






基础组件介绍
我们按照下图的数据介绍组件。
Begin(开始)组件
- • 启动工作流:Begin组件是工作流中的起始组件,自动出现在画布上,不能被删除。原文
- • 设置开场白或接受输入:可以设置开场白或接受用户输入的全局变量。
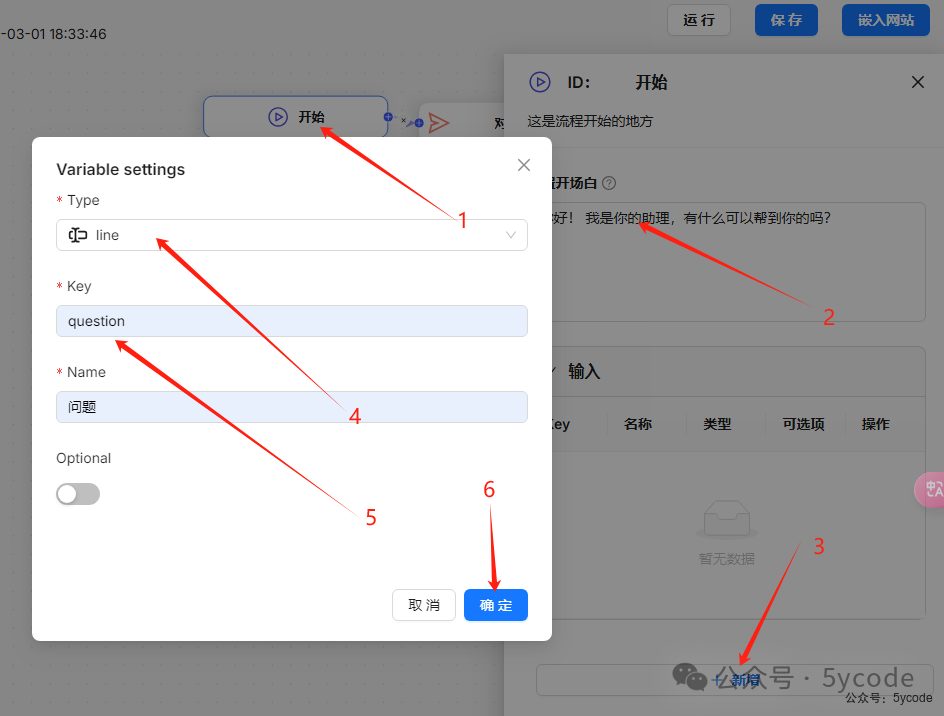
- • 在开始节点中,我们通过
2设置agent的开白场 - • 通过点击
3新增变量(需要注意的是,ragflow的变量是全局变量) - • 打开变量设置对话框以后,我们可以通过
4设置输入框的类型
Retrieval(知识检索)组件
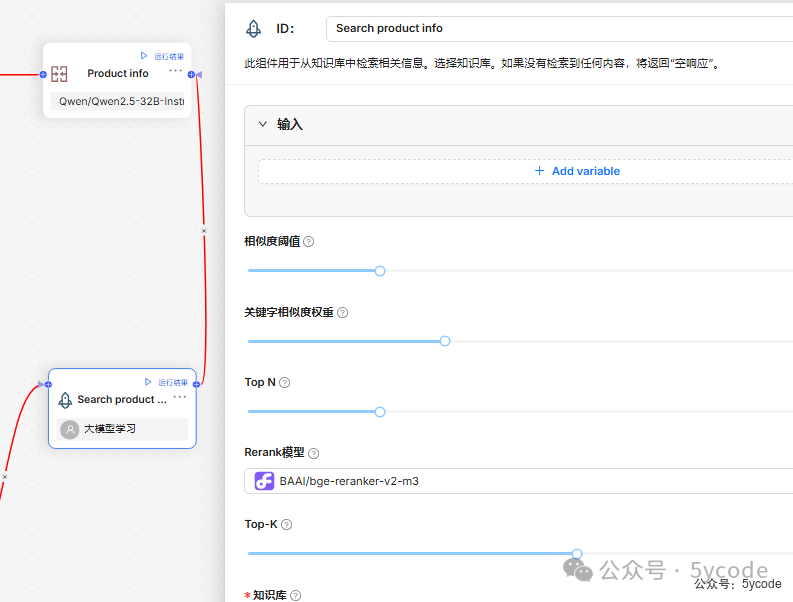
此组件用于从知识库中检索相关信息。选择知识库。如果没有检索到任何内容,将返回“空响应”。
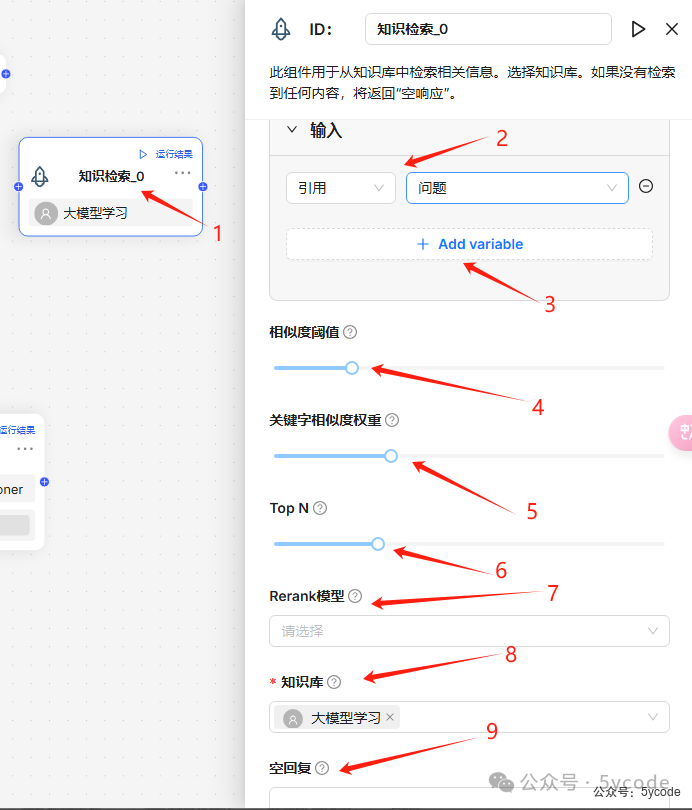
- •
- • 新增输入变量
3:有两种类型的输入变量——引用和文本。引用e使用组件输出或用户输入作为数据源,Text使用固定文本作为查询。没有dify丰富,而且还有个问题,引用的时候能看到所有的变量
- • 新增输入变量
- •
4相似度阈值:设置用户查询与数据集中存储的块之间的相似度阈值,默认值为0.2 - • 关键词相似度权重
5:设置关键词相似度在综合相似度得分中的权重,默认值为0.7,向量相似度的权重为0.3。 - • Top N
6:从检索到的块中选择“Top N”块并传递给LLM,默认值为8。 - • 重排模型
