







🍉CSDN小墨&晓末:https://blog.csdn.net/jd1813346972
个人介绍: 研一|统计学|干货分享
擅长Python、Matlab、R等主流编程软件
累计十余项国家级比赛奖项,参与研究经费10w、40w级横向
文章目录
该篇文章利用介绍了蒙特·卡罗算法及其主要步骤;优点;局限性,同时利用R语言对实际案例进行蒙特卡罗模拟演示。
1 蒙特·卡罗算法简介
蒙特·卡罗(Monte Carlo)算法,也称为蒙特卡洛方法或统计模拟方法,是一种基于随机采样的数值计算方法。它的基本思想是通过大量的随机采样来估计某个难以直接计算的值,从而得到近似结果。蒙特卡罗方法在各种领域都有广泛的应用,如计算物理、金融工程、统计学、计算机科学等。
蒙特·卡罗方法的核心是随机性和大数定律。通过生成随机数或伪随机数,蒙特卡罗方法能够模拟各种复杂的随机过程,并通过统计这些随机过程的结果来得到问题的近似解。随着采样次数的增加,蒙特卡罗方法的估计结果将逐渐逼近真实值,这是由大数定律保证的。
2 蒙特·卡罗方法主要步骤
蒙特卡罗方法的主要步骤如下:
- 定义问题:明确需要求解的问题,确定问题的目标函数或概率分布。
- 生成随机数:根据问题的需要,生成相应分布的随机数或伪随机数。
- 模拟过程:使用生成的随机数模拟问题的随机过程,如物理实验、金融交易等。
- 统计结果:收集模拟过程中的数据,并计算所需的统计量,如平均值、方差等。
- 估计结果:根据统计结果,估计问题的近似解,并给出相应的置信区间或误差分析。
3 蒙特·卡罗方法优点
蒙特卡罗方法的优点包括:
- 通用性:蒙特卡罗方法适用于各种类型的问题,只要问题可以转化为随机过程进行模拟。
- 灵活性:蒙特卡罗方法可以根据问题的特点进行定制和优化,如采用重要性采样、分层采样等技术提高采样效率。
- 易于实现:蒙特卡罗方法的算法相对简单,易于编程实现和并行化。
4 蒙特·卡罗方法局限性
蒙特卡罗方法的局限性主要表现在以下三个方面:
- 计算成本:为了得到较为准确的结果,蒙特卡罗方法通常需要大量的采样次数,这可能导致较高的计算成本。
- 收敛速度:蒙特卡罗方法的收敛速度通常与问题的维度和复杂性有关,对于高维或复杂问题,可能需要更长的计算时间。
- 随机性:蒙特卡罗方法的结果受到随机数生成器的影响,不同的随机数序列可能导致结果的波动。因此,在使用蒙特卡罗方法时,需要选择合适的随机数生成器并进行充分的测试。
5 蒙特·卡罗方法的代码实现——基于R
5.1 求圆周率 π \pi π
运行程序:
library('ggplot2')
f <- function(r){
sqrt(1-r^2)
}
x <- seq(0,1,length=3000)
y <- f(x)
df <- data.frame(x,y)
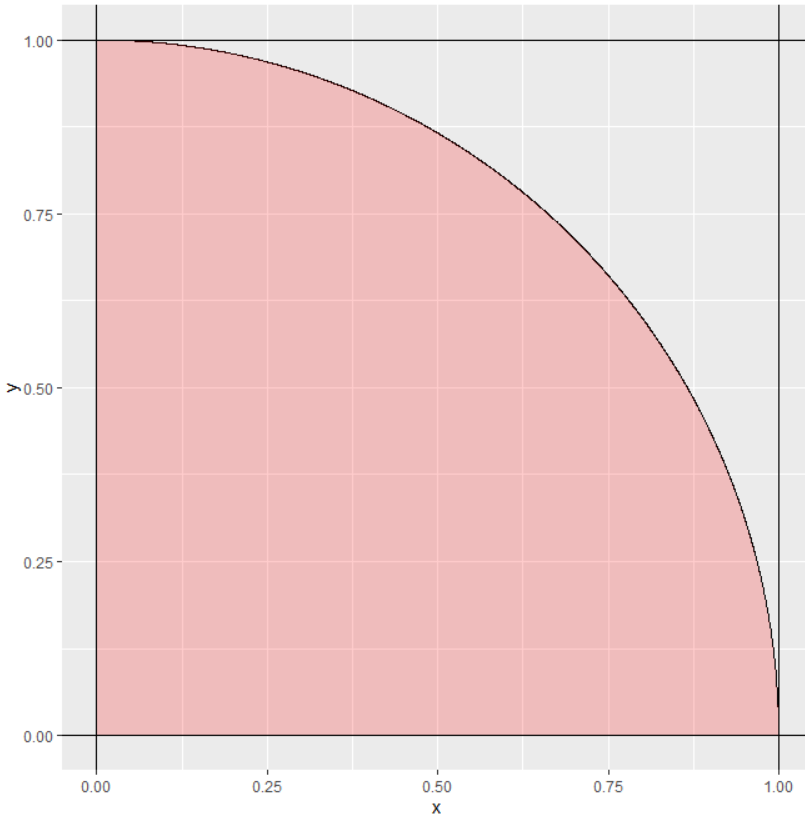
ggplot(df, mapping = aes(x=x,y=y))+
geom_line()+geom_ribbon(aes(ymin=0, ymax=y, x = x),
fill="red", alpha=0.2)+
geom_hline(yintercept = c(0,1))+geom_vline(xintercept = c(0,1))
##计数函数
MC1 <- function(n){
k <- 0
x <- runif(n, 0, 1)
y <- runif(n, 0, 1) #从已知概率分布中抽样
for (i in 1:n){
if (y[i] < f(x[i]))
k <- k+1
}
k/n #建立所需的统计量
}
4*MC1(10000000)
运行结果:
3.141294
5.2 计算定积分
运行程序:
library('ggplot2')
f <- function(x){
log(1+x)/(1+x^2)
}
x <- seq(0,1,length=50)
y <- f(x)
df <- data.frame(x,y)
ggplot(df, mapping = aes(x=x,y=y))+geom_line()
