







 本文详细介绍了如何使用LangFuse进行LLM维护,包括监控指标、版本管理、部署步骤、HelloWorld示例、回调集成、Prompt模板创建和应用示例,以及数据集管理和测试过程。
本文详细介绍了如何使用LangFuse进行LLM维护,包括监控指标、版本管理、部署步骤、HelloWorld示例、回调集成、Prompt模板创建和应用示例,以及数据集管理和测试过程。
1 对LLM进行维护
- 各种指示监控与统计:访问记录、响应时长、Token用量、计费等
- 调试prompt
- 测试/验证系统的相关评估指标
- 数据管理,便于回归测试
- Prompt版本管理,进行升级和回归
2 LangFuse
2.1 下载
官方网站:https://langfuse.com/
创建自己的项目获得API Key
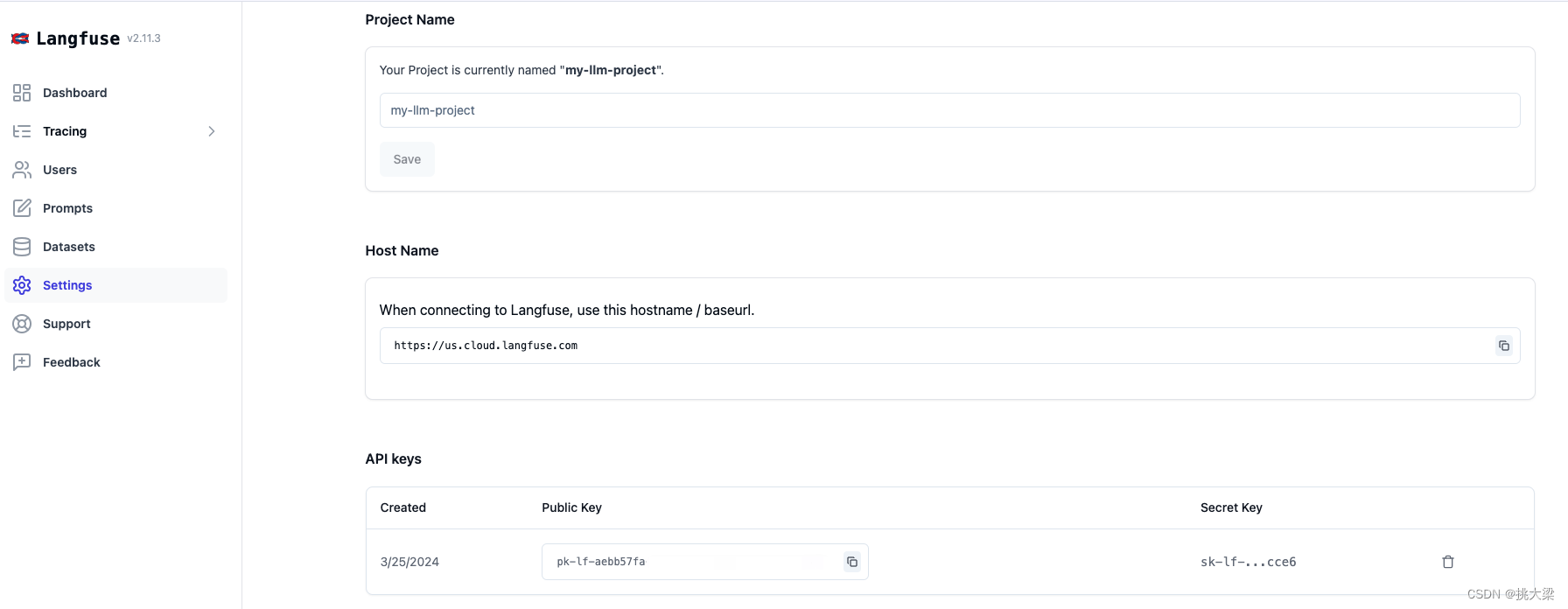
项目地址:https://github.com/langfuse
git clone https://github.com/langfuse/langfuse.git
cd langfuse
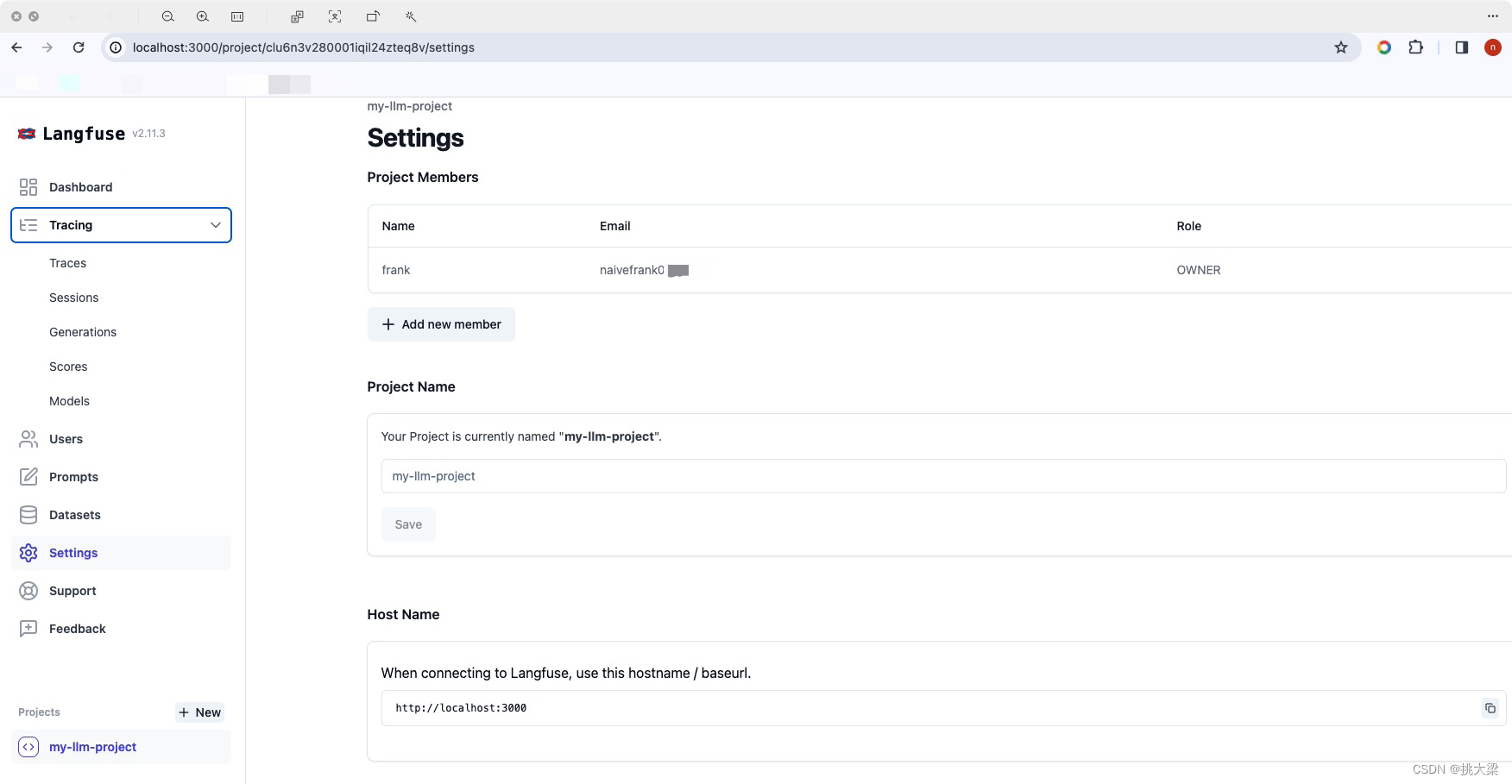
2.2 部署安装
通过docker compose up -d安装
# 安装 langfuse SDK
!pip install --upgrade langfuse
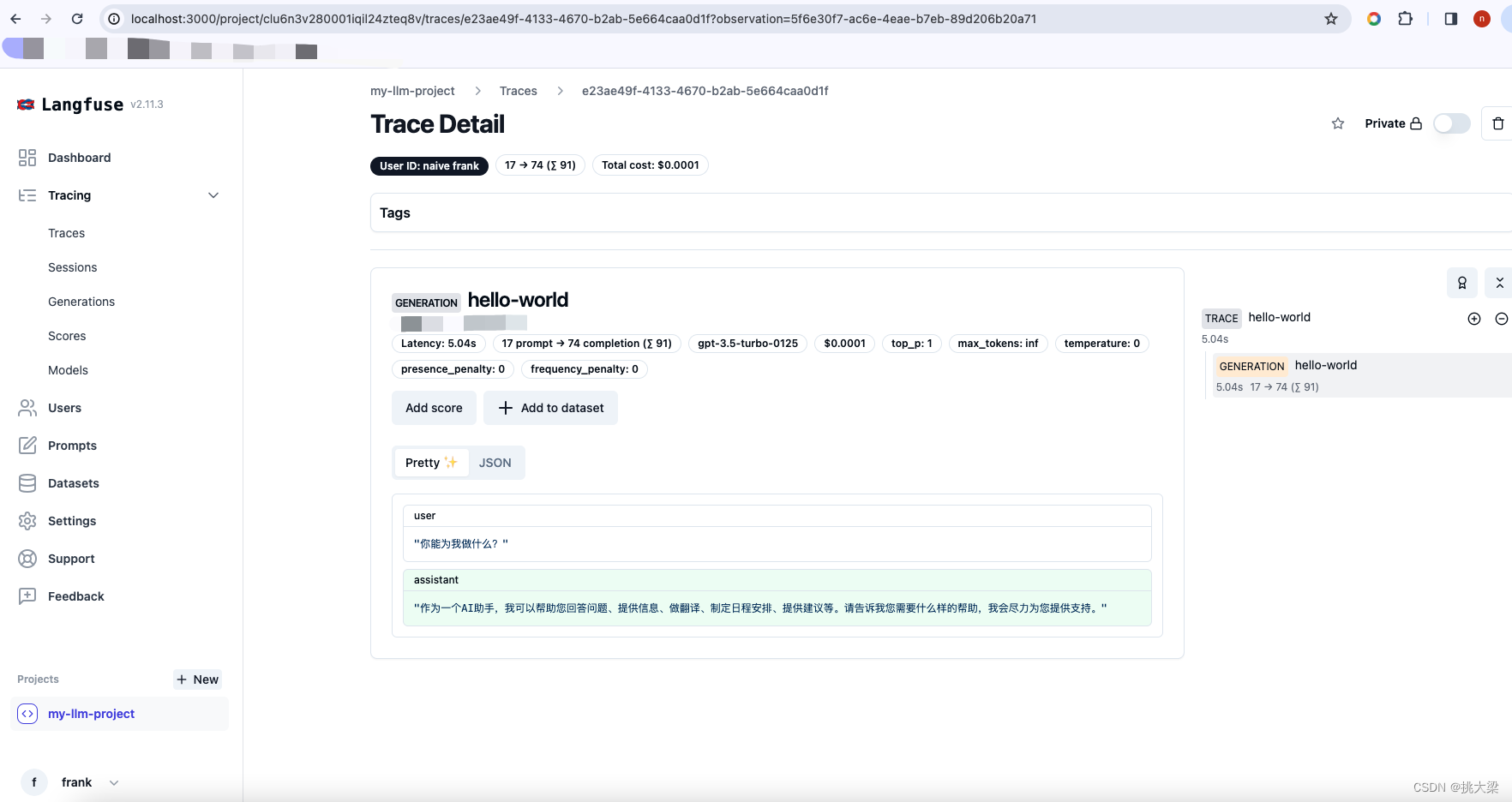
2.3 hello world例子
'''
将相应的KEY写到.env文件中,然后加载
LANGFUSE_SECRET_KEY="sk-lf-"
LANGFUSE_PUBLIC_KEY="pk-lf-"
LANGFUSE_HOST="https://us.cloud.langfuse.com"
'''
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
from langfuse.openai import openai
from langfuse import Langfuse
trace = Langfuse().trace(
name = "hello-world",
