










背景
之前写了一些知识库的文章,最后试用了dify,想着前端dify+企业自己的向量数据,随时可以切换前端应用,觉得很香。有些朋友向我案例ragflow。
试用完以后我发现,我想复杂了,定制企业向量数据库,ragflow完全能够满足,简单调整下,成本最低。功能实在是太强大了.
🌟 ragflow主要功能
🍭 “Quality in, quality out”
-
• 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。
-
• 真正在无限上下文(token)的场景下快速完成大海捞针测试。
🍱 基于模板的文本切片
-
• 不仅仅是智能,更重要的是可控可解释。
-
• 多种文本模板可供选择
🌱 有理有据、最大程度降低幻觉(hallucination)
-
• 文本切片过程可视化,支持手动调整。
-
• 有理有据:答案提供关键引用的快照并支持追根溯源。
🍔 兼容各类异构数据源
- • 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
🛀 全程无忧、自动化的 RAG 工作流
-
• 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
-
• 大语言模型 LLM 以及向量模型均支持配置。
-
• 基于多路召回、融合重排序。
-
• 提供易用的 API,可以轻松集成到各类企业系统。
🔎 系统架构
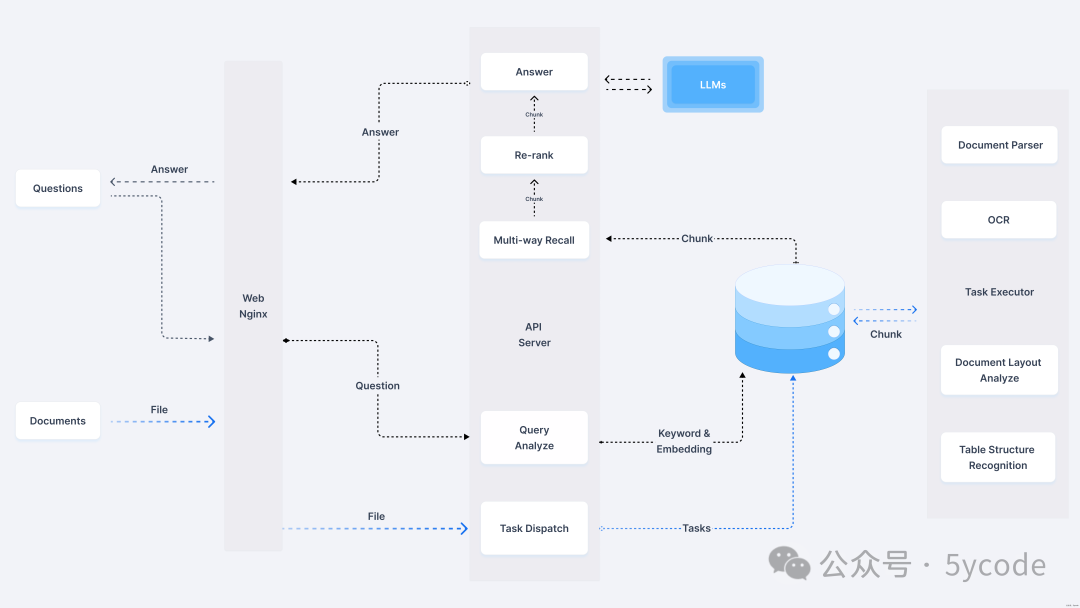
安装
硬件要求
-
• CPU >= 4 核
-
• RAM >= 16 GB
-
• Disk >= 50 GB
-
• Docker >= 24.0.0 & Docker Compose >= v2.26.1
软件要求:
vm.max_map_count 不小于 262144,这个是针对linux
下载代码
git clone https://github.com/infiniflow/ragflow.git
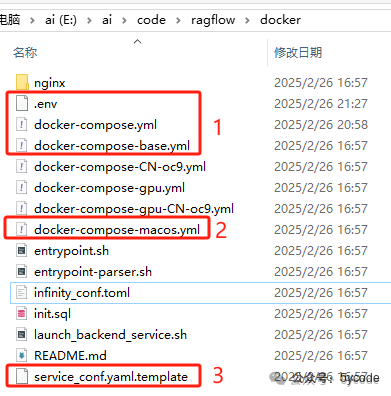
我们看下docker目录中的文件,主要关注圈中的3块
-
•
.env主要是docker部署的时候一些变量,service_conf.yaml.template是服务启动使用的配置文件,需要和.env文件里的配置对应,特别是端口 -
• 需要注意的是,在mac操作系统下,会引入
2
|
镜像tag
|
镜像大小(GB)
|
是否有向量模型?
|
是否稳定版版?
|
| — | — | — | — |
|
v0.16.0
|
≈9
|
✔️
|
稳定
|
|
v0.16.0-slim
|
≈2
|
❌
|
稳定
|
|
nightly
|
≈9
|
✔️
|
不稳定,每晚构建
|
|
nightly-slim
|
≈2
|
❌
|
不稳定,每晚构建
|
关键参数
.env文件
