







 本文介绍了人工神经网络的基础概念,包括神经元、感知器、输入层、输出层和隐藏层的功能,以及激活函数、加权和处理的重要性。详细讲解了FNN(前馈神经网络)如何在浅层和深层学习中切换。此外,文章还概述了神经网络的学习过程,涉及学习算法、损失函数和R包实现示例。
本文介绍了人工神经网络的基础概念,包括神经元、感知器、输入层、输出层和隐藏层的功能,以及激活函数、加权和处理的重要性。详细讲解了FNN(前馈神经网络)如何在浅层和深层学习中切换。此外,文章还概述了神经网络的学习过程,涉及学习算法、损失函数和R包实现示例。
brief
机器学习就是通过算法使得机器能从大量历史数据中学习规律, 从而对新的样本做智能识别或对未来做预测。(machine learn and predict from data).
机器学习根据其学习模型分为浅层学习和深层学习。
- 浅层学习模型包括:隐马尔可夫模型 (HMM)、 线性或非线性动态系统、 条件随机域 ( CRFs)、最大熵 (Max - entropy) 模型、 支持向量机 ( SVM)、 逻辑回归、 内核回归和具有单层隐藏层的多层感知器 (MLP) 神经网络。
- 深层学习模型包括:FNN,CNN,DNN,RNN,DBN,GAN等等
他们的主要区别是:有没有自适应非线性特征(特征变换一次就出结果还是特征连续变化多次出结果)。
我们今天学习的是FNN(Feed - forward Neural Networks),他就很特殊,可以是浅层学习,也可以是深层学习模型。适合我这种新手入门。他是如何做到身份切换的呢?
上面说到具有单层隐藏层的多层感知器 (MLP) 神经网络是一种浅层学习模型,FNN包括一层隐藏层那就是浅层学习模型,包括两层隐藏层以上就是深层学习模型。
为了说的更清楚一些,我们下面会解释很多概念,这些最基础的概念对理解人工神经网络很有帮助。
基础概念
神经元
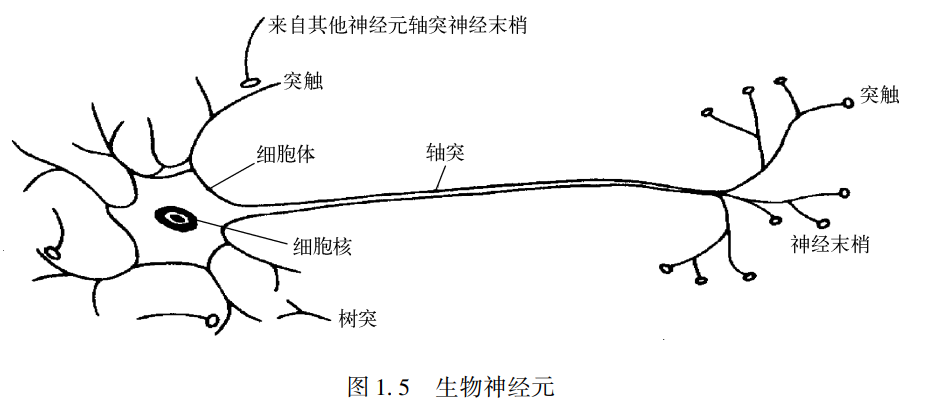
通常说的神经元指反射弧中的神经细胞,机器学习中的神经元指的是感知器。
感知器模拟人的神经元细胞的工作原理,实现信息的处理和传递。
神经细胞的树突接受外部信号,细胞体整合这些信号,有些是刺激信号有些是抑制信号,整合后得到一个一般性的信号,如果这个信号强度大则通过轴突往外部传递,如果这个信号强度小则忽略这个信号。
感知器
可以看到神经细胞在信号传递过程中有三个关键过程,1.信号接受;2.信号整合;3.信号输出
感知器模拟神经元细胞工作,所以他也有三个关键部分构成:
1.输入层:输入层对输入数据进行求和
2.中间层:中间层对由输入层传输而来的加权信息进行转换
3.输出层:输出层对由中间层传输而来的信息进行判断和输出

给定一个输入样本的特征 { x1,…,xn } 和 一个权重 Wi; 接着计算神经元输入的加权和, 公式如下:

