







题目:batch gradient descent和stochastic/incremental gradient descent
由于斯坦福机器学习公开课的影响力,网上已有各种解析文章,但当我想找个程序时却没有搜索到,因此这里不再去谈具体内容,只给出个人编写的matlab代码。
下面给出batch gradient descent和stochastic/incremental gradient descent算法的代码,内容对应公开课资料中的“讲义”文件夹下的《notes1.pdf》的前7页。
1、batch gradient descent(只有一个变量)
%batch gradient descent with one variable
%h_theta(x) = theta0 + theta1*x1
clc;clear all;close all;
%初始化training set
x = 1:10;
m = length(x);%training set中training example个数
y = x + 0.5*randn(1,m);
%初始化learning rate,此值不能太大
alpha = 0.0005;
%初始化parameters(also called weights)
theta0 = 0;
theta1 = 0;
%将training set画出来
figure;plot(x,y,'x');
%将training set画出来
figure;plot(x,y,'kx','linewidth',2);hold on;
kk = 0;
while 1
htheta = theta0 + theta1*x;%由线性函数h所预测的y
plot(x,htheta);
%求迭代公式求和号项
sum_t0 = 0;
sum_t1 = 0;
for ii = 1:m
sum_t0 = sum_t0 + (y(ii)-htheta(ii))*1;%letting x0=1
sum_t1 = sum_t1 + (y(ii)-htheta(ii))*x(ii);
end
%计算新的theta0和theta1
theta0_t = theta0 + alpha * sum_t0;
theta1_t = theta1 + alpha * sum_t1;
%更新theta0和theta1
theta0 = theta0_t;
theta1 = theta1_t;
%以下为收敛性判断
kk = kk + 1;
htheta_n = theta0 + theta1*x;
h_err = (htheta_n - htheta)*(htheta_n - htheta)';
%迭代两次差别很小时
if h_err<1e-6
break;
end
%防止不收敛造成死循环
if kk>1000%迭代1000次还不收敛则跳出循环
break;
end
end
htheta = theta0 + theta1*x;
plot(x,htheta,'r','linewidth',3);
xlim([1 10]);ylim([1 10]);
hold off;2、stochastic/incremental gradient descent(只有一个变量)
%stochastic/incremental gradient descent with one variable
%h_theta(x) = theta0 + theta1*x1
clc;clear all;close all;
%初始化training set
x = 1:10;
m = length(x);%training set中training example个数
y = x + 0.5*randn(1,m);
%初始化learning rate,此值不能太大
alpha = 0.001;
%初始化parameters(also called weights)
theta0 = 0;
theta1 = 0;
%将training set画出来
figure;plot(x,y,'x');
%将training set画出来
figure;plot(x,y,'kx','linewidth',2);hold on;
kk = 0;
while 1
htheta = theta0 + theta1*x;
plot(x,htheta);
for ii = 1:m
htheta_ii = theta0 + theta1*x(ii);%由线性函数h所预测的y
theta0 = theta0 + alpha * (y(ii)-htheta_ii)*1;%letting x0=1
theta1 = theta1 + alpha * (y(ii)-htheta_ii)*x(ii);
end
%以下为收敛性判断
kk = kk + 1;
htheta_n = theta0 + theta1*x;
h_err = (htheta_n - htheta)*(htheta_n - htheta)';
%迭代两次差别很小时
if h_err<1e-6
break;
end
%防止不收敛造成死循环
if kk>1000%迭代1000次还不收敛则跳出循环
break;
end
end
htheta = theta0 + theta1*x;
plot(x,htheta,'r','linewidth',3);
hold off;3、batch gradient descent(有两个变量)
%batch gradient descent with two variable
%h_theta(x) = theta0 + theta1*x1 + theta2*x2
clc;clear all;close all;
%初始化training set
x1 = 1:10;x2=x1;
m = length(x1);%training set中training example个数
y = x1 + 0.5*randn(1,m);
%初始化learning rate,此值不能太大
alpha = 0.001;
%初始化parameters(also called weights)
theta0 = 0;
theta1 = 0;
theta2 = 0;
%将training set画出来
figure;plot3(x1,x2,y,'x');xlabel('x1');ylabel('x2');grid;
%将training set画出来
figure;plot3(x1,x2,y,'x','linewidth',2);hold on;
kk = 0;
while 1
htheta = theta0 + theta1*x1 + theta2*x2;%由线性函数h所预测的y
plot3(x1,x2,htheta);
%求迭代公式求和号项
sum_t0 = 0;
sum_t1 = 0;
sum_t2 = 0;
for ii = 1:m
sum_t0 = sum_t0 + (y(ii)-htheta(ii))*1;%letting x0=1
sum_t1 = sum_t1 + (y(ii)-htheta(ii))*x1(ii);
sum_t2 = sum_t2 + (y(ii)-htheta(ii))*x2(ii);
end
%计算新的theta0和theta1和theta2
theta0_t = theta0 + alpha * sum_t0;
