







SLAM中的非线性优化和BA总结
一、非线性最小二乘问题
先考虑简单的问题:
min
x
1
2
∣
∣
f
(
x
)
∣
∣
2
2
\underset{x}{\min} \frac{1}{2}||f(x)||_{2}^{2}
xmin21∣∣f(x)∣∣221.当
f
f
f很简单时:令
d
f
d
x
=
0
\frac{df}{dx}=0
dxdf=0,将得到极值点或鞍点,比较这些解即可。
2.当
f
f
f复杂时(
f
f
f为n元函数):
d
f
d
x
\frac{df}{dx}
dxdf难求,或
d
f
d
x
=
0
\frac{df}{dx}=0
dxdf=0很难解,此时使用迭代方式来求解。
迭代的方式为:
- 给定某个初始值 x 0 x_{0} x0。
- 对于第k次迭代,寻找一个增量 Δ x k \Delta x_{k} Δxk,使得 ∣ ∣ f ( x k + Δ x k ) ∣ ∣ 2 2 ||f(x_{k}+\Delta x_{k})||_{2}^{2} ∣∣f(xk+Δxk)∣∣22达到极小值。
- 若 Δ x k \Delta x_{k} Δxk足够小,则停止。
- 否则,令 x k + 1 = x k + Δ x k x_{k+1}=x_{k}+\Delta x_{k} xk+1=xk+Δxk,返回2。
这里需要确定增量的方法(即梯度下降策略):一阶的或二阶的。首先需要对其进行泰勒展开得到:
∣
∣
f
(
x
k
+
Δ
x
k
)
∣
∣
2
2
≈
∣
∣
f
(
x
)
∣
∣
2
2
+
J
(
x
)
Δ
x
+
1
2
Δ
x
T
H
Δ
x
||f(x_{k}+\Delta x_{k})||_{2}^{2} \approx ||f(x)||_{2}^{2} +J(x)\Delta x+\frac{1}{2} \Delta x^{T}H\Delta x
∣∣f(xk+Δxk)∣∣22≈∣∣f(x)∣∣22+J(x)Δx+21ΔxTHΔx 若只保留一阶梯度:
min
Δ
x
∣
∣
f
(
x
)
∣
∣
2
2
+
J
Δ
x
\underset{\Delta x}{\min} ||f(x)||_{2}^{2} +J\Delta x
Δxmin∣∣f(x)∣∣22+JΔx,增量的方向为:
Δ
x
∗
=
−
J
T
(
x
)
\Delta x^{\ast} =-J^{T}(x)
Δx∗=−JT(x).(通常还需要计算步长),该方法称为最速下降法。
若保留二阶梯度:
Δ
x
∗
=
a
r
g
min
∣
∣
f
(
x
)
∣
∣
2
2
+
J
(
x
)
Δ
x
+
1
2
Δ
x
T
H
Δ
x