#文档引擎,默认使用es DOC_ENGINE=${DOC_ENGINE:-elasticsearch} #docker部署的镜像,默认不带模型 RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0-slim #redis端口,6379,我本机以及docker已经有了,我改程了6380 REDIS_PORT=6380 #服务端端口 SVR_HTTP_PORT=9380 #自定义了两个变量,nginx的暴露端口 EXPOSE_NGINX_PORT=8002 EXPOSE_NGINX_SSL_PORT=8444 #如果你需要在docker中拉取模型,网有不好,添加此镜像,将前面的#去掉 # HF_ENDPOINT=https://hf-mirror.com #mac系统需要将此参数放开,默认禁用,将前面的#去掉就开启了 # MACOS=1
需要注意的是.env文件修改后,对应的service_conf.yaml.template配置中一些默认值也得改变。比如我们改了redis的端口,
`#将redis的端口由6379改成6380 redis: db: 1 password: '${REDIS_PASSWORD:-infini_rag_flow}' host: '${REDIS_HOST:-redis}:6380'`
拉取镜像
# 拉取镜像 docker compose pull
如果拉不到,网络不稳定,替换国内的镜像
` - 华为云镜像名:`swr.cn-north-4.myhuaweicloud.com/infiniflow/ragflow` - 阿里云镜像名:`registry.cn-hangzhou.aliyuncs.com/infiniflow/ragflow` `
启动
我们通过-p指定分组名称,或者在docker-compose.yaml中添加name: 'ragflow'
docker compose up -d -p ragflow
等一会,安装过程只遇到了端口冲突的问题,修改下端口即可。
通过docker ps或docker desktop 软件查看启动状态。
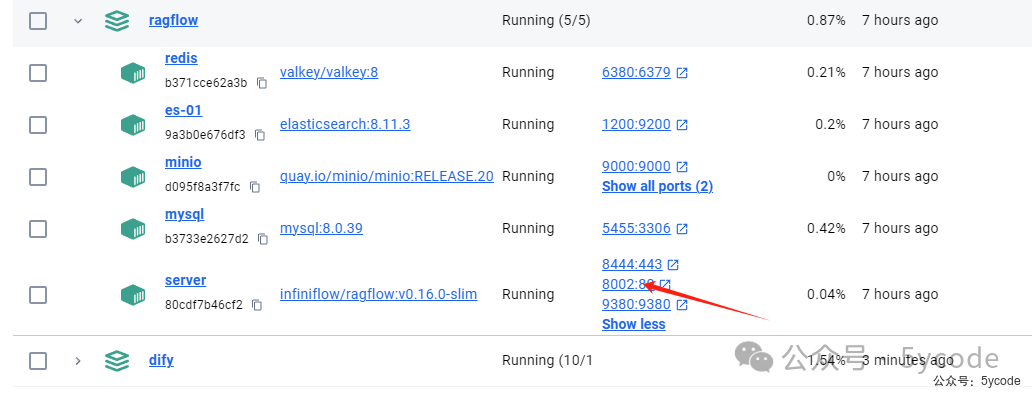
登录
点击docker desktop或者http://localhost:8002/就进入了登录注册界面。
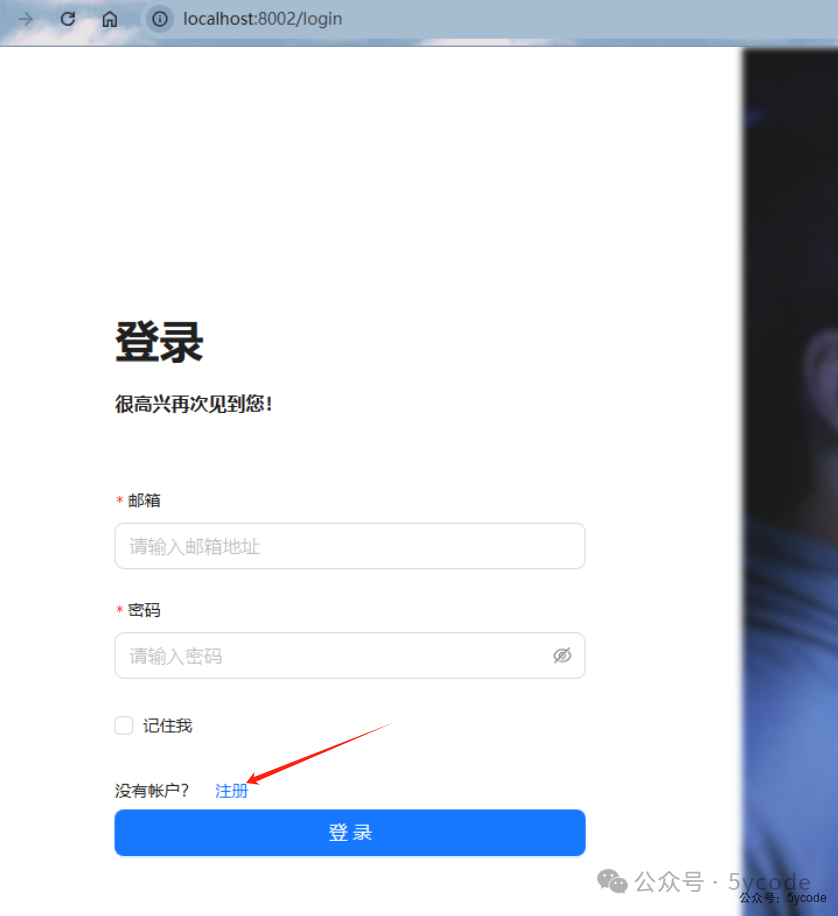
上来是没有账户的,我们先点击注册一个,然后登录。
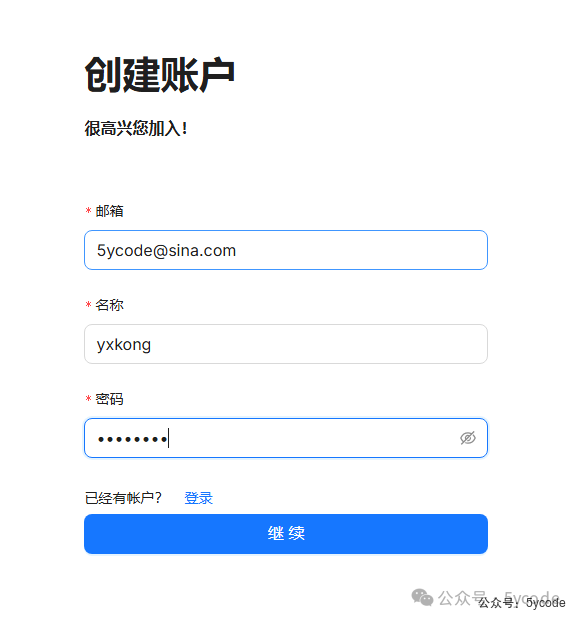
基本设置
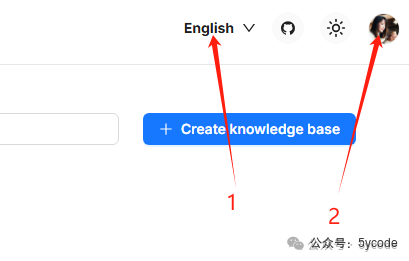
登录进来以后,我们先将右上角的1设置为简体中文,然后点击2
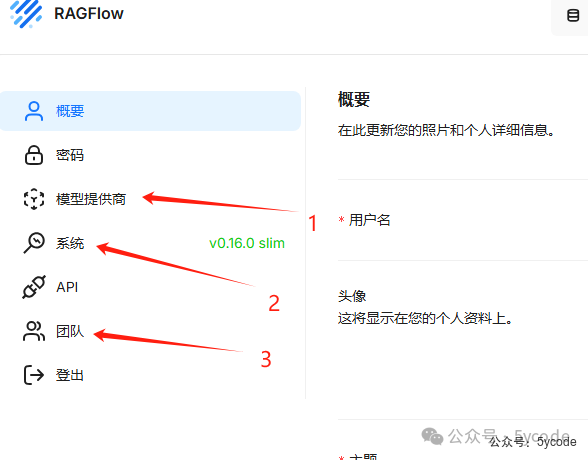
我们主要关注1模型供应商和3团队即可。可以通过2查看系统的资源概况,以及任务数。
点击1我们开始添加模型
模型配置
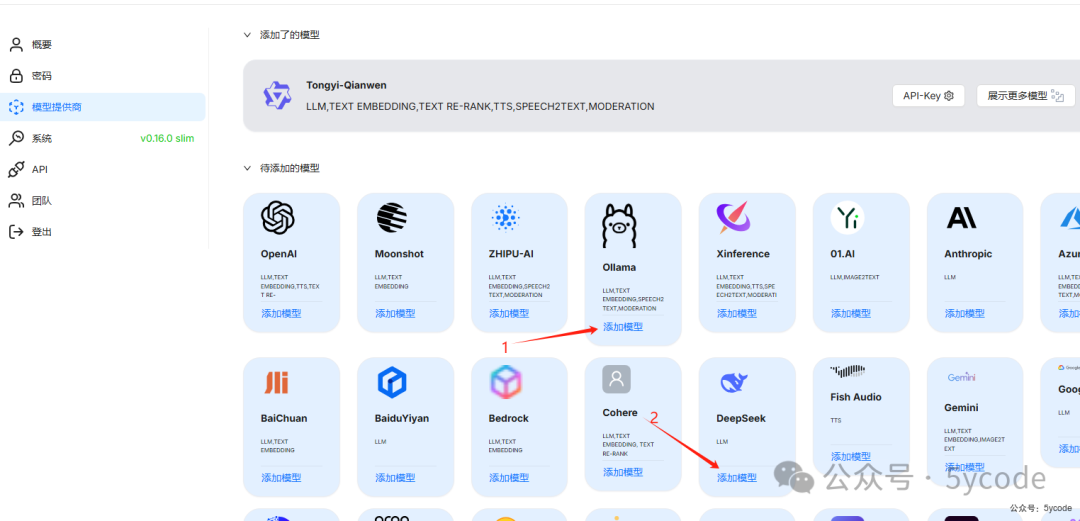
官方默认推荐通义,应该是合作了,我们添加本地ollama和刚充值的热乎的deepseek.
