






目录
引言
k-近邻算法,根据前面一章所学,属于监督学习算法,高效且易于掌握,这一章节主要就是讨论k-近邻算法的基本理论,以及如何使用距离测量的方法分类物品,同时将使用python从文本文件中导入并解析数据,对于存在数据来源时还将讨论如何避免计算距离时可能碰到的一些常见错误。
一、k-近邻算法概述(kNN)
k-近邻算法是通过采用测量不同特征值之间的距离方法来进行分类的:
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型。
kNN的工作原理是:存在一个样本数据集合(训练样本集),且样本集中每个数据都存在标签(样本集中的每个数据与所属分类的对应关系)。当输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,通过算法提取样本集中特征最相似(最近邻)数据的分类标签。一般来说,选择样本数据集中前k个最相似的数据,这也是kNN中k的出处,k通常是不大于20的整数。选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
以电影分类为例,以k-近邻算法分类对爱情片和动作片进行分类,通过统计电影中打斗和接吻的镜头对其进行分类。

在使用kNN进行分类之前需要知道未知电影存在多少的打斗镜头以及接吻镜头,表1中给出了相关信息。因为不知道未知电影属于哪种类型,但可以通过某种方法计算出来,首先计算未知电影与样本集中其他电影的距离。
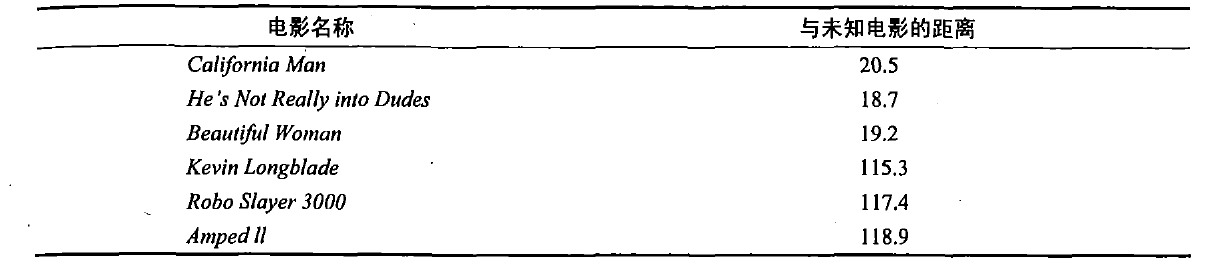
通过计算得出了样本集中,所有电影与未知电影的距离,按照距离递增排序,通过找到k个距离电影最近的电影,这里就可以假设k=3得到表1中前三个电影,按照kNN的工作原理,就可以知道未知电影的类型为爱情片。
k-近邻算法的一般流程:
(1) 收集数据:可以使用任何方法
(2) 准备数据:计算所需要的数值,最好是结构化的数据格式
(3) 分析数据:可以使用任何方法
(4) 训练算法:这个步骤并不适用于k-近邻算法
(5) 测试算法:计算错误率
(6) 使用算法:需要输入样本数据和结构化的输出结果,然后再运行k-近邻算法判定输入数据 分别属于哪个分类,最后应用对计算出的分类执行后续的处理。
1.1 python导入数据
创建kNN.py的python模块,并在其中增加如下代码:
from numpy import *
# 导入科学计算包
import operator
# 导入运算符模块
def creatDataSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) # 给定数据集
labels = ['A', 'A', 'B', 'B'] # 创建标签
return group, labels 这里导入了两个模块,包括科学计算包Numpy以及运算符模块operator,operator是python中内置的操作符接口,定义了一些算术和比较内置操作的函数,具体的对应关系可以从下面的链接中加以理解。python——operator详解_来路与归途的博客-CSDN博客_python中operator
import kNN
group, labels = kNN.creatDataSet() # 创建变量group和labels
通过上述代码创建变量group和labels,这里group与labels就获得了kNN.py中creatDataSet() 中对应的数据。向量label包含了每个数据点的标签信息,label包含的元素个数就等于group矩阵行数,假设将数据点(1,1.1)定义为类A,数据点(0,0.1)定义为类B。
