






A Unified Generative Framework for Aspect-Based Sentiment Analysis论文速看
)
总括
ABSA旨在识别: aspect terms, their corresponding sentiment polarities, and the opinion terms。文章总结了7类ABSA的子任务,看这些子任务,我们可以观察到:input不一样,output也不一样,任务类型也不一样。所以现有的一些研究都是只做1-3个子任务的,还未有一个方法去一下子解决7类子任务。本文就是做了这样一件事!此paper把这7个subtask都变成了一个 unified generative formulation.
Introduction
ABSA是细粒度的情感分析任务,旨在识别a,s,o.( aspect terms, sentiment polarities, and the opinion terms。)
- 看例子 ,

黄色字体是aspect term ,粉色字是opinion term,情感都是positive。 - 7subtask总结
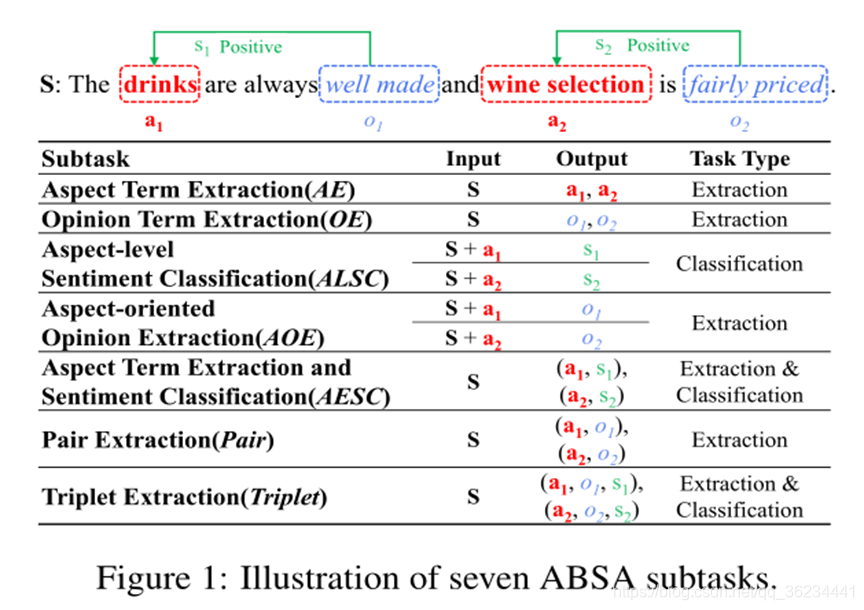
可以看到,有不同的输入输出以及任务类型。
正是这些divergences才导致make it difficult to solve all subtask in a unified framework. - recently work the existing methods can hardly solve all the subtasks by a unified framework without relying on the sub-models or changing the model structure to adapt to all ABSA subtasks。所以我们提出的统一生成框架去解决这7类任务很有必要。
- 贡献
• We formulate both the extraction task and classification task of ABSA into a unified index generation problem. Unlike previous unified models,our method needs not to design specific decoders for different output types.
• With our re-formulation, all ABSA subtasks
can be solved in sequence-to-sequence framework, which is easy-to-implement and can be built on the pre-trained models, such as BART.
• We conduct extensive experiments on four public datasets, and each dataset contains a subset of all ABSA subtasks. To the best of our knowledge, it is the first work to evaluate a model on all ABSA tasks.
• The experimental results show that our proposed ramework significantly outperforms recent SOTA methods.
Methodology
-
Task Formulation
-For example, o s, a erepresent the start index of an opinion term o and the end index of an aspect term a. We use the s p to denote the index of sentiment polarity class. The target sequence for each subtask is as follows:
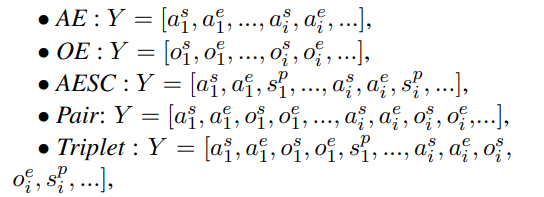
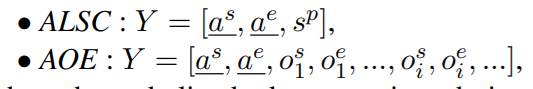

