







频繁项集挖掘方法
Apriori算法
- 先验性质:频繁项集的所有非空子集也一定是频繁的。
如果项集 I 不满足最小支持度阈值
min_sup ,则 I 不是频繁的,即P(I)<min_sup 。如果把项A添加到项集 I 中,则结果项集(I⋃A) 不可能比 I 更频繁出现。因此,I⋃A 也不是频繁的,既 P(I⋃A)<min_sup
该性质属于一类特殊的性质,成为反单调性(antimonotone) 意指如果一个集合不能通过测试,则他的所有超集也不能通过相同的测试。
Apriori算法实例:使用Apriori算法发现下图中的频繁项集。
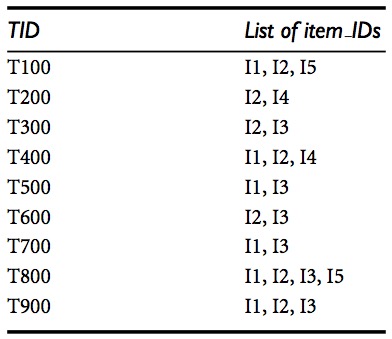
求解过程如下图所示:
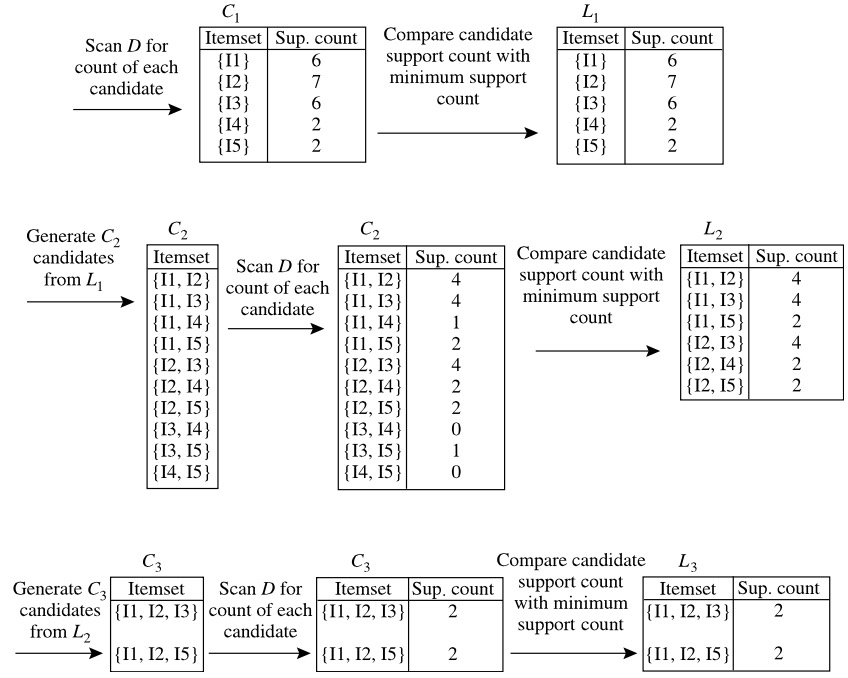
Apriori算法伪代码:

Method:
(1) 找出频繁 1 项集的集合L1 。
(2)在第2~10步,对于 k≥2 , Lk−1 用于产生候选 Ck ,以便找出 Lk 。
(3) apriori_gen 过程产生候选,然后使用先验性质删除那些具有非频繁自己的候选。
(4)扫描数据库。
(5)用于每个事务,使用 subset 函数找出该事务中是候选的所有子集。
(6)(7)对每个这样的候选累加计数。
(9)所有满足最小支持度的候选形成频繁项集的集合 L 。
apriori_gen 做两个动作:连接和剪枝。
has_infrequent_subset 使用先验性质删除具有非频繁自己的候选。
Frequent-Pattern Growth,FP-growth
转自 http://blog.csdn.net/sealyao/article/details/6460578
FPTree算法:在不生成候选项的情况下,完成Apriori算法的功能。
FPTree算法的基本数据结构,包含一个一棵FP树和一个项头表,每个项通过一个结点链指向它在树中出现的位置。基本结构如下所示。需要注意的是项头表需要按照支持度递减排序,在FPTree中高支持度的节点只能是低支持度节点的祖先节点。
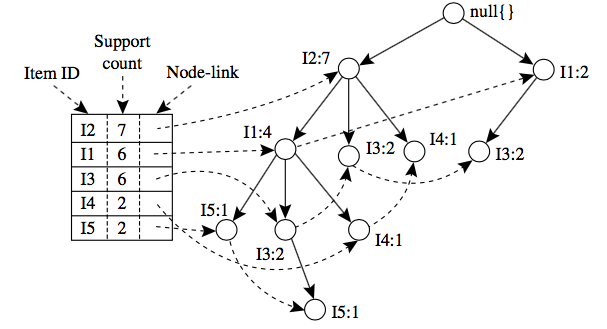
另外还要交代一下FPTree算法中几个基本的概念:
FP-Tree:就是上面的那棵树,是把事务数据表中的各个事务数据项按照支持度排序后,把每个事务中的数据项按降序依次插入到一棵以NULL为根结点的树中,同时在每个结点处记录该结点出现的支持度。
条件模式基:包含FP-Tree中与后缀模式一起出现的前缀路径的集合。也就是同一个频繁项在PF树中的所有节点的祖先路径的集合。比如I3在FP树中一共出现了3次,其祖先路径分别是{I2,I1:2(频度为2)},{I2:2}和{I1:2}。这3个祖先路径的集合就是频繁项I3的条件模式基。
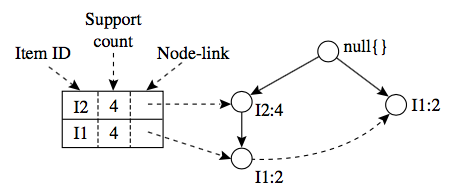
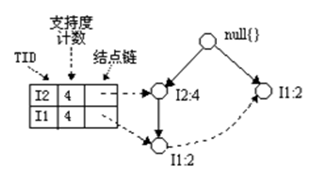
条件树:将条件模式基按照FP-Tree的构造原则形成的一个新的FP-Tree。比如上图中I3的条件树就是:
1、 构造项头表:扫描数据库一遍,得到频繁项的集合F和每个频繁项的支持度。把F按支持度递降排序,记为L。
2、 构造原始FPTree:把数据库中每个事物的频繁项按照L中的顺序进行重排。并按照重排之后的顺序把每个事物的每个频繁项插入以null为根的FPTree中。如果插入时频繁项节点已经存在了,则把该频繁项节点支持度加1;如果该节点不存在,则创建支持度为1的节点,并把该节点链接到项头表中。
3、 调用FP-growth(Tree,null)开始进行挖掘。伪代码如下:

FP-growth是整个算法的核心,再多啰嗦几句。
FP-growth函数的输入:tree是指原始的FPTree或者是某个模式的条件FPTree,a是指模式的后缀(在第一次调用时a=NULL,在之后的递归调用中a是模式后缀)
FP-growth函数的输出:在递归调用过程中输出所有的模式及其支持度(比如{I1,I2,I3}的支持度为2)。每一次调用FP_growth输出结果的模式中一定包含FP_growth函数输入的模式后缀。
我们来模拟一下FP-growth的执行过程。
1、 在FP-growth递归调用的第一层,模式前后a=NULL,得到的其实就是频繁1-项集。
2、 对每一个频繁1-项,进行递归调用FP-growth()获得多元频繁项集。
下面举两个例子说明FP-growth的执行过程。
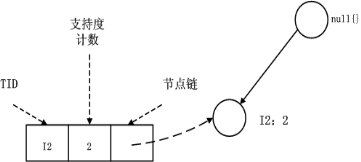
1、I5的条件模式基是(I2 I1:1), (I2 I1 I3:1),I5构造得到的条件FP-树如下。然后递归调用FP-growth,模式后缀为I5。这个条件FP-树是单路径的,在FP_growth中直接列举{I2:2,I1:2,I3:1}的所有组合,之后和模式后缀I5取并集得到支持度>2的所有模式:{ I2 I5:2, I1 I5:2, I2 I1 I5:2}。
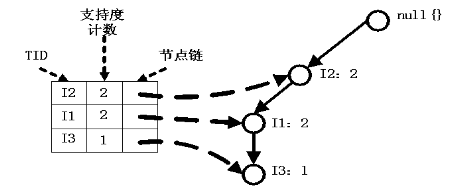
2、I5的情况是比较简单的,因为I5对应的条件FP-树是单路径的,我们再来看一下稍微复杂一点的情况I3。I3的条件模式基是(I2 I1:2), (I2:2), (I1:2),生成的条件FP-树如左下图,然后递归调用FP-growth,模式前缀为I3。I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2 I3:4, I1 I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如右下图所示。这是一个单路径的条件FP-树,在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1 I2 I3:2}。理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{ I2 I3:4, I1 I3:4, I1 I2 I3:2}
根据FP-growth算法,最终得到的支持度>2频繁模式如下:

FP-growth算法比Apriori算法快一个数量级,在空间复杂度方面也比Apriori也有数量级级别的优化。但是对于海量数据,FP-growth的时空复杂度仍然很高,可以采用的改进方法包括数据库划分,数据采样等等。
等价类变换(Equivalence CLAss Transformation,Eclat)算法
- 水平数据格式(horizontal data format): {TID:itemset}
- 垂直数据格式(vertical data format): {item:TID_set}
Apriori算法的例子,使用垂直数据格式扫描结果如下。
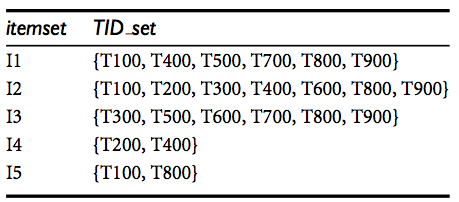
设置最小支持度为2那么所有项集都是频繁一项集。
5项集要进行10次交运算(
C25
) ,其中,
{I1,I4}
和
{I3,I5}
都只包含一个事务,因此他们都不属于频繁2项集。
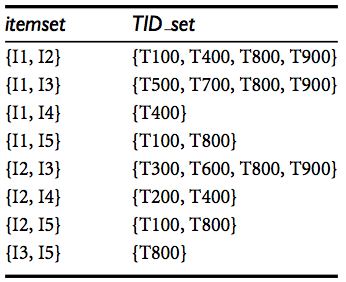
根据先验性质,一个给定的3项集是候选3项集,仅当它的每一个2项集子集都是频繁的。

通过探查垂直数据格式挖掘频繁项集的过程,首先,通过扫描一次数据集,把水平格式的数据转换成垂直格式。相机的支持度技术简单地等于项集TID集的长度。从
k=1
开始可以根据先验性质,使用频繁
k
项集来构造候选
算法优点:除了在产生候选















 7551
7551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