1.2 从文本文件中解析数据
kNN算法的伪代码为:
1、计算已知类别数据集中的点与当前点之间的距离
2、按照距离递增次序排序
3、选取与当前点距离最小的k个点
4、确定前k个点所在类别的出现频率
5、返回前k个点出现频率最高的类别作为当前点的预测分类
python代码程序:
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0] # dataSetSize等于dataSet的行数
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 将inX的横向扩展dataSetSize倍,纵向不变,并与dataSet的坐标相减
sqDiffMat = diffMat ** 2 # 将相减后的坐标进行乘方
sqDistances = sqDiffMat.sum(axis=1) # 将sqDiffMat的坐标按列相加求和
distances = sqDistances ** 0.5 # 开根号,得出距离
sortedDistIndicies = distances.argsort() # argsort()是排序的意思,将distance的内容按从小到大返回下标
# 取排序里的前k个放入字典中,即kNN里的前k个距离最近的值
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]] # 设置字典里的key值,即标签
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# get函数是获取voteIlabel里的值,当存在值时返回要取的值,当没有值时则返回0,这里返回的是key值对应的value
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# key = operator.itemgetter(1)是按照字典的第一个域排序,这里因为是字典也就是按照value进行排序,reverse = True即倒序排列
return sortedClassCount[0][0] # 返回列别最多的那一个
在该函数中存在有4个输入参数包括:用于分类的输入向量inX,输入的训练样本集dataSet,标签向量labels,以及k-近邻算法中需要用到的k值。
在代码中通过设置dataSetSize = dataSet.shape[0] 使得标签向量的元素数目与矩阵dataSet的行数相同,之后就是使用欧式距离公式计算向量带你xA与xB之间的距离:
当计算完所有点之间的距离后对数据进行从小到大的次序排序得到前k个最小距离的,输入k必须为正整数。程序中设置其排序方式为从大到小,最终返回的值为发生频率最高的元素标签。
实验:
import kNN
group, labels = kNN.creatDataSet() # 创建变量group和labels
print(kNN.classify0([0, 0], group, labels, 3))最终返回结果为:B
修改输入向量inX最终得到的标签也将不同。
二、使用k-近邻算法改进约会网站的配对结果
kNN算法在使用中需要庞大数据集的支撑,在前面的学习中,给出的数据集很小并且是通过人工手打的,这不符合机器学习的准则,这里是书中给出的一个实验案例,通过学习这一块知识对kNN算法有更进一步的理解。
在约会网站上使用kNN算法是步骤为:
1、收集数据: 提供文本文件
2、准备数据: 使用python解析文本文件
