






前置工具:
Ollama 下载地址 https://ollama.com/download
AnythingLLM 下载地址 https://useanything.com/download
Open WebUI 安装地址 https://github.com/v1cc0/open-webui
具体搭建步骤:
1、安装完成ollama后,在win键界面找到命令行,或者win键 + R,输入cmd打开命令行。
安装Ollama工具后,在命令行输入【ollama pull qwen:4b】 下载模型(也可以下载其他模型,支持的模型列表:https://ollama.com/library)。
2、要开始运行Ollama,只需要在命令行输入【ollama run qwen:4b】就可以使用并访问这个模型了。
3、接下来我们需要安装向量模型和数据库,在https://ollama.com/里面搜索【nomic-embed-text】,这个模型可以将文本内容转换成向量数据,里面是模型介绍。
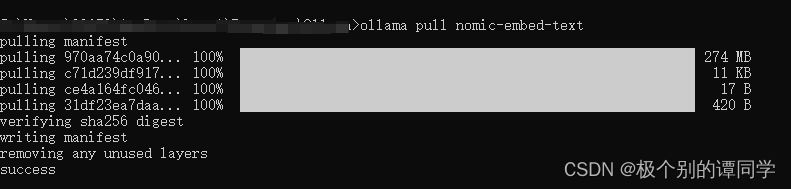
4、安装模型可以在命令行输入【ollama pull nomic-embed-text】进行下载和安装。
5、安装AnythingLLM工具后打开初始化界面,会进入到配置页面,在【LLM Preference】选项卡中,选择Ollama,然后配置【http://127.0.0.1:11434】、选择运行的大模型【qwen:4b】,token填【8192】
