







RANSAC是“RANdom SAmple Consensus(随机抽样一致)”的缩写。它可以从一组包含“局外点”的观测数据集中,通过迭代方式估计数学模型的参数。它是一种不确定的算法,有一定的概率得出一个合理的结果。为了提高得出合理结果的概率必须提高迭代次数。
1、基本思想:
RANSAC通过反复选择数据中的一组随机子集来达成目标。被选取的子集被假设为局内点,并用下述方法进行验证:
-
有一个模型适用于假设的局内点,即所有的未知参数都能从假设的局内点计算得出。
-
用1中得到的模型去测试所有的其它数据,如果某个点适用于估计的模型,认为它也是局内点。
-
如果有足够多的点被归类为假设的局内点,那么估计的模型就足够合理。
-
然后,用所有假设的局内点去重新估计模型,因为它仅仅被初始的假设局内点估计过。
-
最后,通过估计局内点与模型的错误率来评估模型。
这个过程被重复执行固定的次数,每次产生的模型要么因为局内点太少而被舍弃,要么因为它比现有的模型更好而被选用。

2、对上述步骤,进行简单总结如下:
N:样本点个数,K:求解模型需要的最少的点的个数
- 随机采样K个点
- 针对该K个点拟合模型
- 计算其它点到该拟合模型的距离,小于一定阈值当做内点,统计内点个数
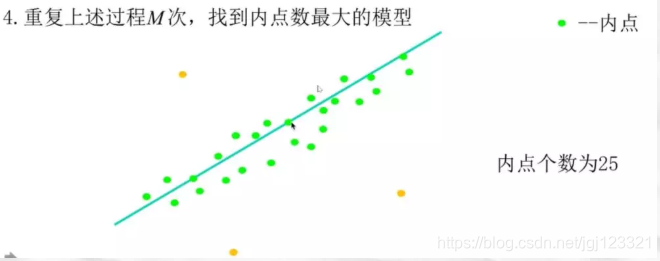
- 重复M次,选择内点数最多的模型
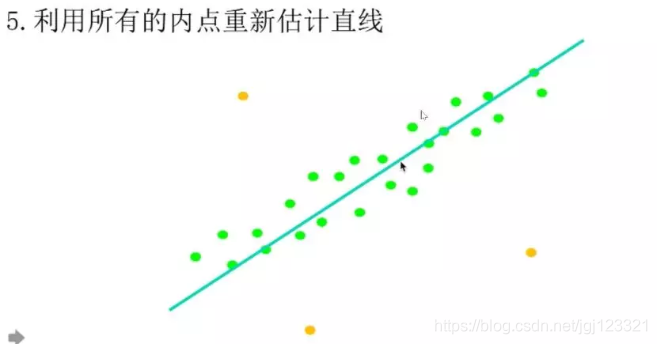
- 利用所有的内点重新估计模型(可选)
3、举例:利用RANSAC算法拟合一条直线



4、计算需要的迭代次数k
:模型需要的最少点个数
:随机选取的一个点为局内点的概率,w=局内点个数 / 数据点总数
:n个点均为局内点的概率
1-:n个点中至少有一个为局外点的概率,即采样失败
:k次采样全部失败的概率
:随机选取的n个点均为局内点的概率,即采样成功的概率
因此有下式:
上式两边取对数,得出:
其中,n已知,w可以计算出来,只要设置p的值(通常设置为0.99),即可得到迭代次数k。

















 5633
5633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









