






目录:
1、定义
2、原理
3、代码示例
1、定义:机器翻译是指将一段文本从一种语言自动翻译到另一种语言。因为一段文本序列在不同语言中的长度不一定相同,所以我们使用机器翻译为例来介绍编码器—解码器和注意力机制的应用。
2、原理:机器翻译(Machine Translation, MT)是指使用计算机自动将一种自然语言(源语言)的文本转换成另一种自然语言(目标语言)的文本的技术。其背后的原理和过程涉及多个关键步骤,包括预处理、编码、解码和训练。下面详细介绍这些步骤及其关联的概念和技术。
(1) 数据预处理
机器翻译的数据预处理是非常重要的一步,它包括:
a. 分词(Tokenization):将原始文本分割成词语或子词的序列。
b. 建立词汇表(Vocabulary Building):收集并统计所有在训练数据中出现的词语或子词,并为每个词分配一个唯一的索引。
c. 填充和截断(Padding and Truncation):确保所有输入序列具有相同的长度,通过填充(通常使用特殊符号如`<pad>`)或截断处理。
(2) 编码器-解码器框架
机器翻译通常使用编码器-解码器(Encoder-Decoder)框架来实现。这种框架主要由两部分组成:
编码器(Encoder): 编码器负责将输入文本编码成一个中间表示,即编码器输出(encoder representation)。典型的编码器结构包括:
a. 词嵌入(Word Embeddings):将词汇表中的词索引转换为密集的词向量表示。
b. 位置编码(Positional Encoding):将输入序列的位置信息编码到词嵌入中,以保留序列的顺序信息。
c. 多层Transformer编码器(Multi-layer Transformer Encoder):使用多头自注意力(Multi-head Self-Attention)和前馈神经网络(Feedforward Neural Networks)构成的Transformer编码器层,用于捕捉输入序列中的语义和上下文信息。
解码器: 解码器接收编码器输出,并将其转换成目标语言的文本。解码器的关键组件包括:
a. 词嵌入和位置编码:类似编码器部分,但这里的词嵌入和位置编码用于目标语言的序列。
b. 多层Transformer解码器(Multi-layer Transformer Decoder):由多个Transformer解码器层组成,每个层使用自注意力和编码器-解码器注意力(Encoder-Decoder Attention),帮助解码器聚焦于输入的不同部分并生成适当的输出。
c. 生成器(Generator):最后一层解码器输出的线性层,将Transformer解码器的输出映射到目标语言的词汇表上。
(3) 训练过程
机器翻译的训练过程通常包括以下步骤:
a. 数据准备:将数据划分为训练集、验证集和测试集。每个训练样本是一个源语言句子和一个对应的目标语言句子。
b. 损失函数:通常使用交叉熵损失函数(Cross-Entropy Loss),用于衡量模型生成的目标语言序列与实际目标语言序列之间的差异。
c. 优化器:使用优化算法(如Adam或SGD)来最小化损失函数,更新模型参数。
d. 前向传播和反向传播:对于每个训练样本,将源语言序列传递给编码器,然后将解码器的输出与目标语言序列进行比较,并计算损失。然后通过反向传播计算梯度,并更新模型参数以减小损失。