本地Ollama 模型配置
在ragflow中,ollama的模型类型可以选择4个,其实也就比dify多了一个reran模型,
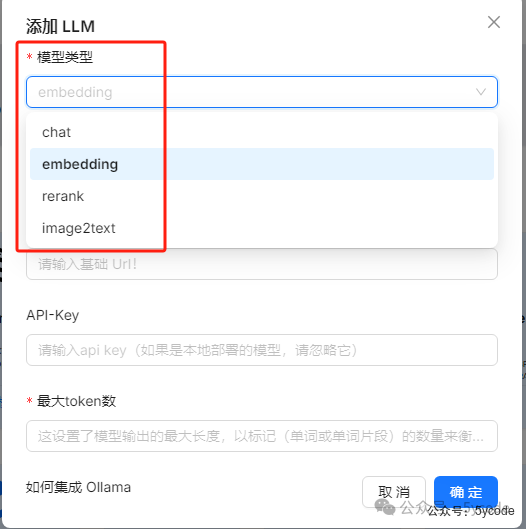
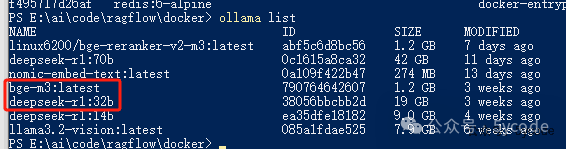
通过ollama listt查看模型列表,然后添加两个一个chat模型,一个embedding模型。
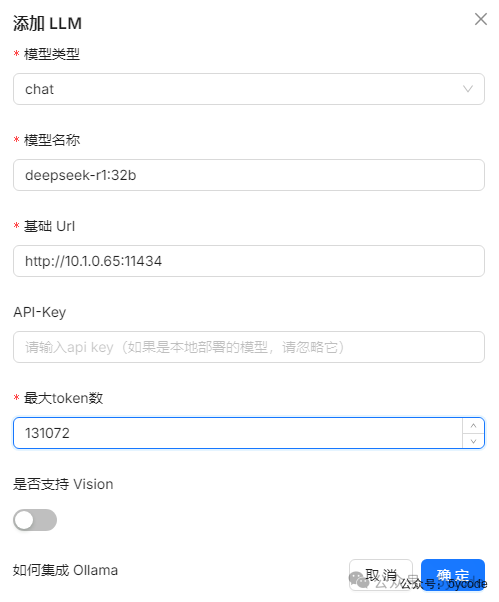
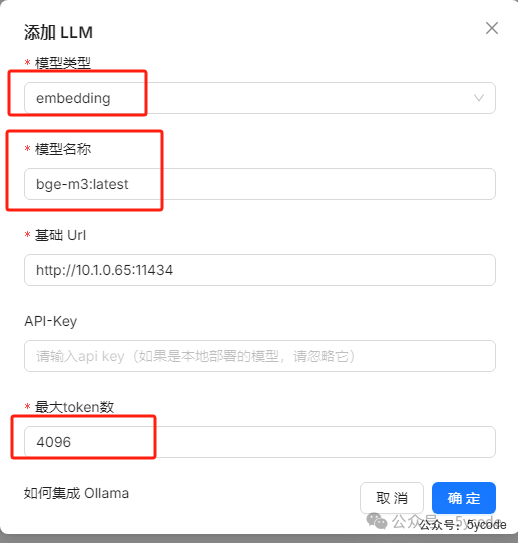
最大token我们通过ollama show deepseek-r1:32b获取后填入。然后保存。
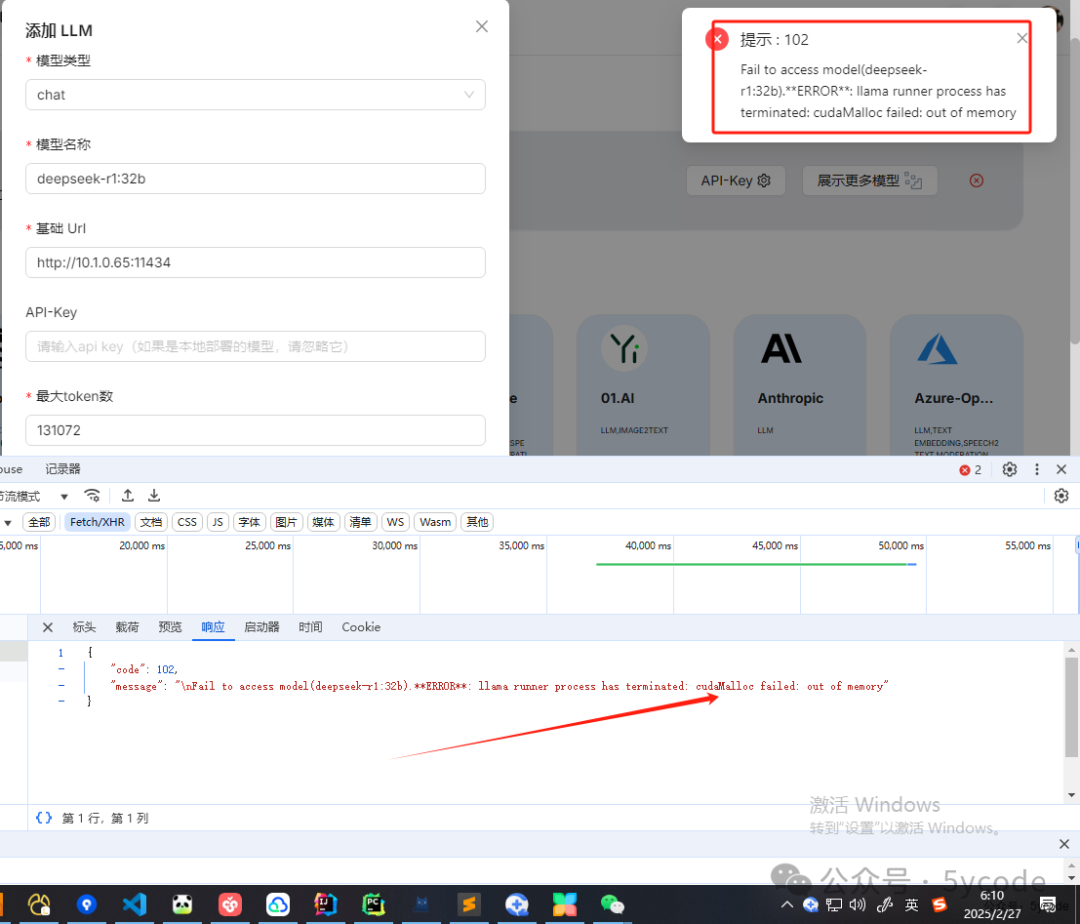
报错了了,一看cudaMalloc failed: out of memory,一看内存81%了,空余12g的内存竟然不够用。赶紧关一些软件。
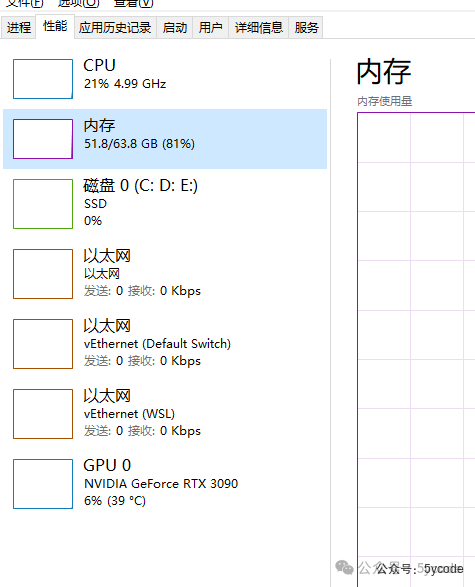
