






主流的卷积网络基本都设计批量归一化这个层
1.为什么要批量归一化?

①网络层很深,数据在底层,损失函数在最顶层。反向传播后,顶层的梯度大,所以顶层训练的较快。数据在底层,底层的梯度小,底层训练的慢。(学习率不变)
②数据在最底部,底部层的训练较慢。
Ⅰ底部层一变化,所有的层都要跟着变化
Ⅱ顶部的层需要重新学习很多次
Ⅲ导致收敛变慢
③批量归一化可以在学习底部层的时候避免变化顶部层。
2.批量归一化的思想:
①固定小批量里面的均值和方差(因为方差和均值的分布在不同的层有变化 )
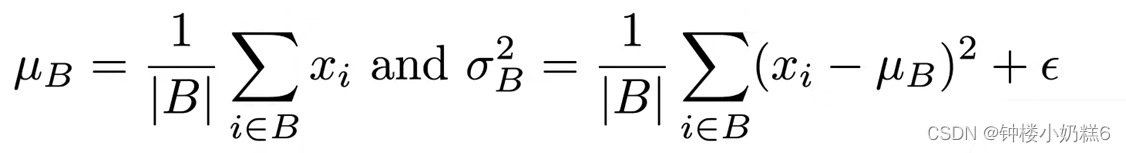
②可学习参数:如果均值为0,方差为1的分布不是很适合的话,可以学习一个均值和方差使得对网络更好一些。

3.批量归一化层
①可学习的参数γ和β
②作用在:
Ⅰ全连接层和卷积层输出之后,(批量归一化层这里:线性变换,均值方差拉的比较好)激活函数之前
Ⅱ全连接层和卷积层的输入上
③对全连接层,作用在特征维 ( 二维的输入,每一行就是样本,每一列就是特征。全连接层对每一个特征计算标量的均值和方差。不一样的是每一个全连接层的输入和输出都做这件事,不只是做在数据上面。而是重新用学到的γ和β,对方差和均值做校验)
④对卷积层,作用在通道维(1*1卷积等价于全连接层,对于每一个像素有多通道。比如有一个像素对应通道是100,这个像素有100维的向量。向量就是这个像素的特征。所以在输入的时候,每一个像素就是一个样本。
卷积层输入:批量大小*高*宽*通道数 样本数:批量大小*高*宽。所以就是所有的像素当作样本,一个像素对应的所有通道当作特征)
4.批量归一化的作用是什么
①最初的论文减少内部协变量的转移
②后续论文,通过每个小批量里加入噪音控制模型复杂度

加入随机偏移和方差,然后通过学到的稳定的均值方差,使得变化不剧烈
③没必要和丢弃法一起
【总结】
①批量归一化固定小批量中的均值和方差,然后学习出适合偏移和缩放
②可以加速收敛速度,学习率可以变大,但一般不改变模型的精度
【代码实现】
import torch
from torch import nn
from d2l import torch as d2l
# X是输入 ,gamma-beta可学习参数,moving_mean,moving_var全局的均值和方差,是在预测的时候使用,eps避免分母出现0,momentum更新移动的平均和方差通常取0.9
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使用传入的移动平均所得的均值和方差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else: # 训练模式下
assert len(X.shape) in (2, 4) # 2是全连接层(两个维度,batch和全连接层的大小) 4是卷积层(batch,通道数,高,宽)
if len(X.shape) == 2:
# 使用全连接层的情况,计算特征维上的均值和方差
mean = X.mean(dim=0) # 按行求出来 对同一列元素求均值
var = ((X - mean) ** 2).mean(dim=0) # 方差
else:
# 使用二维卷积层的情况,计算通道维上(axis=1)的均值和方差。
# 这里我们需要保持X的形状以便后面可以做广播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True) # 按通道数求均值
var = ((X - mean) ** 2).mean(dim=(0, 2, 3), keepdim=True) # 按通道数求方差
# 训练模式下,用当前的均值和方差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和方差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表示完全连接层,4表示卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# 非模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
# 应用 LeNet模型
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), BatchNorm(16, num_dims=4), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(16 * 4 * 4, 120), BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2), nn.Sigmoid(),
nn.Linear(84, 10))
# 训练
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()简易实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), nn.Flatten(),
nn.Linear(256, 120), nn.BatchNorm1d(120), nn.Sigmoid(),
nn.Linear(120, 84), nn.BatchNorm1d(84), nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
d2l.plt.show()














 3442
3442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









