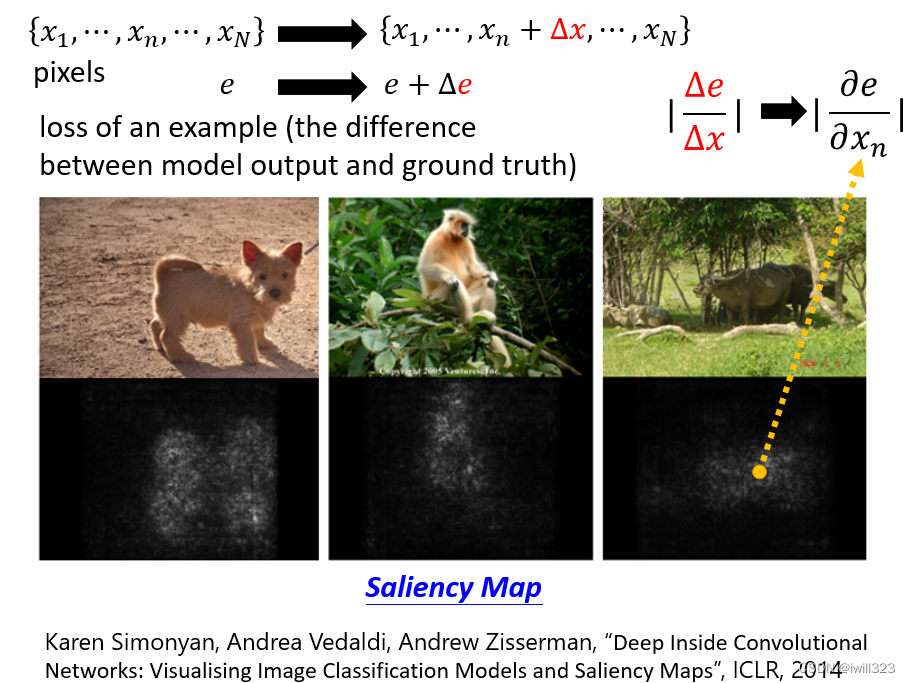
Saliency Map
Loss对图片的每个像素求导,根据导数的绝对值大小来判断像素的重要性。saliency map(显著图)中的白点越白,代表导数的值越大,该处的像素点对决策越重要。
举例来说,给机器看这个水牛的图片,并不是看到草地,也不是看到竹子,而是真的知道牛在这个位置,所以才会 Output 牛这个答案
一个真实的例子,有一个 Benchmark Corpus,叫做 PASCAL VOC 2007,裡面有各式各样的物件,机器要学习做影像的分类,机器看到这张图片,它知道是马的图片,但如果你画 Saliency Map 的话,发现左下角对马是最重要,因為左下角有一串英文,这个图库裡面马的图片很多都是来自於某一个网站,左下角都有一样的英文,所以机器看到左下角这一行英文就知道是马,根本不需要学习马是长什么样子
def normalize(image):
return (image - image.min()) / (image.max() - image.min())
# return torch.log(image)/torch.log(image.max())
def compute_saliency_maps(x, y, model):
model.eval()
x,y = x.cuda(), y.cuda()
# we want the gradient of the input x
x.requires_grad_()
y_pred = model(x)
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(y_pred, y)
loss.backward()
# saliencies = x.grad.abs().detach().cpu()
saliencies, _ = torch.max(x.grad.data.abs().detach().cpu(),dim=1)
# x shape:[10, 3, 128, 128] saliencies.shape:[10, 3, 128, 128]
# We need to normalize each image, because their gradients might vary in scale
saliencies = torch.stack([normalize(item) for item in saliencies])
