









神经网络基础
目录
5、得分函数
线性函数:从输入à输出的映射,f(x-图像数据,w-权重参数,b-微调)= wx + b每个类别的得分
6、损失函数
损失函数:Li(衡量权值的优劣)
正则化惩罚项:只考虑权重参数的影响
损失函数=数据损失+正则化惩罚项
(越强大的神经网络,越容易过拟合)
7、前向传播整体流程
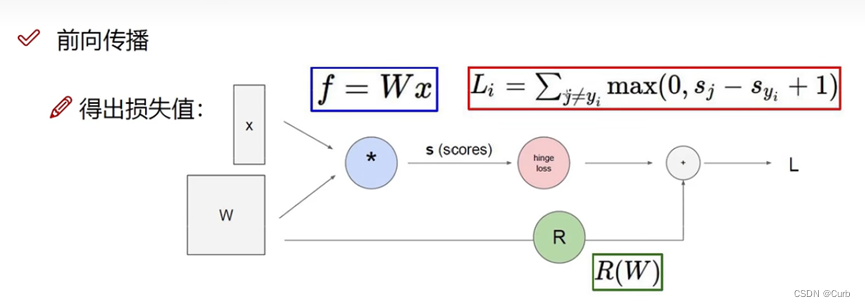
整个过程就是fàL的过程
Softmax分类器:

归一化:得到0-1的值
计算损失值
8、反向传播计算方法
更新模型——这个就交给反向传播了(梯度下降-求导(或者偏导))
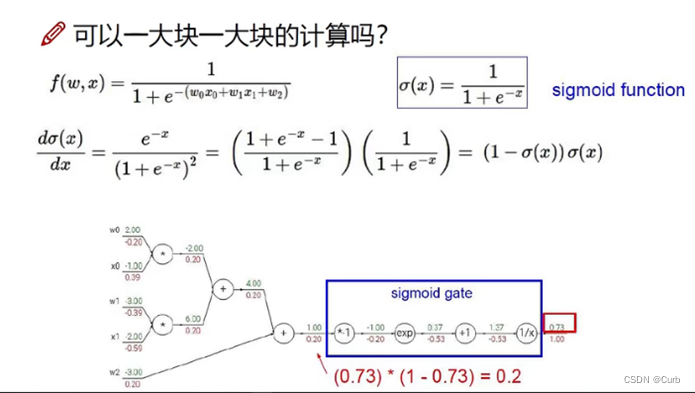
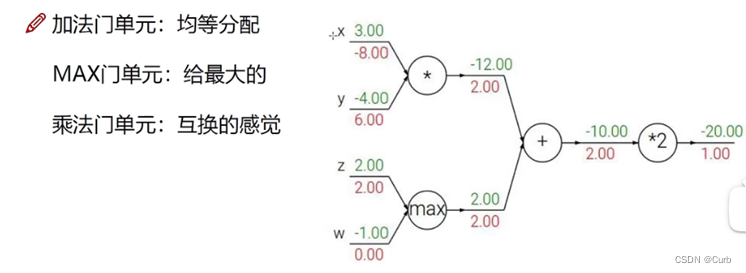
链式法则:梯度是一步一步传递的

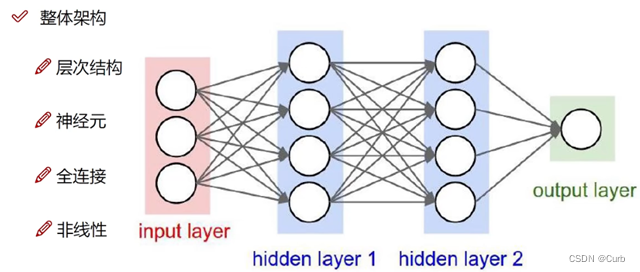
9、神经网络整体架构
需要做到:明白从前到后对x做了什么,从后到前对权重w又做了什么
10、神经网络架构细节
层次结构:输入层、隐藏层、输出层
神经元:数据
全连接:其中注意输入的数量,权重矩阵的大小,最终的效果主要取决于权值
非线性:[(xw1)w2]w3,不能这样,非线性变换(sigmod、max函数等)

