







深度优先搜索
深度优先搜索和广度优先搜索一样,都是对图进行搜索的算法,目的也都是从起点开始搜索直到到达指定顶点(终点)。深度优先搜索会沿着一条路径不断往下搜索直到不能再继续为止,然后再折返,开始搜索下一条候补路径。
图解:
01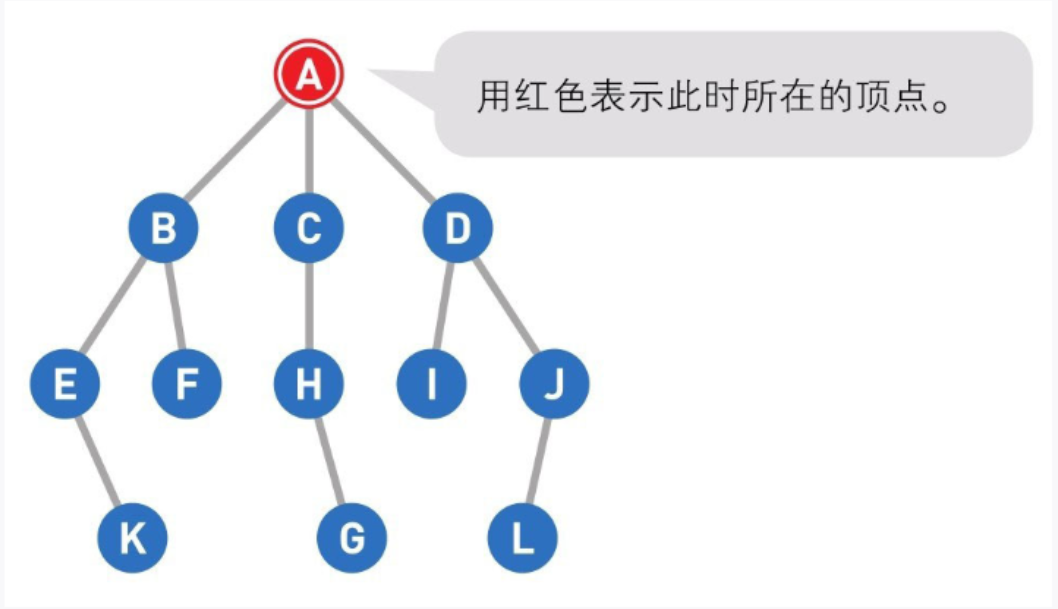
A为起点,G为终点。一开始我们在起点A上。
02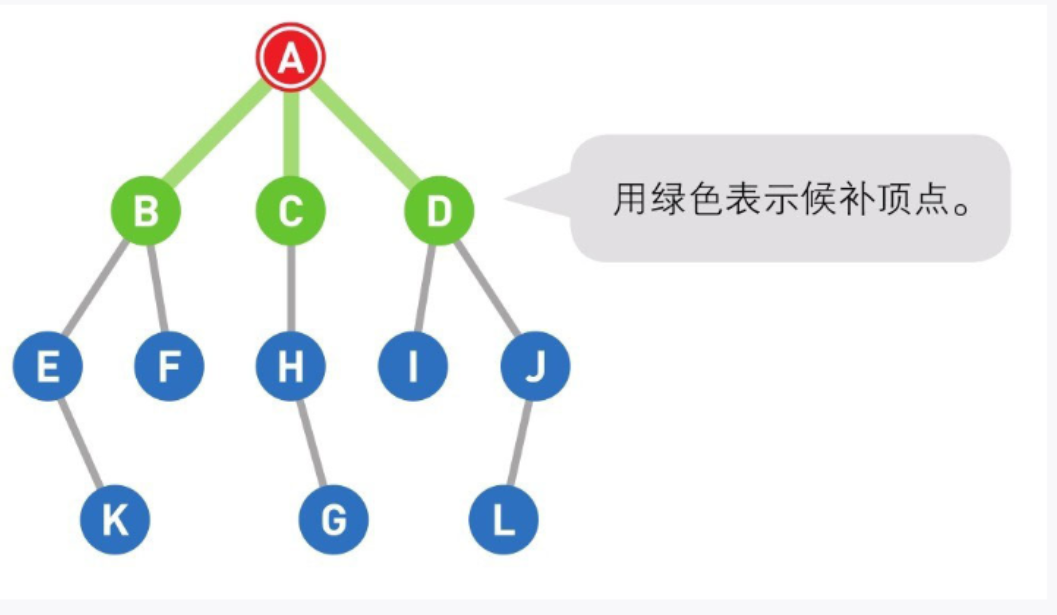
将可以从A直达的三个顶点B、C、D设为下一步的候补顶点。
03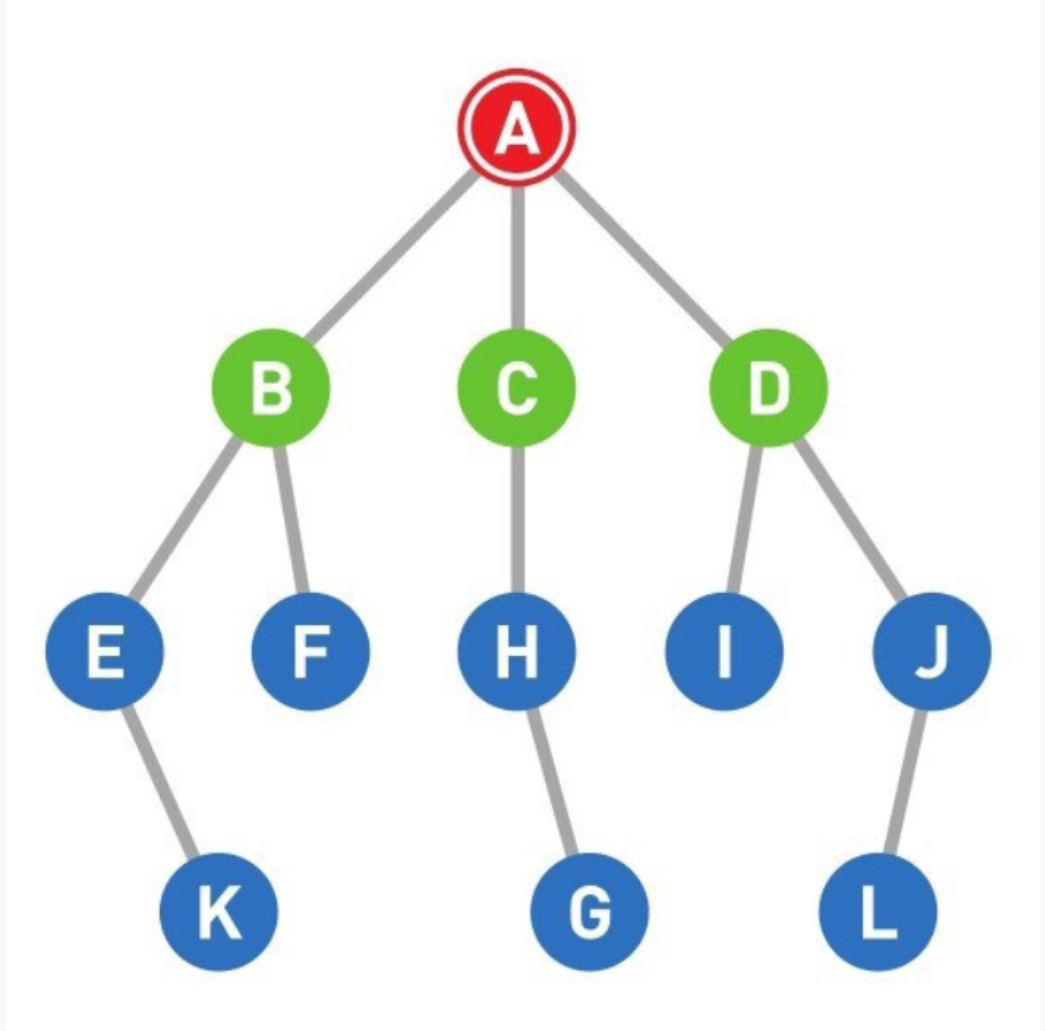
从候补顶点中选出一个顶点。优先选择最新成为候补的点,如果几个顶点同时成为候补,那么可以从中随意选择一个。