(4) 推理(Inference)
训练完成后,可以将训练好的模型用于实际的翻译任务。推理阶段类似于训练阶段的解码器过程,但在每个时间步骤选择具有最高概率的词作为输出,直到遇到结束符号(如`<eos>`)或达到最大输出长度。
3、代码示例
import torch import torch.nn as nn import torch.nn.functional as F import torch.utils.data as Data import torchtext.vocab as Vocab import io import collections # 常量定义 PAD, BOS, EOS = '<pad>', '<bos>', '<eos>' # 分词函数示例(根据实际情况选择合适的分词方法) def tokenize(text): return text.split() # 简单的空格分割 # 将一个序列中所有的词记录在all_tokens中以便之后构造词典,然后在该序列后面添加PAD直到序列 # 长度变为max_seq_len,然后将序列保存在all_seqs中 def process_one_seq(seq_tokens, all_tokens, all_seqs, max_seq_len): all_tokens.extend(seq_tokens) seq_tokens += [EOS] + [PAD] * (max_seq_len - len(seq_tokens) - 1) all_seqs.append(seq_tokens) # 读取和处理Tatoeba Project数据集的函数 def read_data_tatoeba(file_path, max_seq_len): in_tokens, out_tokens, in_seqs, out_seqs = [], [], [], [] with io.open(file_path, 'r', encoding='utf-8') as f: lines = f.readlines() for line in lines: # 根据 Tatoeba Project 数据集的格式进行处理 parts = line.rstrip().split('\t') if len(parts) < 2: continue in_seq, out_seq = parts[0], parts[1] in_seq_tokens = tokenize(in_seq) out_seq_tokens = tokenize(out_seq) if max(len(in_seq_tokens), len(out_seq_tokens)) > max_seq_len - 1: continue process_one_seq(in_seq_tokens, in_tokens, in_seqs, max_seq_len) process_one_seq(out_seq_tokens, out_tokens, out_seqs, max_seq_len) # 调用 build_data 函数来构建词汇表和数据集 in_vocab, out_vocab, dataset = build_data(in_tokens, out_tokens, in_seqs, out_seqs) return