然后再保存。成功。然后点击添加向量模型。

添加DeepSeek
很简单,就填写一个api-key就行了。
系统模型配置
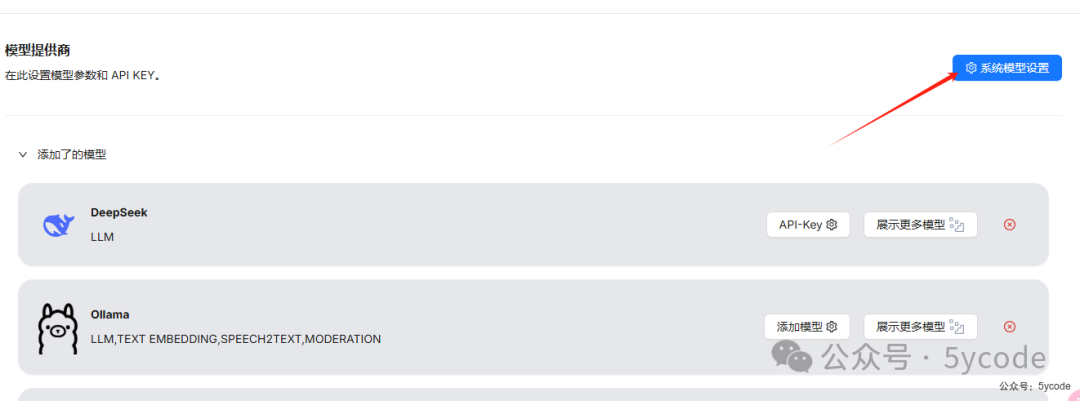
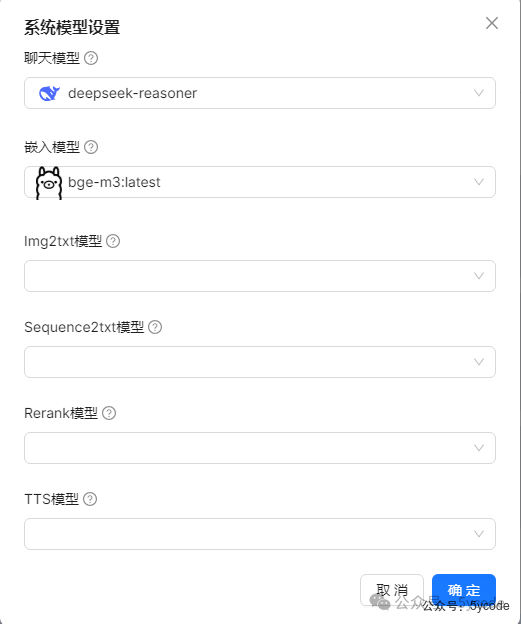
选择相应的模型即可。
团队
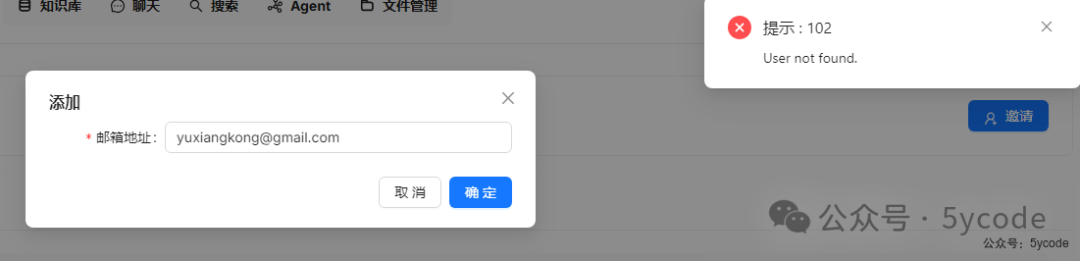
我点击右上角的邀请,填写用户邮箱,点击确定。提示用户不存在。
我猜测,应该是注册制,注册以后再邀请进团队。
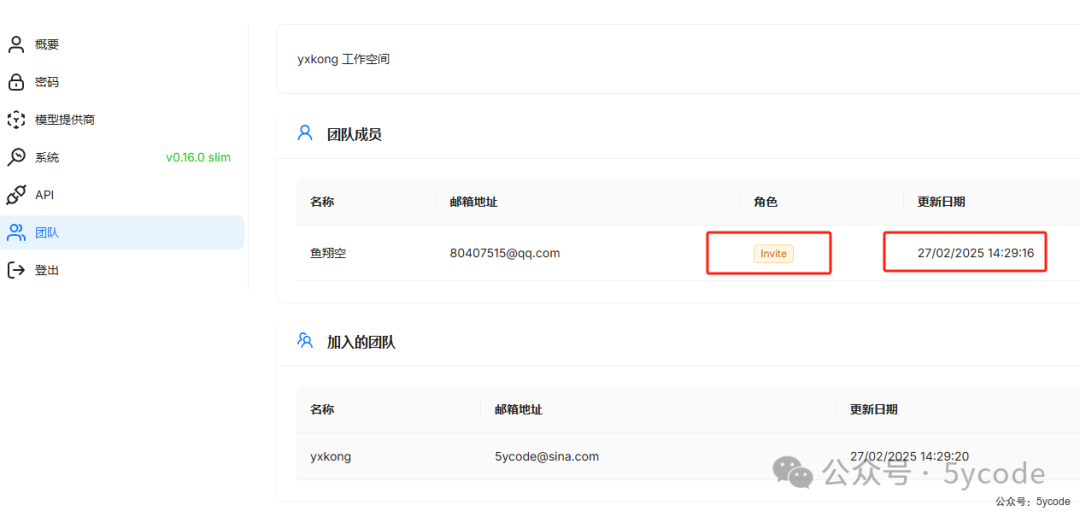
然后角色是Invite,时间也有问题。应该是数据库的时区的问题。在.env中TIMEZONE配置的是shanghai时区。这个不太影响,下次再看下。
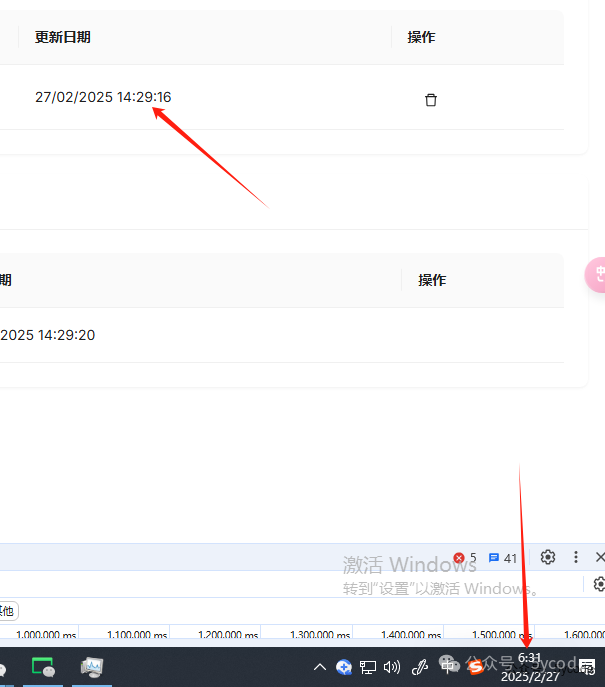
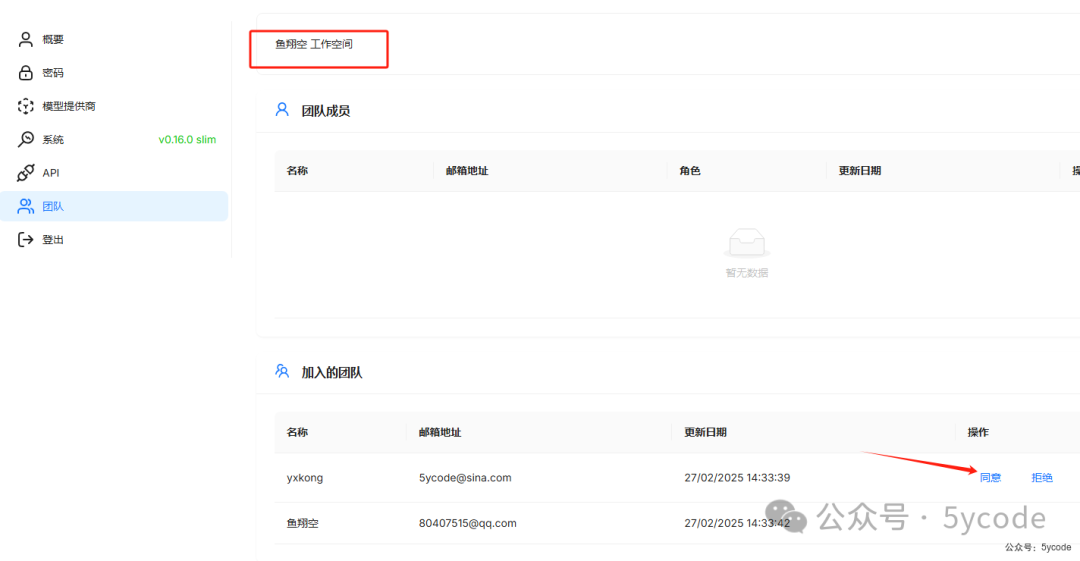
然后我就很好奇,另外一个用户里是什么?我登录了另外一个账户,原来邀请的用户还得同意。
