







DPCNet
研究背景及现状
- 目前的视频面部表情学习工作消耗了大量的计算资源来学习空间通道特征表示和时间关系;
- 与基于图像的FER相比,基于视频的FER不仅使用cnn提取视频序列的外观特征,还使用递归神经网络(rnn)或lstm提取时间动态。
- 对于视频中的面部表情表示,有两种主流架构,包括3D卷积神经网络和2D卷积神经网络,其次是长短期记忆(LSTM),级联的CNN-LSTM框架,其中cnn提取连续面部帧的外观特征,LSTM进一步计算其时间动态;
- 基于交叉熵的Softmax损失用于表情识别,但它在学习重要特征方面存在困难,深度人脸识别中的对比损失和三联体损失也适用于FER区域。然而,训练样本的选择会影响这两种损失函数的稳定性和鲁棒性;
模型介绍
- 提出了空间-框架激励模块,采用空间特异性激励和框架特异性激励级联的方式(为了在全空间分辨率下突出表达特异性特征,我们设计了空间特异性激励);
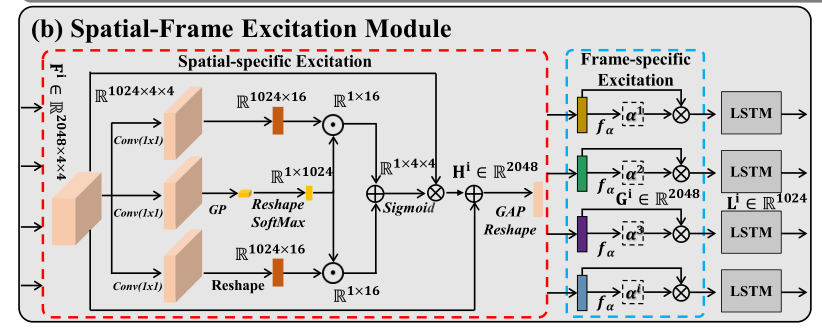
- 尽管LSTM用于学习空间框架特征之间的长期依赖关系,但它仍然将通道感知特征和时间信息视为对最终表达式识别的同等贡献;
- 设计了一个通道-时间聚合模块(CTAM),通过对通道感知和时间感知特征进行元素加(尽管LSTM用于学习空间框架特征之间的长期依赖关系,但它仍然将通道感知特征和时间信息视为对最终表达式识别的同等贡献);

学习目标
- 为了使SFEM所表示的空间帧特征保持一致,我们设计了一个基于自监督学习的多帧正则化损失算法;
- 为了使双路径分类器获得一致的预测,我们提出了基于Jensen-Shannon散度的双路径正则化损失,旨在最小化双路径表达概率分布之间的距离;
减少对计算源的依赖,对所有原始图像进行基于人脸地标的预处理,生成人脸图像,将图像大小调整为120 × 120,并通过比例抖动随机裁剪为112 × 112
DPCNet在DFEW的5个设置中表现一致,并且在快乐表情中达到了90%的最高平均识别率,但在厌恶和恐惧表情中混淆主要是由于有限的数据和严重的长尾数据分布














 475
475











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









