







 文章介绍了HQ-SAM,一种在保持SegmentAnythingModel(SAM)零镜头功能和灵活性的同时,通过学习高质量输出令牌和全局-局部特征融合提升分割质量的模型。HQ-SAM在少量高精度掩码数据集上训练,对复杂结构物体的分割效果显著优于原始SAM。
文章介绍了HQ-SAM,一种在保持SegmentAnythingModel(SAM)零镜头功能和灵活性的同时,通过学习高质量输出令牌和全局-局部特征融合提升分割质量的模型。HQ-SAM在少量高精度掩码数据集上训练,对复杂结构物体的分割效果显著优于原始SAM。
Segment Anything in High Quality
paper:https://arxiv.org/pdf/2306.01567v1.pdf
code:https://github.com/SysCV/SAM-HQ
SAM-HQ的使用也可以参考:
Grounded-SAM(最强Zero-Shot视觉应用):本地部署及各个模块的全网最详细使用教程!
Abstract
最近推出的 Segment Anything Model (SAM) 是扩展分割模型方面的一大飞跃,它具有强大的零镜头功能和灵活的提示功能。尽管 SAM 已使用 11 亿个Mask进行了训练,但在很多情况下,尤其是在处理具有复杂结构的物体时,其Mask预测质量仍有不足。我们提出了 HQ-SAM,使 SAM 具备准确分割任何物体的能力,同时保持 SAM 最初的可提示设计、效率和零点泛化能力。我们的精心设计重用并保留了 SAM 的预训练模型权重,同时只引入了极少的额外参数和计算。我们设计了一种可学习的高质量输出token,它被注入到 SAM 的掩码解码器中,负责预测高质量掩码。我们并没有将其仅应用于掩码解码器特征,而是首先将其与早期和最终 ViT 特征融合,以改善掩码细节。为了训练我们引入的可学习参数,我们从多个来源收集了 44K 个细粒度掩码数据集。HQ-SAM 仅在引入的 44K 掩码数据集上进行训练,在 8 个 GPU 上仅需 4 个小时。我们在不同下游任务的 9 个不同分割数据集中展示了 HQ-SAM 的功效,其中 7 个数据集在零镜头传输协议中进行了评估。
1.Introduction
对多样化物体进行精确的分割是一系列场景理解应用的基础,包括图像/视频编辑、机器人感知,以及AR/VR等。最近发布的 Segment Anything Model(SAM)[21]使用了数十亿规模的掩码标签进行训练,是用于一般图像分割的基础视觉模型。SAM 能够将由点、边界框或粗略mask组成的提示作为输入,在不同场景中分割各种物体、部件和视觉结构。它的 "zero-shot "分割能力促使模式迅速转变,因为通过简单的提示就能将其应用到众多应用中。
尽管 SAM 已经取得了令人印象深刻的性能,但在许多情况下其分割结果仍然不能令人满意。特别是 SAM 存在两个关键问题:
1)mask边界粗糙,甚至忽略了对薄对象结构的分割,如图1所示。
2)不正确的预测,破损的masks,或在具有挑战性的情况下的大错误。
这通常与 SAM 误解薄结构有关,例如图1最右边一列中的风筝线。这些类型的故障严重限制了 SAM 等基础分割模型的适用性和有效性,特别是在自动注释和图像/视频编辑任务中,高度精确的图像掩码至关重要。

我们提出的 HQ-SAM 可以预测高精度的分割掩码,即使在非常具有挑战性的情况下也是如此(见图 1),同时又不影响原始 SAM 强大的零镜头功能和灵活性。为了保持效率和零镜头性能,我们对 SAM 进行了最小化调整,增加了不到 0.5% 的参数,以扩展其高质量分割的能力。