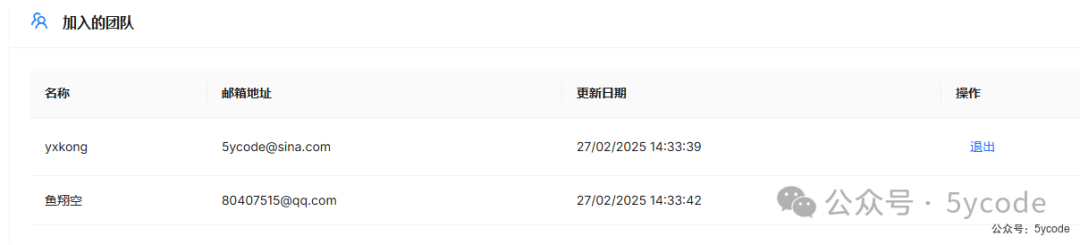
同意以后,还可以退出。我再切换到原来的账户里,
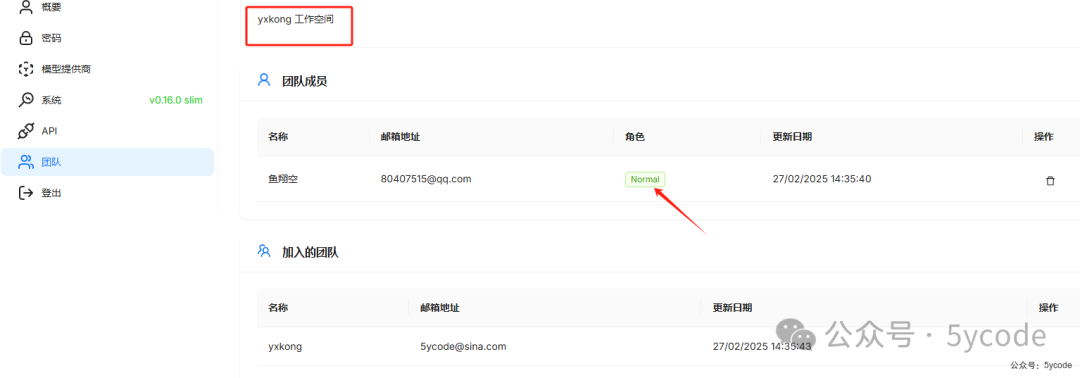
发现角色变成了Normal
需要注意的是,团队共享了知识库,但是聊天助理并没有共享,模型也没有共享。
不过想想也对,创建的应用可以通过api分享,出来,共用的功能,设置都不需要邀请用户。知识反而是核心。我的理念和他好像。哈哈。
功能概述

从面板上看,就几个功能。还是很清晰,它的模板特别少,在创建agent的时候可以选择。
知识库
创建知识库
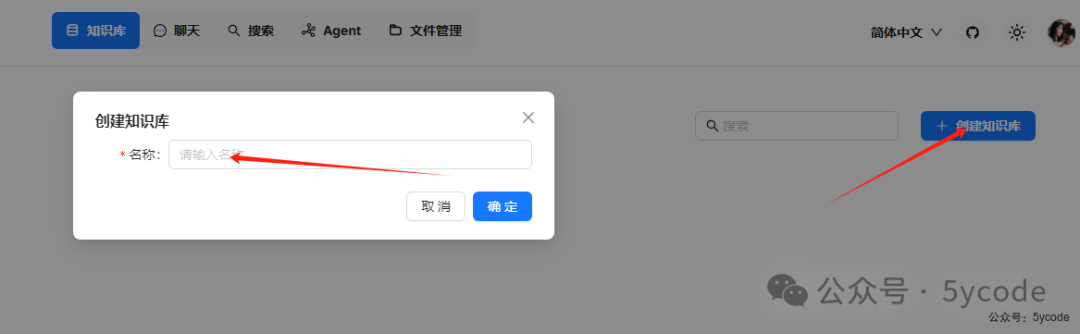
点击创建知识库,填写名称,点确定即可。
这个时间反而是准的。
知识库配置
配置
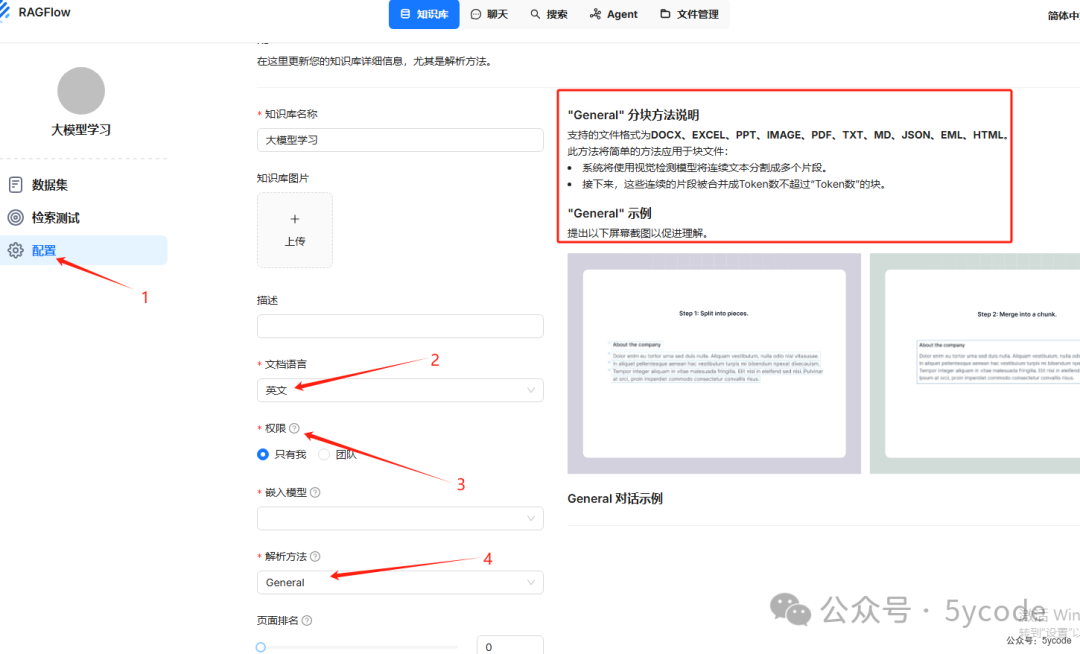
-
• 点击
1的配置, -
• 我们可以指定文档语言
2 -
• 也可以设置这个知识库的权限
3 -
• 可以自定义解析方法
4,而且每个解析方法后面都有对应的示例说明。是不是用它内置的向量模型会更好一些?