3、分析数据: 利用matplotlib绘制二维扩散图
4、训练算法: 不适用kNN算法
5、测试算法: 使用已有数据作为测试样本
6、使用算法:产生命令行,使用户能够根据特征找到自己所需的类型
知道执行步骤后就开始着手进行算法的构建,计算机中通常使用文本文件进行数据的存储,因此在获得数据前需要利用python对文本文件进行解析:
def file2matrix(filename):
fp = open(filename) # 打开文件
array0lines = fp.readlines() # readlines()用途为:一次阅读所有内容,并按照行返回列表,便于遍历
number0lines = len(array0lines) # 得到array0lines的长度
returnMat = zeros((number0lines, 3)) # 创建一个新数组大小为number0line*3
classLabelVector = [] # 创建列表
index = 0
for line in array0lines:
line = line.strip() # strip()为去除字符串头尾指定的字符,无法去除中间字符,当给定的不是char而是None时就是去除头尾的空格
listfromline = line.split('\t') # 将字符串转换成列表,这里的情况是遇到字符串中存在\t的情况时对其进行分割。
returnMat[index,:] = listfromline[0:3] # 截取listfromline的第一到第三位字符并赋值给矩阵,这里的index表示行数
classLabelVector.append(int(listfromline[-1])) # 每一行的最后一位赋值给标签,强制转换成int类型
index += 1
return returnMat, classLabelVector通过文件名在python中打开文件,由readlines()阅读并返回以行为基础的列表,通过len()获得行数,并由此创建一个新的矩阵,遍历列表中的字符串元素,使用strip和split函数对其加以整理修饰,选取前三个元素存储到特征矩阵中,最后将列表中的最后一列存储到classLabelVector向量中。
主程序中写入:
datamat, datalabels = kNN.file2matrix('D:\\learning\\datingTestSet2.txt')
print(datamat,"\n",datalabels)输出结果为:

而文本文件中的数据为:
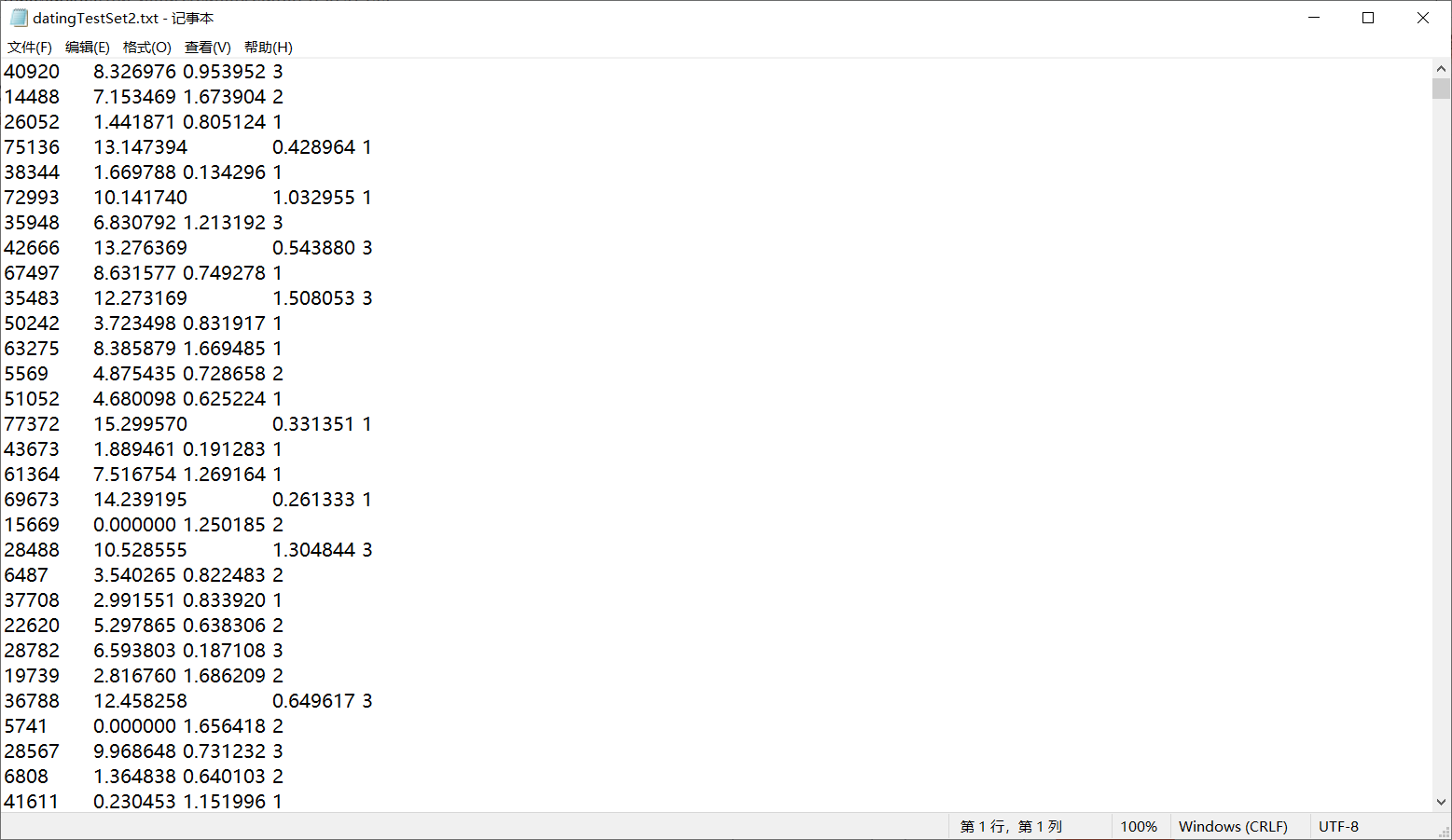
比较两幅图就可以看出python运行后的结果取出了前三位数据并将最后一位数据设置为了标签。
2.1 分析数据:
这里使用matplotlib制作出原始数据的散点图
import kNN
import matplotlib.pylab as plt
datamat, datalabels = kNN.file2matrix('D:\\learning\\datingTestSet2.txt')
print(datamat, "\n", datalabels)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datamat[:, 1], datamat[:, 2]) # [:,n]取出全部集合的第n个数据
plt.show()有关add_subplot()函数的具体用法可以参考博客fig.add_subplot()函数参数的意思_流年若逝的博客-CSDN博客_fig.add_subplot函数