直接对SAM解码器进行微调,或者引入一个新的解码器模块,会严重降低通用的零样本分割性能。因此,我们提出了HQ-SAM架构,该架构与现有学习的SAM结构紧密集成和重用,以完全保留零样本性能。首先,我们设计了一个可学习的HQ输出令牌,该令牌作为输入传递给SAM的掩码解码器,与原始的提示和输出令牌一起使用。与原始的输出令牌不同,我们的HQ输出令牌及其关联的MLP层被训练用于预测高质量的分割掩码。其次,我们的HQ输出令牌不仅重用SAM的掩码解码器特征,还通过在ViT编码器中使用早期和晚期特征图与SAM的掩码解码器特征进行融合,从而对一组精确的掩码细节进行操作。在训练过程中,我们冻结整个预训练的SAM参数,只更新我们的HQ输出令牌、其关联的三层MLP和一个小的特征融合块。
学习精确的分割需要具有复杂和详细几何结构的多样化对象的准确掩码注释数据集。SAM是在包含1100万张图像的SA-1B数据集上训练的,该数据集由类似SAM的模型自动生成了十亿个掩码。然而,使用这个大规模数据集会带来显著的成本影响,并且无法实现我们工作中所追求的高质量掩码生成,正如图1 中 SAM 的表现所示。因此,我们构建了一个名为HQSeg-44K的新数据集,其中包含44K个非常精细的图像掩码注释。HQSeg-44K由六个现有的具有高精度掩码注释的图像数据集[34, 29, 26, 37, 8, 45] 合并而成,涵盖了1000多种多样化的语义类别。由于规模较小的数据集和我们的最小集成架构,HQ-SAM 可以在8个RTX 3090 GPU上仅需4小时训练。
为了验证HQ-SAM的有效性,我们进行了广泛的定量和定性实验分析。我们对9个多样化的分割数据集进行了HQ-SAM和SAM的比较,涵盖了不同的下游任务,其中有7个是在zero-shot转移协议下进行的,包括COCO、UVO、LVIS、HQ-YTVIS、BIG、COIFT和HR-SOD。这个严格的评估表明,所提出的HQ-SAM相对于SAM在保持零-shot能力的同时能够产生更高质量的掩码。换句话说,HQ-SAM在生成准确的分割掩码方面表现更出色。
2 Related Work
3 Method
我们提出 HQ-SAM 来升级 SAM,以实现高质量的zero-shot分割。HQ-SAM 是轻量级的,只对 SAM 模型引入了两个重要的调整。在第 3.1 节中,我们首先简要回顾了 HQ-SAM 所基于的 SAM 架构。然后,在第 3.2 节中,我们将介绍带有高质量令牌(HQ-Output Token)和全局-本地特征融合的 HQ-SAM,它们是在保留其零拍能力的同时为 SAM 实现更好分割质量的关键组件。最后,在第 3.3 节中,我们将介绍 HQ-SAM 的训练和推理过程。
3.1 Preliminaries: SAM
SAM [21]由三个模块组成:(a) 图像编码器:一个基于ViT的重型骨干网络,用于提取图像特征,最终得到空间尺寸为64×64的图像嵌入。(b) 提示编码器:编码输入点/框/掩码的交互位置信息,提供给掩码解码器使用。© 掩码解码器:一个基于两层Transformer的解码器,同时利用提取的图像嵌入和拼接的输出与提示令牌进行最终的掩码预测。发布的SAM模型是在大规模的SA-1B数据集上训练的,该数据集包含超过10亿个自动生成的掩码(比任何现有分割数据集[14, 24]多400倍)和1100万张图像。因此,SAM展现了对新数据有着有价值的强零-shot泛化能力,无需额外的训练。但是,我们也注意到SAM的训练非常昂贵,使用256个GPU、大批量大小为256张图像在SA-1B上分布式训练ViT-H-based的SAM需要2个epoch。有关SAM方法的更多细节,请参考[21]。
3.2 Ours: HQ-SAM