\Delta x^{\ast} =arg\min ||f(x)||_{2}^{2} +J(x)\Delta x+\frac{1}{2} \Delta x^{T}H\Delta x
Δx∗=argmin∣∣f(x)∣∣22+J(x)Δx+21ΔxTHΔx,则得到(令上式关于
Δ
x
\Delta x
Δx的导数为零):
H
Δ
x
=
−
J
T
H \Delta x=-J^{T}
HΔx=−JT该方法称为牛顿法。
最速下降法和牛顿法虽然直观,但使用当中存在一些缺点:
- 最速下降法由于过于贪婪可能导致迭代次数的增多
- 牛顿法迭代次数少,但需要计算复杂的Hessian矩阵
因此,可以通过Gauss-Newton和Levenberg-Marquadt来回避Hessian的计算。
二、理解Gauss-Newton,Levenburg-Marquadt等下降策略
Gauss-Newton
一阶近似
f
(
x
)
f(x)
f(x):
f
(
x
+
Δ
x
)
≈
f
(
x
)
+
J
(
x
)
Δ
x
f(x+\Delta x)\approx f(x)+J(x)\Delta x
f(x+Δx)≈f(x)+J(x)Δx
平方误差变为:
1
2
∣
∣
f
(
x
)
+
J
(
x
)
Δ
x
∣
∣
2
=
1
2
(
f
(
x
)
+
J
(
x
)
Δ
x
)
T
(
f
(
x
)
+
J
(
x
)
Δ
x
)
=
1
2
(
∣
∣
f
(
x
)
∣
∣
2
2
+
2
f
(
x
)
T
J
(
x
)
Δ
x
+
Δ
x
T
J
(
x
)
T
J
(
x
)
Δ
x
)
\frac{1}{2} ||f(x)+J(x)\Delta x||^{2}=\frac{1}{2}(f(x)+J(x)\Delta x)^{T}(f(x)+J(x)\Delta x) =\frac{1}{2}(||f(x)||_{2}^{2} +2f(x)^{T}J(x)\Delta x+\Delta x^{T}J(x)^{T}J(x)\Delta x)
21∣∣f(x)+J(x)Δx∣∣2=21(f(x)+J(x)Δx)T(f(x)+J(x)Δx)=21(∣∣f(x)∣∣22+2f(x)TJ(x)Δx+ΔxTJ(x)TJ(x)Δx)令关于
Δ
x
\Delta x
Δx导数为零:
2
J
(
x
)
T
f
(
x
)
+
2
J
(
x
)
T
J
(
x
)
Δ
x
=
0
2J(x)^{T}f(x)+2J(x)^{T}J(x)\Delta x=0
2J(x)Tf(x)+2J(x)TJ(x)Δx=0
J
(
x
)
T
J
(
x
)
Δ
x
=
−
J
(
x
)
T
f
(
x
)
J(x)^{T}J(x)\Delta x=-J(x)^{T}f(x)