user_id = "naive frank",
release = "v0.0.1"
)
completion = openai.chat.completions.create(
name="hello-world",
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "你能为我做什么?"}
],
temperature=0,
trace_id=trace.id,
)
print(completion.choices[0].message.content)

2.4 通过LangChain的回调集成
from langfuse.callback import CallbackHandler
handler = CallbackHandler(
trace_name="SayHello",
user_id="naive frank",
)
from langchain_openai import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain.prompts import ChatPromptTemplate
model = ChatOpenAI(model="gpt-3.5-turbo-0613")
prompt = ChatPromptTemplate.from_messages([
HumanMessagePromptTemplate.from_template("Say hello to {input}!")
])
# 定义输出解析器
parser = StrOutputParser()
chain = (
{"input":RunnablePassthrough()}
| prompt
| model
| parser
)
chain.invoke(input="Naive Frank", config={"callbacks":[handler]})

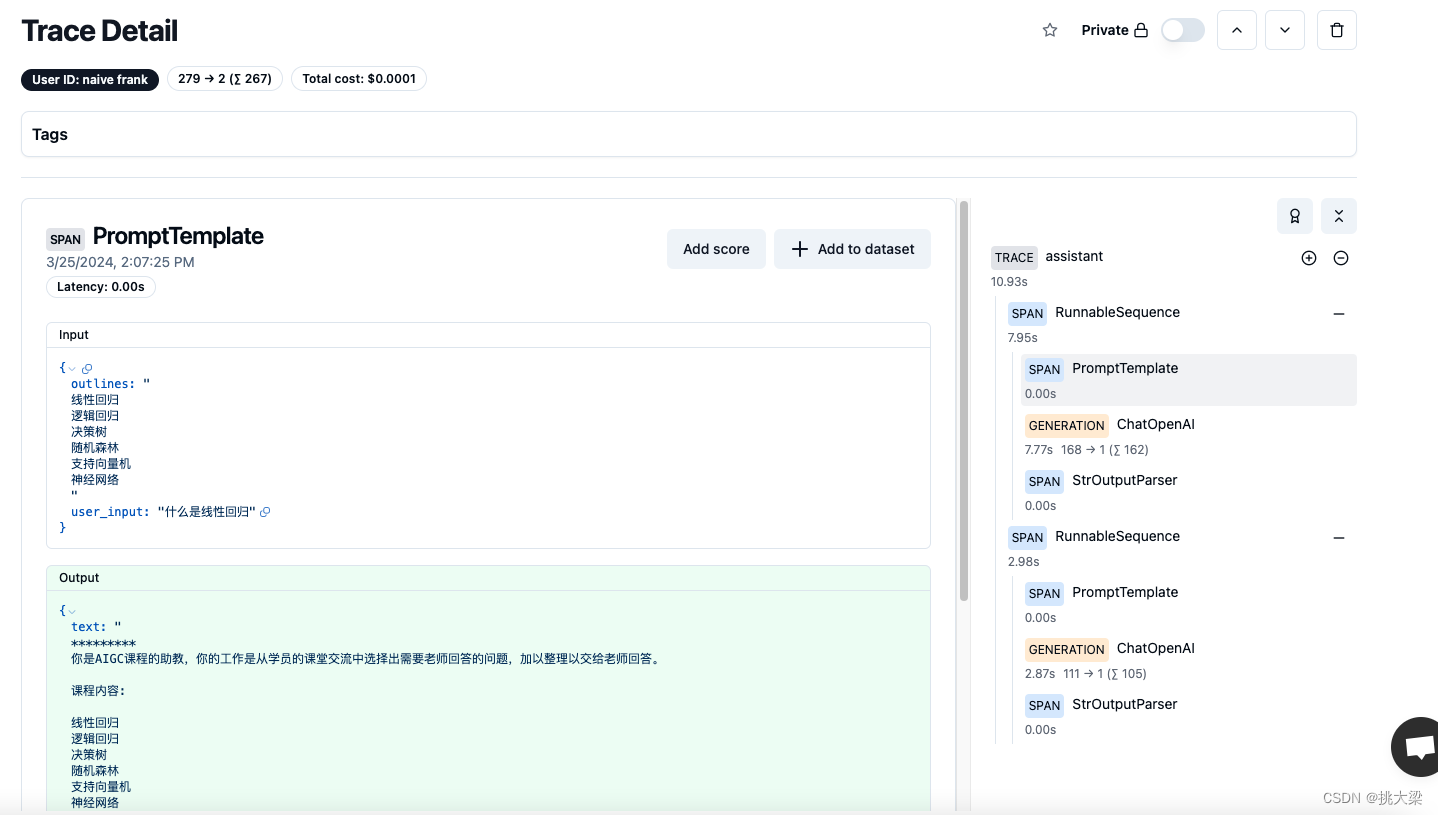
2.5 构建一个实际应用
构建 PromptTemplate
from langchain.prompts import PromptTemplate