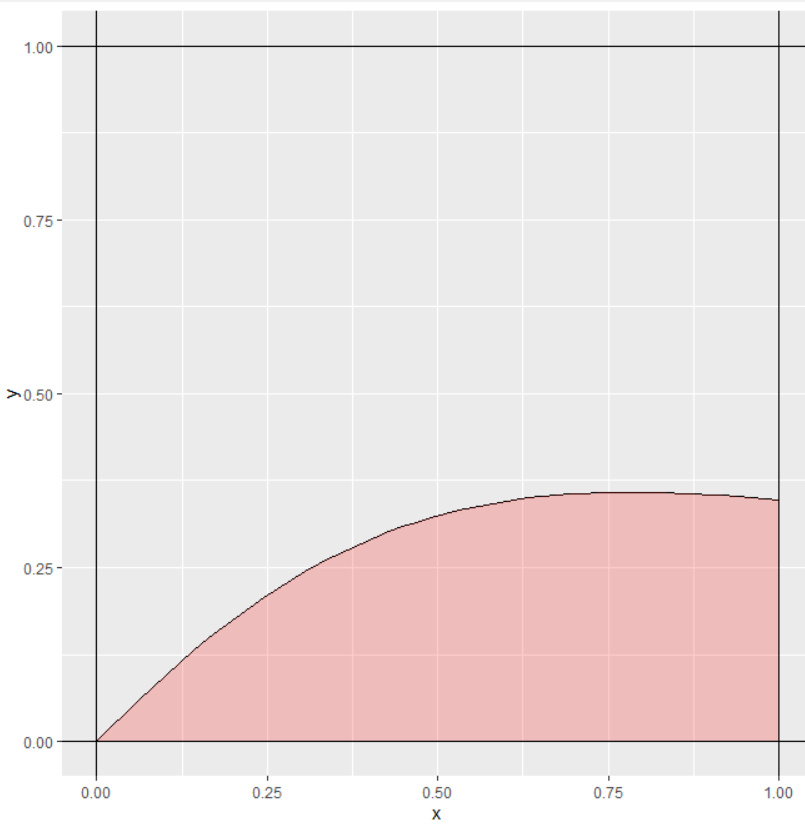
ggplot(df, mapping = aes(x=x,y=y))+
geom_line()+geom_ribbon(aes(ymin=0, ymax=y, x = x),
fill="red", alpha=0.2)+
geom_hline(yintercept = c(0,1))+geom_vline(xintercept = c(0,1))
##计数函数
MC1 <- function(n){
k <- 0
x <- runif(n, 0, 1)
y <- runif(n, 0, 1) #从已知概率分布中抽样
for (i in 1:n){
if (y[i] < f(x[i]))
k <- k+1
}
k/n #建立所需的统计量
}
MC1(10000000)
运行结果:
0.2721784
该积分正确结果为:0.27057,蒙特卡洛模拟结果逼近正确结果。
5.3 蒙特卡罗算法在项目管理中的应用
运行程序:
x <- seq(7,35,length = 100)
y1 <- dnorm(x, mean = 14, sd = 2)#dnorm正态分布概率密度函数值
y2 <- dnorm(x, mean = 23, sd = 3)
y3 <- dnorm(x, mean = 22, sd = 4)
data <- data.frame(x,y1,y2,y3)
colnames(data) <- c("x","y1","y2","y3")
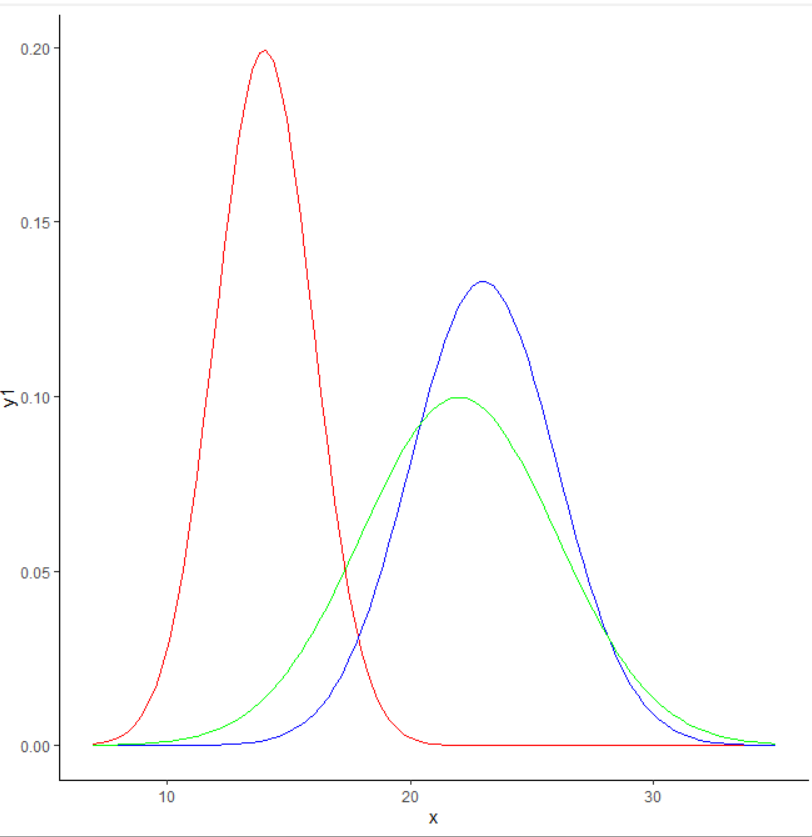
ggplot(data)+
geom_line(aes(x=x,y=y1), color = "red")+
geom_line(aes(x=x,y=y2), color = "blue")+
geom_line(aes(x=x,y=y3), color = "green")+