in_vocab, out_vocab, dataset # 构建词汇表和数据集的函数 def build_data(in_tokens, out_tokens, in_seqs, out_seqs): in_vocab = Vocab.Vocab(collections.Counter(in_tokens), specials=[PAD, BOS, EOS]) out_vocab = Vocab.Vocab(collections.Counter(out_tokens), specials=[PAD, BOS, EOS]) in_indices = [[in_vocab.stoi[w] for w in seq] for seq in in_seqs] out_indices = [[out_vocab.stoi[w] for w in seq] for seq in out_seqs] dataset = Data.TensorDataset(torch.tensor(in_indices), torch.tensor(out_indices)) return in_vocab, out_vocab, dataset # 编码 class Encoder(nn.Module): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, drop_prob=0, **kwargs): super(Encoder, self).__init__(**kwargs) self.embedding = nn.Embedding(vocab_size, embed_size) self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=drop_prob) def forward(self, inputs, state): # 输入形状是(批量大小, 时间步数)。将输出互换样本维和时间步维 embedding = self.embedding(inputs.long()).permute(1, 0, 2) # (seq_len, batch, input_size) return self.rnn(embedding, state) def begin_state(self): return None def attention_model(input_size, attention_size): model = nn.Sequential(nn.Linear(input_size, attention_size, bias=False), nn.Tanh(), nn.Linear(attention_size, 1, bias=False)) return model def attention_forward(model, enc_states, dec_state): """ enc_states: (时间步数, 批量大小, 隐藏单元个数) dec_state: (批量大小, 隐藏单元个数) """ # 将解码器隐藏状态广播到和编码器隐藏状态形状相同后进行连结 dec_states = dec_state.unsqueeze(dim=0).expand_as(enc_states) enc_and_dec_states = torch.cat((enc_states, dec_states), dim=2) e = model(enc_and_dec_states) # 形状为(时间步数, 批量大小, 1) alpha = F.softmax(e, dim=0) # 在时间步维度做softmax运算 return (alpha * enc_states).sum(dim=0) # 返回背景变量 # 解码 class Decoder(nn.Module): def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, attention_size, drop_prob=0): super(Decoder, self).__init__() self.embedding = nn.Embedding(vocab_size, embed_size) self.attention = attention_model(2*num_hiddens, attention_size) # GRU的输入包含attention输出的c和实际输入, 所以尺寸是 num_hiddens+embed_size self.rnn = nn.GRU(num_hiddens + embed_size, num_hiddens, num_layers, dropout=drop_prob) self.out = nn.Linear(num_hiddens, vocab_size) def forward(self, cur_input, state, enc_states): """ cur_input shape: (batch, ) state shape: (num_layers, batch, num_hiddens) """ # 使用注意力机制计算背景向量 c = attention_forward(self.attention, enc_states, state[-1]) # 将嵌入后的输入和背景向量在特征维连结, (批量大小, num_hiddens+embed_size) input_and_c = torch.cat((self.embedding(cur_input), c), dim=1) # 为输入和背景向量的连结增加时间步维,时间步个数为1 output, state = self.rnn(input_and_c.unsqueeze(0), state) # 移除时间步维,输出形状为(批量大小, 输出词典大小) output = self.out(output).squeeze(dim=0) return output, state def begin_state(self, enc_state): # 直接将编码器最终时间步的隐藏状态作为解码器的初始隐藏状态 return enc_state # 损失函数 def batch_loss(encoder, decoder, X, Y, loss): batch_size = X.shape[0] enc_state = encoder.begin_state() enc_outputs, enc_state = encoder(X, enc_state) # 初始化解码器的隐藏状态 dec_state = decoder.begin_state(enc_state) # 