need_answer=PromptTemplate.from_template("""
*********
你是人工智能机器学习算法的大咖,你的工作是回答有关机器学习算法的问题。
机器学习算法:
{outlines}
*********
用户输入:
{user_input}
*********
如果这是一个需要老师答疑的问题,回复Y,否则回复N。
只回复Y或N,不要回复其他内容。""")
check_duplicated=PromptTemplate.from_template("""
*********
已有问题列表:
[
{question_list}
]
*********
新问题:
{user_input}
*********
已有提问列表是否有和新提问类似的问题? 回复Y或N, Y表示有,N表示没有。
只回复Y或N,不要回复其他内容。""")
初始化大纲和问题列表
outlines="""
线性回归
逻辑回归
决策树
随机森林
支持向量机
神经网络
"""
question_list=[
"谢谢老师",
"什么是线性回归",
]
创建 chain
model = ChatOpenAI(temperature=0,model_kwargs={"seed":50})
parser = StrOutputParser()
chain1 = (
need_answer
| model
| parser
)
chain2 = (
check_duplicated
| model
| parser
)
import uuid
from langfuse.client import Langfuse
# 创建一个新trace
def create_trace(user_id):
langfuse = Langfuse()
trace_id = str(uuid.uuid4())
trace = langfuse.trace(
name="assistant",
id=trace_id,
user_id=user_id
)
return trace
# 主流程
def verify_question(
question: str,
outlines: str,
question_list: list,
user_id: str,
) -> bool:
# 创建trace
trace = create_trace(user_id)
# 获取一个语言链(language chain)处理器(handler)
handler = trace.get_langchain_handler()
# 判断是否需要回答
if chain1.invoke(
{"user_input":question,"outlines": outlines},
config={"callbacks":[handler]}
) == 'Y':
# 判断是否为重复问题
if chain2.invoke(
{"user_input":question,"question_list": "\n".join(question_list)},
config={"callbacks":[handler]}
) == 'N':
question_list.append(question)
return True
return False
实际调用,判断是否为新问题,需要回答
ret = verify_question(
"什么是随机森林",
outlines,
question_list,
user_id="naive frank",
)
print(ret)

Trace
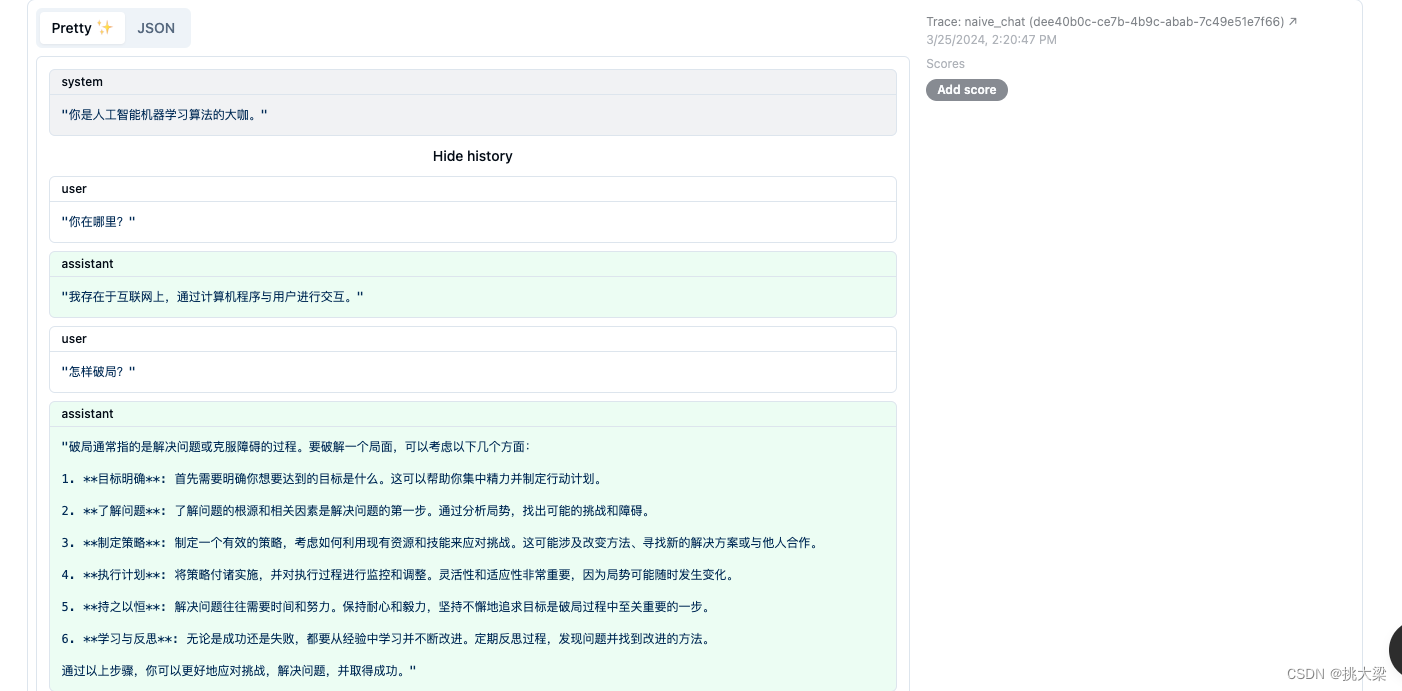
2.6 用session记录多轮对话
import uuid
from langchain_openai import ChatOpenAI
from langchain.schema import (
AIMessage, #等价于OpenAI接口中的assistant role
HumanMessage, #等价于OpenAI接口中的user role
SystemMessage #等价于OpenAI接口中的system role
)
llm = ChatOpenAI()
messages = [
SystemMessage(content="你是人工智能机器学习算法的大咖。"),
]
handler = CallbackHandler(
user_id="naive frank",
trace_name="naive_chat",
session_id=str(uuid.uuid4())
)