7:可选,如果选择了重排模型,将使用加权关键词相似度和加权重排得分进行检索,但这会显著增加系统的响应时间。 - • 知识库
8:可以选择多个知识库,如果选择多个,必须保证它们使用相同的嵌入模型,否则会出现错误信息 - • 空回复
9:如果没有检索到数据,回复设置的默认值
Generate(生成回答)组件
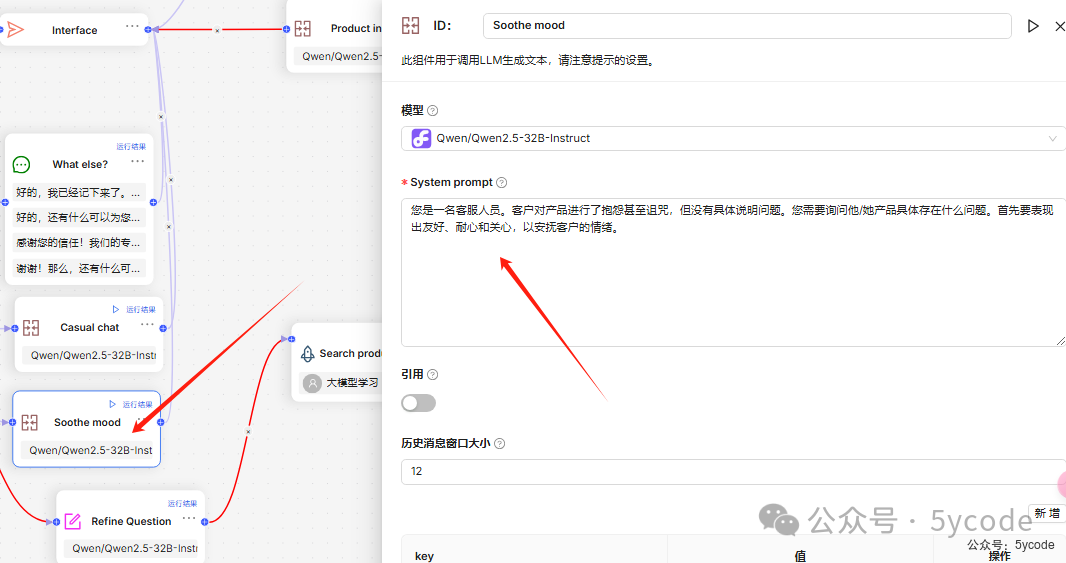
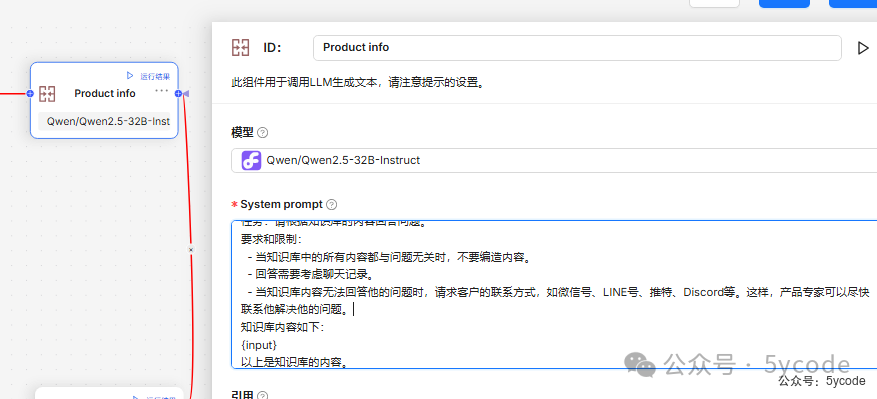
此组件用于调用LLM生成文本,请注意提示词的设置。
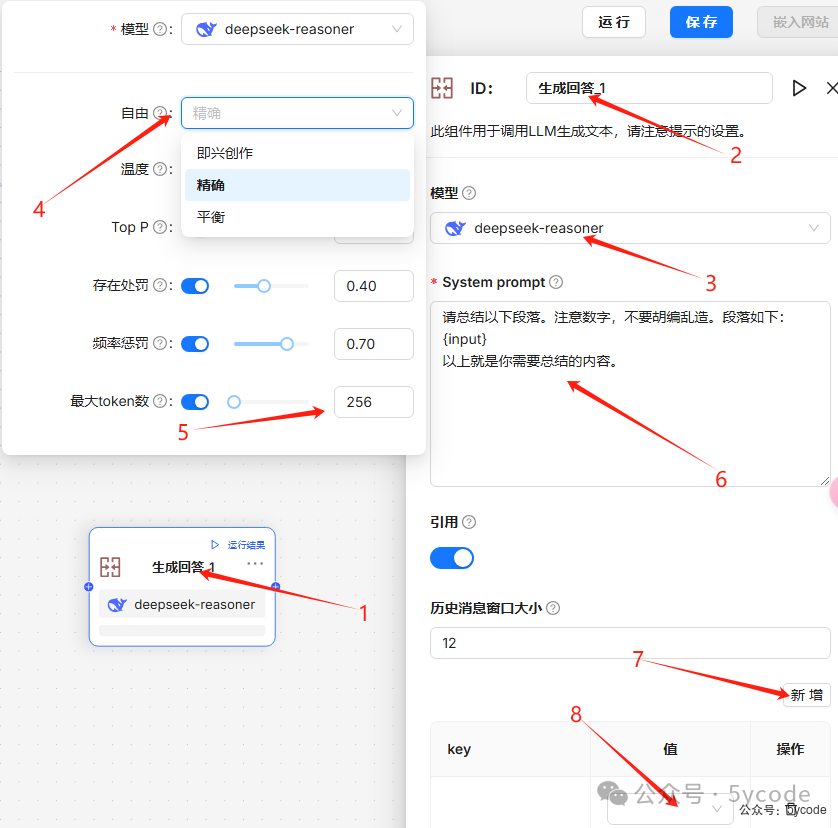
- • 在生成回答组件
1中,我们通过2可以修改修改组件的id - • 通过
3调整组件使用的模型,可以选择已经配置的模型服务- • ragflow给了我们三组参数
4用来控制模型的自由度,可以减少我们的思考 - • 需要注意的是,我们需要关注下最大
Token根据自己的业务来即可。 - • 存在惩罚(Presence penalty):鼓励模型在响应中包含更多样化的标记,默认值为0.4
- • 频率惩罚(Frequency penalty):阻止模型在生成的文本中过于频繁地重复相同的单词或短语,默认值为0.7
- • ragflow给了我们三组参数
- • 系统提示词
6,通过提示词我们来指定模型的能力,一般会结合输入,需要注意的是ragflow不能通过{来快捷的获取变量引用 - • 引用,主要用于多轮会话,是否引用以前的内容,12是引用多少个窗口,这个和token相结合
- • 通过