把这七类都转换成目标序列生成

-
Our model
-

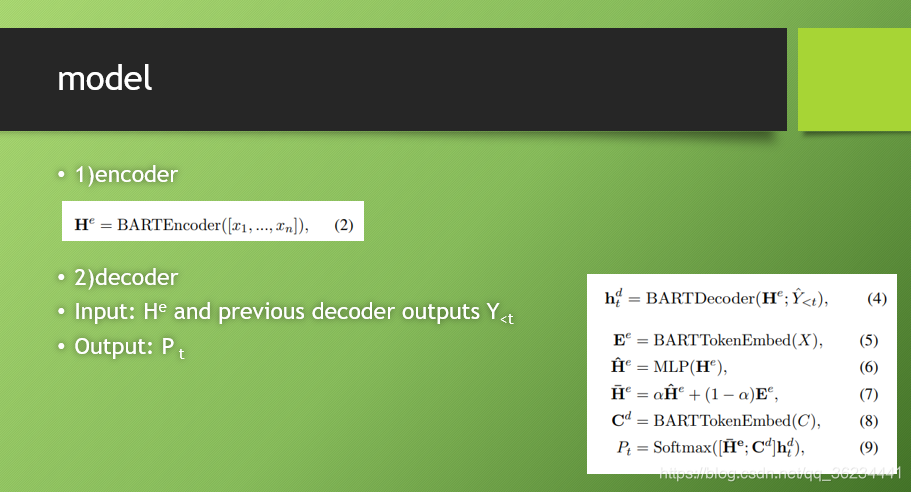
框架的整体结构,图底下有详细介绍。在训练阶段,我们使用了 teacher
forcing 来训练 model and the negative loglikelihood to optimize the model. Moreover, during the inference, we use the beam search to get
the target sequence Y in an autoregressive manner.