04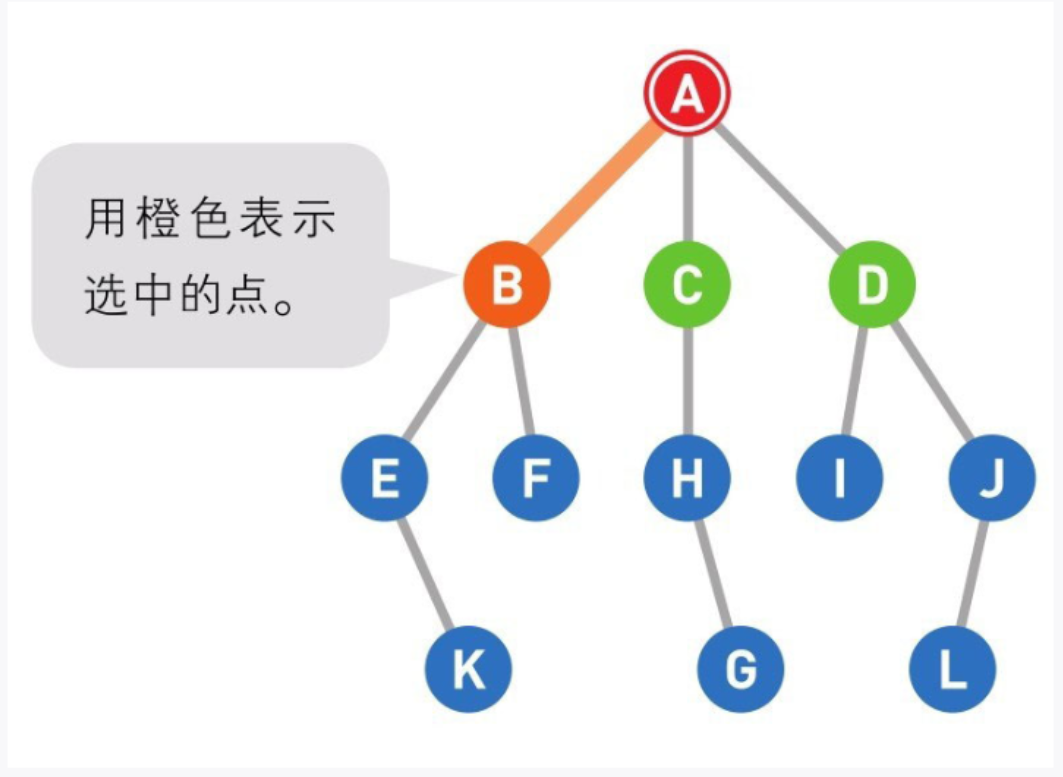
此处B、C、D同时成为候补,所以我们随机选择了最左边的顶点。
05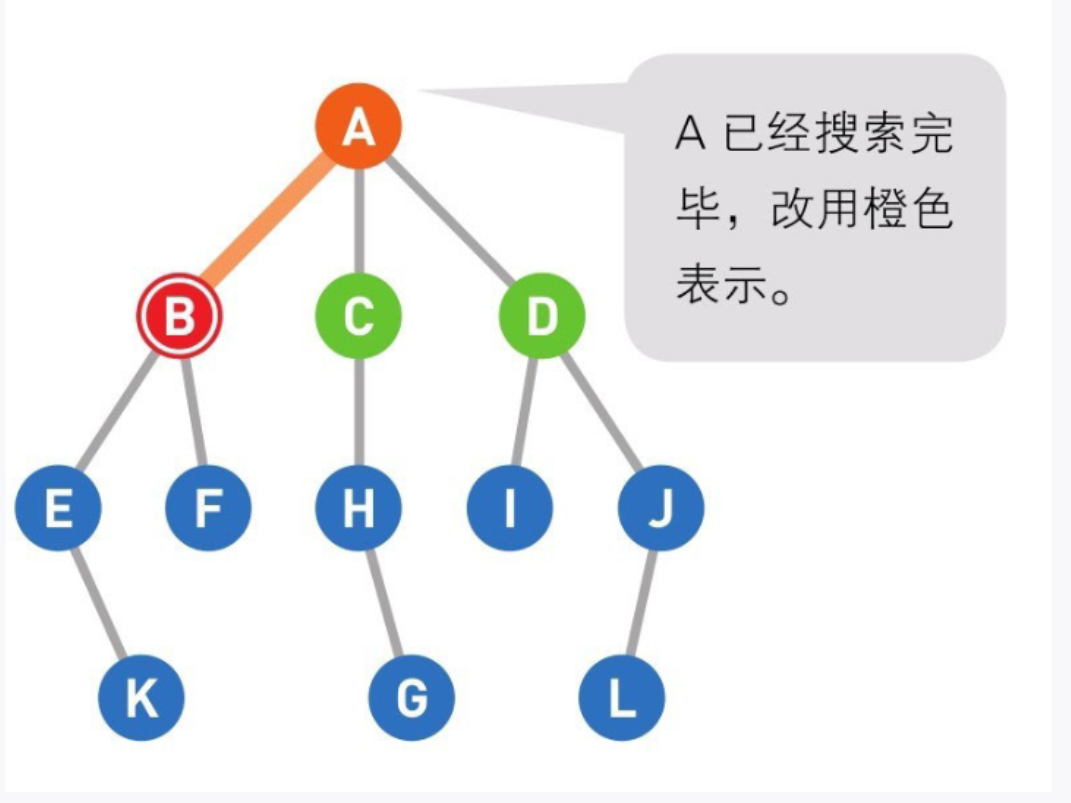
移动到选中的顶点B。此时我们在B上,所以B变为红色,同时将已经搜索过的顶点变为橙色。
06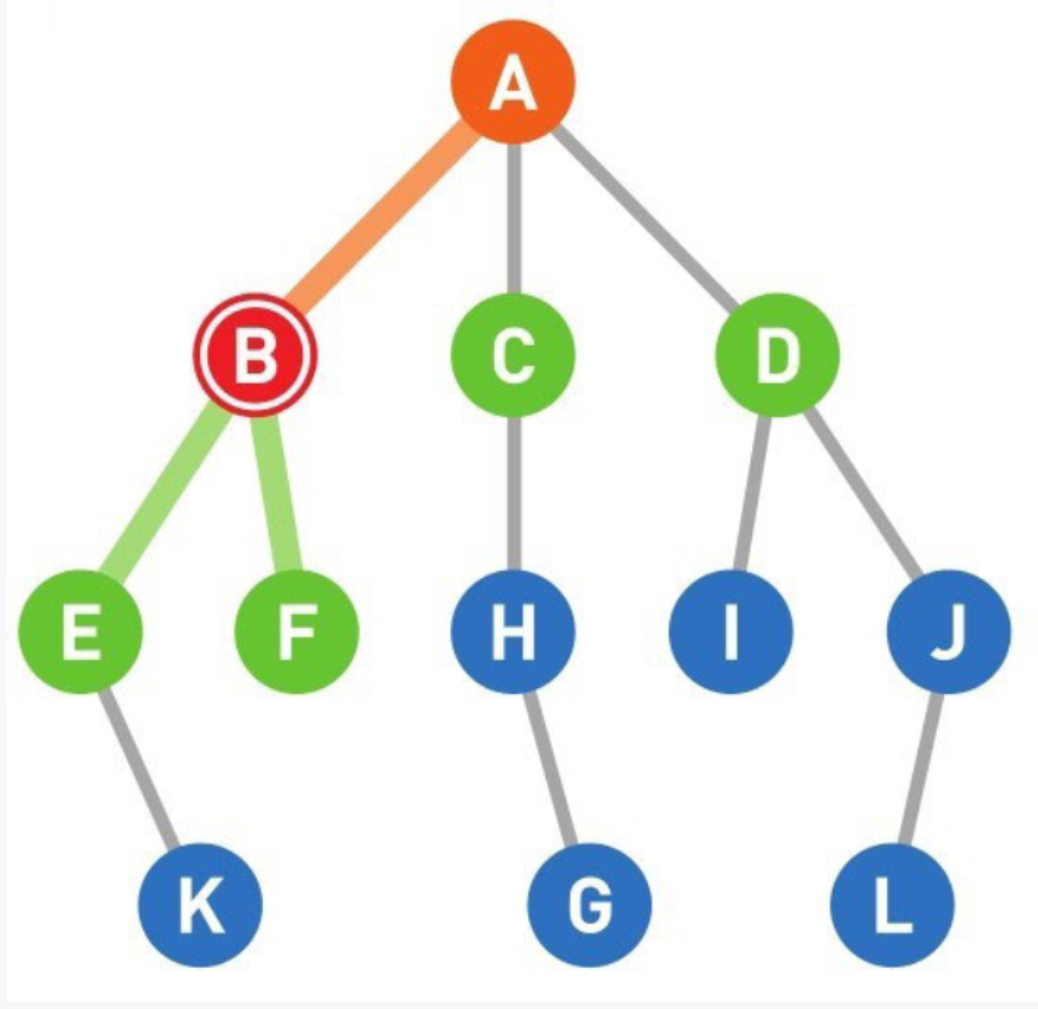
将可以从B直达的两个顶点E和F设为候补顶点。
07

此时,最新成为候补顶点的是E和F,我们选择了左边的顶点E。
08
移动到选中的顶点E上。
09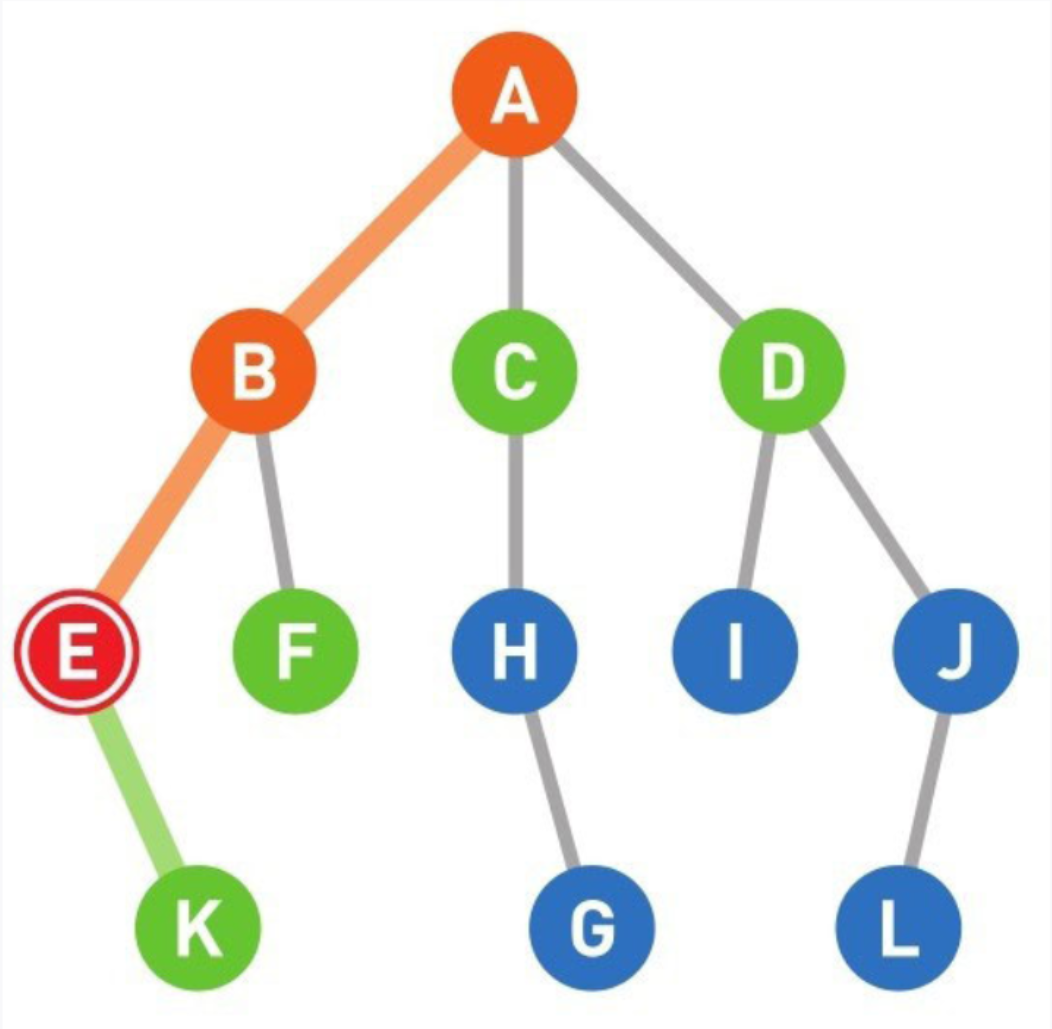