在本节中,我们将介绍 HQ-SAM 网络的架构。为了保持 SAM 的零镜头传输能力,同时防止模型过拟合或灾难性遗忘,我们没有直接对 SAM 进行微调,也没有增加新的重解码器网络,而是尽可能采取最小化适应方法。为此,HQ-SAM 尽可能地重复使用了 SAM 的预训练模型权重,只新增了两个关键组件,即高质量输出令牌和全局-局部特征融合,如图 2 所示。因此,HQ-SAM 可被视为从 SAM 演化而来的高质量零镜头分割模型,其额外的模型参数和计算成本几乎可以忽略不计。
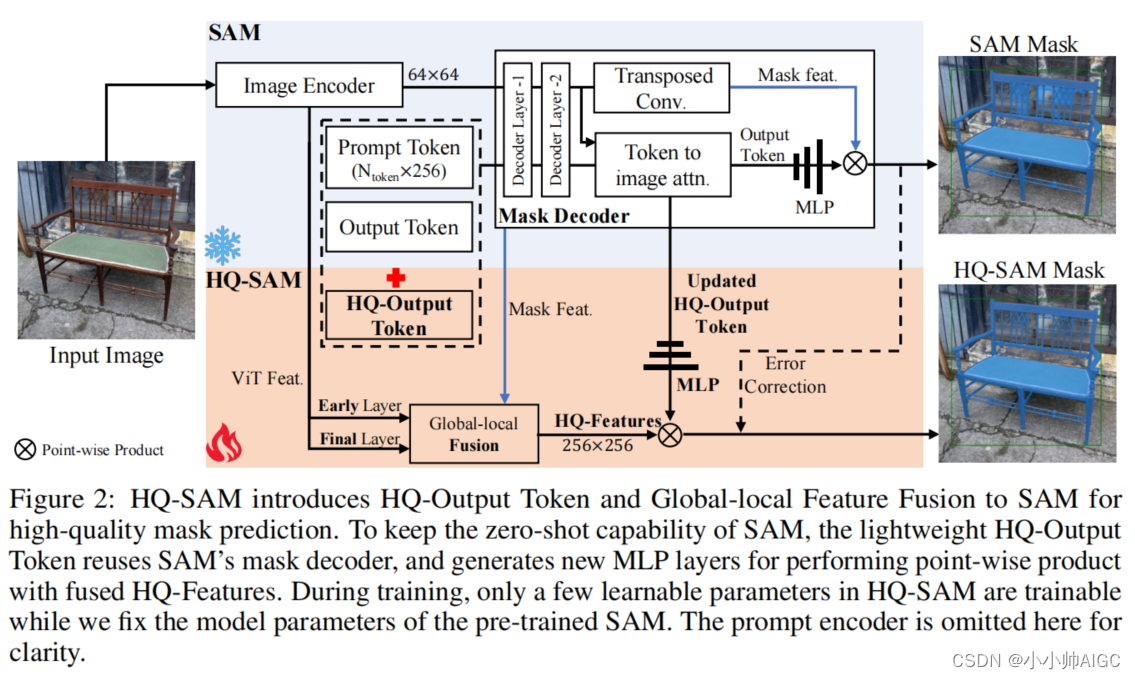
3.2.1 High-Quality Output Token
我们提出了提高 SAM 掩码质量的高效标记学习方法。如图 2 所示,在 SAM 最初的掩码解码器设计中,采用输出令牌(类似于 DETR [3] 中的对象查询)进行掩码预测,预测动态 MLP 权重,然后与掩码特征进行逐点乘积。为了在 HQ-SAM 中提高 SAM 的掩码质量,我们不再直接将 SAM 的粗掩码作为输入,而是引入了 HQ 输出标记和一个新的掩码预测层,用于高质量的掩码预测
在图 2 中,通过重复使用和固定 SAM 的掩码解码器,一个新的可学习 HQ 输出令牌(大小为 1×256)与 SAM 的输出令牌(大小为 4×256)和提示令牌(大小为 Nprompt×256)连接起来,作为 SAM 掩码解码器的输入。与原始输出令牌类似,在每个注意层中,HQ-输出令牌首先与其他令牌进行自我注意,然后进行令牌到图像和图像到令牌的反向注意,以更新其特征。请注意,在每个解码器层中,HQ-输出令牌都使用了与其他令牌共享的点式 MLP。经过两层解码器后,更新的 HQ 输出令牌可以访问全局图像上下文、提示令牌的关键几何/类型信息以及其他输出令牌的隐藏掩码信息。最后,我们添加了一个新的三层 MLP,从更新的 HQ 输出令牌生成动态卷积核,然后与融合的 HQ 特征进行空间点积,生成高质量的掩码。
我们没有直接对 SAM 进行微调,也没有进一步添加重型后微调网络,而是只允许训练 HQ 输出令牌及其相关的三层 MLP,以纠正 SAM 输出令牌的掩码错误。这与现有的高质量分割模型完全不同[19, 6, 20, 22]。通过大量实验,我们发现了高效标记学习的两大优势:1) 与原始 SAM 相比,这种策略大大提高了 SAM 的掩码质量,同时只引入了可忽略不计的参数,使得 HQ-SAM 的训练非常省时、省数据;2) 学习的标记层和 MLP 层不会过度拟合掩码特定数据集的注释偏差,从而在新图像上保持 SAM 强大的零点分割能力,而不会发生灾难性的知识遗忘。
3.2.2 Global-local Fusion for High-quality Features
非常精确的分割还需要具有丰富的全局语义上下文和局部边界细节的输入图像特征。为了进一步提高掩模质量,我们在 SAM 的掩模解码器特性中充实了高层目标上下文和低层边界/边缘信息。我们不直接使用 SAM 的掩码解码器特征,而是通过从 SAM 模型的不同阶段提取和融合特征来构成新的高质量特征(HQFeatures) : 1) SAM 的 ViT 编码器的早期层局部特征,其空间形状为64 × 64,捕获更一般的图像边缘/边界细节[12]。具体来说,我们在 ViT 编码器的第一个全局注意块之后提取特征,对于基于 ViT-Large 的 SAM,这是24个块的第6个块输出; 2) SAM 的 ViT 编码器的最后一层全局特征是形状为64 × 64,具有更多的全局图像上下文信息; 3) SAM 的掩模解码器的掩模特征是大小为256 × 256,也是输出标记共享的,包含强掩模形状信息。
如图 2 所示,为了获得输入的 HQ 特征,我们首先通过转置卷积将早期层和末期层编码器特征升采样为空间大小为 256×256 的特征。然后,经过简单的卷积处理,以元素为单位将这三类特征相加。我们的研究表明,这种全局-局部特征融合既简单又有效,能以较小的内存占用和计算负担获得保留细节的分割结果。我们还在实验部分对每个特征源的效果进行了详细的消减(表 3)。