实验
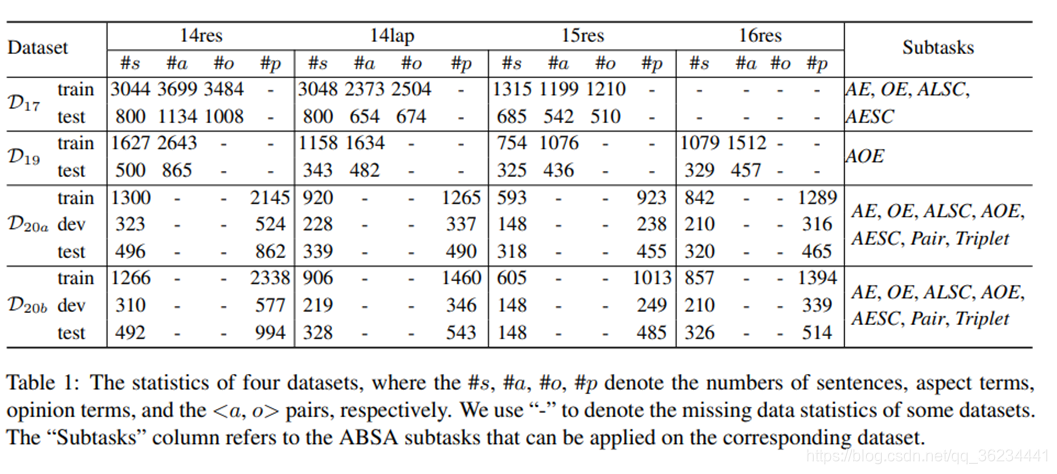
dataset
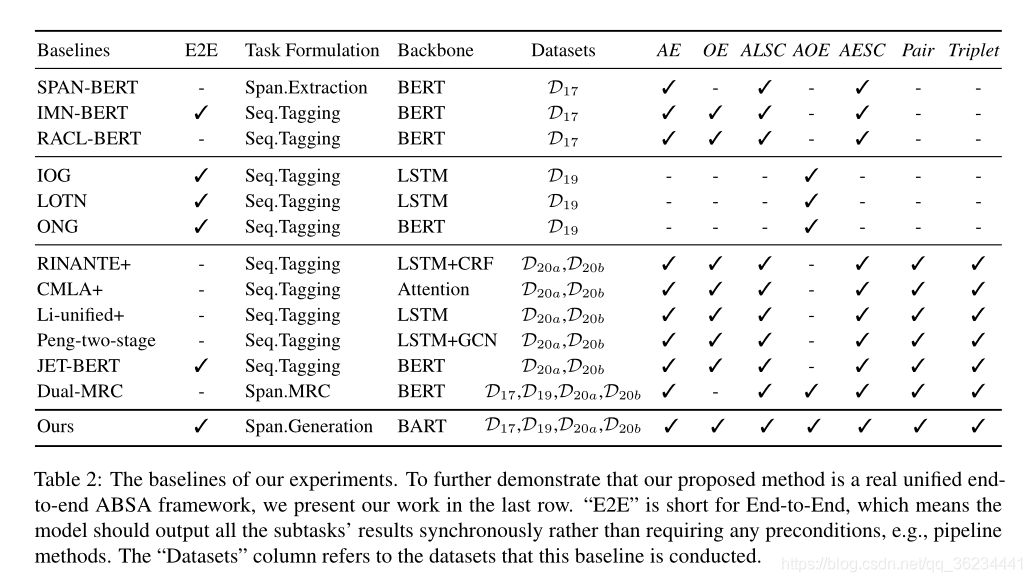
baseline
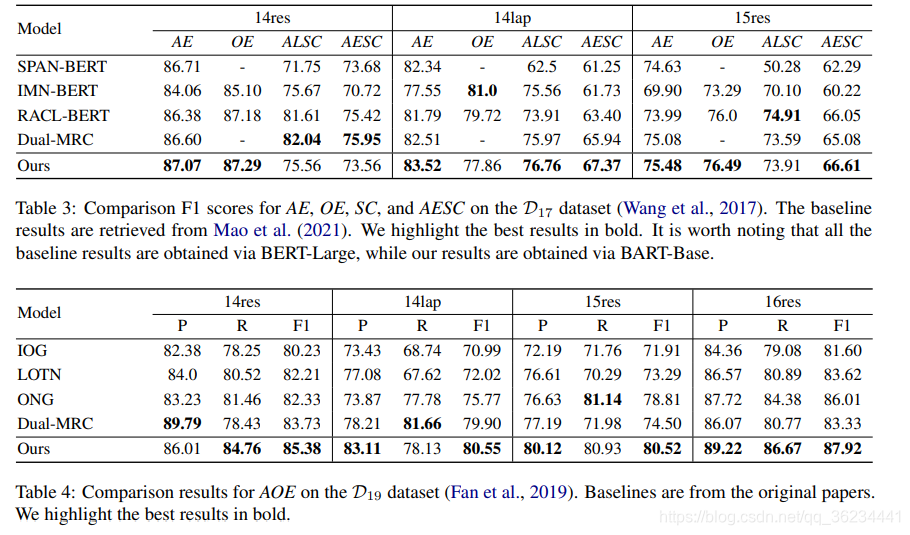
main result
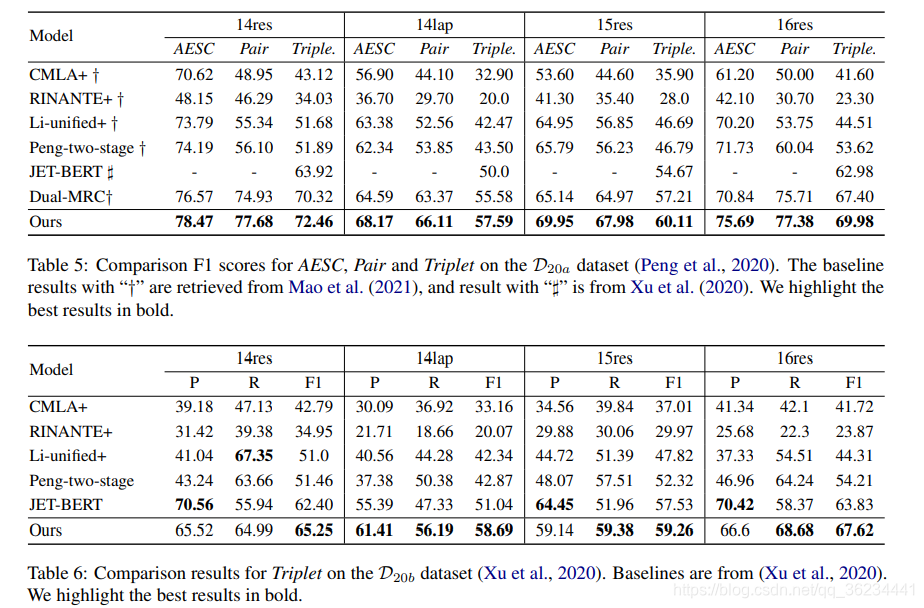
Framework Analysis
为了证明我们的生成框架能够适应ABSA生成任务,我们进行了测试,定义了三种错误“invalid token”,“invalid size”,“invalid order”

实验证实错误都很少,所以说我们这个生成框架基本上没有什么问题。
conclusion

论文不是很长,也就七八页,详细内容请看原文。(上面放的都是我之前做的PPT)本人也是第一次写博客,有不足之处请多包含。有错误也请批评指正。














 1454
1454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