7新增变量以后,才可以在组件内使用,和dify一样
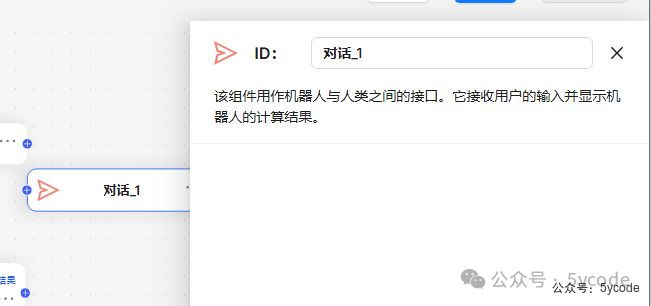
Interact(对话)组件
该组件用作机器人与人类之间的接口。它接收用户的输入并显示机器人的计算结果。
Categorize(问题分类)组件
此组件用于对文本进行分类。请指定类别的名称、描述和示例。每个类别都指向不同的下游组件。问题分类,你可以理解为是条件判断的增强,条件判断是基于具体的值,问题分类是使用大模型根据问题描述,以及示例,推导出的分类,并指向对应的流程。
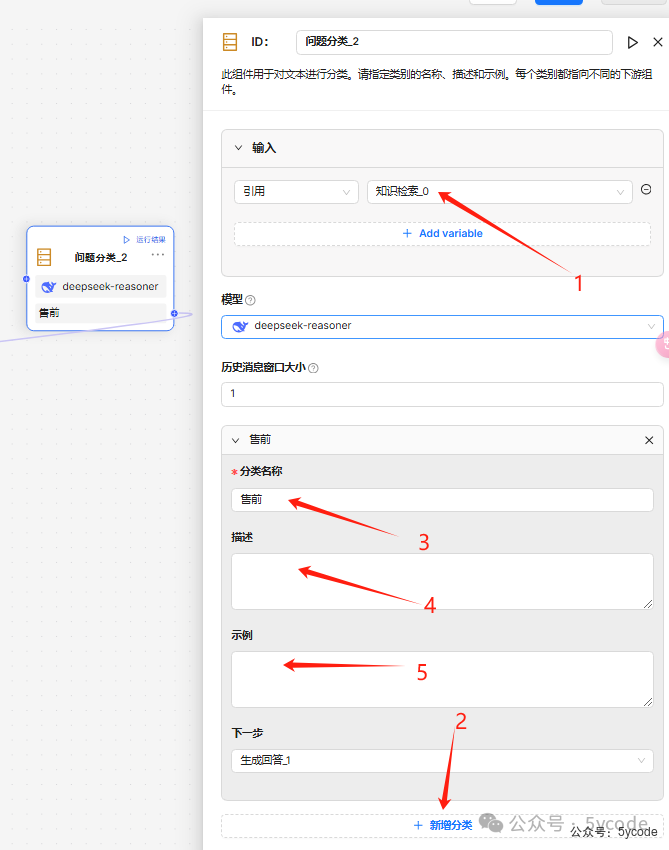
- • 引用节点输出
1并不是一个结构化的输出, - • 模型参数的调整和生成回答一样
- • 通过
3和4、5设置大概什么情况归到这个分类。
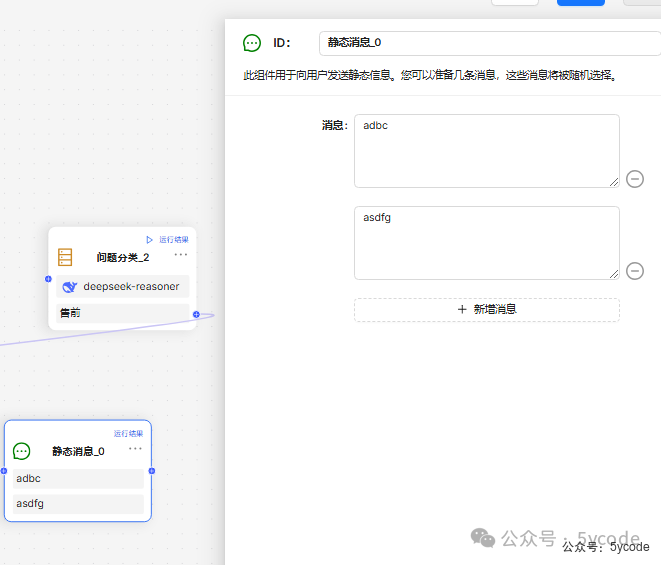
Message (静态消息)组件
此组件用于向用户发送静态信息。您可以准备几条消息,这些消息将被随机选择。
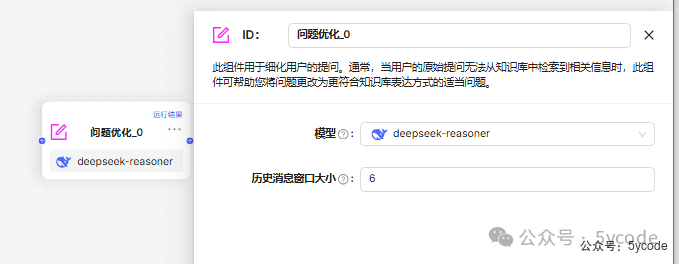
Rewrite(问题优化)组件
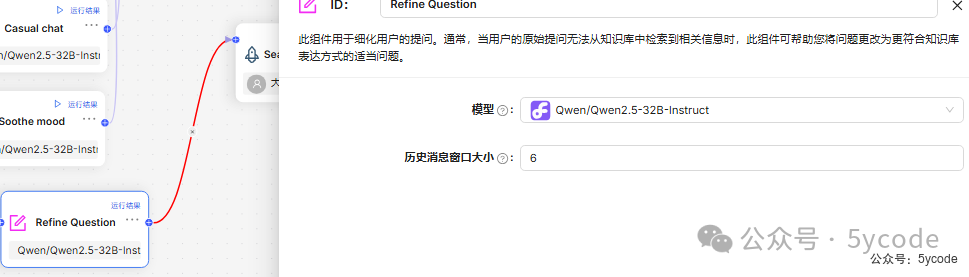
此组件用于细化用户的提问。通常,当用户的原始提问无法从知识库中检索到相关信息时,此组件可帮助您将问题更改为更符合知识库表达方式的适当问题。
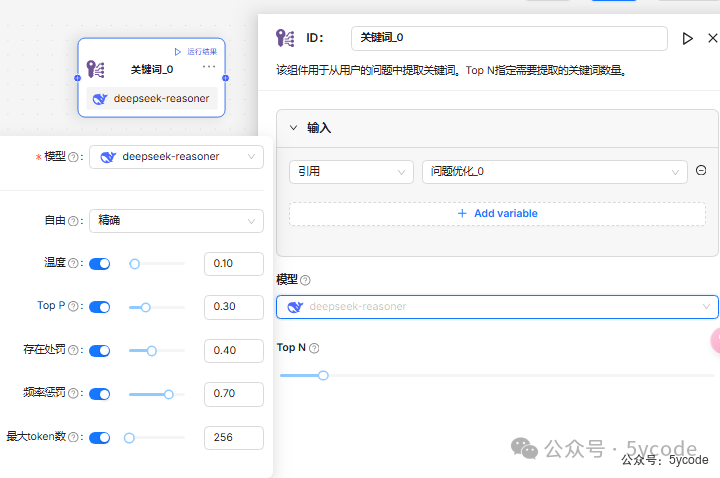
keyword( 关键词 )组件