代码中[:,n]表示取所有集合中的第n个元素,[n,:]表示第n个集合的全部元素,[:,n,m]取全部集合中的第n到m-1个元素。
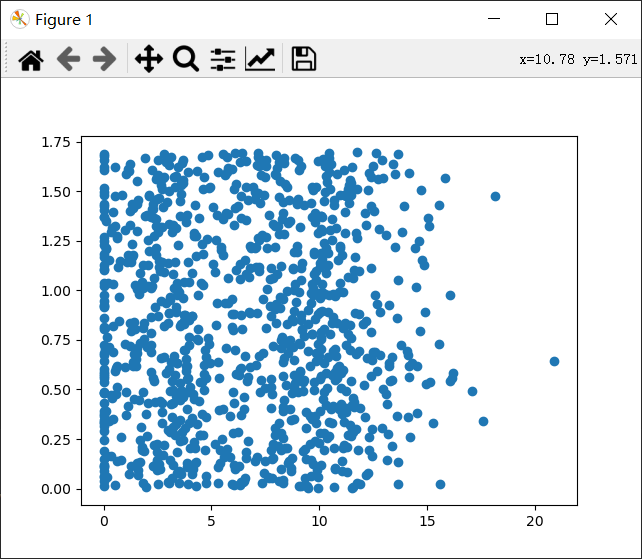
尽管在上图中得到了数据,但我们并不能从中得到任何有用的数据模式信息,这时需要通过采用色彩或者其他记号来标记不同的样本分类以便理解数据信息。调用scatter函数时加上如下参数:
ax.scatter(datamat[:, 1], datamat[:, 2], 15.0 * array(datalabels), 15.0 * array(datalabels))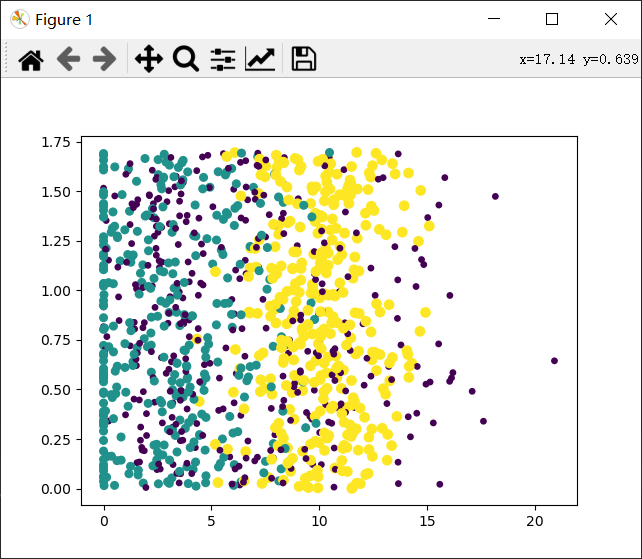
2.2 准备数据:归一化数值
从表3给出的数据来看数字差值大的属性对计算结果的影响最大,表中的飞行常客里程数对计算结果的影响就远远超过了其他的两个特征。但这样的影响往往是不正确的,三种特征在计算中应当同等重要。以此在处理这类数据时需要将数值归一化。

下面的公式可以实现将任意取值范围的特征值转化为0到1区间的值:
newValue = (oldValue - min) / (max - min)min和max分别是数据集中的最小特征值和最大特征值,如此操作可能会增加分类器的复杂度,但也保证了结果的准确。在kNN.py中添加函数autoNorm(),用以自动将数字特征值转化为0到1的区间。
def autoNorm(dataSet):
minVals = dataSet.min(0) # 获取dataSet列表中每一列最小的数值
maxVals = dataSet.max(0) # 获取dataSet列表中每一列最大的数值
ranges = maxVals - minVals # 计算得出数据列表中最大值与最小值之差
normDateSet = dataSet.zeros(shape(dataSet)) # 返回一个新的矩阵, shape的数据类型为元组,返回的是以dataSet的行数为维度的矩阵
m = dataSet.shape[0] # m的值为dataSet的行数
normDateSet = dataSet - tile(minVals, (m, 1)) # 这个步骤为(oldValue - min),tile()函数将minVals扩展到与dataset矩阵一样的大小以便进行运算
normDateSet = normDateSet / tile(ranges, (m, 1)) # ranges 就指代了(max - min),同理
return normDateSet, ranges, minVals # 返回运算后的矩阵, ranges以及最小值的数组autonorm()函数用于归一化运算,变量minVals中存放这dataSet里每一列的最小值,maxVals则存放这dataSet里每一列的最大值。在上述代码的步骤的后都添加了注释以解释其意义。Numpy库中矩阵除法需要使用函数linalg.solve(matA,matB),这里使用的是/。
下面就是进行测试:
主程序中写入:
datamat, datalabels = kNN.file2matrix('D:\\learning\\datingTestSet2.txt')
normMat, ranges, minVals = kNN.autoNorm(datamat)
print(normMat,"\n",ranges,"\n",minVals)得到结果
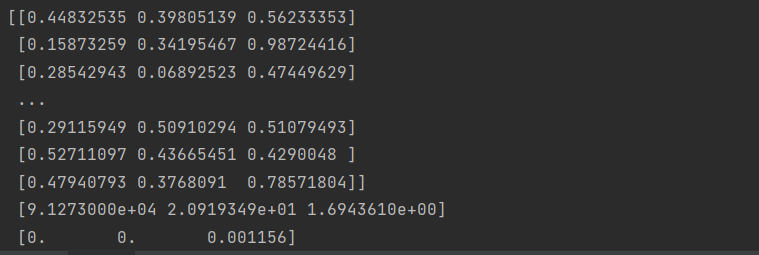
