







 本文是Ng机器学习课程的线性回归部分,包括监督学习概念,线性回归介绍,Least Mean Squares(LMS)算法,梯度下降法及其在单变量和多变量线性回归中的应用。文章提供了编程实战,展示了如何计算代价函数、执行梯度下降以及使用正规方程找到最优解。
本文是Ng机器学习课程的线性回归部分,包括监督学习概念,线性回归介绍,Least Mean Squares(LMS)算法,梯度下降法及其在单变量和多变量线性回归中的应用。文章提供了编程实战,展示了如何计算代价函数、执行梯度下降以及使用正规方程找到最优解。
编者按:本系列系统总结Ng机器学习课程(http://cs229.stanford.edu/materials.html) Notes理论要点,并且给出所有课程exercise的作业code和实验结果分析。”游泳是游会的“,希望通过这个系列可以深刻理解机器学习算法,并且自己动手写出work高效的机器学习算法code应用到真实数据集做实验,理论和实战兼备。
Part 1 Linear Regression
1. Supervised Learning
在Supervise Learning的Setting中,我们有若干训练数据(x^(i),y^(i)) i= 1,...,m ,这里i用于index training example。监督学习的任务就是要找到一个函数 (又称为模型或者假设hypothesis)H: X -> Y, 使得h(x)是相应值y的好的预测。整个过程可以描述为下图
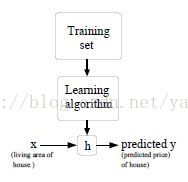
当待预测的目标变量是连续型数据时,我们称之为回归(regression)问题;当待预测的目标变量是离散型数据时,我们称之为分类(classification)问题。因此回归问题和分类问题是监督学习针对连续型数据预测和离散型数据预测的两种典型学习问题。
2 Linear Regression
一般而言,我们会用feature向量来描述训练数据X,我们用x_j^i来表示,其中j用于index feature, i用于index训练样本。在监督学习里面,我们需要找到一个最佳的预测函数h(x),比如我们可以选取feature的线性组合函数
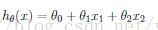
那么我们的问题就变成了要寻找最优的参数\theta可以使得预测的error最小。把这个函数用向量表示
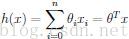
机器学习里面一般默认变量为列向量,因此这里是参数向量\theta的转置矩阵。同时我们还加上了”feature 0“即x_0 = 1 以便方便表示成为向量乘积的形式。为了寻找最优的参数\theta,我们可以最小化error function即cost function
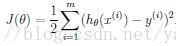
这个就是least-squares cost function,通过最小化这个函数来寻找最优参数。
3 LMS算法
为了寻找最优参数,我们可以随机初始化,然后沿着梯度慢慢改变参数值(需要改变\theta所有维),观察cost function值的变化,这就是梯度下降法的思想。假设我们只有一个训练样本(x,y), 对参数\theta_j求偏导数有
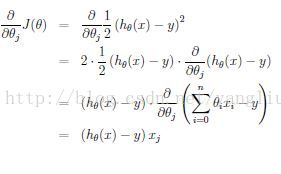
我们可以得到下面的参数update rule
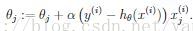
其中\alpha叫learning rate,用于调节每次迭代参数变化的大小,这就是LMS(least mean squares)算法。用直观的角度去理解,如果我们看到一个训练样本满足y^(i) - h(x(i))等于0,那么说明参数就不必再更新;反之,如果预测值error较大,那么参数的变化也需要比较大。
如果我们有多个训练样本,比如有m个样本,每个样本用n个feature来描述,那么GD的update rule需要对n个feature对应的n个参数都做更新,有两种更新方式:batch gradient descent和stochastic/incremental gradient descent。对于前者,每次更新一轮参数\theta_j(注意n个参数需要同步更新才算完成一轮)需要都需要考虑所有的m个训练样本,即
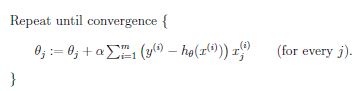
也就是每更新一个\theta_j我们需要计算所有m个训练样本的prediction error然后求和。而后者更新一轮参数\theta_j我们只需要考虑一个训练样本,然后逐个考虑完所有样本(因此是incremental的)即
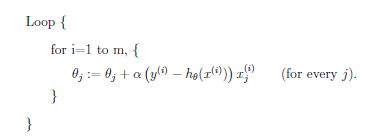
当训练样本size m非常大时,显然stochastic/incremental gradient descent会更有优势,因为每更新一轮参数不需要扫描所有的训练样本。
我们也可以把cost function写出矩阵相乘的形式,即令
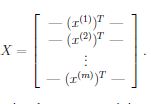
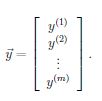
则有
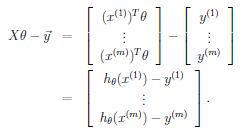
因此代价函数J可以写成
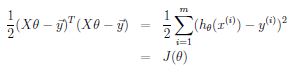
我们将J(\theta)对向量\theta求梯度(对于向量求导,得到的是梯度,是有方向的,这里需要用到matrix calculus,比标量形式下求导麻烦一些,详见NG课程notes),令梯度为0可以直接得到极值点,也就是唯一全局最优解情形下的最值点(normal equations)
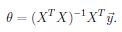
这样可以避免迭代求解,直接得到最优的参数\theta值。
3 编程实战
(注:本部分编程习题全部来自Andrew Ng机器学习网上公开课ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3930
3930

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