theta1_t = theta1 + alpha * sum_t1;
theta2_t = theta2 + alpha * sum_t2;
%更新theta0和theta1和theta2
theta0 = theta0_t;
theta1 = theta1_t;
theta2 = theta2_t;
%以下为收敛性判断
kk = kk + 1;
htheta_n = theta0 + theta1*x1 + theta2*x2;
h_err = (htheta_n - htheta)*(htheta_n - htheta)';
%迭代两次差别很小时
if h_err<1e-6
break;
end
%防止不收敛造成死循环
if kk>1000%迭代1000次还不收敛则跳出循环
break;
end
end
htheta = theta0 + theta1*x1 + theta2*x2;
plot3(x1,x2,htheta,'r','linewidth',3);
xlabel('x1');ylabel('x2');grid;
hold off;4、stochastic/incremental gradient descent(有两个变量)
%stochastic/incremental gradient descent with two variable
%h_theta(x) = theta0 + theta1*x1 + theta2*x2
clc;clear all;close all;
%初始化training set
x1 = 1:10;x2=x1;
m = length(x1);%training set中training example个数
y = x1 + 0.5*randn(1,m);
%初始化learning rate,此值不能太大
alpha = 0.001;
%初始化parameters(also called weights)
theta0 = 0;
theta1 = 0;
theta2 = 0;
%将training set画出来
figure;plot3(x1,x2,y,'x');xlabel('x1');ylabel('x2');grid;
%将training set画出来
figure;plot3(x1,x2,y,'x','linewidth',2);hold on;
kk = 0;
while 1
htheta = theta0 + theta1*x1 + theta2*x2;%由线性函数h所预测的y
plot3(x1,x2,htheta);
for ii = 1:m
htheta_ii = theta0 + theta1*x1(ii) + theta2*x2(ii);%由线性函数h所预测的y
theta0 = theta0 + alpha * (y(ii)-htheta_ii)*1;%letting x0=1
theta1 = theta1 + alpha * (y(ii)-htheta_ii)*x1(ii);
theta2 = theta2 + alpha * (y(ii)-htheta_ii)*x2(ii);
end
%以下为收敛性判断
kk = kk + 1;
htheta_n = theta0 + theta1*x1 + theta2*x2;
h_err = (htheta_n - htheta)*(htheta_n - htheta)';
%迭代两次差别很小时
if h_err<1e-6
break;
end
%防止不收敛造成死循环
if kk>1000%迭代1000次还不收敛则跳出循环
break;
end
end
htheta = theta0 + theta1*x1 + theta2*x2;
plot3(x1,x2,htheta,'r','linewidth',3);
xlabel('x1');ylabel('x2');grid;
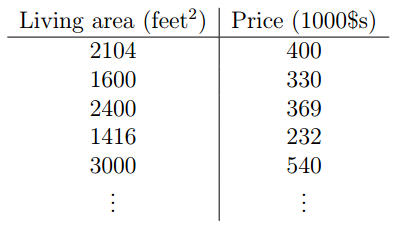
hold off;5、利用讲义notes1.pdf第1页的数据的batch gradient descent
%batch gradient descent with one variable
%使用讲义第1页的数据
%h_theta(x) = theta0 + theta1*x1
clc;clear all;close all;
%初始化training set
%x = 1:10;
x=[2104 1600 2400 1416 3000];
m = length(x);%training set中training example个数
%y = x + 0.5*randn(1,m);
y=[400 330 369 232 540];
%初始化learning rate,此值不能太大
%alpha = 0.0005;
alpha = 0.00000001;
%初始化parameters(also called weights)
theta0 = 0;
theta1 = 0;
%将training set画出来
figure;plot(x,y,'x');
%将training set画出来
figure;plot(x,y,'kx','linewidth',2);hold on;
kk = 0;
while 1
htheta = theta0 + theta1*x;%由线性函数h所预测的y
plot(x,htheta);
%求迭代公式求和号项
sum_t0 = 0;
sum_t1 = 0;
for ii = 1:m
sum_t0 = sum_t0 + (y(ii)-htheta(ii))*1;%letting x0=1
sum_t1 = sum_t1 + (y(ii)-htheta(ii))*x(ii);
end
%计算新的theta0和theta1
theta0_t = theta0 + alpha * sum_t0;
theta1_t = theta1 + alpha * sum_t1;
%更新theta0和theta1
theta0 = theta0_t;
theta1 = theta1_t;
%以下为收敛性判断
kk = kk + 1;
htheta_n = theta0 + theta1*x;
h_err = (htheta_n - htheta)*(htheta_n - htheta)';
%迭代两次差别很小时
if h_err<1e-6
break;
end
%防止不收敛造成死循环
if kk>1000%迭代1000次还不收敛则跳出循环
break;
end
end
htheta = theta0 + theta1*x;
plot(x,htheta,'r','linewidth',3);
%xlim([1 10]);ylim([1 10]);
hold off;6、总结
之所以最后又给了一组代码,这是因为当我用写好的程序去处理讲义第1页的数据时发现结果不收敛,试了很多次,后来想到可能是learning rate参数的设置问题,后来把alpha的值一直减小,终于得到了收敛结果。所以,试处理不同的数据时一定要注意alpha参数的设置。
不知道程序到底对不对,反正自己生成的数据是可以很好的去处理。















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









