







目标检测综述
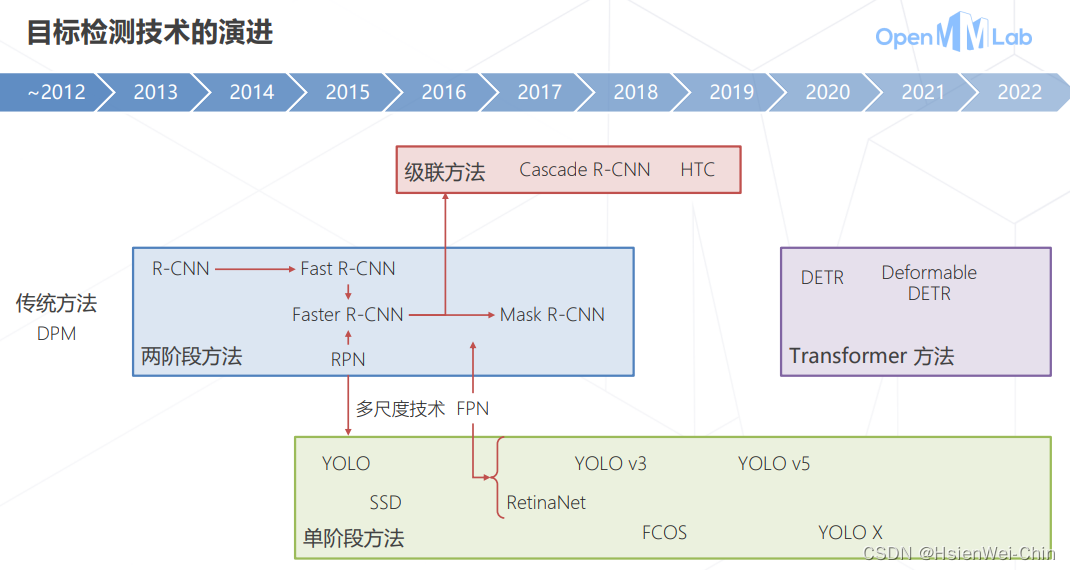
深度学习以来的目标检测演进
传统两阶段方法:R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN
多尺度技术
FPN
单阶段方法:YOLO, SSD, RetinaNet
Transformer的方法
DETR, Deformable DETR
非极大值抑制
已知:检测器产生的一系列检测框B={B1, B2, …, Bn},及相应的置信度s={s1, s2, …, sn}, IoU阈值t(通常0.7)
步骤:
- 初始化结果集R=空集
- 重复直至B为空集
1)找出B集中置信度最大的框Bi,并加入结果集R
2)从B中删除Bi以及与Bi交并比大于t的框 - 输出结果集R
特征金字塔FPN结构
问题提出:多尺度检测的必要性
图像中物体本身大小就有一定的差异;高层特征经过多次采样后位置信息会逐渐丢失,小物体检测能力较弱,定位精度较低
层次化的特征天然适用于检测不同尺寸的物体
劣势:底层特征抽象层级不够,预测物体比较困难
改进思路:高层次特征包含足够的抽象语义信息,将高层特征融入底层特征,补充底层特征的语义信息
融合方法:特征求和
单阶段的目标检测算法:
yolo是多任务的学习:回归和分类共同计入损失函数中,通过入控制权重
yolo的总损失=边界框需要产生物体预测时计算的边界框回归损失+边界框需要产生物体/背景预测时计算的置信度回归损失+边界框产生物体预测时计算的c个类别概率的回归损失
yolo的优点:快
yolo v1的缺点:每个格子预测一个物体,对大量重叠的小物体容易产生漏检;直接回归边界框有难度,回归误差较大,v2开始使用基于anchor的回归















 192
192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