与图一对比后可以看出结果之间的差距出现了明显的减小。
2.3 测试算法:作为完整程序验证分类器
为测试分类器效果,在kNN.py中创建函数datingClassTest:
# 分类器测试算法
def datingClassTest():
hoRatio = 0.10 # 选取数据比例10%
datamat, datalabels = file2matrix('D:\\learning\\datingTestSet2.txt') # 读取数据
normMat, ranges, minVals = autoNorm(datamat) # 从auto中获取数据
m = normMat.shape[0] # m等于normMat的行数,即数据集中矩阵的行数
numTestVecs = int(m * hoRatio) # 通过行数乘以比例得到选取范围,并将其强制转换为整数
errorCount = 0.0 # 初始化错误率
# 测试数据,逐行测试
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:], normMat[numTestVecs:m,:], datalabels[numTestVecs:m], 3)
# 向分类器输入数据并得出结果,若得出结果与分类器标签不一致则存在问题
print('the classifier came back with: %d, the real answer is: %d' %(classifierResult, datalabels[i]))
if (classifierResult != datalabels[i]):
errorCount += 1.0
print("time of testing is: %d" %numTestVecs)
print("whole data number is %d" %m)
print("the total error rate is %f" %(errorCount/float(numTestVecs)))这里使用了filematrix和autoNrom()函数,从文件中读取数据并将其转换为归一化特征值计算测试向量的数量,这一步通过将测试数据比例与数据集行数相乘得到,从下面的结果中可以看到测试数据为100。将两部分数据输入分类器函数classify0中,最终得出分类结果。

这里可以看到错误率在5%,若将测试数据比例调整至20%,此时的结果为8%:

2.4 构建完整可用系统
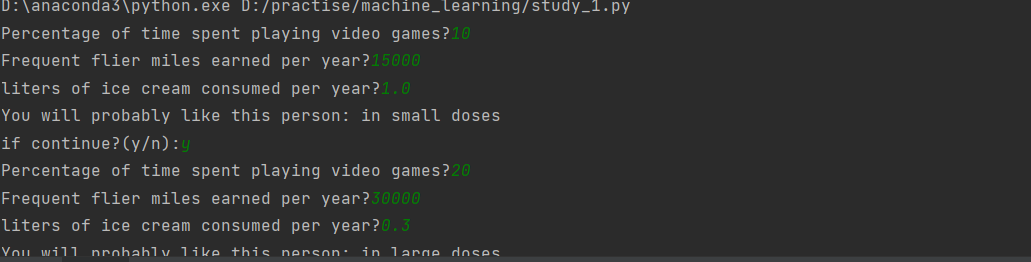
上面已经通过数据对分类器进行了测试,现在就随机输入数据从约会网站上预测用户对目标的喜欢程度:
# 输入数据预测函数
def classifyPerson():
# 类别
resultList = ["not at all", "in small doses", "in large doses"] # 显示结果列表
percentTats = float(input("Percentage of time spent playing video games?")) # float(input()) 输入数据并将其转化为浮点型数据
ffMiles = float(input("Frequent flier miles earned per year?"))
iceCream = float(input("liters of ice cream consumed per year?"))