该组件用于从用户的问题中提取关键词。Top N指定需要提取的关键词数量。比如用于我们之前的从数据库查询知识的场景,不用我们去处理了。
Switch(条件)组件
该组件用于根据前面组件的输出评估条件,并相应地引导执行流程。通过定义各种情况并指定操作,或在不满足条件时采取默认操作,实现复杂的分支逻辑。
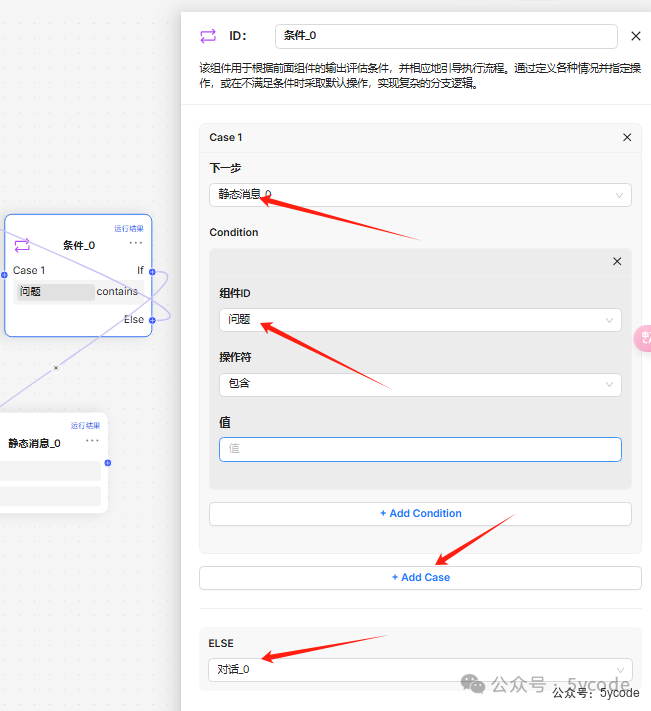
这里可以通过引用组件的输出值作为比较条件,可以添加多个条件,且支持逻辑操作符。
Concentrator(集线器)组件
该组件可用于连接多个下游组件。它接收来自上游组件的输入并将其传递给每个下游组件。
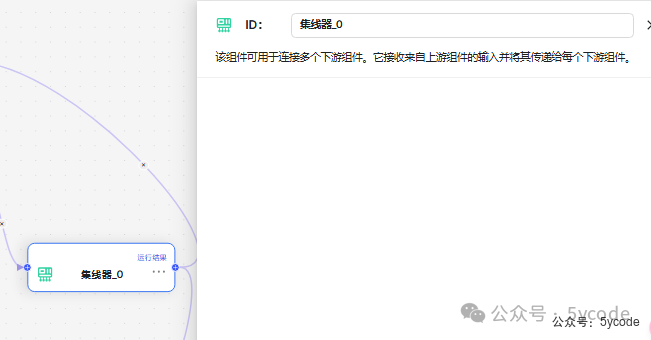
在ragflow中,有些节点的输出,只能指向一个节点,如果你需要并行操作的时候,需要添加集线器。
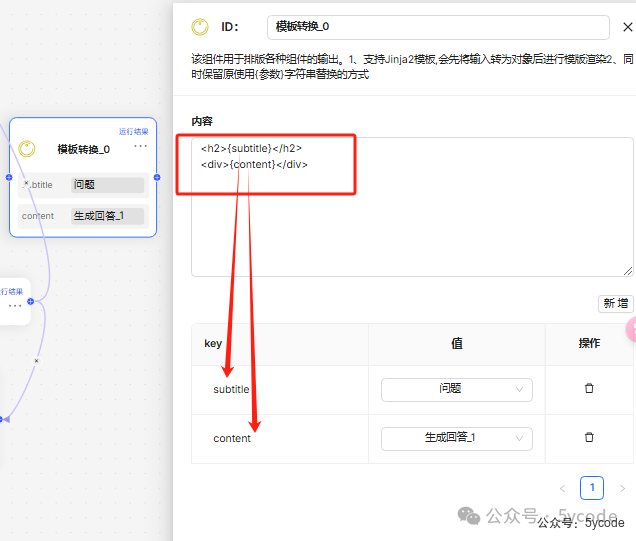
Template(模板转换)组件
该组件用于排版各种组件的输出。有助于将各种数据或信息源组织成特定格式,便于后续处理和展示
-
• 1、支持Jinja2模板,会先将输入转为对象后进行模版渲染
-
• 2、同时保留原使用{参数}字符串替换的方式
(循环)组件
该组件首先将输入以“分隔符”分割成数组,然后依次对数组中的元素执行相同的操作步骤,直到输出所有结果,可以理解为一个任务批处理器。 例如在长文本翻译迭代节点中,如果所有内容都输入到LLM节点,可能会达到单次对话的限制,上游节点可以先将长文本分割成多个片段,配合迭代节点对每个片段进行批量翻译,避免达到单次对话的LLM消息限制。