J(x)TJ(x)Δx=−J(x)Tf(x)
记为:
H
Δ
x
=
g
H \Delta x=g
HΔx=g
G-N用J的表达式近似了H。
步骤如下:
- 给定初始值 x 0 x_{0} x0。
- 对于第k次迭代,求出当前的雅可比矩阵 J ( x k ) J(x_{k}) J(xk)和误差 f ( x k ) f(x_{k}) f(xk)。
- 求解增量方程: H Δ x k = g H \Delta x_{k}=g HΔxk=g。
- 若 Δ x k \Delta x_{k} Δxk足够小,则停止。否则,令 x k + 1 = x k + Δ x k x_{k+1}=x_{k}+ \Delta x_{k} xk+1=xk+Δxk。
Levenberg-Marquadt
Gauss-Newton简单实用,但
Δ
x
k
=
H
−
1
g
\Delta x_{k}=H^{-1}g
Δxk=H−1g当中无法保证H可逆(二次近似不可靠)。
而Levenberg-Marquadt方法一定程度上改善了它。
G-N属于线搜索方法:先找到方向,再确定长度;L-M属于信赖区域方法,认为近似只在区域内可靠。
在L-M中考虑近似程度的描述
ρ
=
f
(
x
+
Δ
x
)
−
f
(
x
)
J
(
x
)
Δ
x
\rho =\frac{f(x+\Delta x)-f(x)}{J(x)\Delta x}
ρ=J(x)Δxf(x+Δx)−f(x)即实际下降/近似下降。若太小,则减小近似范围;若太大,则增加近似范围。
LM的流程如下:
- 给定初始值 x 0 x_{0} x0,以及初始优化半径 μ \mu μ。
- 对于第k次迭代,求解: min Δ x k 1 2 ∣ ∣ f ( x k ) + J ( x k ) Δ x k ∣ ∣ 2 , s . t . ∣ ∣ D Δ x k ∣ ∣ 2 ≤ μ \underset{\Delta x_{k}}{\min} \frac{1}{2} ||f(x_{k})+J(x_{k}) \Delta x_{k}||^{2},s.t.||D\Delta x_{k}||^{2}\le \mu Δxkmin21∣∣f(xk)+J(xk)Δxk∣∣2,s.t.∣∣DΔxk∣∣2≤μ其中 μ \mu μ是信赖域的半径。
- 计算 ρ \rho ρ。
- 若 ρ > 3 4 \rho>\frac{3}{4} ρ>43,则 μ = 2 μ \mu = 2\mu μ=2μ;
- 若 ρ < 1 4 \rho<\frac{1}{4} ρ<41,则 μ = 0.5 μ \mu = 0.5\mu μ=0.5μ;
- 如果 ρ \rho ρ大于某个阈值,认为近似可行。令 x k + 1 = x k + Δ x k x_{k+1}=x_{k}+\Delta x_{k} xk+1=xk+Δxk。