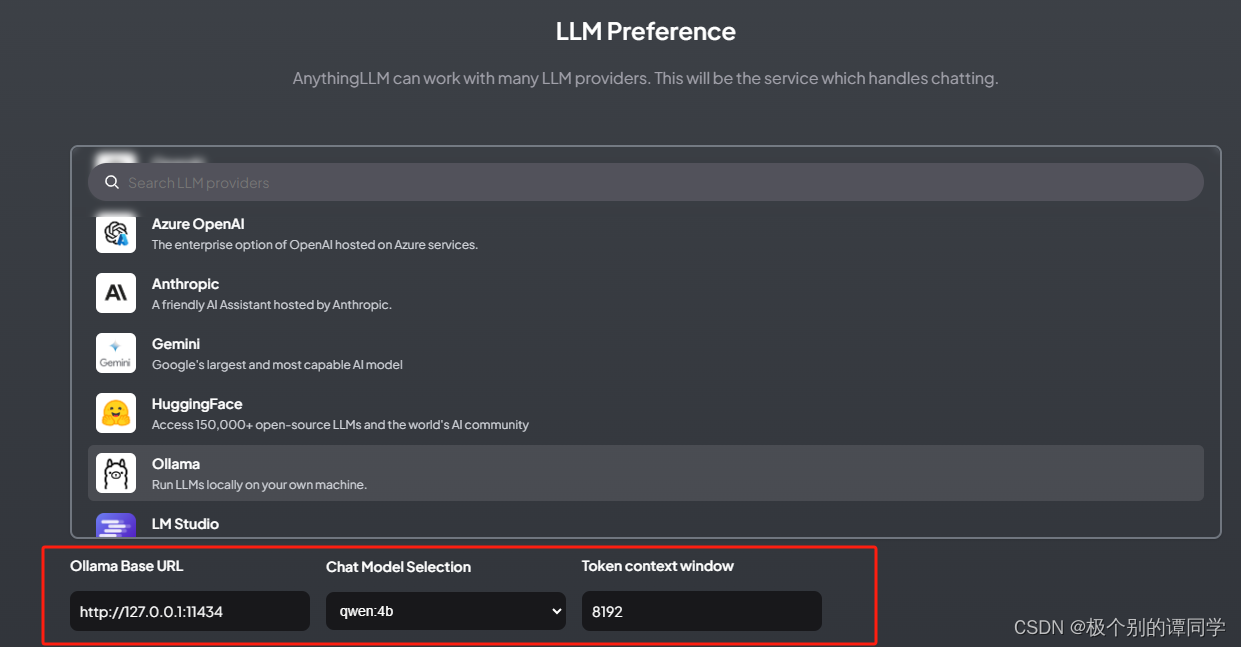
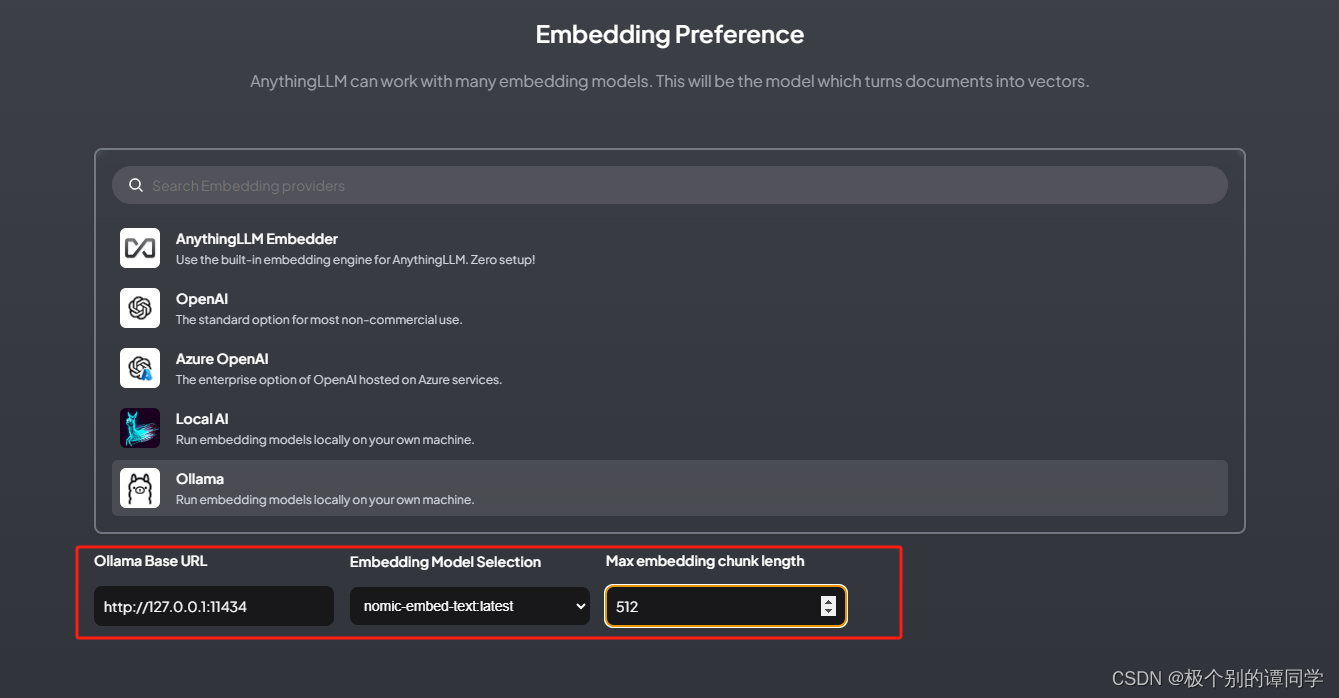
6、下一步是配置【Embedding Preference】选项卡中,一样选择 Ollama,然后配置【http://127.0.0.1:11434】、选择运行的大模型【nomic-embed-text】,length填【512】
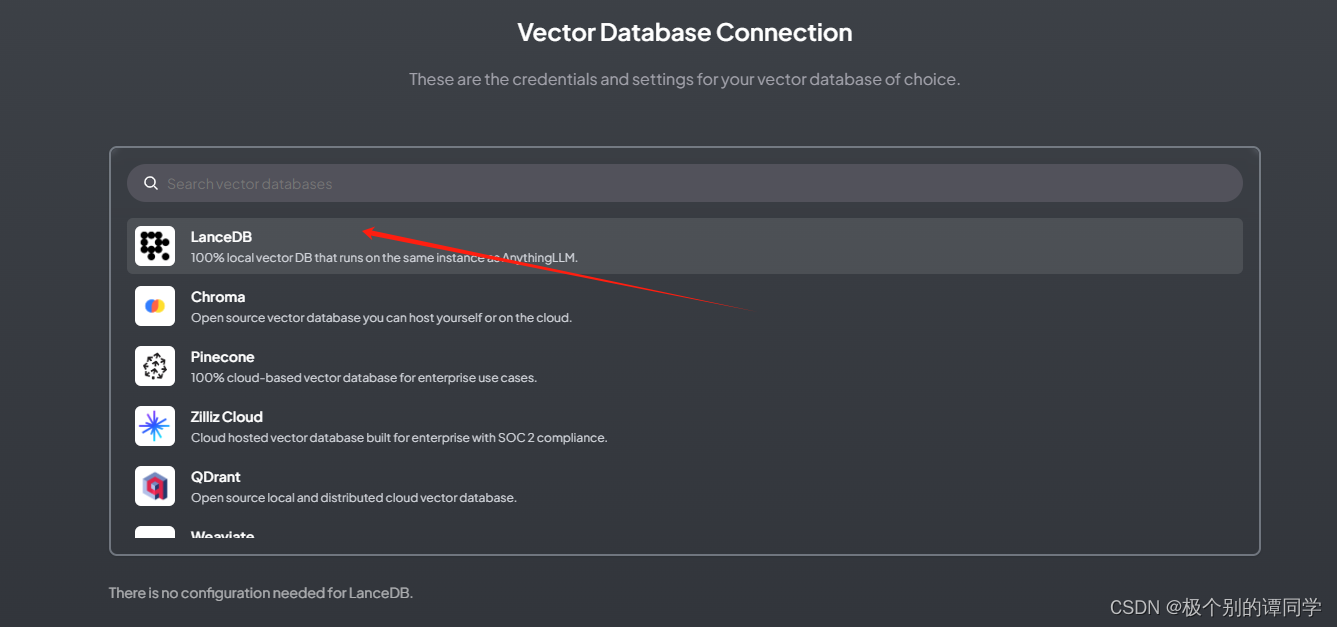
7、下一步是配置【Vector Database】,选择默认的【LanceDB】,这是内置的向量数据库,如果想用云端数据库,可以选择【Pinecone】进行云端配置。
