






遇到知识库上传文档失败,各种报错,然后网络搜索,好多解决方案都是收费的,也看不到也不知道行不行。
这里整理下自己使用的几种方法。
特此留档记录,防止忘记。
1. 使用ollama下载安装向量化工具
nomic-embed-text
Ubuntu环境下,命令行输入
ollama pull nomic-embed-text
open-webui管理员面板,进入“设置”栏找到“模型”选项,并点击右上角的设置图标进行模型设置,


把deepseek和刚下载的nomicembed-text排序在前,
并选择默认模型为deepseek:
embed-text,点击保存:
管理员面板找到“文档”选项,将“语义向量模型引擎”设置为Ollama,并且在“语义向量模型”手动输入“Nomic-Embed-Text”,设置完点击保存,
这里有个错误,应该是输入模型里的全称例如 XXX:latest

确保open-webui识别到Ollama,进一步找到“外部连接”选项,只勾选Ollama API而不勾选OpenAI API

bga-m3向量模型
方法和nomic-embed-text类似
ollama pull nomic-embed-text
管理员面板找到“文档”选项,将“语义向量模型引擎”设置为Ollama,并且在“语义向量模型”手动输入“bga-ma:latest”,设置完点击保存,图例参考上面的。
2.PDF文件无法处理问题修复
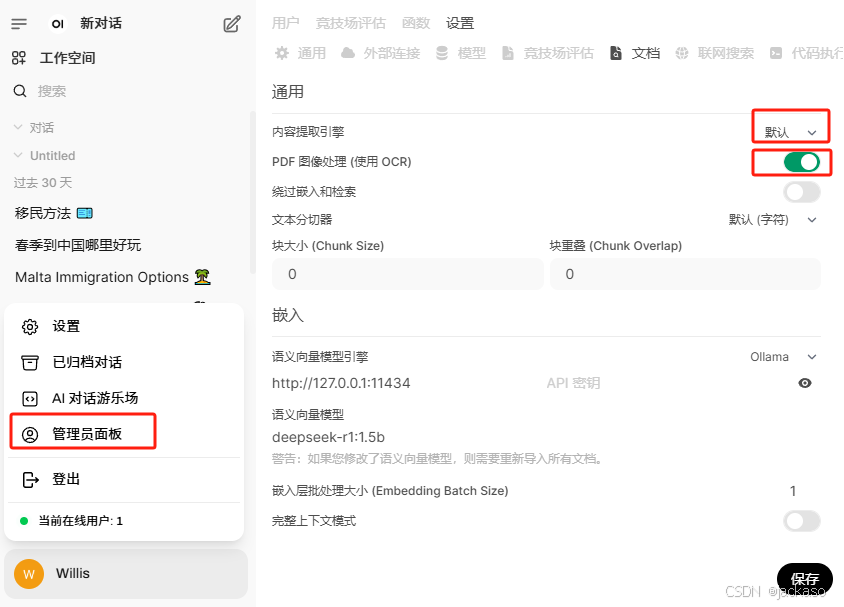
管理员面板->设置->文档
内容提前引擎,选择默认,pdf图像处理开发打来
源码部署还需要安装一些库文件
在backend目录下执行
pip install rapidocr-onnxruntime
apt-get install mesa-utils
安装上这俩,基本上没有问题了
3. Dimensionality of (1024) does not match index dimensionality (384)
这个问题,搜索好久都没有好的解决办法,要么就是说的高深莫测的专业术语,看的迷迷糊糊,只是原理上说下,不给实际的解决方法。无意中弄好了,大家可以尝试下。就是重置数据库,不过有风险,之前存储的文档都会丢失。
主要的原因是,切换向量模型,不同的向量模型使用的维度不同,导致数据库存储时出现差异,不能保存导致的错误。
管理员面板找到“文档”选项,拉倒最下面,点击“重置上传目录”、“重置向量存储/知识”右面的重置按钮,设置完点击保存,

重置后,基本上解决向量维度错误的问题。
4. PDF上传报“ Extracted content is not available for this file. Please ensure that the file is processed before proceeding”错问题