高级应用组件
高级应用组件主要是封装了一些能力。这些是我给它分的类,没看到官方的文档。主要以实际应用为主。这次简单的过一下功能,以及大致的用户,具体的使用还得具体使用的时候验证

invoke(Http)组件
该组件可以调用远程接口调用。将其他组件的输出作为参数或设置常量参数来调用远程函数。
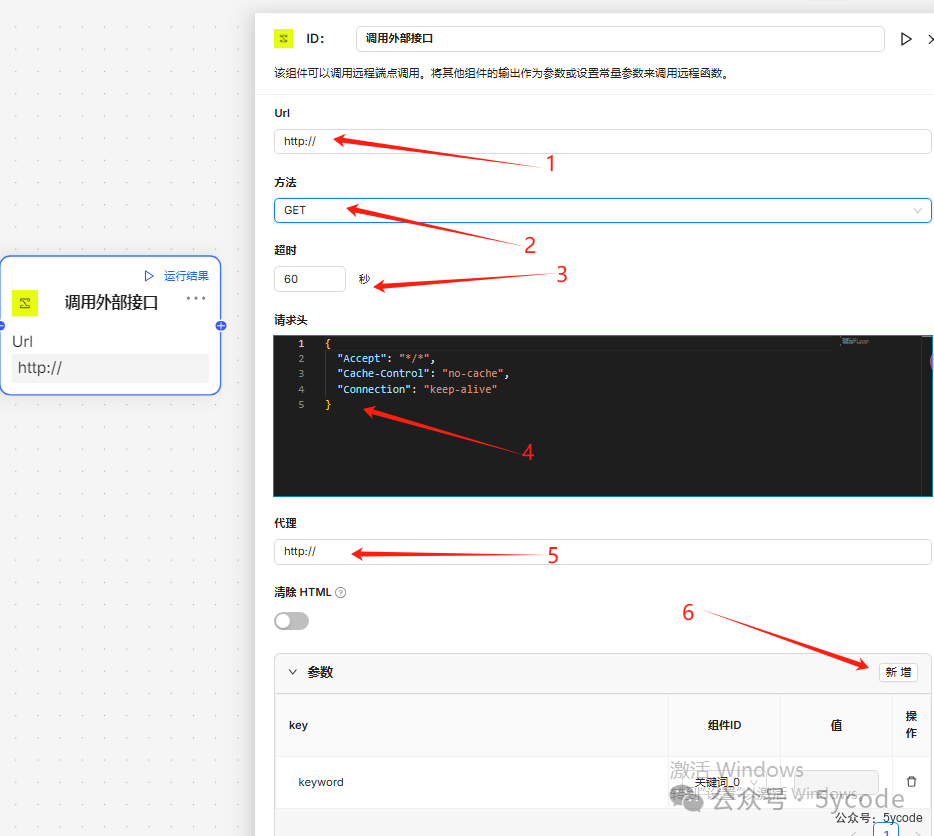
- • 我们可以通过
1设置请求地址 - • 请求方法
2中目前只支持get、post、put三种方法 - •
3可以自定义超时时间 - • 可以在
4自定义请求头 - • 可以通过
5设置代理 - • 通过
6可以新增请求参数
通过这个invoke组件,明显感受到设计这块的人,并没有考虑其他语言的通用性,典型的python接口规范。也不知道是不是实现比较复杂。
另一个方面,对于结构化数据,我们该返回一个什么样的格式?有没有特殊的要求?未知,只能自己去摸索。
网页爬虫
该组件可用于从指定url爬取html源码。
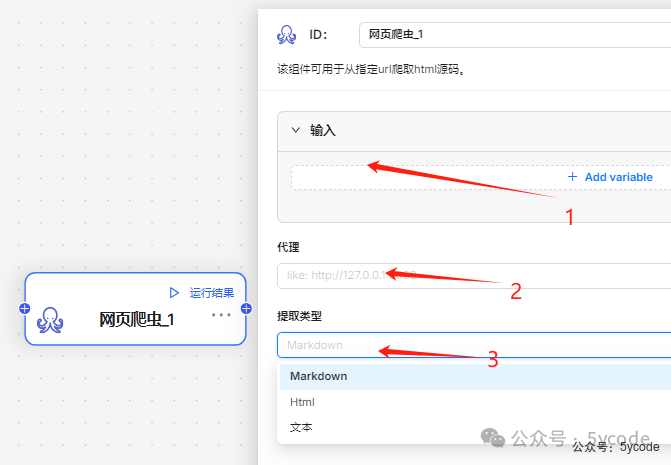
爬取的内容,我们可以指定提取的类型。
邮箱
发送邮件到指定邮箱
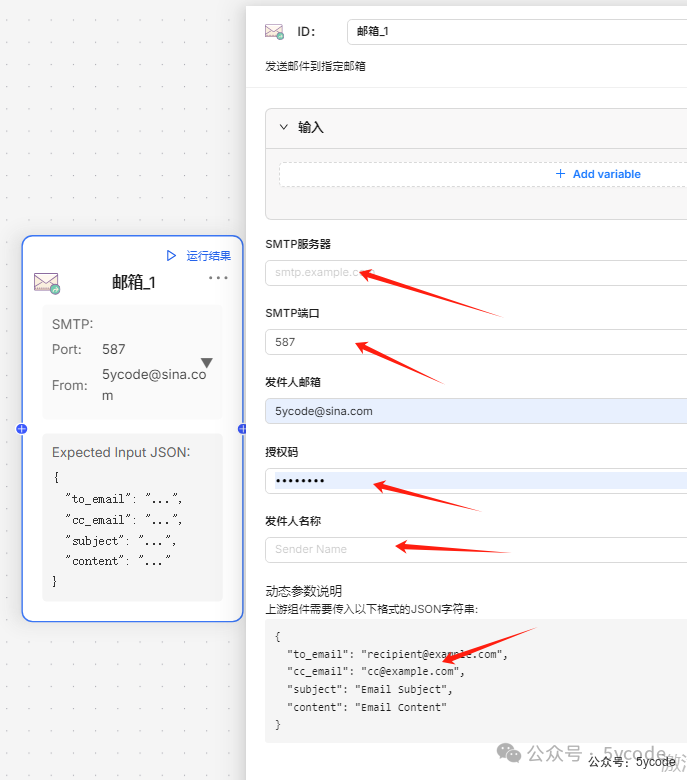
使用的前提是需要模板化转成对应的json数据。那么问题来了,如果你没有结构化的数据,这些变量该如何提取?总不能每次固定或者内置吧,压根不考虑通用性。这只适合给固定的人发邮件。
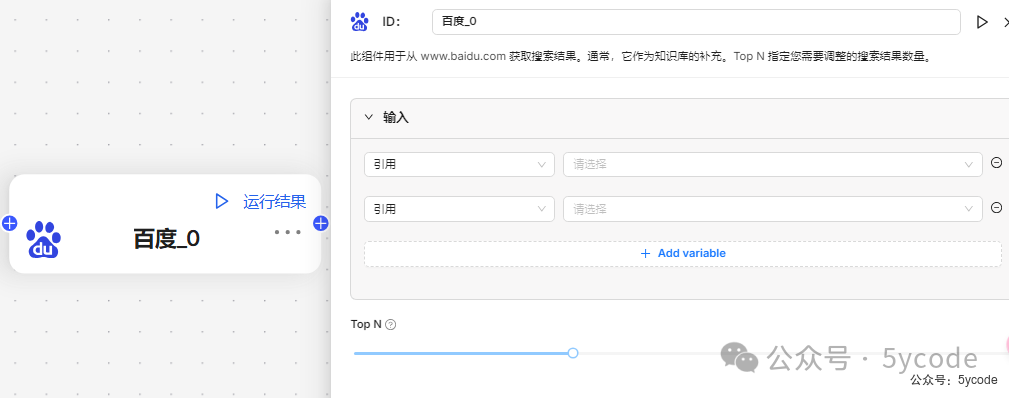