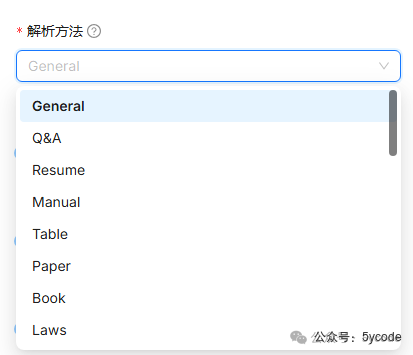
解析方法类型
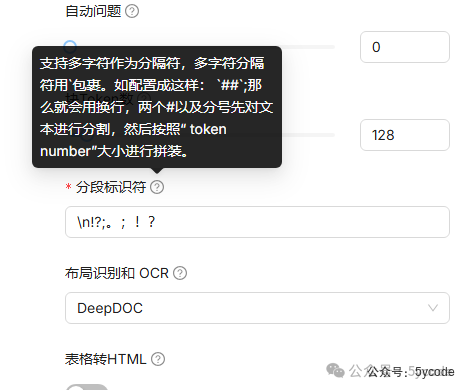
分段标识符,支持多字符作为分隔符,这对复杂格式的文档,也太友好了。还能有布局识别和OCR功能。
知识上传(数据集)
在ragflow中上传的在数据集模块里。
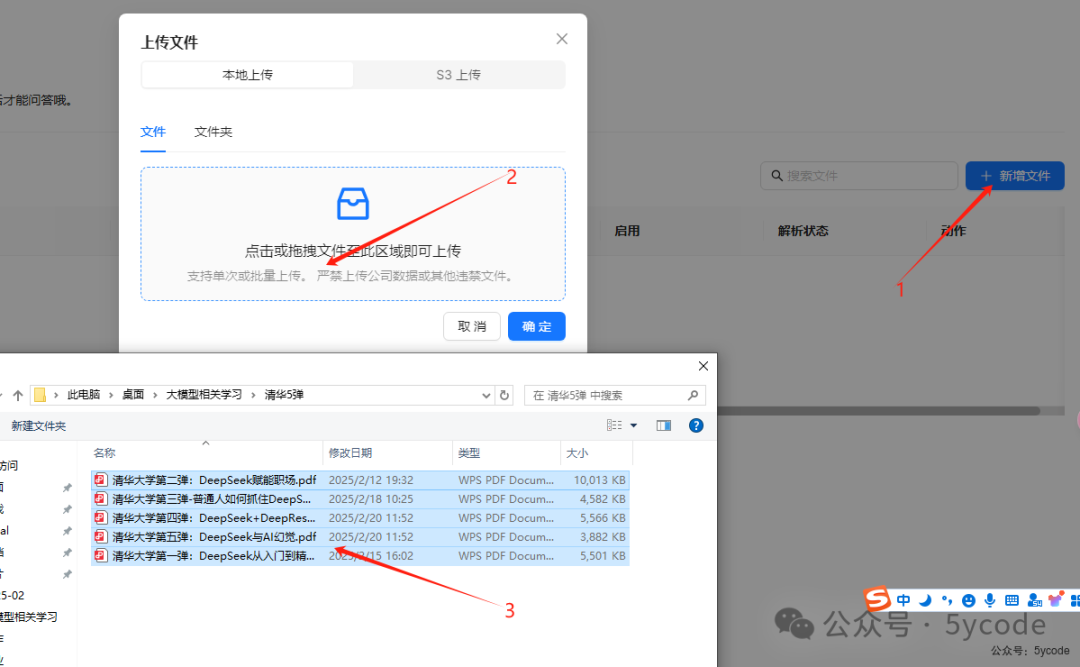
ragflow的知识库,只支持和上传文件或s3同步。同时可以一次上次多个知识。提示也很友好严禁上传公司数据或其他违禁文件。
上传以后不会自动解析,需要手动点击。
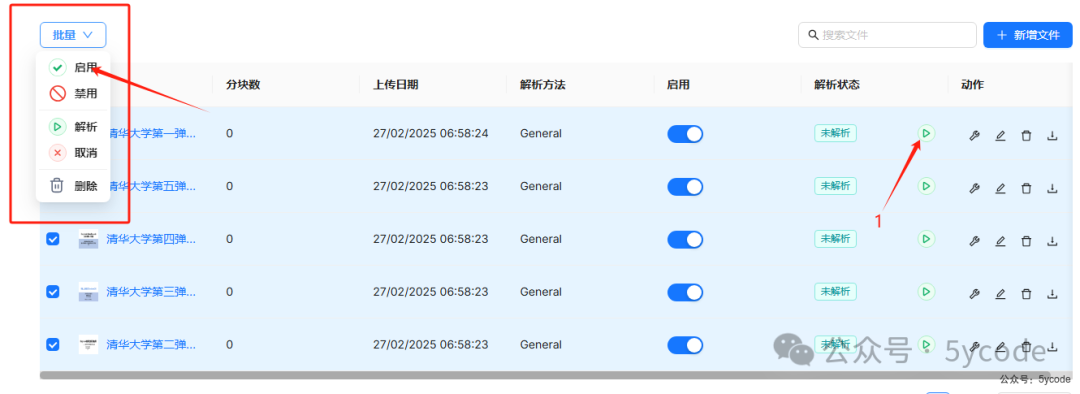
可以通过1单个解析,也可以通过勾选多个,批量解析。
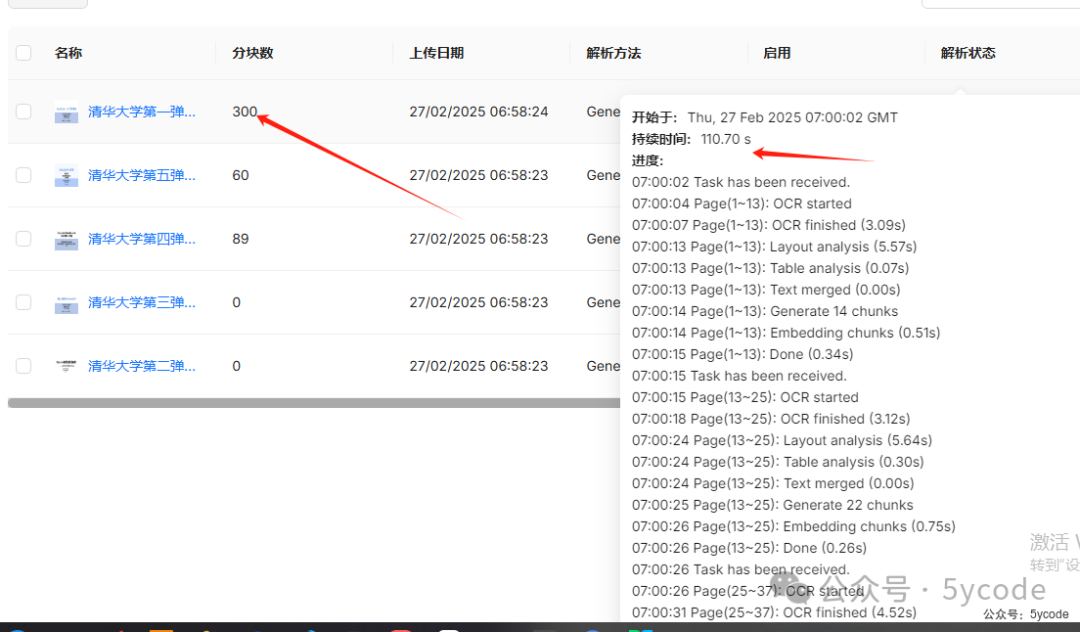
