







介绍
在线文档:https://pyod.readthedocs.io/en/latest/
项目地址: https://github.com/yzhao062/pyod
官网提供的资源: https://github.com/yzhao062/anomaly-detection-resources
官网上有介绍pyod:
PyOD is the most comprehensive and scalable Python library for detecting outlying objects in multivariate data. This exciting yet challenging field is commonly referred as Outlier Detection or Anomaly Detection.
PyOD 是用于检测多元数据中的异常对象的最全面和可扩展的 Python 库。 这个令人兴奋但具有挑战性的领域通常被称为异常检测或异常检测。
PyOD includes more than 40 detection algorithms, from classical LOF (SIGMOD 2000) to the latest ECOD (TKDE 2020). Since 2017, PyOD [AZNL19] has been successfully used in numerous academic researches and commercial products [AZHC+21, AZNHL19] with more than 7 million downloads.
PyOD 包括 40 多种检测算法,从经典的 LOF (SIGMOD 2000) 到最新的 ECOD (TKDE 2020)。 自 2017 年以来,PyOD 已成功用于众多学术研究和商业产品 ,下载量超过 700 万次。
pyod的特点:
- 跨各种算法的统一 API、详细文档和交互式示例。
- 高级模型,包括距离和密度估计的经典模型、最新的深度学习方法以及 ECOD 等新兴算法。
- 使用 numba 和 joblib 使用 JIT 和并行化优化性能。
- 使用 SUOD [AZHC+21] 进行快速训练和预测。
代码(举个例子)
所有的算法模型都在 pyod/pyod/models/ 这个目录下,所有算法的用法/例子都在 examples/ 下
就拿官方提供的KNN的例子来说,
KNN算法代码路径是 pyod/pyod/models/knn.py ,KNN用法路径是pyod/examples/knn_example.py ,
核心代码如下(完整代码:click here):
(看懂example很重要,因为后面很多其他的算法的用法/example都是采用这样的代码模板)
1.生成样本数据
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, y_train, X_test, y_test = generate_data(
n_train=n_train, n_test=n_test, contamination=contamination)
- generate_data():用来生成合成数据,正常数据由多元高斯分布生成,异常值由均匀分布生成。生成200个训练数据和100个测试数据,其中异常率是0.1
2.初始化KNN,并训练
# train kNN detector
clf_name = 'KNN'
clf = KNN()
clf.fit(X_train)
# get the prediction labels and outlier scores of the training data
y_train_pred = clf.labels_ # binary labels (0: inliers, 1: outliers)
y_train_scores = clf.decision_scores_ # raw outlier scores
# get the prediction on the test data
y_test_pred = clf.predict(X_test) # outlier labels (0 or 1)
y_test_scores = clf.decision_function(X_test) # outlier scores
- fit(X):KNN类的一个方法(其他算法也有),主要功能是用数据X来训练检测器clf
- labels_:检测器预测的标签
- decision_scores_:检测器对x的异常分数,分数越高,说明越异常
- predict():检测器被训练(fit)好后,预测未知数据(测试数据)的异常标签
- decision_function():在检测器clf被fit后,可以通过该函数来预测未知数据的异常程度,返回值为原始分数,并非0和1。返回分数越高,则该数据点的异常程度越高
所以,整个代码逻辑是,先生成一些数据,分别来自正态分布和均匀分布。用生成的x数据去训练(fit)初始化的clf检测器,然后就可以得到异常标签和异常分数,当clf被训练好后,可以使用decision_function() 和 predict() 函数来对测试集进行预测
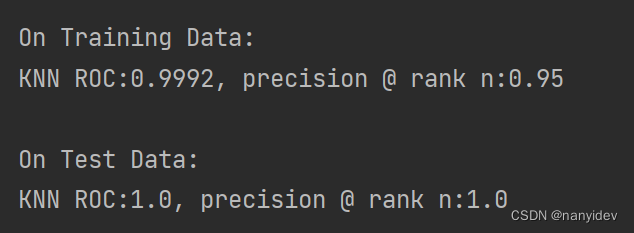
3.评估性能(Roc)
from pyod.utils.data import evaluate_print
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, y_train_scores)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, y_test_scores)
可视化结果:
分为训练集和测试集,训练集分为一开始真实数据的分布,以及预测集的分布;测试集同理。


















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