解码器在最初时间步的输入是BOS dec_input = torch.tensor([out_vocab.stoi[BOS]] * batch_size) # 我们将使用掩码变量mask来忽略掉标签为填充项PAD的损失, 初始全1 mask, num_not_pad_tokens = torch.ones(batch_size,), 0 l = torch.tensor([0.0]) for y in Y.permute(1,0): # Y shape: (batch, seq_len) dec_output, dec_state = decoder(dec_input, dec_state, enc_outputs) l = l + (mask * loss(dec_output, y)).sum() dec_input = y # 使用强制教学 num_not_pad_tokens += mask.sum().item() # EOS后面全是PAD. 下面一行保证一旦遇到EOS接下来的循环中mask就一直是0 mask = mask * (y != out_vocab.stoi[EOS]).float() return l / num_not_pad_tokens # 训练模型 def train(encoder, decoder, dataset, lr, batch_size, num_epochs): enc_optimizer = torch.optim.Adam(encoder.parameters(), lr=lr) dec_optimizer = torch.optim.Adam(decoder.parameters(), lr=lr) loss = nn.CrossEntropyLoss(reduction='none') data_iter = Data.DataLoader(dataset, batch_size, shuffle=True) for epoch in range(num_epochs): l_sum = 0.0 for X, Y in data_iter: enc_optimizer.zero_grad() dec_optimizer.zero_grad() l = batch_loss(encoder, decoder, X, Y, loss) l.backward() enc_optimizer.step() dec_optimizer.step() l_sum += l.item() if (epoch + 1) % 10 == 0: print("epoch %d, loss %.3f" % (epoch + 1, l_sum / len(data_iter))) # 示例使用 max_seq_len = 20 # 替换为实际的Tatoeba Project数据集路径和参数 in_vocab, out_vocab, dataset = read_data_tatoeba('tatoeba.txt', max_seq_len) # 根据您的模型配置替换 embed_size, num_hiddens, num_layers = 64, 64, 2 attention_size, drop_prob, lr, batch_size, num_epochs = 10, 0.5, 0.01, 