默认规则下,解析速度还行,清华大学第一弹一共104页,解析了110秒。
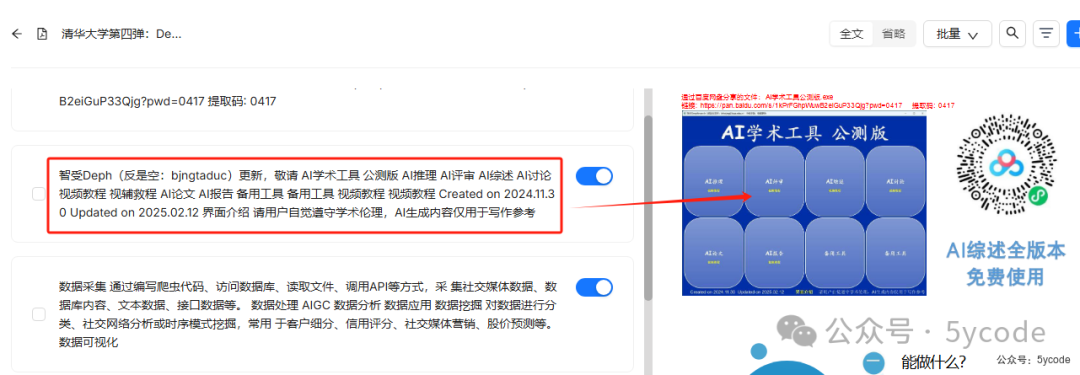
然后看了下分段效果。点开一看,太强大了图片内容也解析出来了。《清华大学第四弹》的内容。
我没有使用ocr呀,这个后续再研究。
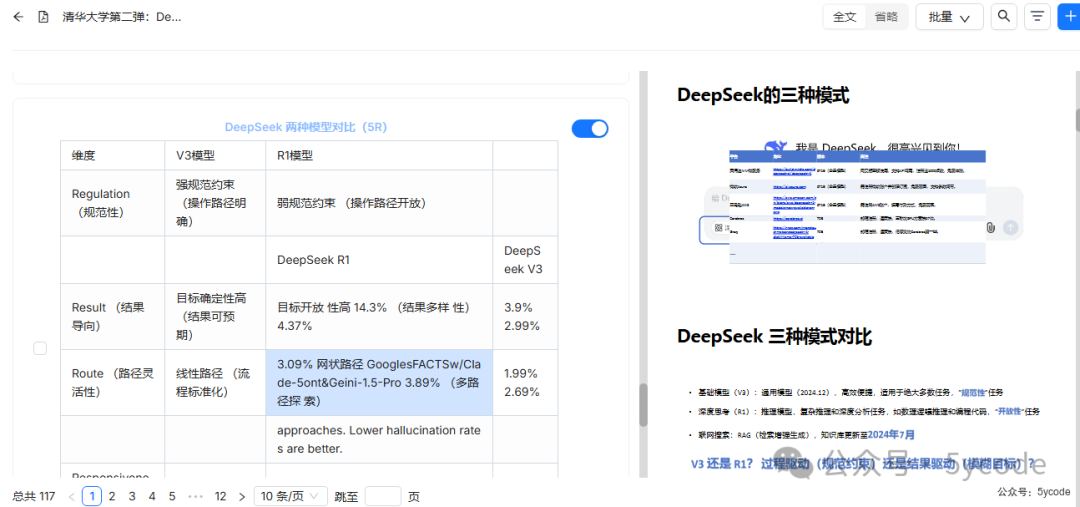
还有表格的识别。
检索测试
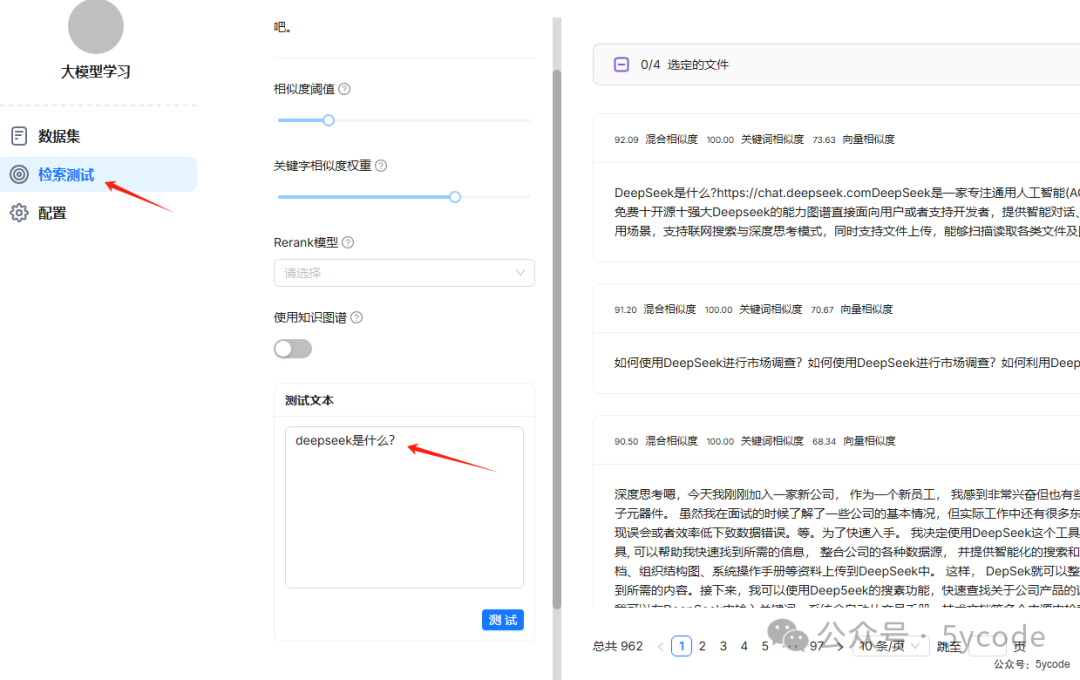
随便问一下,这检索效果,真棒。而且返回速度特别快。
文件管理
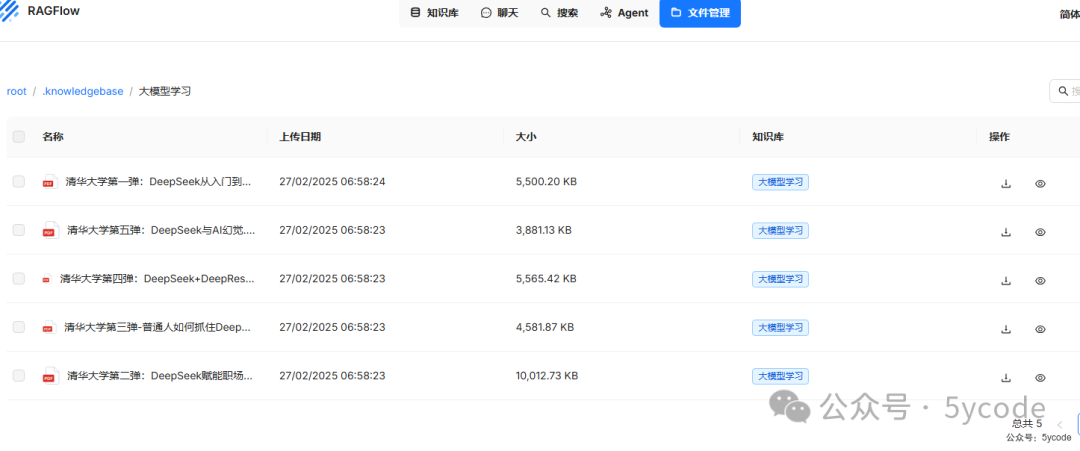
上传的文件在文件管理里面。
聊天
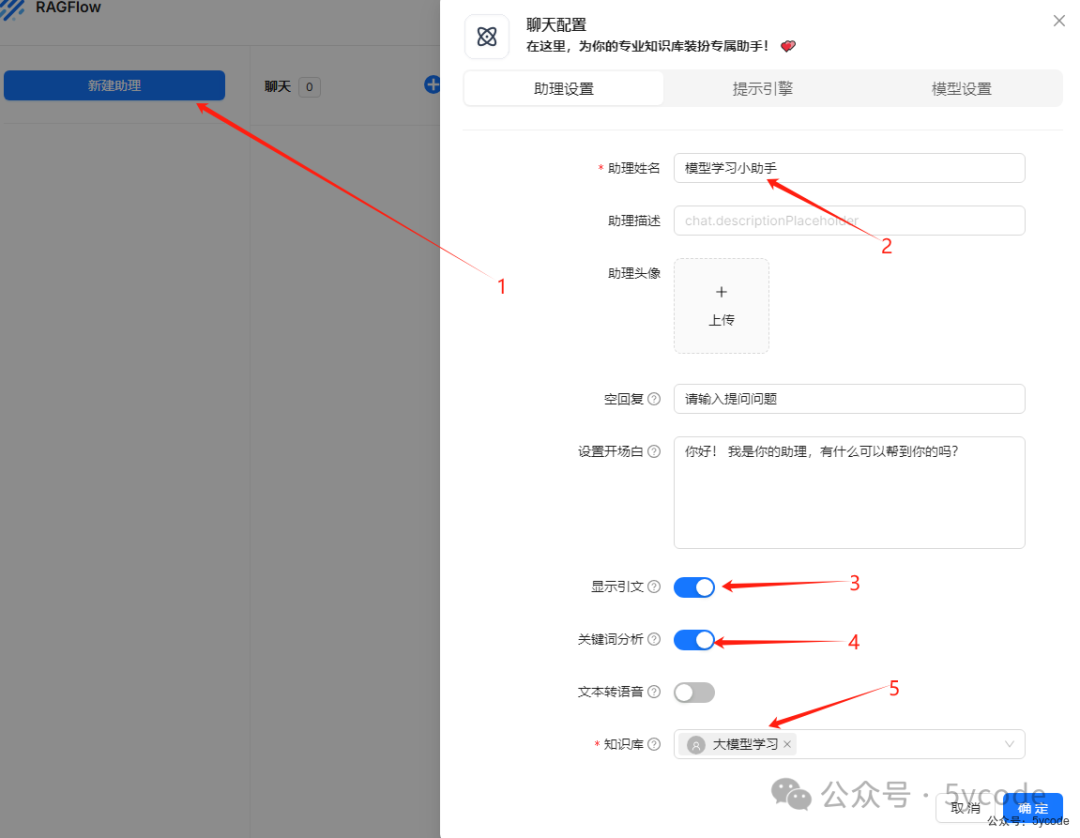
创建聊天
-
• 点击新建助手
-
• 显示引文
3 -