11、神经元的个数对结果的影响
越多,拟合程度越大,得到的效果越好,但是速度会越慢
12、正则化与激活函数
增加一个神经元,隐藏层参数增加很大
惩罚力度对结果的影响,惩罚力度较小,效果不太好;最终主要还是测试集达到好的效果,训练集体现好,可能存在过拟合的情况
参数个数对结果的影响:权重参数(权重矩阵64、128、256、512)
正则化:它是一种非常实用的减少方差的方法,正则化时会出现偏差方差权衡问题,偏差可能略有增加,如果网络足够大,增幅通常不会太高。
过拟合、高偏差的解决:1)正则化
2)增加数据
过拟合:一开始经过迭代若干次损失函数为0的情况叫做过拟合,训练集和测试集是有差异的,过分去拟合了训练集,放大了差异性,衰弱了共性,回归损失函数为0的情况说明你拟合了噪声,最后导致了效果差,换句话说拟合函数的过程中模型需要顾忌每一个点,最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,但是损失函数附加了参数的平方和,导致整个算法不会让参数变的过大,使得拟合函数波动变小。这个参数的平方和就是一种正则化项,用来解决过拟合问题。损失函数加正则项,一般称为目标函数。
逻辑回归中实现L2正则化。其中,正则化部分通常表示为:
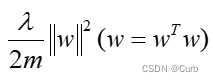
神经网络中实现正则化。可表示为
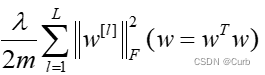
其中L表示层数
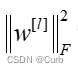
该矩阵范数称为“弗罗贝尼乌斯范数”,用下标F标注。 是正则化参数,通常使用验证集或交叉验证集来配置这个参数。L2正则化有时被称为:权重衰减
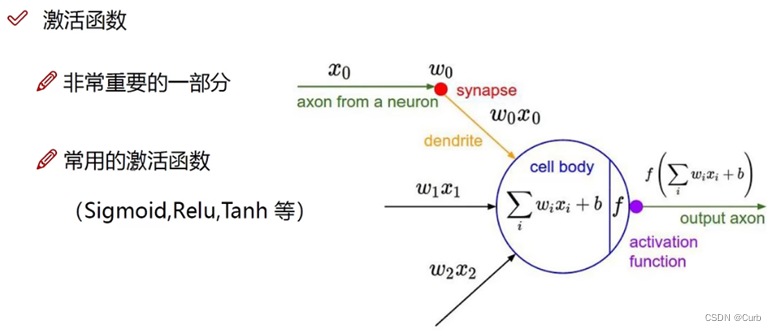
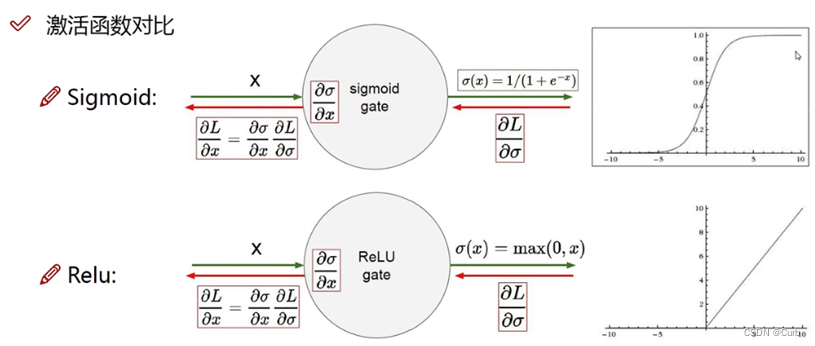
Sigmoid:存在梯度消失的情况(无穷大和无穷小的时候,梯度趋于0)
Relu:
13、神经网络过拟合解决办法
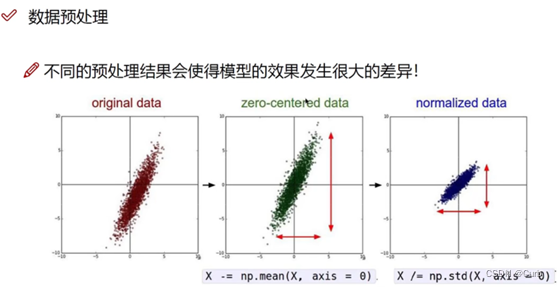
前面也有提到相关的办法。数据预处理——标准化
参数初始化——
一开始给一个随机值