dataMat, dataLabels = file2matrix("D:\\learning\\datingTestSet2.txt") # 获取训练数据及标签
normMat, ranges, minVals = autoNorm(dataMat) # 归一化训练数据
inArr = array([ffMiles, percentTats, iceCream]) # 以输入数据创建数组
classifierResult = classify0((inArr - minVals) / ranges, normMat, dataLabels, 3) # 分类器进行分类
print("You will probably like this person:", resultList[classifierResult - 1])
# 输出结果主函数中调用,设置一个while循环进行多次预测:
while(1):
kNN.classifyPerson()
choice = input("if continue?(y/n):")
if choice == 'y':
continue
elif choice == 'n':
break
else:
print("error input!")在操作台中输入数据得到了结果。两次数据的返回结果不同说明了能够正常使用。
三、二进制存储的图像中使用kNN——手写识别系统
为了便于理解,这里还是将图像转换为文本格式。使用kNN-近邻算法的手写识别系统步骤为:
1、 收集数据:提供文本文件
2 、准备数据:编写分类器classify0,将图像格式转化为分类器使用的list格式
3、 分析数据:在python命令提示符中检查数据确保符合要求
4、 训练算法:不适用于k-近邻算法
5、 测试算法:编写函数使用提供的部分数据作为测试样本,若测试样本在测试结束后得到的预测分类与实际分类不同则为一个错误
6、 使用算法
在这个例子里如果要使用之前的分类器就必须将图像格式化成一个向量,比如说将一个32*32的二进制图像矩阵转换为1*1024的数组向量。下面的代码就实现了这样的操作:
# 将32*32的二进制图像矩阵转化成1*1024的向量
def img2vector(filename):
returnVect = zeros((1, 1024)) # 创建1*1024大小的数组
fr = open(filename) # 打开文本文件
for i in range(32):
lineStr = fr.readline() # 读取文本文件数据并按行将其转换为数组,循环32次
for j in range(32):
returnVect[0, 32 * i + j] = int(lineStr[j]) # 将前linestr中每行的前32位字符存储在数组中
return returnVect # 返回数组
在上面的代码中首先是创建一个数组,设置其大小为1*1024,打开目标文本文件并读取数据,将所需数据存储在先前创建的数组里。 在主程序中执行:
testVector = kNN.img2vector('D:\\learning\\trainingDigits\\0_13.txt')
print(testVector[0, 0:31]) # 打印第一个元素的第1-32个字符得出的结果如下:

3.1 测试算法——k-近邻算法识别手写数字
在上一节的讨论中已经将需要处理的数据从二进制图像转换成了文本文件,这里将数据输入到分类器并检测分类器的执行效果,创建函数handwritingClassTest()并将其写在kNN.py里。
# 手写数字识别
def handwritingClassTest():
hwLabels = [] # 创建一个列表
