







论文:https://arxiv.org/abs/2205.01529
github:https://github.com/yzd-v/MGD
看到CV领域的知识蒸馏,看完摘要和图片后,心中大喜哈哈哈知识蒸馏还能这么做。
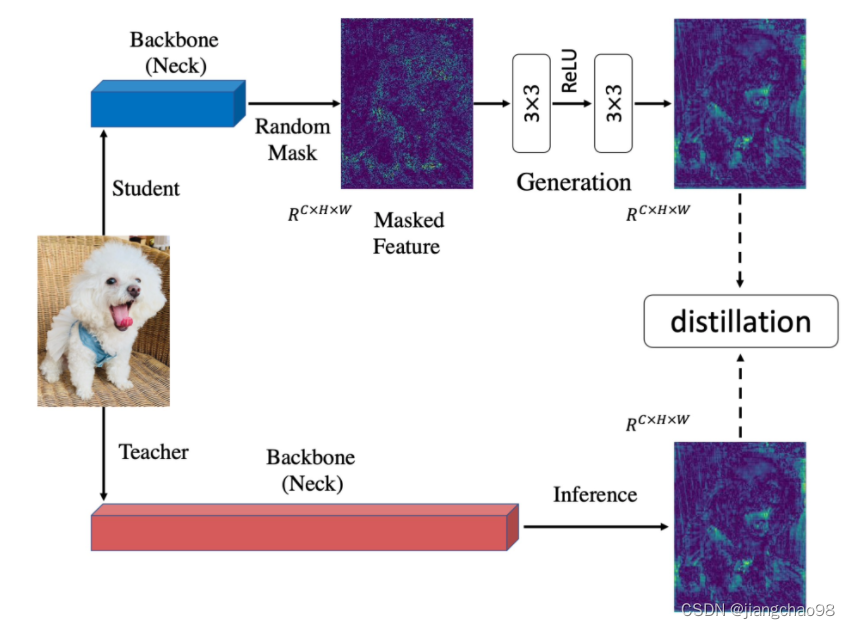
知识蒸馏主要可以分为logit蒸馏和feature蒸馏。其中feature蒸馏具有更好的拓展性,已经在很多视觉任务中得到了应用。但由于不同任务的模型结构差异,许多feature蒸馏方法是针对某个特定任务设计的。
之前的知识蒸馏方法着力于使学生去模仿更强的教师的特征,以使学生特征具有更强的表征能力。我们认为提升学生的表征能力并不一定需要通过直接模仿教师实现。从这点出发,我们把模仿任务修改成了生成任务:让学生凭借自己较弱的特征去生成教师较强的特征。在蒸馏过程中,我们对学生特征进行了随机mask,强制学生仅用自己的部分特征去生成教师的所有特征,以提升学生的表征能力。
为了证明MGD并不是通过模仿教师来提升学生,我们对学生和教师的特征图进行了可视化。可以看到,蒸馏前的学生与教师的注意力相差很大。在使用FGD蒸馏(模仿教师)后,学生的注意力和教师变得很接近,表现也得到了较大的提升。但当使用MGD蒸馏后,学生与教师差异很大,学生对于背景的响应大幅减小,对于目标的响应得到了增强,学生的最终表现也好于FGD蒸馏。

通常的做法,使得学生的特征去模仿教师的特征, 使用KL散度或者MSE来对齐学生的特征以及教师的特征,但是学生模仿的效果必然差于教师模型。
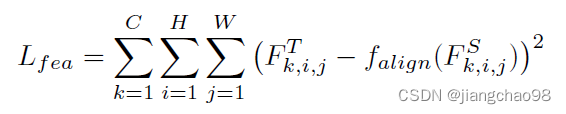
Generation with Masked Feature
本文使用的方法,对学生模型的特征进行随机mask遮盖,通过卷积层和ReLU激活函数来进行特征变换,使得对特征进行修复
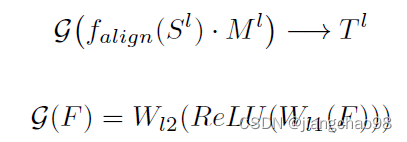
loss损失函数为:
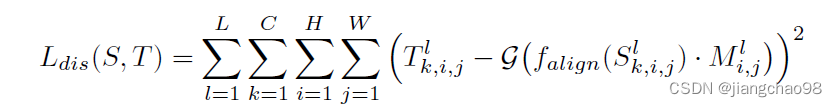
S、T分别表示学生和教师,L表示层数,C、H、W表示特征图的大小
总的训练loss函数为: , 为原始的loss与 蒸馏的loss相加

MGD是一个基于特征的蒸馏方法,可以被应用于不同的任务中。文章中在不同任务上进行了实验,包括图片分类、目标检测、语义分割、实例分割。
MGD迫使学生去产生教师的完全特征图而不是直接模仿教师,它帮助学生模型更好的表示图片的输入。模仿的蒸馏loss是教师和学生特征图之间的平方差损失函数。
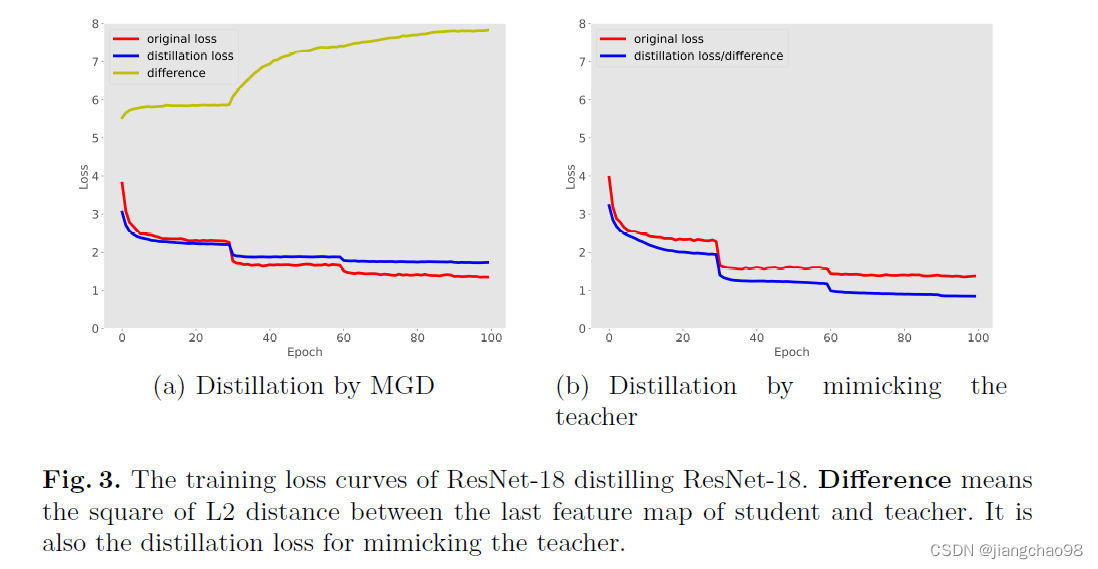 loss损失如图所示, 使用MGD的distillation loss逐渐会超越teacher model
loss损失如图所示, 使用MGD的distillation loss逐渐会超越teacher model















 451
451











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