3.3 Training and Inference of HQ-SAM
Training Data Construction
为了以数据高效的方式训练 HQ-SAM,我们没有在 SA-1B [21] 上进行进一步训练,而是创建了一个新的训练数据集 HQSeg-44K,其中包含 44,320 个极其精确的图像掩码注释。我们注意到,已发布的 SA-1B 数据集只包含自动生成的遮罩标签,缺少对具有复杂结构的对象进行非常精确的人工标注。由于注释困难,HQSeg-44K 利用了六个现有图像数据集,包括 DIS [34](训练集)、ThinObject-5K [29](训练集)、FSS-1000 [26]、ECSSD [37]、MSRA- 10K [8]、DUT-OMRON [45],其中每个数据集平均包含 7.4K 个掩码标签。为了使 HQ-SAM 对新数据具有鲁棒性和通用性,HQSeg-44K 包含了 1000 多个不同的语义类别。我们在补充分析中将 HQ-SAM 训练与 44K 随机抽样图像和来自 SA-1B [21] 的掩码进行了比较,从而展示了使用 HQSeg-44K 的优势。
HQ-SAM Training
在训练过程中,我们固定了预训练 SAM 模型的模型参数,而只让提议的 HQ-SAM 可学习。因此,可学习参数只包括 HQ 输出令牌、其相关的三层 MLP 和用于 HQ 特征融合的三个简单卷积。由于 SAM 专为灵活的分割提示而设计,因此我们通过对混合类型的提示进行采样来训练 HQ-SAM,包括边界框、随机采样点和粗糙掩码输入。 我们通过在 GT 掩码的边界区域添加随机高斯噪声来生成这些降级掩码。为了适用于不同的对象尺度,我们使用了大规模抖动技术[13]。我们使用 0.001 的学习率对 HQ-SAM 进行 12 次迭代训练,10 次迭代后学习率下降。 我们使用 8 个 Nvidia GeForce RTX 3090 GPU 进行训练,总批次大小为 32,16.6K 次迭代训练需要 4 个小时。更多详情,请参阅我们的补充文件。
HQ-SAM Inference
我们采用与 SAM 相同的推理流程,但使用 HQ 输出令牌的掩码预测作为高质量掩码预测。在推理过程中,我们将 SAM 掩码(通过输出令牌)和我们预测的掩码(通过 HQ-输出令牌)的预测对数相加,在空间分辨率 256×256 上进行掩码校正。然后,我们将校正后的掩码上采样到原始分辨率 1024×1024 作为输出。
SAM vs. HQ-SAM on Training and Inference
在表 1 中,我们报告了 HQ-SAM 和 SAM 在训练和推理方面的详细比较。虽然 HQ-SAM 的分割质量要好得多,但它的训练非常快速且经济实惠,使用 8 个 RTX3090 GPU 只需 4 个小时。HQ-SAM 还具有轻量级和高效的特点,模型参数、GPU 内存使用量和每幅图像的推理时间的增加可以忽略不计。
4 Experiments
5 Conclusion
我们提出了 HQ-SAM,这是第一个高质量零镜头分割模型,对原始 SAM 的开销几乎可以忽略不计。我们在 HQ-SAM 中提出了一种轻量级高质量输出标记,以取代原始 SAM 的输出标记,从而实现高质量掩码预测。仅在 44K 个高精度掩码上进行训练后,HQ-SAM 就显著提高了在 11 亿个掩码上进行训练的 SAM 的掩码预测质量。零镜头传输评估是在 7 个图像和视频任务的分割基准上进行的,涵盖了不同的对象和场景。我们的研究为如何以数据效率高、计算成本低的方式利用和扩展类似 SAM 的基础分割模型提供了及时的见解。


















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