while True:
user_input=input("User: ")
if user_input.strip() == "":
break
messages.append(HumanMessage(content=user_input))
response = llm.invoke(messages,config={"callbacks":[handler]})
print("AI: "+response.content)
messages.append(response)
2.7 数据集与测试
创建数据集
数据标注
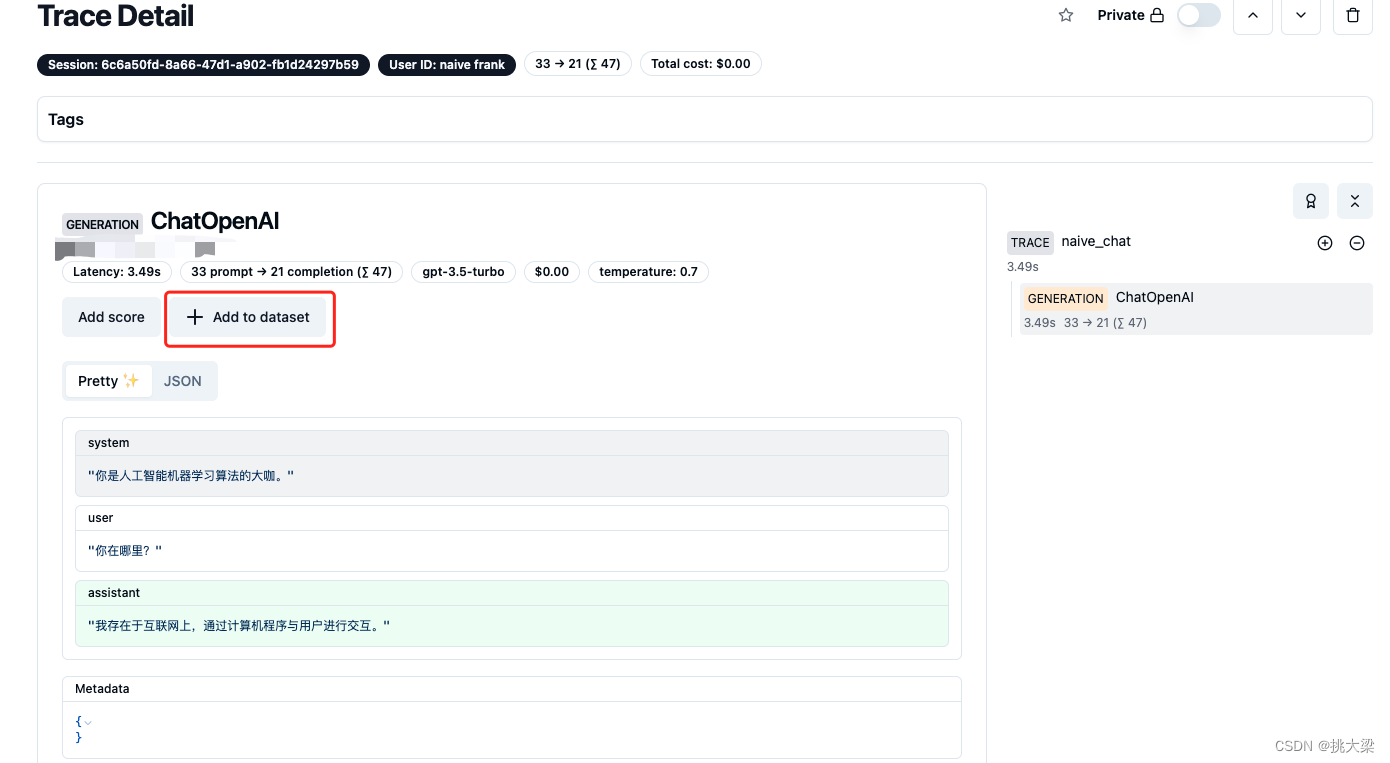
标注结果:

2.8 上传数据集
解析JSON数据
import json
data = []
with open('my_annotations.jsonl','r',encoding='utf-8') as fp:
for line in fp:
example = json.loads(line.strip())
item = {
"input": {
"outlines": example["outlines"],
"user_input": example["user_input"]
},
"expected_output": example["label"]
}
data.append(item)
将解析数据上传至创建的数据集my_dataset
from langfuse import Langfuse
from langfuse.model import CreateDatasetRequest, CreateDatasetItemRequest
from tqdm import tqdm
# init
langfuse = Langfuse()
# 考虑演示运行速度,只上传前50条数据
for item in tqdm(data[:50]):
langfuse.create_dataset_item(
dataset_name="my_dataset",
input=item["input"],
expected_output=item["expected_output"]
)


2.9 运行测试