一般是解析不了当前pdf,大概率是编码问题。
可以使用第三方工具转换成Word文档再上传。
推荐方式 转换成OCR PDF格式
下面网站可以在线转换:
iLovePDF | 为PDF爱好者提供的PDF文件在线处理工具
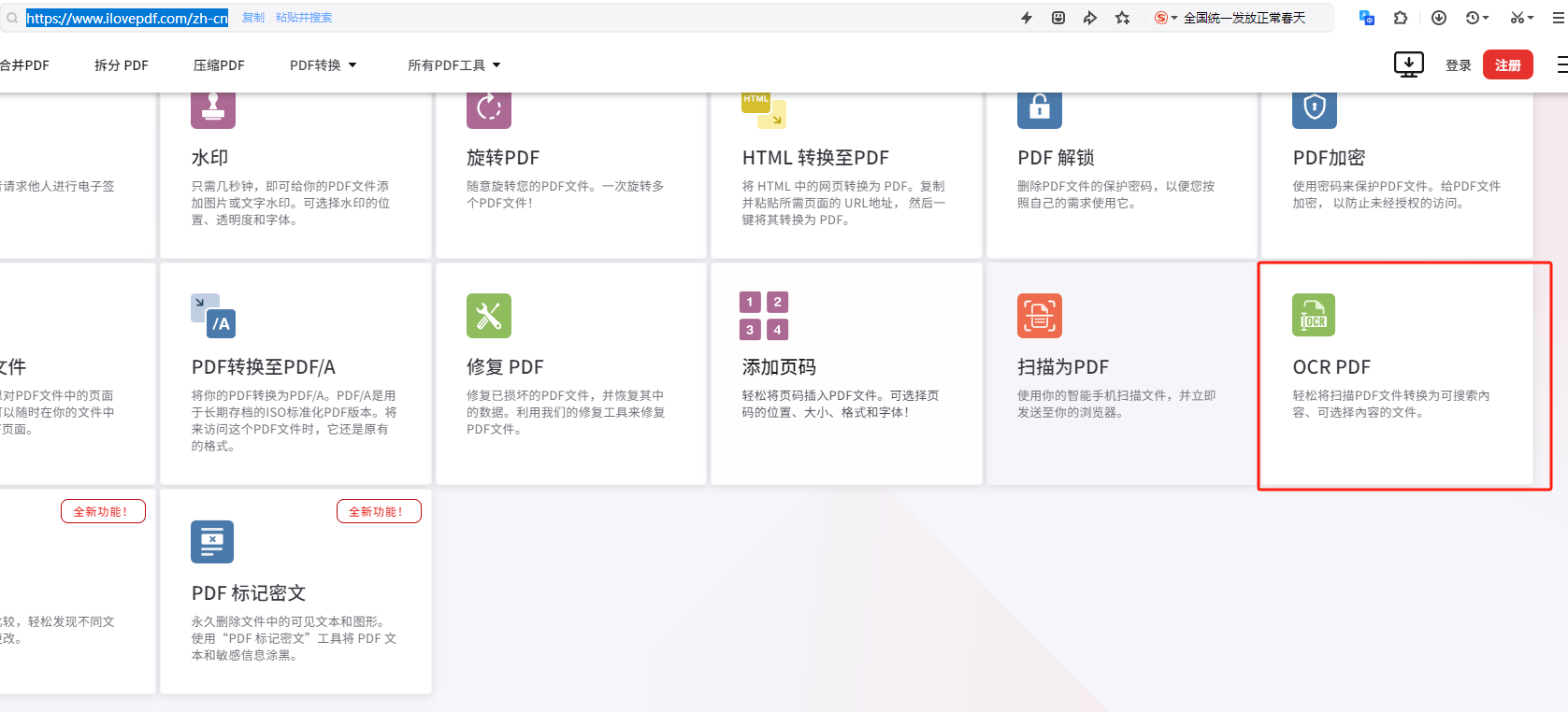
使用在线工具转换成OCR PDF ,然后再次上传,解决问题

















 7602
7602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