ExeSQL 组件
该组件通过SQL语句从相应的关系数据库中查询结果。支持MySQL,PostgreSQL,MariaDB。
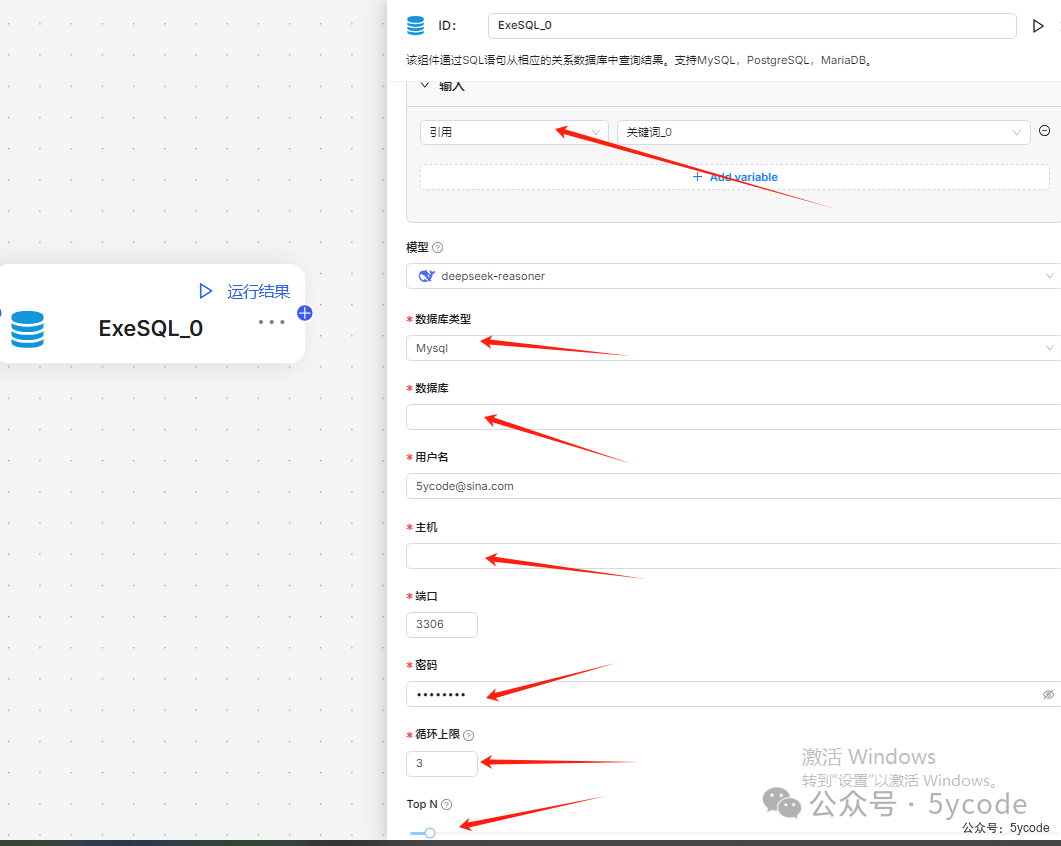
通过界面盲猜
- • 需要在调用这个插件之前把sql准备好
- • 想不明白,这点用大模型的意图,难道是数据查询出来以后大模型进行处理?
- • 下面就是连接数据库的参数
- •
Top N,默认值30,难道大模型在这里是将查到的数据进行过滤?但是没有填写怎么过滤的地方。
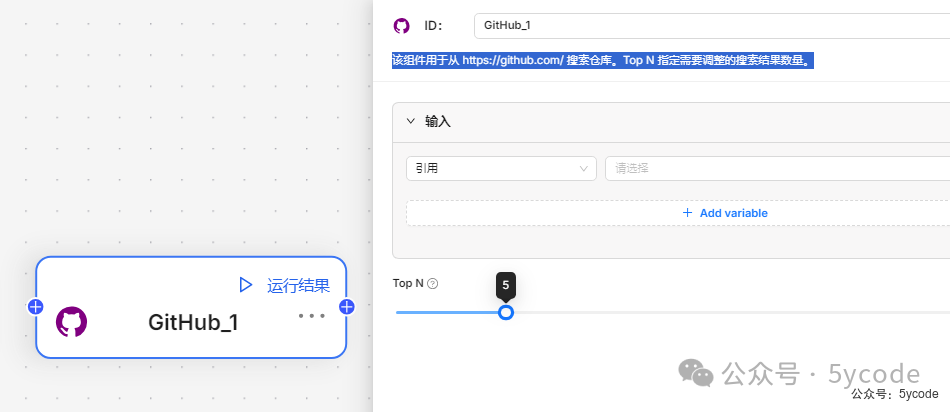
GitHub 插件
该组件用于从 https://github.com/ 搜索仓库。Top N 指定需要调整的搜索结果数量。
搜索、翻译、学术
还提供了搜索、翻译、学术相关的组件,具体怎么用,只能靠盲猜。后续结合官方的示例琢磨下。
通过上面的组件,我们可以看到ragflow的交互难度,对与小白用户不友好,以前觉的腾讯元器的agent死难用,看了这个,觉的,嗯,腾讯的还行。
智能体应用
我们结合一个官方的agent示例,简单的了解下
使用客服模板创建。
流程示例
梳理了下示例
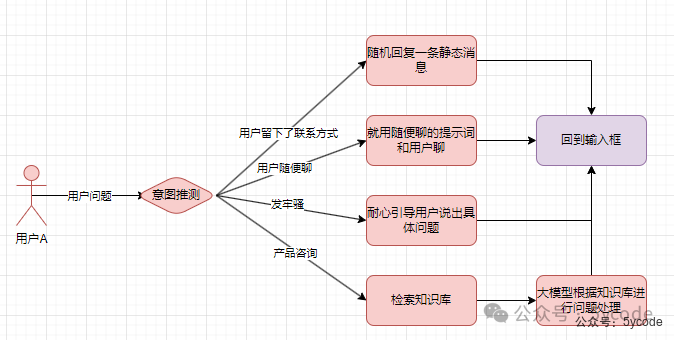
先看下整体流程
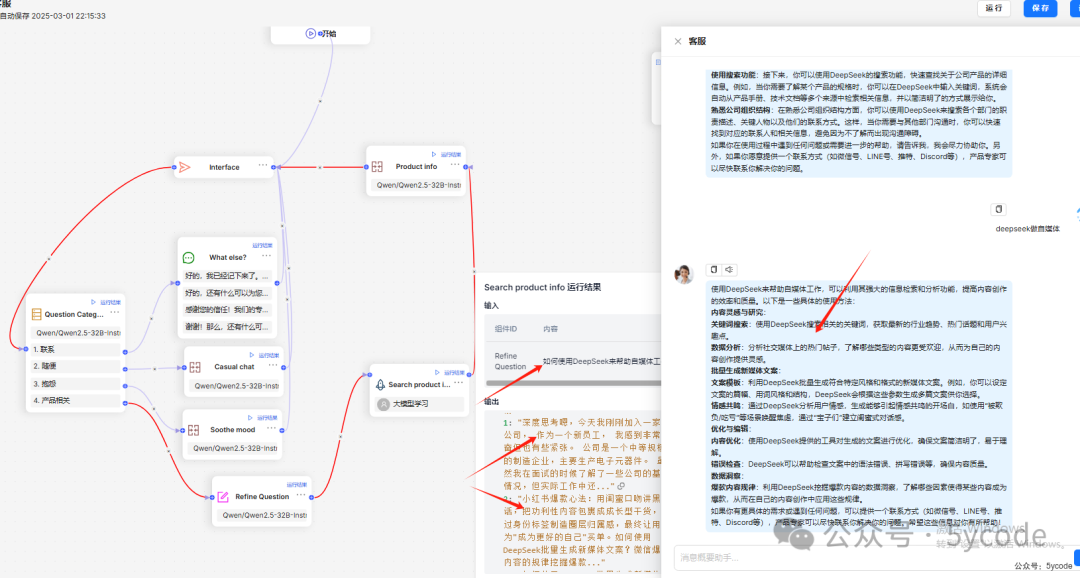
- • 红色的线代表整个运行流程。
- • 在这个过程中把问题也细化了
- • 也检索到了对应的内容
- • 一旦关闭了右侧的聊天框,再打开就没了,就体验来说和dify差的太多。