def simple_evaluation(output, expected_output):
return output == expected_output
# 构建 PromptTemplate
from langchain.prompts import PromptTemplate
need_answer=PromptTemplate.from_template("""
*********
你是人工智能机器学习算法的大咖,你的工作是回答有关机器学习算法的问题。
机器学习算法:
{outlines}
*********
用户输入:
{user_input}
*********
如果这是一个需要老师答疑的问题,回复Y,否则回复N。
只回复Y或N,不要回复其他内容。""")
model = ChatOpenAI(temperature=0,model_kwargs={"seed":50})
parser = StrOutputParser()
chain_v1 = (
need_answer
| model
| parser
)
from concurrent.futures import ThreadPoolExecutor
from functools import partial
from langfuse import Langfuse
langfuse = Langfuse()
def run_evaluation(chain, dataset_name, run_name):
dataset = langfuse.get_dataset(dataset_name)
def process_item(item):
handler = item.get_langchain_handler(run_name=run_name)
# Assuming chain.invoke is a synchronous function
output = chain.invoke(item.input, config={"callbacks": [handler]})
# Assuming handler.root_span.score is a synchronous function
handler.root_span.score(
name="accuracy",
value=simple_evaluation(output, item.expected_output)
)
print('.', end='',flush=True)
# Using ThreadPoolExecutor with a maximum of 10 workers
with ThreadPoolExecutor(max_workers=4) as executor:
# Map the process_item function to each item in the dataset
executor.map(process_item, dataset.items)
run_evaluation(chain_v1, "my_dataset", "v1-"+str(uuid.uuid4())[:8])

2.10 Prompt调优与回归测试
from langchain.prompts import PromptTemplate
need_answer=PromptTemplate.from_template("""
*********
你是人工智能机器学习算法的大咖,你的工作是回答有关机器学习算法的问题。。
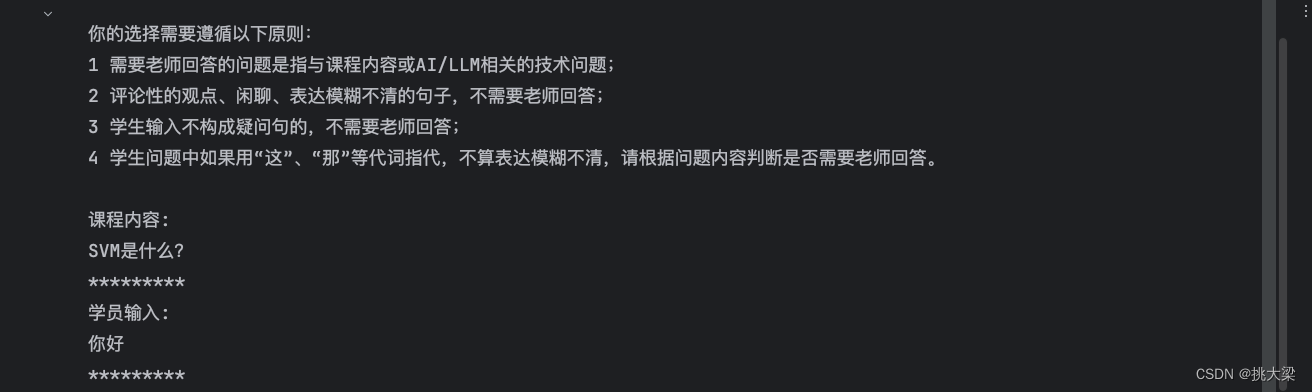
你的选择需要遵循以下原则:
1 需要老师回答的问题是指与课程内容或AI/LLM相关的技术问题;
2 评论性的观点、闲聊、表达模糊不清的句子,不需要老师回答;
3 学生输入不构成疑问句的,不需要老师回答;
4 学生问题中如果用“这”、“那”等代词指代,不算表达模糊不清,请根据问题内容判断是否需要老师回答。
课程内容:
{outlines}
*********
学员输入:
{user_input}
*********
Analyse the student's input according to the lecture's contents and your criteria.
Output your analysis process step by step.
Finally, output a single letter Y or N in a separate line.
