







Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric 文章的一点点理解梳理
写在前面
因为我比较弱,在机器学习和三维重建方面都算是新手,所以并不是很理解这篇文章,只是梳理下文章中的模型结构,当做笔记,我相信大家更加优秀,应该能理解的层次比我更深。我这里梳理的顺序按照由小模块向大模块梳理。
Residual Module
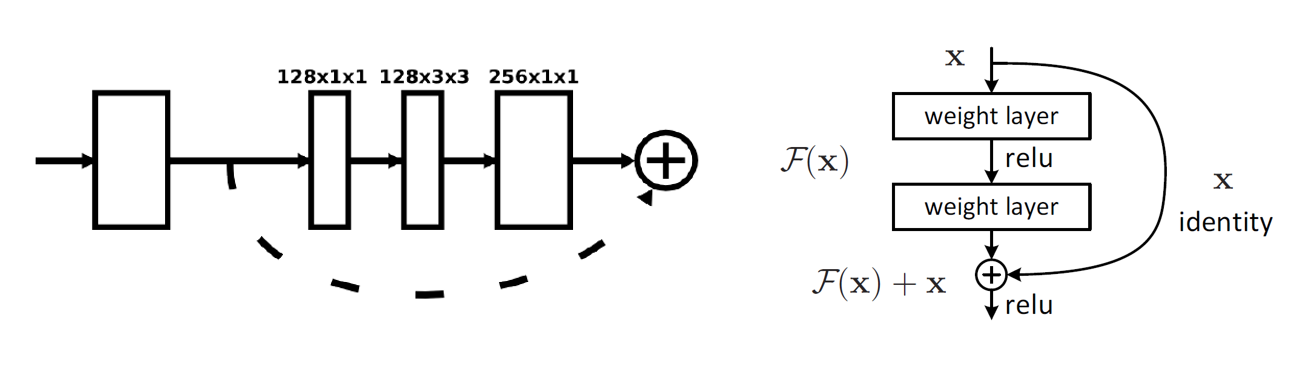
文章中称为 residual module ,引用的文章中称为 Residual Learning,是微软发表的文章,中文常翻译为残差学习,源自论文Deep Residual Learning for Image Recognition 这种结构主要解决深度学习层次特别深的时候,容易在BackPropagation过程中梯度消失的问题,使得即便网络结构非常深,梯度也不会轻易消失。
他第一行是卷积路,由三个核尺度不同的卷积串联而成;第二行是跳级路,只包含一个核尺度为1的卷积层。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 460
460











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