- 判断算法是否收敛。如不收敛则返回2,否则结束。
在信赖域内的优化,利用拉格朗日乘子转化为无约束: min Δ x k 1 2 ∣ ∣ f ( x k ) + J ( x k ) Δ x k ∣ ∣ 2 + λ 2 ∣ ∣ D Δ x ∣ ∣ 2 \underset{\Delta x_{k}}{\min} \frac{1}{2} ||f(x_{k})+J(x_{k}) \Delta x_{k}||^{2}+\frac{\lambda }{2} ||D\Delta x||^{2} Δxkmin21∣∣f(xk)+J(xk)Δxk∣∣2+2λ∣∣DΔx∣∣2仍参照高斯牛顿法展开,增量方程为: ( H + λ D T D ) Δ x = g (H+\lambda D^{T}D)\Delta x=g (H+λDTD)Δx=g在Levenberg方法中,取D=I,则: ( H + λ I ) Δ x = g (H+\lambda I)\Delta x=g (H+λI)Δx=g LM相比于GN,能够保证增量方程的正定性,即认为近似只在一定范围内成立,如果近似不好则缩小范围;从增量方程上来看,可以看成一阶和二阶的混合,参数 λ \lambda λ控制着两边的权重,如果 λ \lambda λ为0,则为 H Δ x = g H\Delta x=g HΔx=g,即采用二阶方法牛顿法;如果 λ \lambda λ非常的大,则采用一阶方法最速下降法。
三、BA
首先,误差是什么?如何表示。BA中待优化的变量是位姿和路标点,如何求误差函数关于位姿和路标点的导数?李代数扰动模型是什么?雅可比矩阵式什么?在BA中具体由怎样的形式?
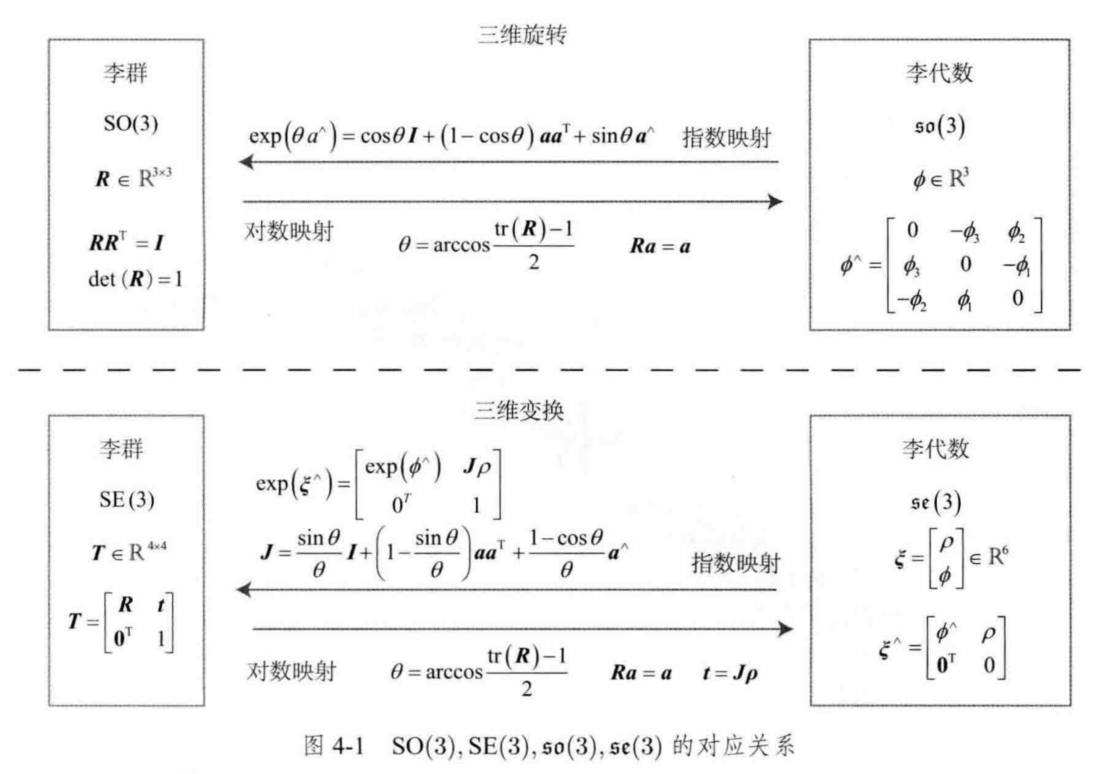
旋转矩阵群与变换矩阵群:
S
O
(
3
)
=
R
∈
R
3
×
3
∣
R
R
T
=
I
,
d
e
t
(
R
)
=
1
SO(3)={R\in \mathbb{R}^{3\times 3}|RR^{T}=I,det(R)=1}
SO(3)=R∈R3×3∣RRT=I,det(R)=1
S
E
(
3
)
=
{
T
=
[
R
T
0
T
1
]
∈
R
4
×
4
∣
R
∈
S
O
(
3
)
,
t
∈
R
3
}
SE(3)=\left \{ T=\begin{bmatrix} R & T\\ 0^{T} &1 \end{bmatrix} \in \mathbb{R}^{4\times 4} |R\in SO(3),t\in \mathbb{R}^{3}\right \}