将可以从E直达的顶点K设为候补顶点。
10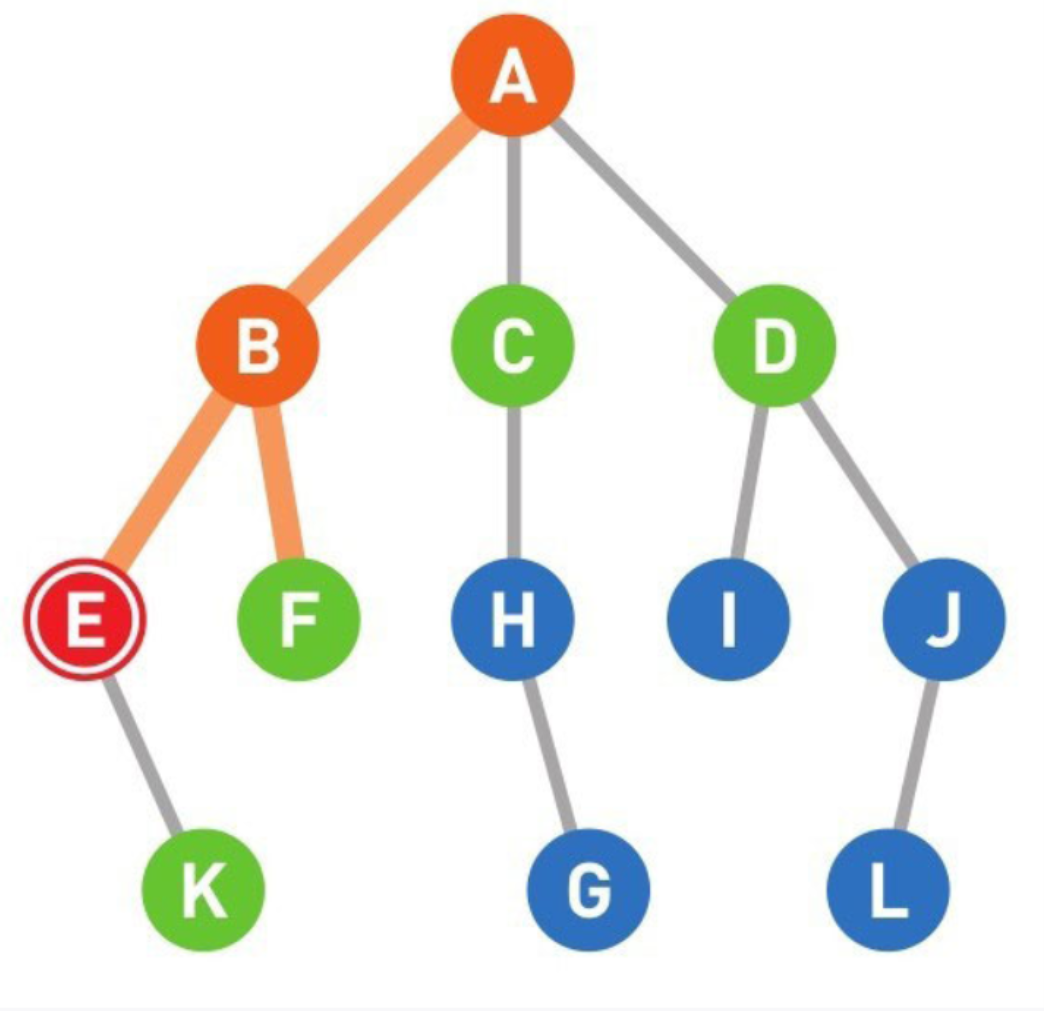
重复上述操作直到到达终点,或者所有顶点都被遍历为止。
11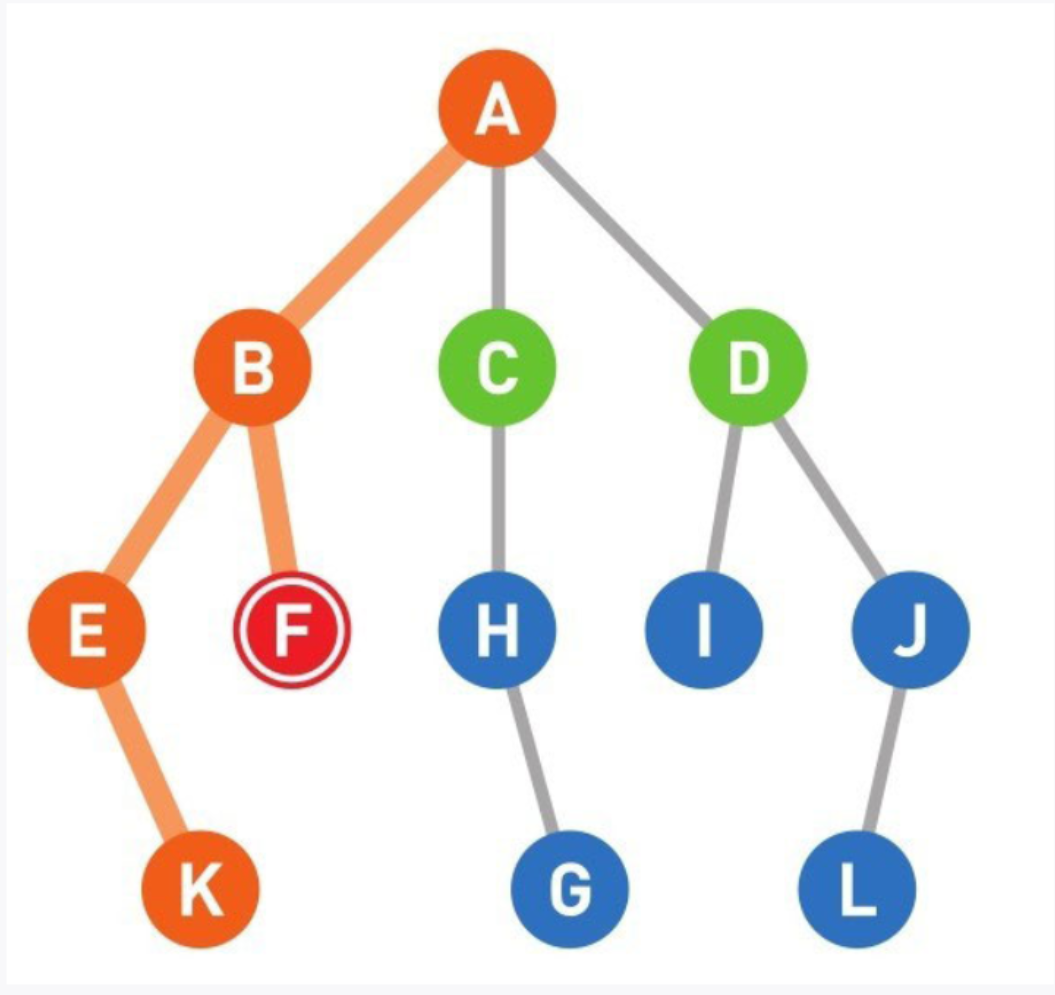
这个示例的搜索顺序为A、B、E、K、F、C、H。
12
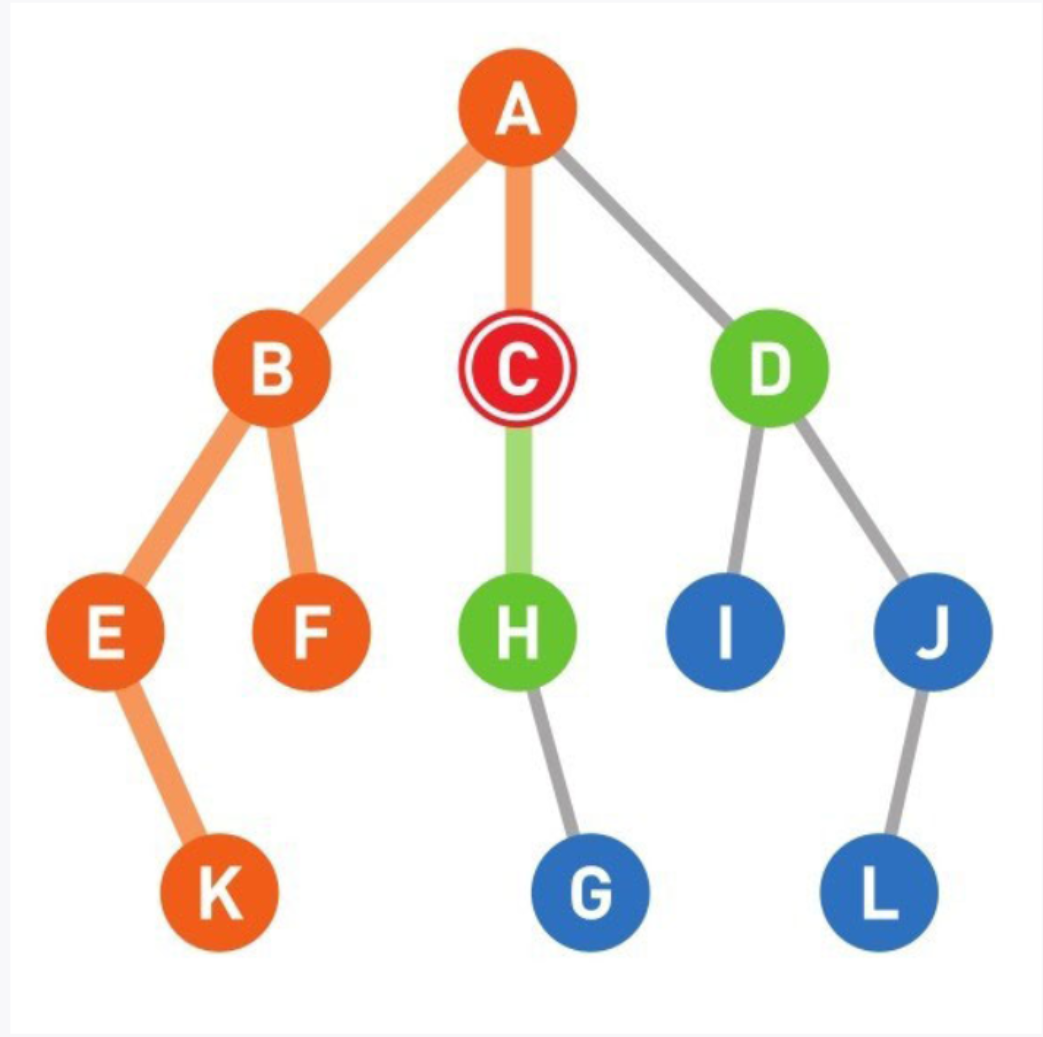
现在我们搜索到了顶点C。
13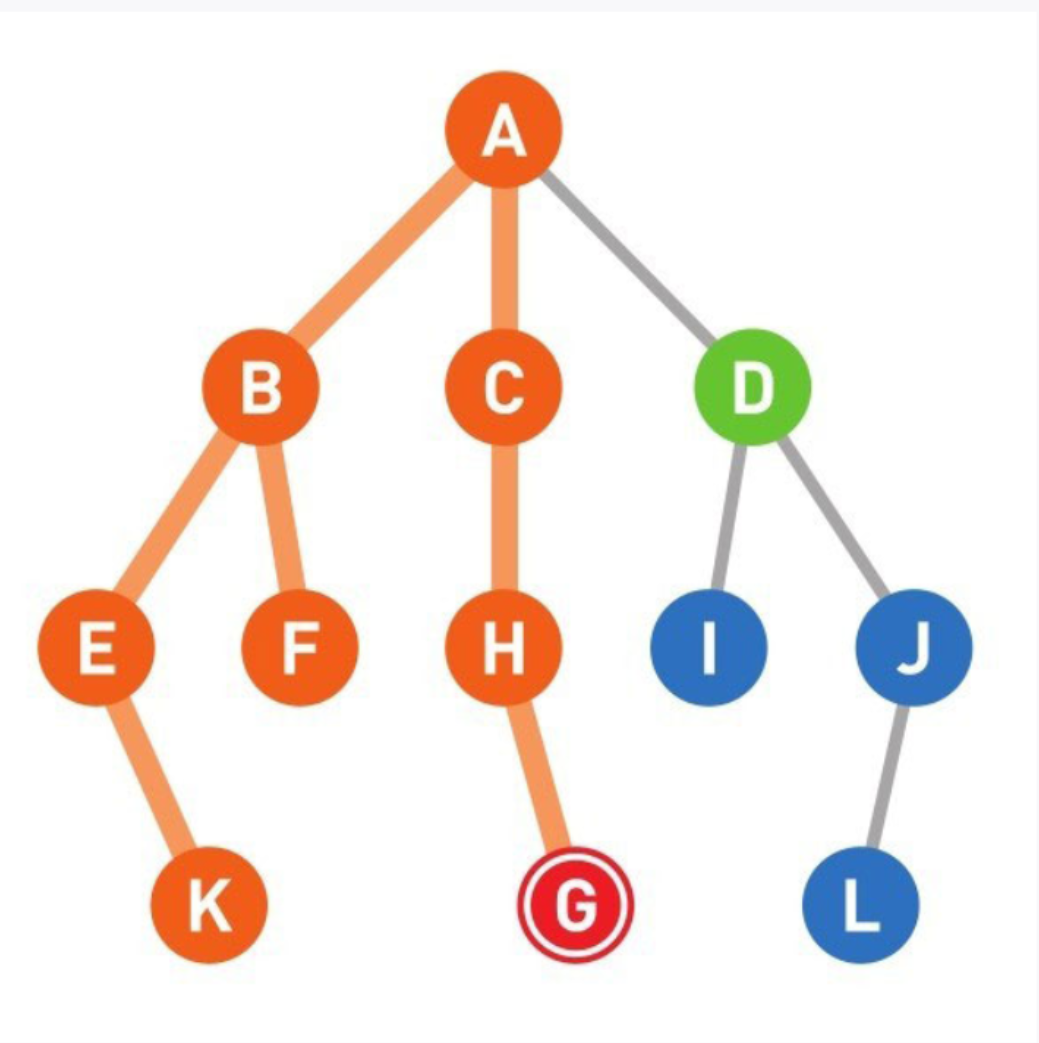
到达终点G,搜索结束。
解说:
深度优先搜索的特征为沿着一条路径不断往下,进行深度搜索。虽然广度优先搜索和深度优先搜索在搜索顺序上有很大的差异,但是在操作步骤上却只有一点不同,那就是选择哪一个候补顶点作为下一个顶点的基准不同。