神经细胞组成了人体的反射弧,那么感知器组成了机器的反射弧,从而实现对一些信息(带有特征信息的样本)做出拟人化智能化的反应:分类,预测,排序,回归等。
人工神经网络
人工神经网络(英语:artificial neural network,ANNs)简称神经网络(neural network,NNs)或类神经网络,在机器学习和认知科学领域,是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型。神经网络由大量的人工神经元(感知器)联结进行计算。
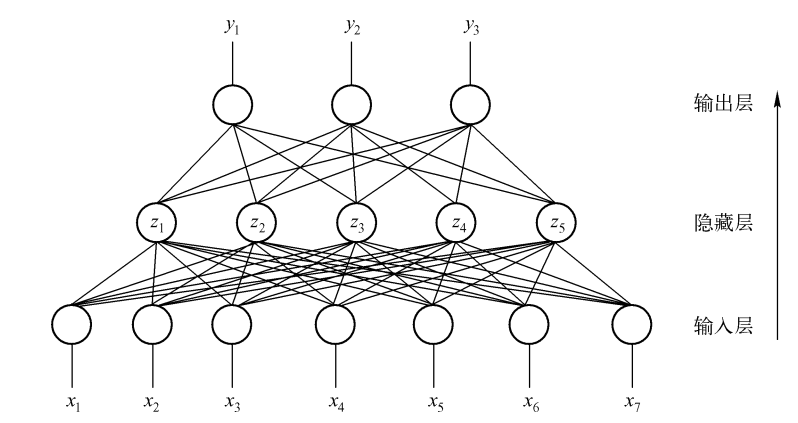
整个神经网络大致可以分为三个部分:输入层,隐藏层,输出层,每一层都包括至少一个人工神经元(人工神经元也有输入层,中间层,输出层)。形如:图中的每一个小圆圈代表一个人工神经元(感知器)
输入层神经元
接收进入网络的信息, 这些信息通过一个数学函数来处理, 接着被传递到隐藏层神经元。(感知器那部分)
输出层神经元
输出层神经元对由隐藏层神经元传输而来的加权信息进行数学函数来处理,接着被分类器函数处理,然后输出
隐藏层
隐藏层神经元接收输入层神经元传输而来的加权信息进行数学函数来处理, 接着被传递到输出层神经元
所以总结来看,神经元的任务就是, 在传递输出到下一层之前, 对输入信号进行数学函数处理并判断是否进行信号的向下传递。这个数学函数处理部分包括加权和以及非线性变换,执行非线性变换的函数被称为激活函数。激活函数得到的信号大于设定的阈值则信号向下传递,否则不传递。
加权和处理: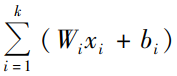
非线性变换: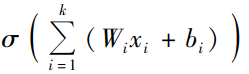
激活函数
隐藏层结点需要激活函数实现非线性变换。 一个神经元先执行激活函数, 接着函数的输出传输到网络的下一层神经元。
设计激活函数是为了限制神经元的输出,输出值通常被限定在 0 ~ 1 或者 - 1 ~ 1 之间。
在大部分情况下, 一个网络中的每一个神经元的激活函数都是一样的。
几乎所有的非线性函数都可以充当激活函数, 尽管如此, 对前向传播算法而言, 激活函数必须是可微的, 如果是有界函数, 将会更有帮助。



每一个激活函数的适用场景略有不同,需要实践中认真体会。
神经网络的学习(训练)过程
我们前面看到,神经网络大致包含了输入层,隐藏层,输出层,每一层的人工神经元做了加权和信号转换以及信号强度判断(细品上面关于隐藏层下面的那段话)。
加权计算的过程有两个参数:特征的权重w 和 截距 b。
权重w在信号加权中决定了那个特征重要,那个特征次要,实现了样本的抽象描述。
参数 b被称为抑制量 (偏置), 它类似于线性回归模型中的截距。 它使得网络能够 “上移” 或者 “下移” 激活函数。 这种弹性对于成功的机器学习是重要的。
神经网络学习的过程就是获取合适的w和b的过程。
学习算法通过最小化或最大化损失函数来优化模型的参数或结构。优化过程的目标是找到使损失函数达到最小(或最大)值的参数设置。这涉及到在参数空间中搜索的过程,通过计算损失函数的梯度(偏导数),更新模型的参数来逐步优化模型。
学习算法和损失函数在机器学习中密切相关,它们共同构成了一个机器学习模型的训练过程。
学习算法
学习算法是指用于从数据中学习/优化模型的方法。它定义了如何根据给定的数据集和目标函数(或损失函数),通过调整模型的参数或结构,使模型能够从数据中学习并进行预测。
学习算法可以是梯度下降、随机森林、支持向量机等等。
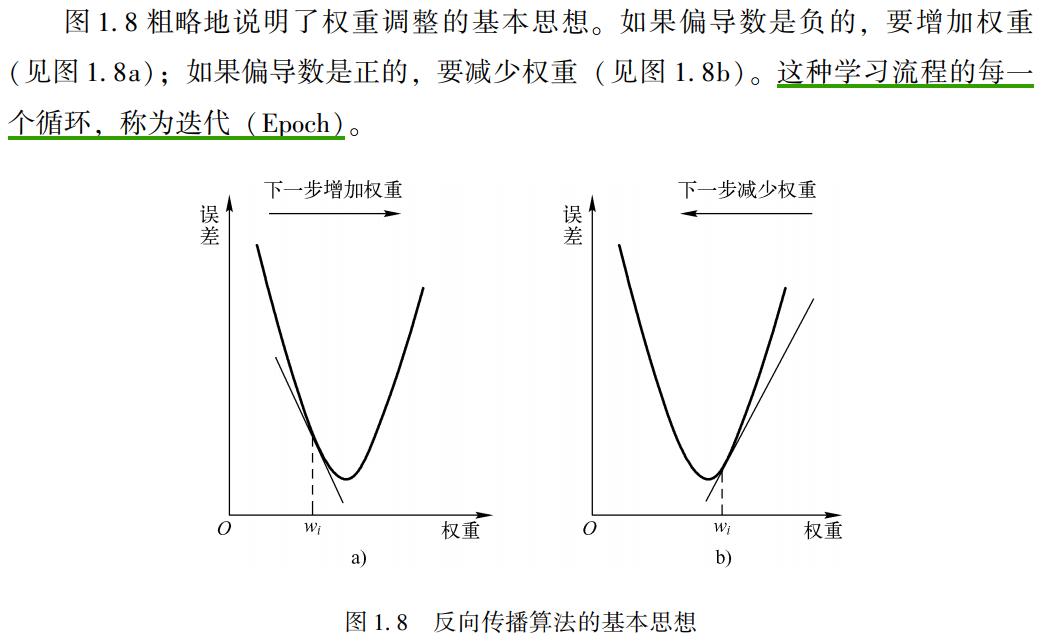
反向传播算法是最流行的学习算法, 并且现在还在广泛使用。 它将梯度下降法作为核心的学习机制。 从随机权重开始, 反向传播算法计算权重值是根据网络输出与期望输出之间的误差逐渐调整权重值。
这个算法将误差从输出端传播到输入端, 并且使用梯度下降逐渐微调网络权重使误差值最小化。