return saliencies
# images, labels = train_set.getbatch(img_indices)
saliencies = compute_saliency_maps(images, labels, model)
# visualize
fig, axs = plt.subplots(2, len(img_indices), figsize=(15, 8))
for row, target in enumerate([images, saliencies]):
for column, img in enumerate(target):
if row==0:
axs[row][column].imshow(img.permute(1, 2, 0).numpy()) # 将pytorch的图片格式(channels, height, width)变为matplotlib图片格式(height, width, channels)
else:
axs[row][column].imshow(img.numpy(), cmap=plt.cm.hot) # img是单通道
plt.show()
plt.close() 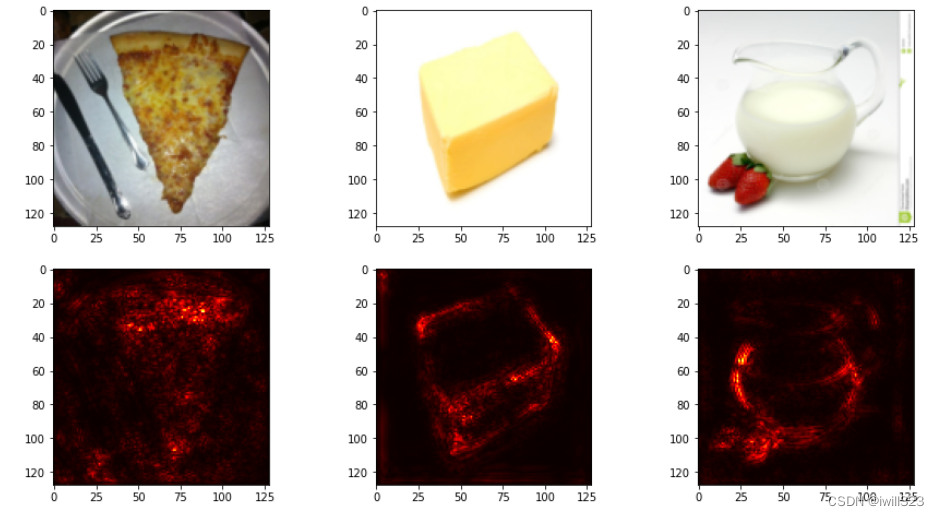
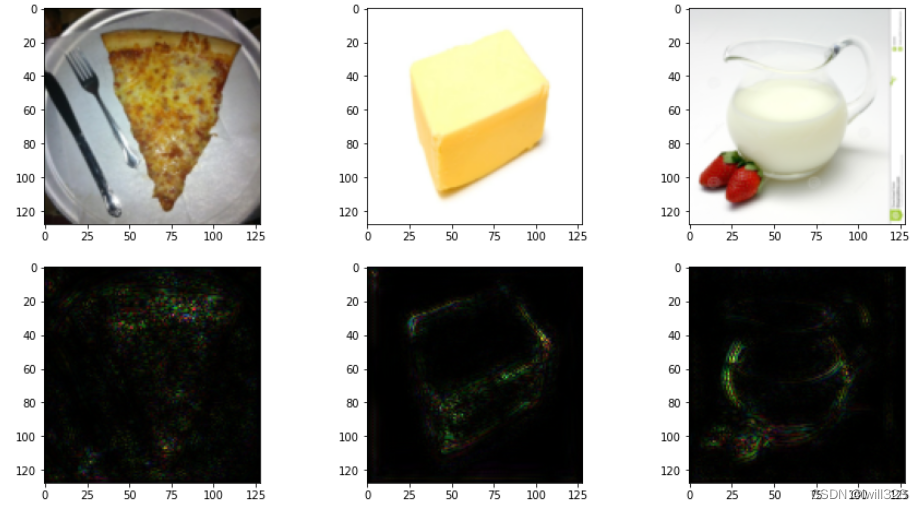
loss关于x在每个通道上都有梯度,上面的做法是在3个通道中取最大值,最终得到的是单通道图像。如果将3个通道上的梯度都保留,即saliencies = x.grad.abs().detach().cpu(),那么得到的是3通道图像,结果如下图
改进Saliency Map——noisy gradient与SmoothGrad
Saliency Map会存在杂讯梯度的问题,在未经处理的显著图(下图中间)中,白点分布杂乱无章看不出规律,通过smoothGrad方法后才减少了杂讯,这样的结果往往能够更加“集中”在被侦测的物体上。
smoothGrad:给输入的图片随机加入noise得到一系列的图片,对每个图片算saliency map后作平均,得到一個比較能抵抗 noisy gradient 的結果,这样就知道哪些
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