广度优先搜索选择的是最早成为候补的顶点,因为顶点离起点越近就越早成为候补,所以会从离起点近的地方开始按顺序搜索;而深度优先搜索选择的则是最新成为候补的顶点,所以会一路往下,沿着新发现的路径不断深入搜索。
演示:
1 递归实现dfs
def dfs(graph, start, visited=None):
if visited is None:
visited = set() # 用集合来存储已经访问过的节点
visited.add(start) # 将当前节点标记为已访问
print(start, end=' ') # 输出当前访问的节点
if start in graph: # 检查当前节点是否在图中存在邻居节点
for neighbor in graph[start]: # 遍历当前节点的邻居节点
if neighbor not in visited: # 如果邻居节点未被访问过
dfs(graph, neighbor, visited) # 递归地对邻居节点进行深度优先搜索
# 示例图的邻接表表示
graph = {
'A': ['B', 'C', 'D'],
'B': ['E', 'F'],
'C': ['H'],
'D': ['I', 'J'],
'E': ['K'],
'H': ['G'],
'J': ['L']
}
# 从节点'A'开始进行深度优先搜索
dfs(graph, 'A')
结果
A B E K F C H G D I J L 2 栈实现dfs
def dfs_iterative(graph, start):
visited = set() # 用集合来存储已访问过的节点
stack = [start] # 使用列表模拟栈,起始时放入起始节点
while stack:
current_node = stack.pop() # 弹出栈顶节点
if current_node not in visited:
visited.add(current_node) # 将当前节点标记为已访问
print(current_node, end=' ') # 输出当前访问的节点
if current_node in graph: # 检查当前节点是否在图中存在邻居节点
for neighbor in graph[current_node]: # 遍历当前节点的邻居节点
if neighbor not in visited: # 如果邻居节点未被访问过
stack.append(neighbor) # 将邻居节点压入栈中以供后续访问
# 示例图的邻接表表示
graph = {
'A': ['B', 'C', 'D'],
'B': ['E', 'F'],
'C': ['H'],
'D': ['I', 'J'],
'E': ['K'],
'H': ['G'],
'J': ['L']
}
# 从节点'A'开始进行深度优先搜索(迭代实现)
dfs_iterative(graph, 'A')
结果
A D J L I C H G B F E K———————————————————————————————————————————
文章来源:书籍《我的第一本算法书》
书籍链接:
我的第一本算法书 (豆瓣) (douban.com)
作者:宫崎修一 石田保辉
出版社:人民邮电出版社
ISBN:9787115495242
本篇文章仅用于学习和研究目的,不会用于任何商业用途。引用书籍《我的第一本算法书》的内容旨在分享知识和启发思考,尊重原著作者宫崎修一和石田保辉的知识产权。如有侵权或者版权纠纷,请及时联系作者。
———————————————————————————————————————————

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