theme_classic()
#构建蒙特卡罗模拟
MC2 <- function(n){
y1 <- rnorm(n , mean = 14, sd = 2) #从已知概率分布中抽样
y2 <- rnorm(n , mean = 23, sd = 3)
y3 <- rnorm(n , mean = 22, sd = 4)
y <- y1 + y2 + y3 #构造问题的概率模型
result <- c(mean(y),var(y)) #建立所需的统计量,即样本均值和样本方差
return(result)
}
result <- MC2(100000)
print(result)
运行结果:
[1] 58.96622 28.98157
运行程序:
x <- seq(7,80,length = 1000)
data <- data.frame(x,y1 <- dnorm(x, mean = 14, sd = 2),
dnorm(x, mean = 23, sd = 3),
dnorm(x, mean = 22, sd = 4),
dnorm(x, mean = result[1],
sd = result[2]^0.5))
colnames(data) <- c("x","y1","y2","y3","y")
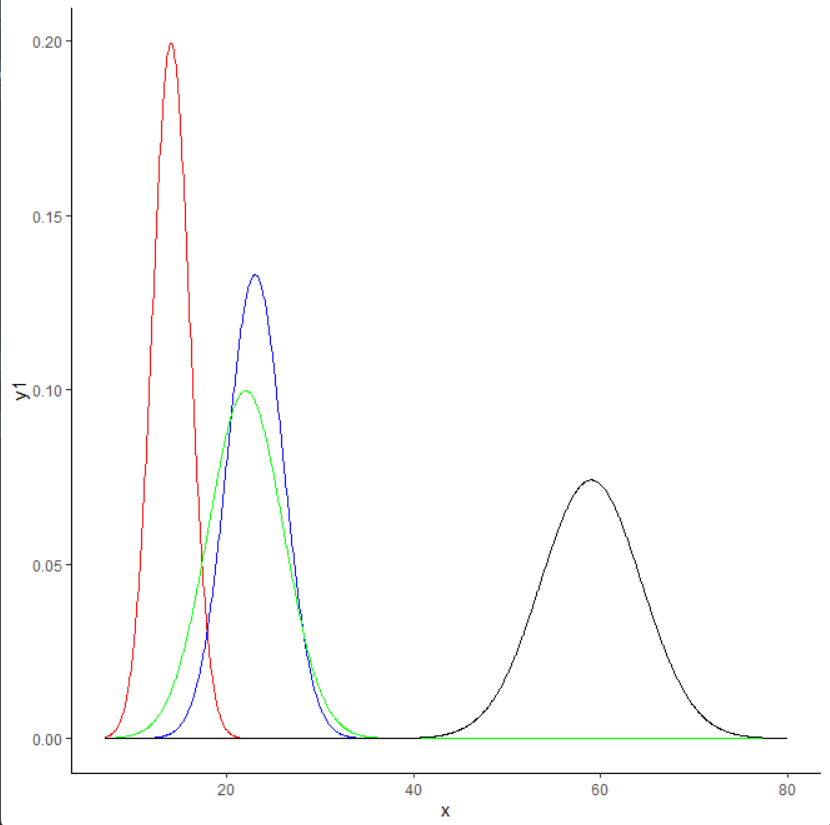
ggplot(data)+
geom_line(aes(x=x,y=y1), color = "red")+
geom_line(aes(x=x,y=y2), color = "blue")+
geom_line(aes(x=x,y=y3), color = "green")+
geom_line(aes(x=x,y=y))+
theme_classic()
运行结果:



















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