正则化:有利于预防过拟合
总结一下,如果正则化参数变得很大,参数W很小,z也会相对变小,此时忽略b的影响z会相对变小,实际上,z的取值范围很小,这个激活函数,也就是曲线函数tanh会相对呈线性,整个神经网络会计算离线性函数近的值,这个线性函数非常简单,并不是一个极复杂的高度非线性函数,不会发生过拟合。(注意定义的J函数,它包含第二个正则化项,否则函数J可能不会在所以调幅范围内都单调递减)
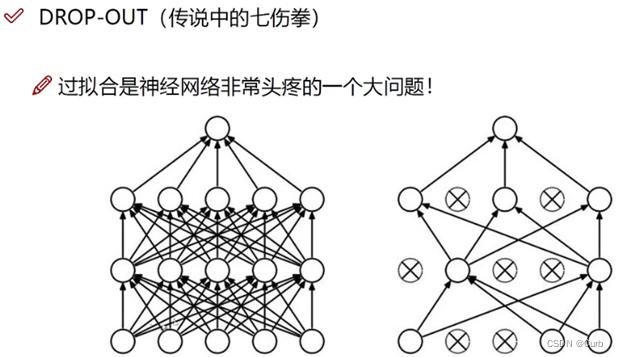
Dropout正则化:“随机失活”,设置了消除神经网络中节点的概率
实施Dropout——最常用的方法:inverted dropout(反向随机失活),其中通过除以keep-prob,确保其期望值不变。
测试阶段不使用Dropout,否则预测会受到干扰。
需要牢记一点,dropout是一种正则化方法,它有助于预防过拟合,因此除非算法过拟合,不然是不会使用dropout的,所以它在其它领域应用得比较少,主要存在于计算机视觉领域,通常因为没有足够的数据,所以一直存在过拟合,这就是有些计算机视觉研究人员如此钟情于dropout函数的原因。
dropout一大缺点就是代价函数J不再被明确定义,每次迭代,都会随机移除一些节点,如果再三检查梯度下降的性能,实际上是很难进行复查的。定义明确的代价函数J每次迭代后都会下降,因为我们所优化的代价函数J实际上并没有明确定义,或者说在某种程度上很难计算,所以我们失去了调试工具来绘制这样的图片。我通常会关闭dropout函数,将keep-prob的值设为1,运行代码,确保J函数单调递减。然后打开dropout函数,希望在dropout过程中,代码并未引入 bug。我觉得你也可以尝试其它方法,虽然我们并没有关于这些方法性能的数据统计,但你可以把它们与dropout方法一起使用。
其他解决过拟合办法:数据扩增(翻转、裁剪)、early stopping
正交化实现减少方差。
附:主要参考了吴恩达深度学习课程
https://www.bilibili.com/video/BV15t4y1G7kq?p=5&vd_source=200eb8f70ee525f2747b0dbbe1d06ab0
https://www.bilibili.com/video/BV16r4y1Y7jv?spm_id_from=333.999.0.0
https://hekuan.blog.csdn.net/article/details/79827273?spm=1001.2014.3001.5506

















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