SE(3)={T=[R0TT1]∈R4×4∣R∈SO(3),t∈R3}具有连续光滑性质的群叫做李群,存在问题:对加法不封闭,无法求导。
求导的方式有两种:
- 对R对应的李代数加上小量,求相对于小量的变化率(导数模型);
- 对R左乘或右乘一个小量,求相对于小量的李代数的变化率(扰动模型):
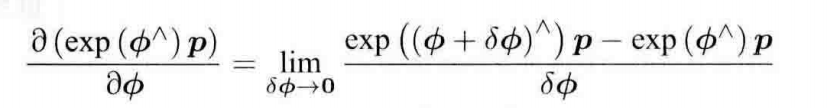
在扰动模型(左乘)中,左乘小量,令其李代数为零,得:
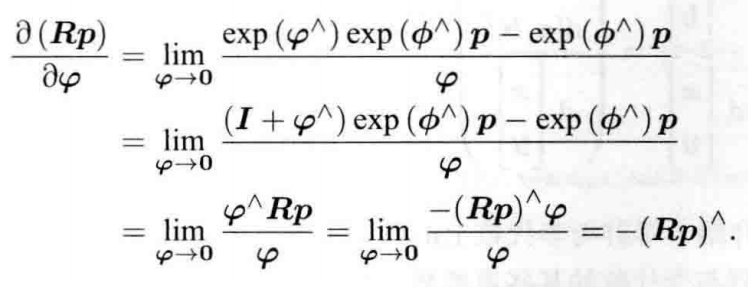
而位姿变换的导数模型为:
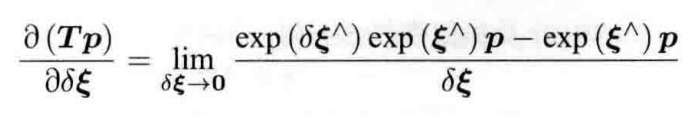

四、图优化与g2o
重投影误差:
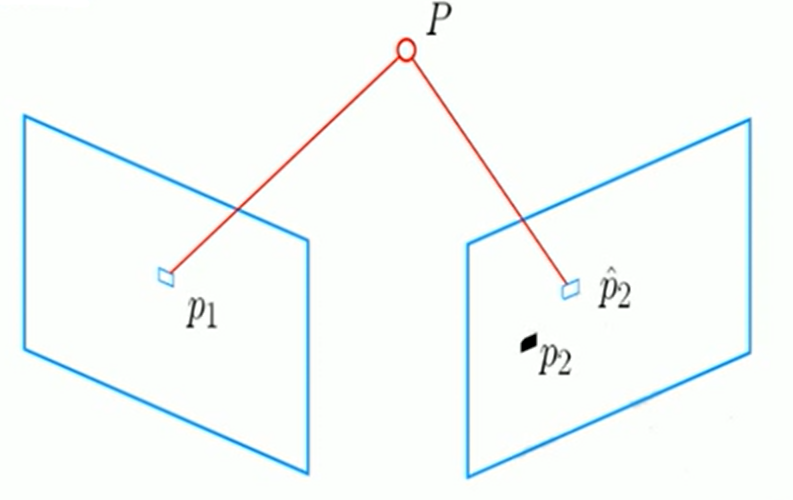
构建关于误差函数的最小二乘问题:

矩阵形式:
s
i
u
i
=
K
e
x
p
(
ξ
∧
)
P
i
s_{i}u_{i}=Kexp(\xi ^{\wedge})P_{i}
siui=Kexp(ξ∧)Pi误差函数:
ξ
∗
=
a
r
g
min
ξ
1
2
∑
i
=
1
n
∣
∣
u
i
−
1
s
i
K
e
x
p
(
ξ
∧
)
P
i
∣
∣
2
2
\xi^{*}=arg\underset{\xi }{\min}\frac{1}{2}\sum_{i=1}^{n}||u_{i}-\frac{1}{s_{i}}Kexp(\xi ^{\wedge })P_{i} ||_{2}^{2}
ξ∗=argξmin21i=1∑n∣∣ui−si1Kexp(ξ∧)Pi∣∣22把该误差函数记为
e
(
x
)
e(x)
e(x):
e
(
x
+
Δ
x
)
=
e
(
x
)
+
J
(
x
)
Δ
x
e(x+ \Delta x)=e(x)+J(x)\Delta x
e(x+Δx)=e(x)+J(x)Δx相机模型:
u
=
f
x
X
′
Z
′
+
c
x
,
v
=
f
y
Y
′
Z
′
+
c
y
u=f_{x}\frac{X'}{Z'}+c_{x},v=f_{y}\frac{Y'}{Z'}+c_{y}
u=fxZ′X′+cx,v=fyZ′Y′+cy利用扰动模型求导:




我们将求得的两项导数相乘得:
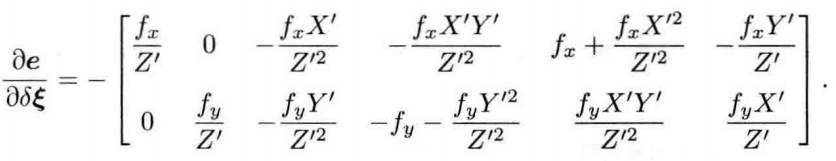
该矩阵即为我们所求得雅可比矩阵,在优化中指导着迭代的方向,使相机的位姿得到优化。
优化特征的空间点位置:



该矩阵为优化特征点空间位置时的雅可比矩阵,指导着迭代的方向。
















 2547
2547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