• 关键词分析
4开启。应用 LLM 分析用户的问题,提取在相关性计算中要强调的关键词。 -
• 知识库可以选择多个
5
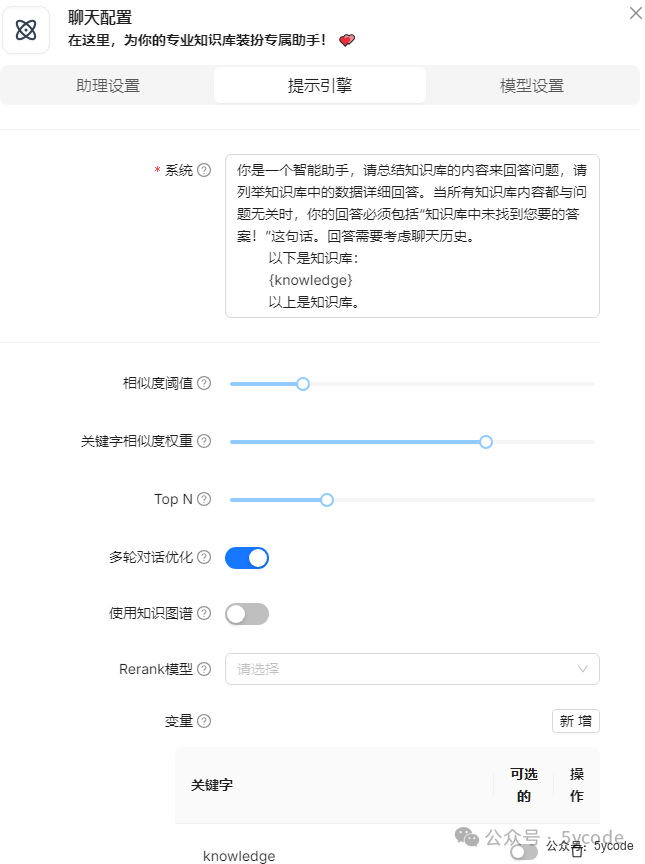
提示引擎默认即可,不用动。
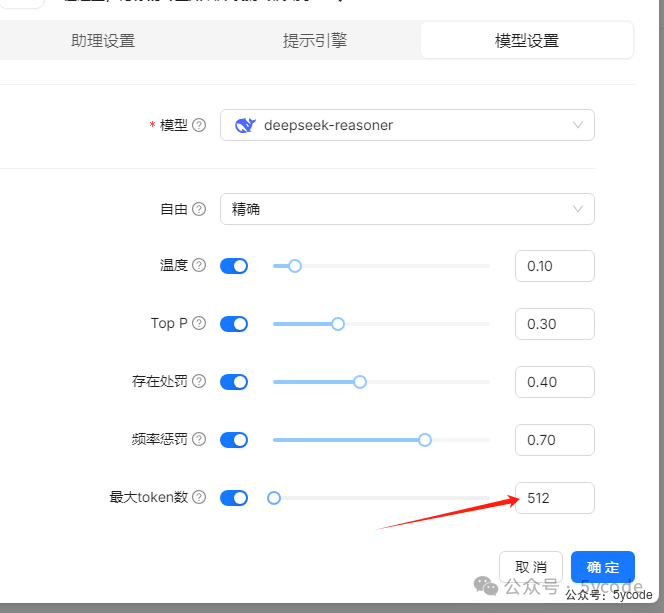
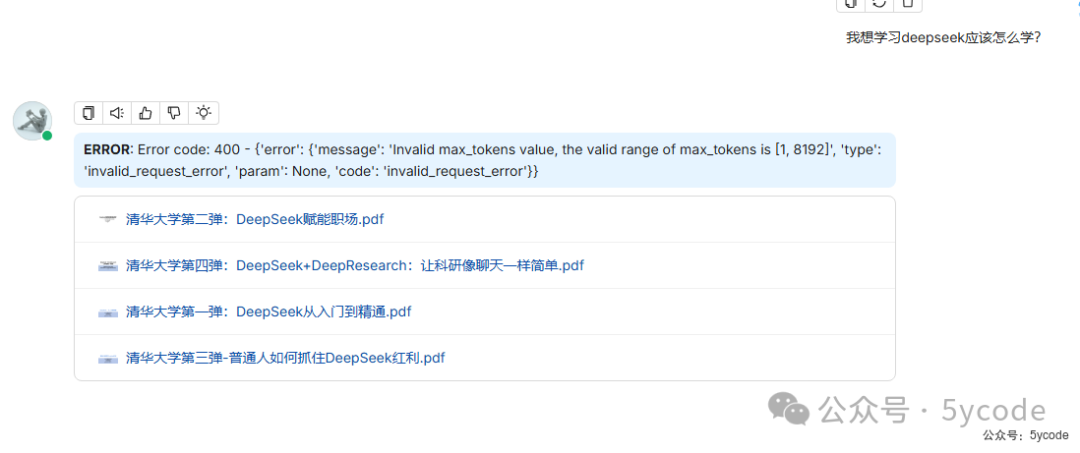
在模型设置里,主要是最大token数,默认512太小了,最大设置为8192
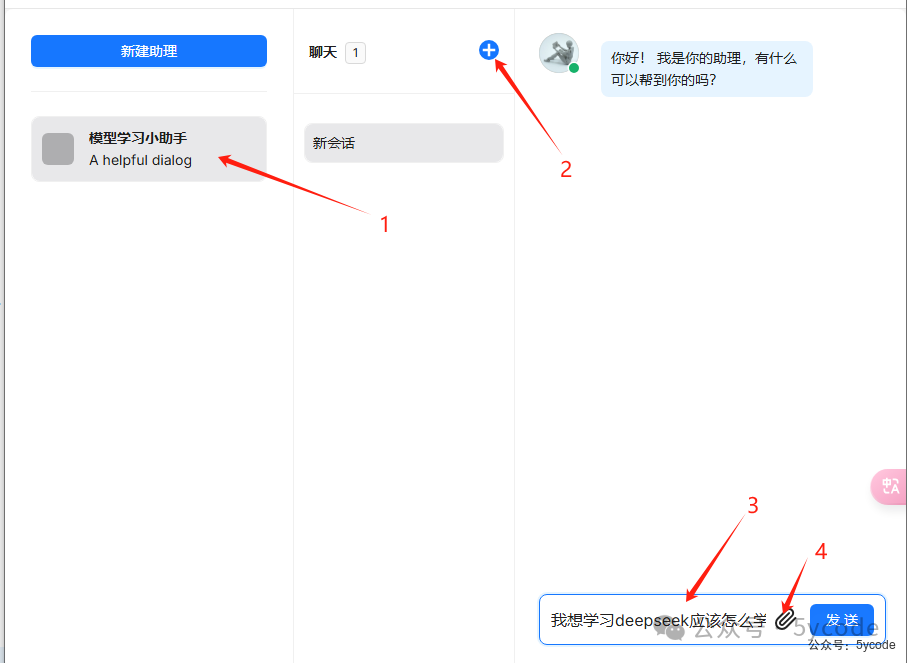
使用
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2025最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









