







 论文提出了一种统一的生成式框架,利用BART模型解决Aspect-based Sentiment Analysis的七个子任务,包括输入、输出和任务类型的统一处理。创新点在于将任务转化为seq2seq形式,提升了模型的灵活性和性能。实验结果显示在多个数据集上超越了现有方法。
论文提出了一种统一的生成式框架,利用BART模型解决Aspect-based Sentiment Analysis的七个子任务,包括输入、输出和任务类型的统一处理。创新点在于将任务转化为seq2seq形式,提升了模型的灵活性和性能。实验结果显示在多个数据集上超越了现有方法。
文章目录
A Unified Generative Framework for Aspect-based Sentiment Analysis
一、该论文关注的是解决ABSA问题的哪个方面?驱动是什么?具体目标是解决什么问题?
解决的方面:统一架构(联合7个子任务)
驱动:
①ABSA有7个子任务,虽然这些ABSA子任务具有很强的相关性,但现有的大多数研究只关注1 ~ 3个子任务。在一个统一的框架中解决所有子任务的困难在于:
- 输入:有些子任务(AE、OE、AESC、Pair和Triplet)只以文本语句作为输入,其余的子任务(ALSC和AOE)以文本和给定的方面词作为输入。
- 输出:有些任务(AE, OE, ALSC, AOE)只输出a, s或o的特定类型,而剩下的任务(AESC, Pair和Triplet)返回a, s和o的复合输出。
- 任务类型:有两种任务:抽取任务(提取方面和观点)和分类任务(预测情绪)。
以前的大量工作只关注这些子任务的子集。然而,在一个统一的框架中解决整个ABSA子任务是十分重要的。
②最近,有几部作品在这一轨道上进行了尝试。一些方法应用管道模型分别从内部子模型输出a, s, o。但是,模型不是端到端。【依赖于子模型】
③另一方向遵循序列标记方法,扩展标记模式。然而,候选标签的组合性阻碍了性能。【改变模型结构】
具体目标:
提出一个统一的生成框架来解决ABSA的所有子任务,能够不依赖于子模型或改变模型结构以适应所有ABSA子任务。
二、该论文采用的方法是什么,方法的核心原理是什么?
方法的提出:
如何构建一个统一的框架?
- 首先,我们将这些子任务定义为a generative task,它可以处理输入、输出和任务类型方面的障碍,并适应所有的子任务,而不需要改变任何模型结构。
- 提取和分类任务分别建模为指针索引和类索引生成。
- 基于统一的任务公式,我们使用序列到序列的预训练模型BART (Lewis et al., 2020)作为我们的骨干,在端到端过程中生成目标序列。
综上:
提出了一种统一的 生成式框架,将子任务统一称为序列生产的任务,这样任务就是seq2seq式。再使用BART等模型进行编码与生成。
核心原理:
-
架构
首先规定输入:
【只需要输入句子的】
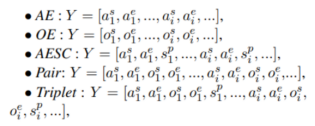
【输入句子+方面词的】
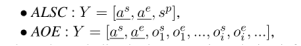
然后统一架构为下面的模型
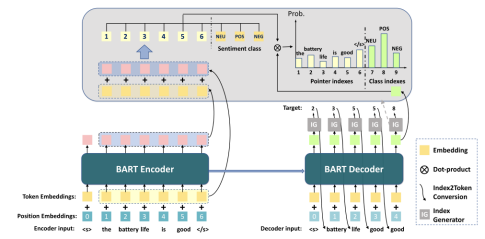
- 输入层:句首加入
<
s
>
< s >
<s> 句尾加入$ < / s > $
i n p u t e m b e d d i n g = p o s i t i o n e m b e d d i n g + t o k e n e m b e d d i n g input embedding = position embedding + token embedding inputembedding=positionembedding+tokenembedding - 编码层:首先将输入的embedding过一遍BART Encode,然后经过一个全连接层【这里就去掉句首标志 < s > <s> <s>了】,然后将输出与输入embedding残差链接,最后将向量与情感类别集合拼接。
- 解码层:
将BARTEncoder的输出+(1-t-1)时刻BARTDecoder的输出作为BARTDecoder输入,由于BARTDecoder输出的全是索引下标,所以需要用一个index2token模块去转换成token输入。 - 输出层:
将encoder最后的向量表示拼接情感类别token的embedding,与decoder输出隐向量点乘过一层softmax做分类得到输出token索引下标。
- 输入层:句首加入
<
s
>
< s >
<s> 句尾加入$ < / s > $
-
BART
BART是一个用于自然语言生成(NLG)的强序列对序列的预训练模型。BART是一种去噪自编码器,由几个变压器(V aswani et al., 2017)编码器和解码器层组成。值得注意的是,BART-Base模型包含6层编码器和6层解码器,这使得它的参数数量与BERT-Base模型相似。BART通过一些方法(如掩蔽和排列)对输入句子进行去噪。编码器以带噪声的句子作为输入,解码器以自回归的方式恢复原始句子。
三、该方法是如何提出的,是开创性的方法还是对已有方法进行的改进,创新点是什么?
参考的观点或模型:
- ①在构建出统一框架,即将任务转化为seq2seq模式后,采用BART (Lewis et al., 2020)来解决这个seq2seq问题。
创新点:
- ①将ABSA的7个子任务制定为一个统一的指标生成问题。与以往的统一模型不同,这篇论文提出的架构是不需要为不同的输出类型设计特定的解码器的,还是挺创新的。
- ②所有的ABSA子任务都可以在seq2seq的框架中解决,可以建立在预先训练的模型上,如BART。seq2seq是NLG的研究内容,也有很多已有的优秀模型了,所以实现不难。
- ③在四个公共数据集上进行了实验,每个数据集包含所有ABSA子任务的子集。据这篇论文描述,这是第一次在所有ABSA任务上评估一个模型。
四、该论文展示的结果如何?使用的是什么数据集?
使用的数据集:针对不同的baseline适用于不同的子任务,作者将baseline分为三大组实验17/19/20
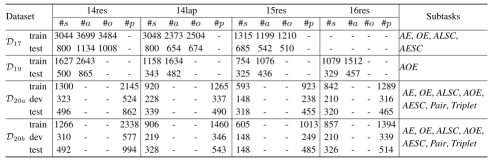
实验指标:
精确度§、召回率®和F1分数
实验结果:
- 在D17数据集上,比较了AE、OE、ALSC和AESC的方法。对比大多数结果达到了更好或可比性的结果基线。我们的结果是在BART-Base模型上获得的,几乎只有一半的参数。这说明我们的框架更适合这些ABSA子任务。
- 在D19数据集上,进行AOE比较。在14res、15res和16res上实现了显著的P/R/F1改进。此外,F1成绩在14lap接近之前的SOTA结果,这可能是由于数据集域的差异造成的。
- 在D20a数据集上,比较了AESC、Pair和Triplet的方法。对比结果能够在所有数据集上超过其他基线。具体来说,我们在三元组中取得了更好的结果,这证明了我们的方法在捕获方面术语、意见术语和情感极性之间的交互作用方面的有效性。
- 在D20b数据集(Xu et al., 2020)上,对Triplet的方法进行了比较。对比结果在14res, 15res和16res上实现了近7个F1点的改进,获得了最好的结果。与其他基线相比,我们的方法在每个数据集上的召回得分都有近13,9,7,12个点的提高。
五、该论文是否提出还有需要改进的地方,即future work?
无
六、该论文的实际应用点在于什么?
该论文的核心在于提出了一个统一了ABSA的7个子任务的框架,并转化成了一个seq2seq的任务,而seq2seq的任务也是NLG一直研究的内容,因此实现起来也是比较容易的。在整体上这个模型的表现还是挺好的,其统一ABSA的架构思想或许在一些应用中能够表现更好。
同时,其将ABSA子任务合并转换为seq2seq的思想也启示我们其他任务的框架是否能够进行类似的转换。


















 2065
2065

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