trainingFileList = os.listdir('D:\\learning\\trainingDigits') # os.listdir用于返回指定文件夹包含的文件或文件夹的名字的列表,这里就是获得目录内容,并将其存储在列表中
m = len(trainingFileList) # 获得列表的长度
trainingMat = zeros((m, 1024)) # 创建m*1024大小的零矩阵
for i in range(m): # 从文件名解析分类数字
fileNameStr = trainingFileList[i] # 将trainingFileList中的元素赋值给filenamestr
fileStr = fileNameStr.split('.')[0] # 以第一个‘.’为分界线,将‘.’前面的字符赋值给filestr
classNumStr = int(fileStr.split('_')[0]) # 以第一个‘_’为分界线,将‘_’前面的字符赋值给classnumstr,并强制转换成整型
hwLabels.append(classNumStr) # 将classnumstr的元素添加到列表中
trainingMat[i, :] = img2vector('D:\\learning\\trainingDigits/%s' % fileNameStr) # 训练矩阵的每一行代表着一个图像
testFileList = os.listdir('D:\\learning\\testDigits') # 获取文件目录
errorCount = 0.0 # 初始化错误率
mTest = len(testFileList) # 计算测试文件目录长度
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('D:\\learning\\testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print('the classifier came back with %d, the real answer is: %d' %
(classifierResult, classNumStr))
if classifierResult != classNumStr: errorCount += 1.0
print('\nthe total number of errors is: %d' % errorCount)
print('\nthe total error rate is: %f' % (errorCount / float(mTest)))上述代码实现了将trainingDigits目录中的文件内容存储在列表中并得到目录中有多少文件,将文件数目存储在变量m中,创建一个m*1024大小的训练矩阵,矩阵的每行数据存储着一个图像。可用从文件名中解析出分类数字,将类代码存储在hwlabels中,用img2vector函数进行图像的载入,对于测试数据操作类似,不同的是并不将该目录下的文件载入矩阵中,而是使用分类器ckassify0测试这目录下的每个文件。
主程序为:
kNN.handwritingClassTest()最终的输出结果为:

在使用k-近邻算法时,可用明显的感觉到当数据集很大时,算法的执行时间就会变的很长,而且还要创建测试向量这也需要预留出存储空间。















 8350
8350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