其中第五步更新权重向量,是一个很复杂的计算过程,这里抽象隐藏了。我们需要知道的是 minimize(Y - y)。
损失函数
损失函数(也称为目标函数或代价函数)是用于衡量模型预测输出与实际目标之间差异的函数。
它表示了模型的预测与真实值之间的误差程度。损失函数的选择取决于具体的问题和模型类型。
例如,对于回归问题,常用的损失函数是均方误差(Mean Squared Error),对于分类问题,常用的损失函数是交叉熵损失(Cross Entropy Loss)。
深度
神经网络的深度一般指隐藏层的层数
神经网络的结构
神经网路的结构一般指输入层,隐藏层和输出层之间是如何组织在一起的。
手动实现
library(tidyverse)
data("iris")
head(iris)
table(iris$Species)
ggplot(data = iris,aes(x = Petal.Length,y = Petal.Width,color=Species))+
geom_point()+
theme_classic()
table(c(rep(0,50),rep(1,100)),y)
### 实现单层FNN的训练过程
a <- 0.2 #学习率
w <- rep(0,3) #初始权重 ,学习的构成也就是更新它的过程
iris1 <- t(as.matrix(iris[,3:4]))
# dim(iris1)
d <- c(rep(0,50),rep(1,100)) # 理论输出值
e <- rep(0,150) # 理论误差
p <- rbind(rep(1,150),iris1) # 给数据加上标签
max <- 10000 # 迭代次数上限,epoch
eps <- rep(0,10000) # 总体误差
# e 和 eps的区别和联系:eps <- sum(e)
i <- 0 # 初始化迭代次数
# 算法学习中
# 开始迭代
repeat{
v <- w %*% p # 计算加权和
y <- ifelse(sign(v) >= 0,1,0) # 根据激活函数计算实际输出值
# 设定损失函数
e <- d - y # 计算误差
eps[i+1] <- sum(abs(e)) / length(e) # 结算平均误差
# 根据平均误差计算是否达到我们要求的精度,达到则终止迭代
# 未达到设定的精度则修改权重 也就是 w
if(eps[i+1] <= 0.01){
print("finish")
print(w)
break
}
# 这里就是反向传播算法的核心
# 梯度下降法
w <- w + a*(d - y) %*% t(p) # 修改权重公式 ,理论值d - 计算值y大于0则w变大,反之会变小
i <- i+1 # 迭代次数加一,用于存储平均误差等
# 当迭代次数达到设定值时,平均误差还不能收敛,我们应当终止训练了
if(i > max ){
print("max time loop")
print(eps[i])
print(y)
break
}
}
R包实现
# install.packages("nnet")
# install.packages("mlbench")
library(nnet)
library(mlbench)
# 数据准准备
# 随机选择半数观测作为训练集, 剩下的作为测试集
set. seed(1); #设随机数种子
data(iris)
# 标签
targets <- class.ind(c(rep("s",50),rep("c",50),rep("v",50)))
# 抽样
samp <- c(sample(1:50,25),sample(51:100,25),sample(101:150,25))
# 建模
# 建模用到 nnet 包中的 nnet 函数, 其调用格式为
ir <- nnet(iris[samp,c(1:4)], #data
targets[samp,], # 标签或者期望值
size = 3,#隐藏节点数
rang = 0.1, # Initial random weights on [-rang, rang].
softmax = TRUE, # 激活函数
decay = 5e-4, # 表明权值是递减的(可以防止过拟合)
maxit = 200 # 最大拟合次数)
)
# 分类
predict(ir, iris[-samp,c(1:4)])
# 评价
test.cl <- function(true, pred) {
true <- max.col(true)
cres <- max.col(pred)
table(true, cres)
}
test.cl(targets[-samp,], predict(ir, iris[-samp,c(1:4)]))
#
# cres
# true 1 2 3
# 1 23 0 2
# 2 0 25 0
# 3 2 0 23

















 2426
2426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