8、后面就是按提示下一步下一步,如果是要加新的工作空间,可以点new workspace来增加不同场景下的工作空间。如果需要更换模型,可以点左下角的配置按钮,重新执行上面三步完成配置。到这里环境已经部署了,这时你已经可以跟大模型进行对话了。
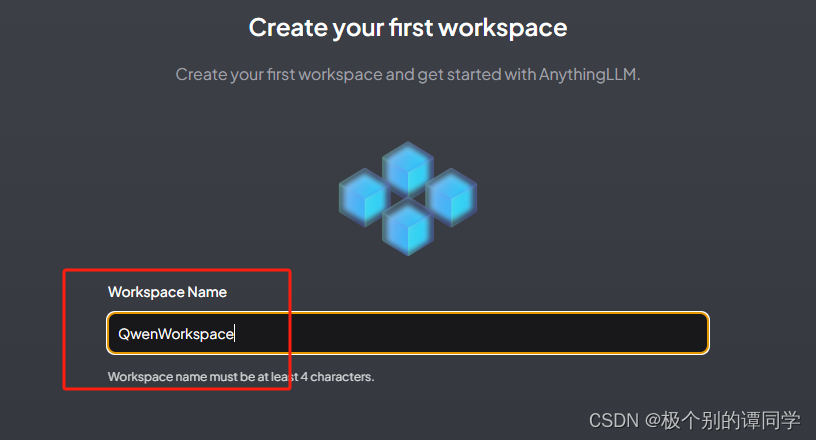
9、接下来的步骤是争对私有知识库的内容进行分析和获取。需要将文档上传到AnythinLLM,通过【nomic-embed-text】模型进行向量转换,然后存在向量数据库中。最后通过提问,去向量数据库获取内容并分析回答。
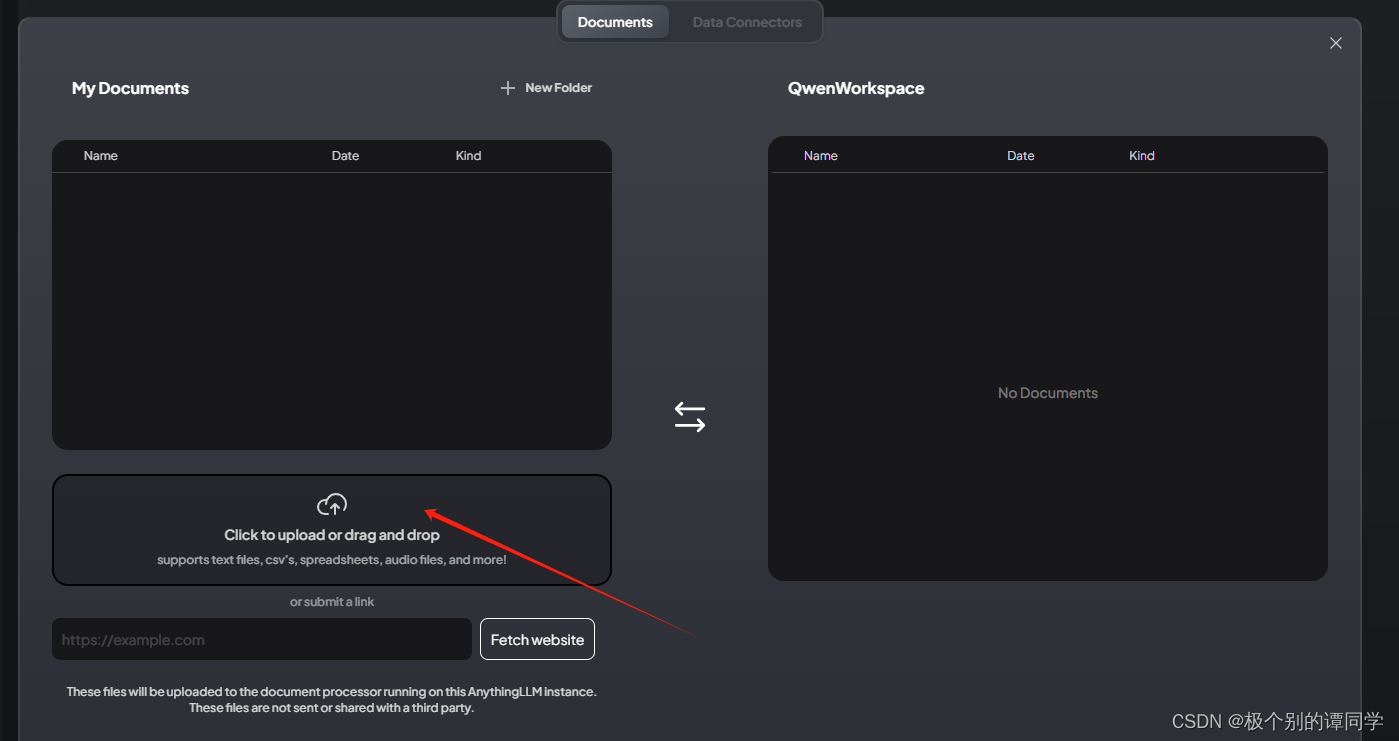