2, 50 encoder = Encoder(len(in_vocab), embed_size, num_hiddens, num_layers, drop_prob) decoder = Decoder(len(out_vocab), embed_size, num_hiddens, num_layers, attention_size, drop_prob) train(encoder, decoder, dataset, lr, batch_size, num_epochs)
模型训练结果

tatoeba数据集获取方式:
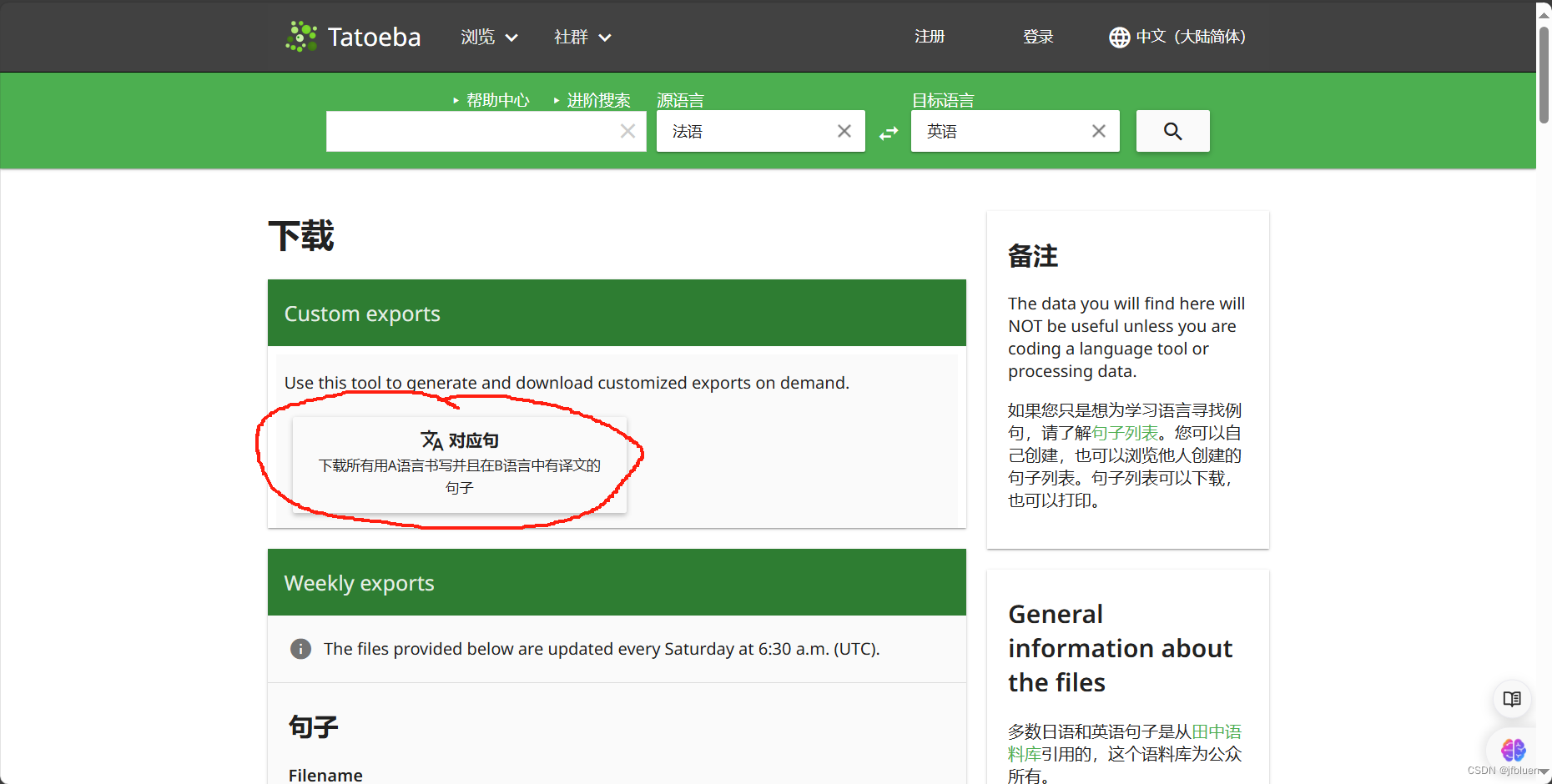
下载句子- Tatoeba ![]() https://tatoeba.org/zh-cn/downloads进入该网站后,点击画圈部分
https://tatoeba.org/zh-cn/downloads进入该网站后,点击画圈部分
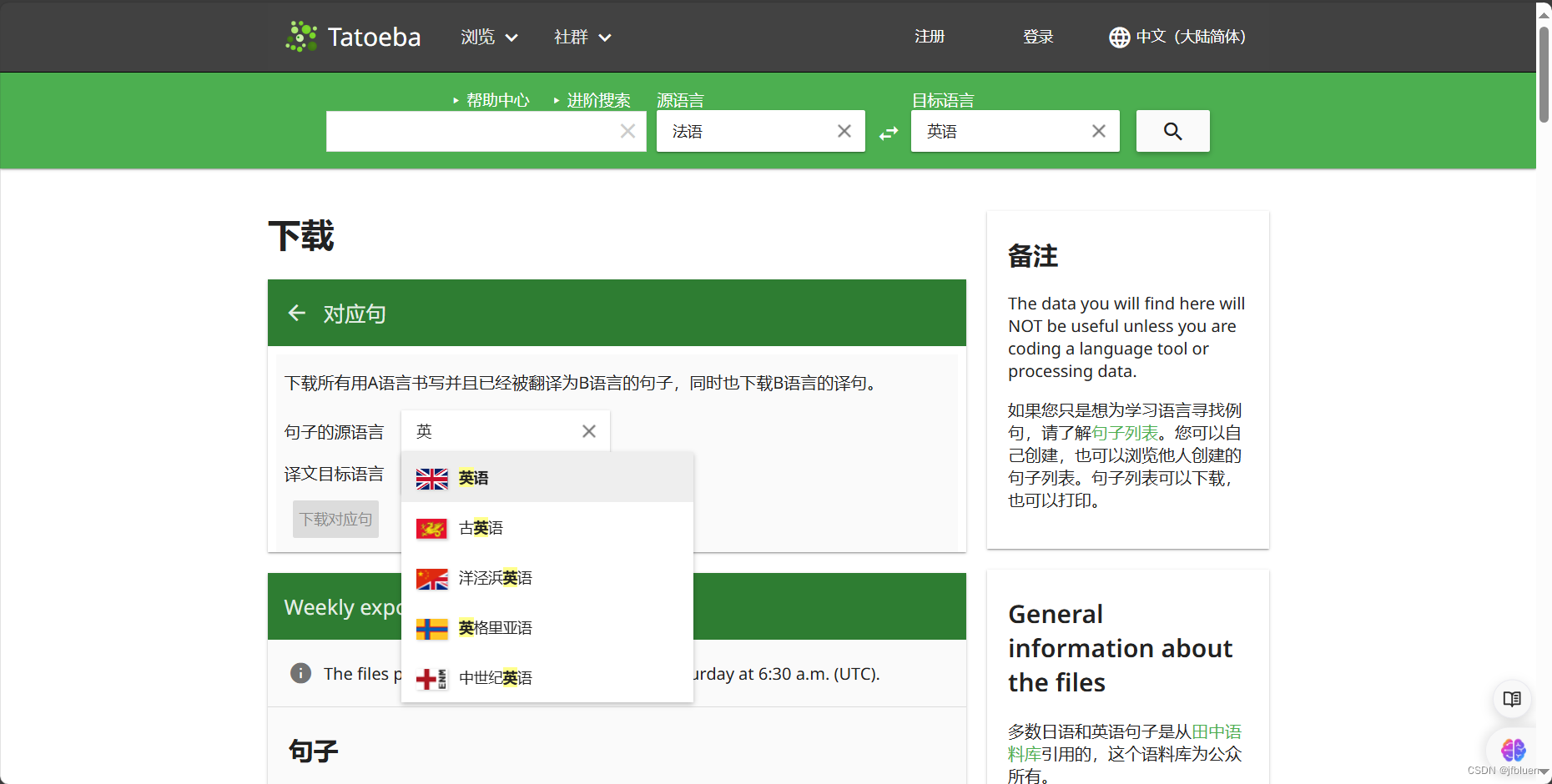
输入想要的语种翻译文本后,点击下载即可
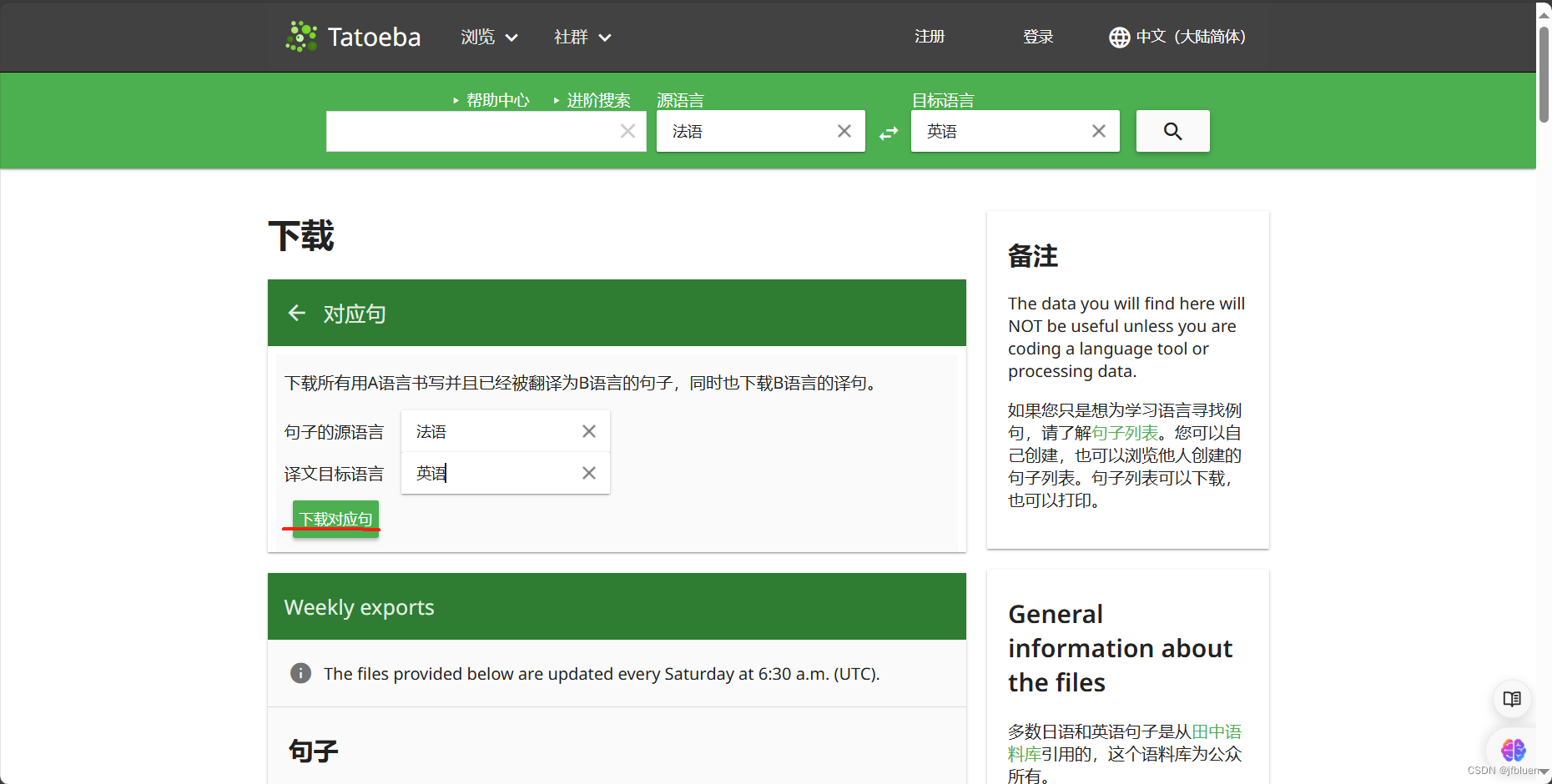
测试模型代码:
def translate(encoder, decoder, input_seq, max_seq_len): in_tokens = input_seq.split(' ') in_tokens += [EOS] + [PAD] * (max_seq_len - len(in_tokens) - 1) enc_input = torch.tensor([[in_vocab.stoi[tk] for tk in in_tokens]]) # batch=1 enc_state = encoder.begin_state() enc_output, enc_state = encoder(enc_input, enc_state) dec_input = torch.tensor([out_vocab.stoi[BOS]]) dec_state = decoder.begin_state(enc_state) output_tokens = [] for _ in range(max_seq_len): dec_output, dec_state = decoder(dec_input, dec_state, enc_output) pred = dec_output.argmax(dim=1) pred_token = out_vocab.itos[int(pred.item())] if pred_token == EOS: # 当任一时间步搜索出EOS时,输出序列即完成 break else: output_tokens.append(pred_token) dec_input = pred return output_tokens input_seq = 'ils regardent .' translate(encoder, decoder, input_seq, max_seq_len)
运行结果:
















 585
585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