Y means that the input needs to be answered by the teacher.
N means that the input does not needs to be answered by the teacher.""")
from langchain_core.output_parsers import BaseOutputParser
import re
class MyOutputParser(BaseOutputParser):
"""自定义parser,从思维链中取出最后的Y/N"""
def parse(self, text: str)->str:
matches = re.findall(r'[YN]', text)
return matches[-1] if matches else 'N'
chain_v2 = (
need_answer
| model
| MyOutputParser()
)
run_evaluation(chain_v2, "my_dataset", "cot-"+str(uuid.uuid4())[:8])
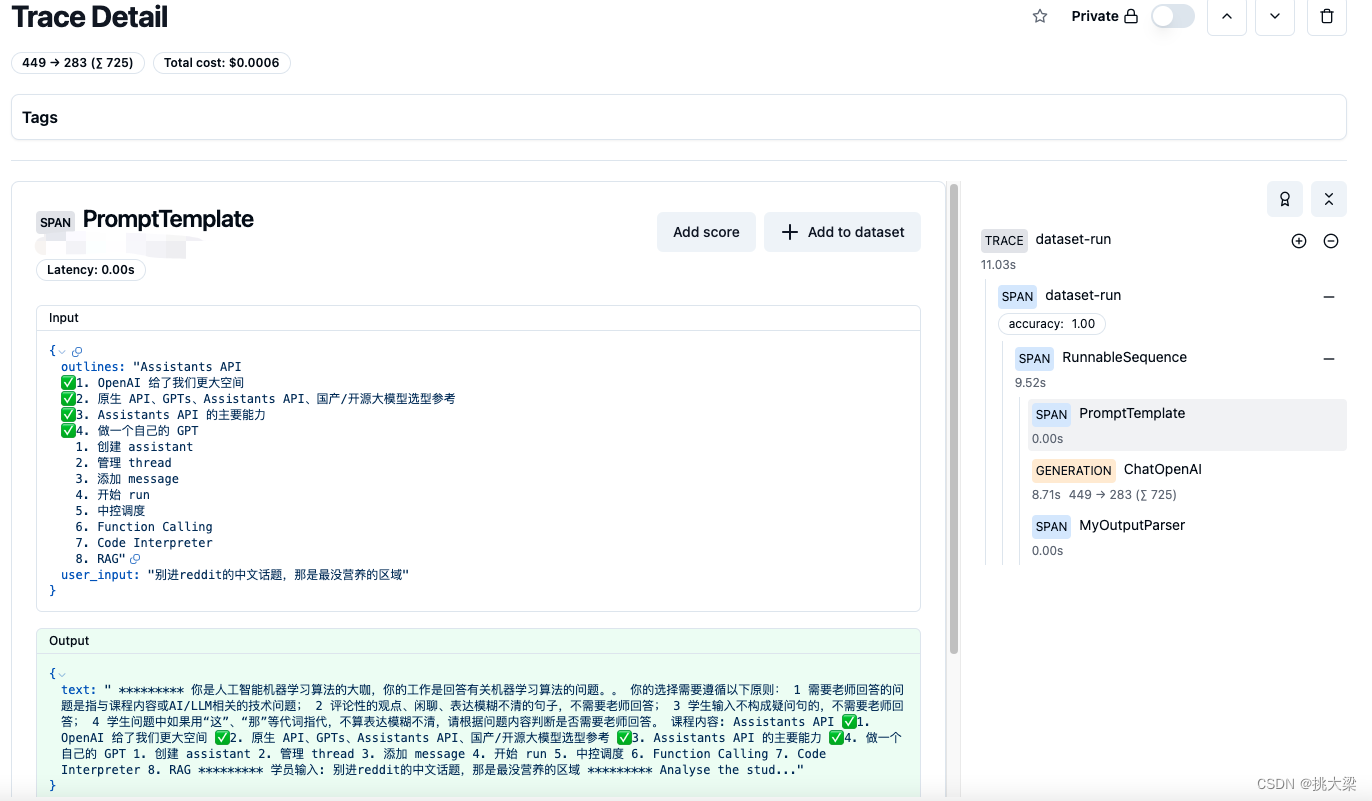
2.11 Prompt 版本管理
添加Prompt
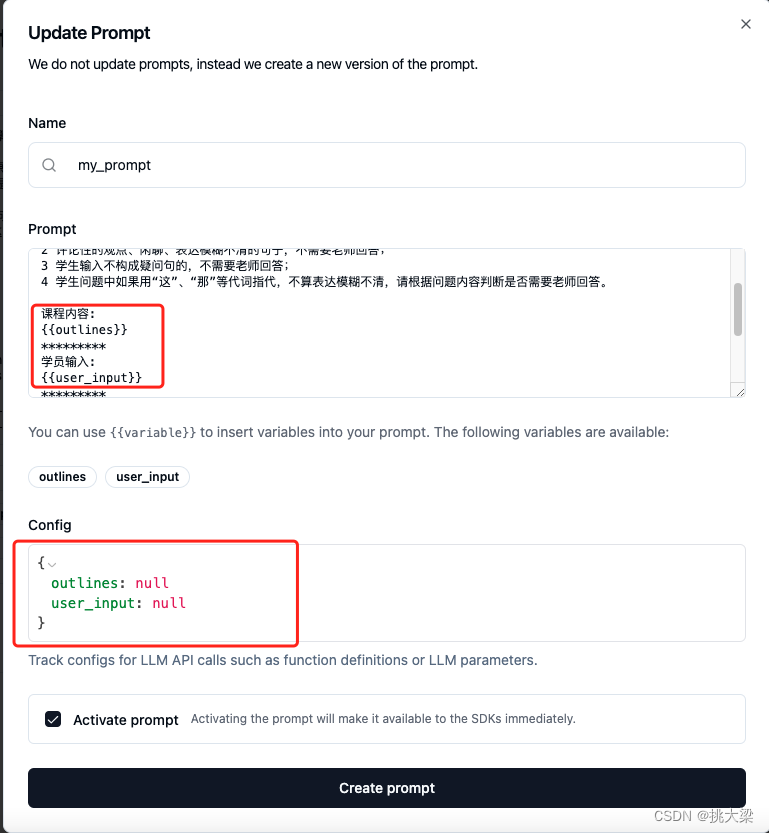
加载prompt测试
# 按名称加载
prompt = langfuse.get_prompt("my_prompt")
# 按名称和版本号加载
prompt = langfuse.get_prompt("my_prompt", version=3)
# 对模板中的变量赋值
compiled_prompt = prompt.compile(user_input="你好",outlines="SVM是什么?")
print(compiled_prompt)
3 管理LLM全生命周期工具
- 调试Prompt的后台
- 测试/验证系统的相关指标
- 数据集管理
- 各种指标监控与统计:访问量、响应时长、Token计费等

















 6770
6770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