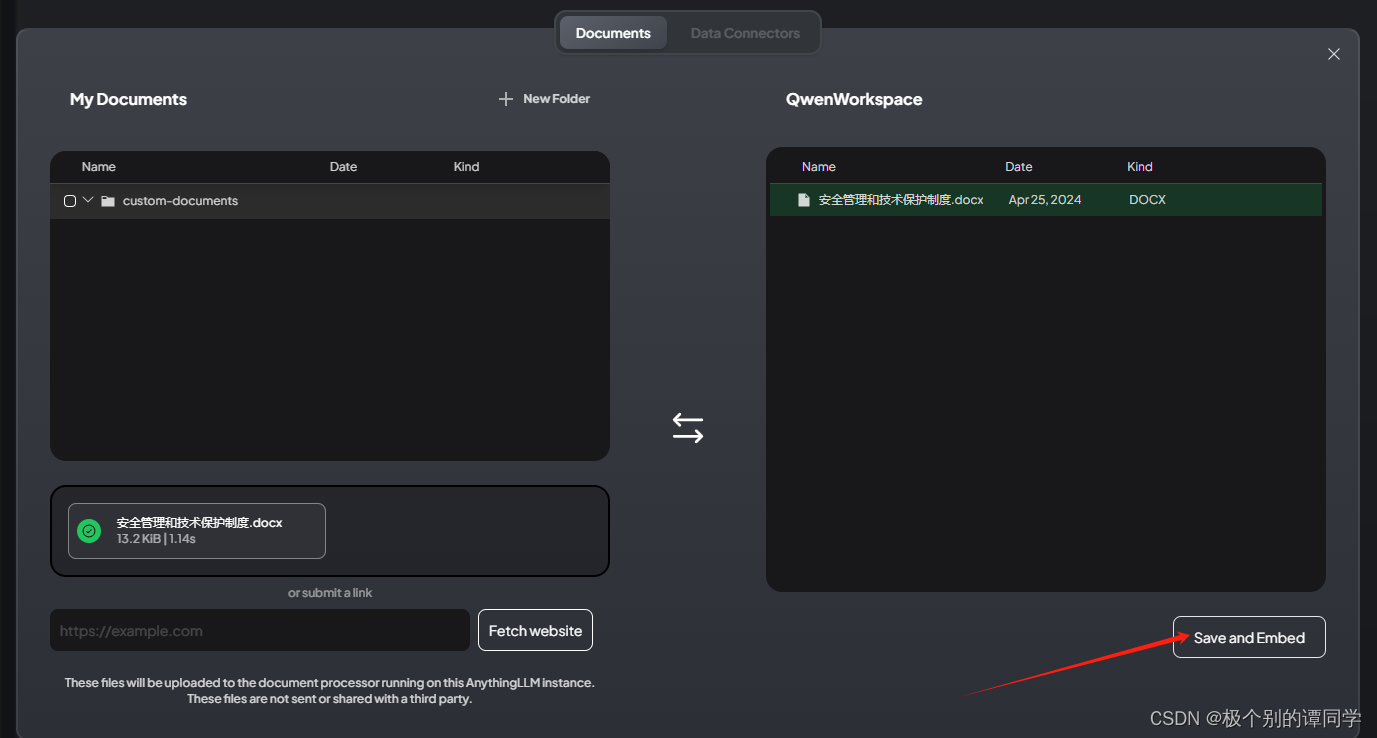
在工作空间页面上有一个上传文档的按钮,点击可以上传我们的文档内容。上传后选中文档,点击【Save and Embed】,等待一段时间,让模型进行向量转换和保存。
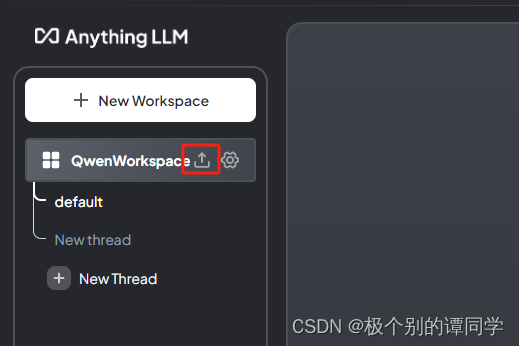
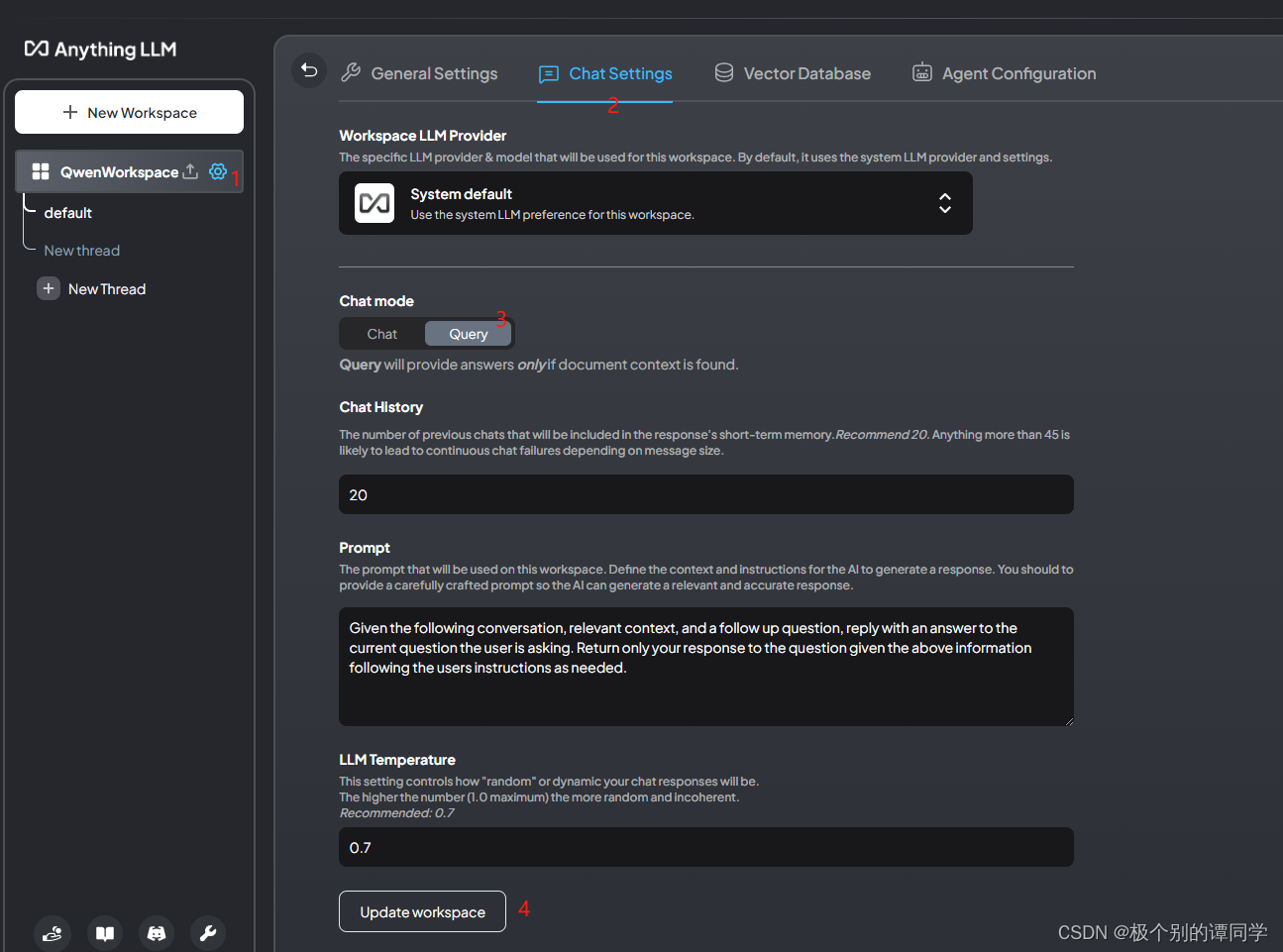
10、然后回到主界面点击工作空间的设置,选择【Chat Setting】选项卡,这里对话模式选择【Query】,这个模式是指只从提供的文档内容进行查找分析,而不要求大语言模型里面提供的信息作答。最后点击【Update workspace】进行更新。
然后就可以进行提问了,以上是本地部署应用的地方,如果你的电脑不太行,可以装Ollama部署在云端GPU服务器,然后本地安装AnythingLLM,在选择URL上填写云端Ollama的地址即可。
11、第三个工具就是Open WebUI,此工具可以支持云端部署web界面,在浏览器上访问大模型。
前置需要安装Docker,具体安装步骤可以看https://github.com/v1cc0/open-webui上面的安装步骤,这里就不再赘述。
安装完后输入github上的指令即可连通Ollama,并进行使用。


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