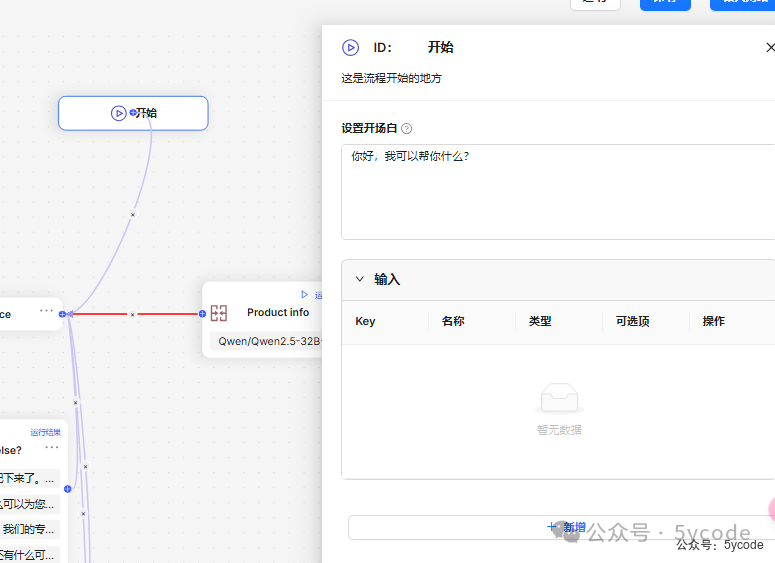
开始节点
作为交互程序,开始节点不需要设置什么。只设置好开白场即可。
问题分类
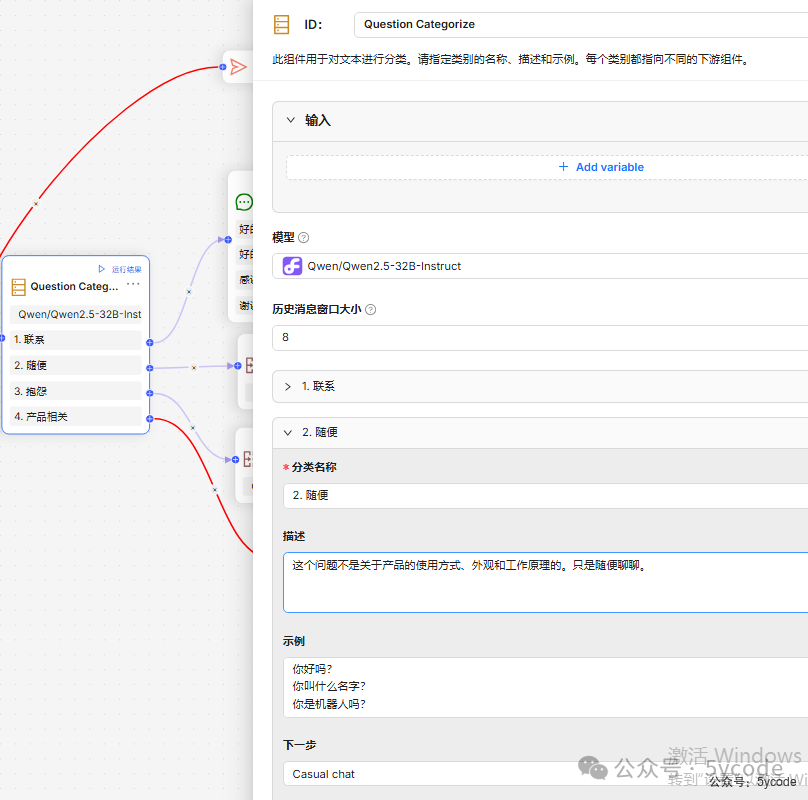
在每个分类下,都有对应的描述,和示例,32b的模型能流畅的运行。
随便聊聊
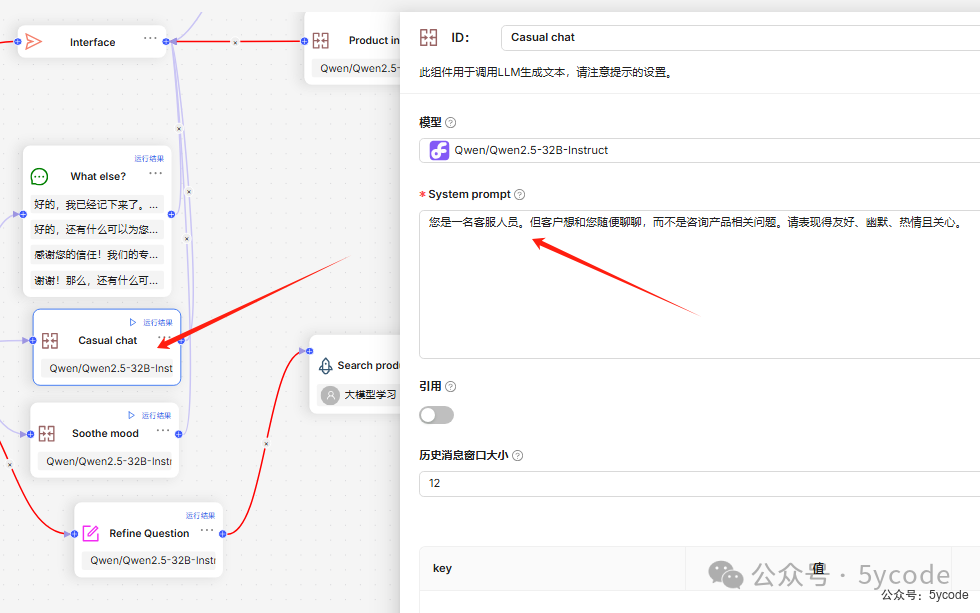
缓解抱怨
细化问题
知识检索
根据知识库推导
发布应用
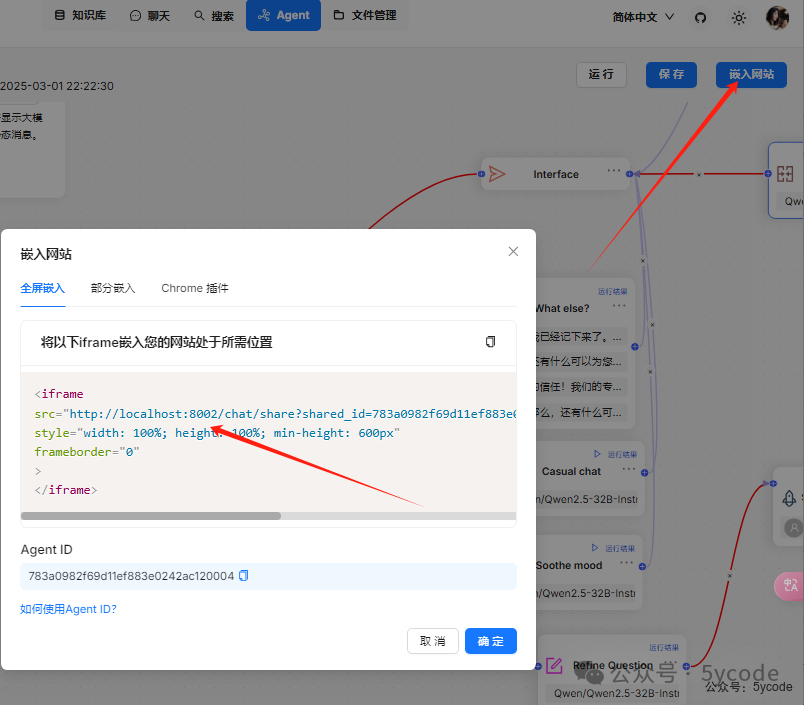
点击右上角的嵌入网站,我们可以看到一串html代码,我们把http连接拿到,直接在浏览器里可以访问。
总结
- • ragflow的的官方文档相对来说还是比较欠缺的,特别是用户交互这块。
- • ragflow的ui使用成本相对比较高,组件不知道返回什么,只能根据示例或意图推断
- • 使用ragflow建议是有技术底子的
链图片转存中…(img-0iuaLPfA-1746154024394)]
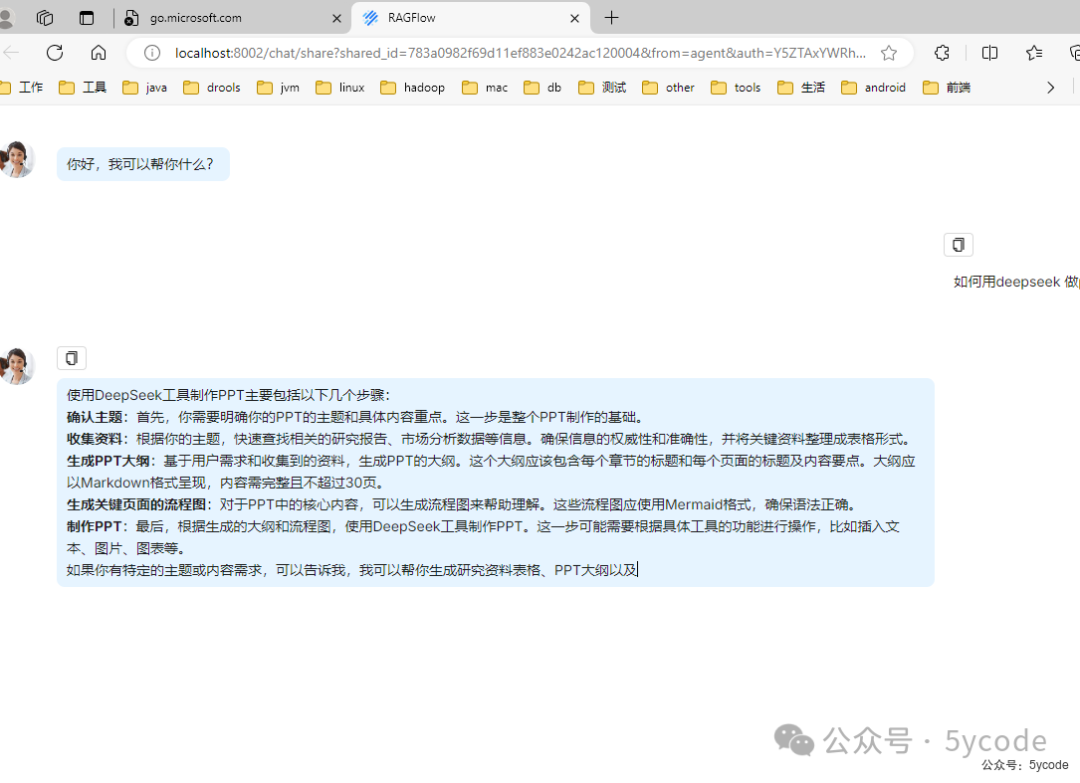
点击右上角的嵌入网站,我们可以看到一串html代码,我们把http连接拿到,直接在浏览器里可以访问。
[外链图片转存中…(img-LXkNsshY-1746154024394)]
总结
- • ragflow的的官方文档相对来说还是比较欠缺的,特别是用户交互这块。
- • ragflow的ui使用成本相对比较高,组件不知道返回什么,只能根据示例或意图推断
- • 使用ragflow建议是有技术底子的
- • 英文文档的描述习惯和中文还是有很大的差别的
如何学习AI大模型?
大模型的发展是当前人工智能时代科技进步的必然趋势,我们只有主动拥抱这种变化,紧跟数字化、智能化潮流,才能确保我们在激烈的竞争中立于不败之地。
那么,我们应该如何学习AI大模型?
对于零基础或者是自学者来说,学习AI大模型确实可能会感到无从下手,这时候一份完整的、系统的大模型学习路线图显得尤为重要。
它可以极大地帮助你规划学习过程、明确学习目标和步骤,从而更高效地掌握所需的知识和技能。
这里就给大家免费分享一份 2025最新版全套大模型学习路线图,路线图包括了四个等级,带大家快速高效的从基础到高级!




如果大家想领取完整的学习路线及大模型学习资料包,可以扫下方二维码获取

👉2.大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。(篇幅有限,仅展示部分)

大模型教程
👉3.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(篇幅有限,仅展示部分,公众号内领取)

电子书
👉4.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(篇幅有限,仅展示部分,公众号内领取)

大模型面试
**因篇幅有限,仅展示部分资料,需要的扫描下方二维码领取 **


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











