










摘要
基于方面的情感分析(ABSA)的现有工作采用了统一的方法,允许子任务之间的交互关系。然而,我们观察到这些方法倾向于根据方面和意见术语的字面意思来预测极性,并且主要考虑单词级别的子任务之间的隐含关系。此外,识别具有极性的多个方面-意见对更具挑战性。因此,全面了解上下文信息关于ABSA 进一步要求方面和意见。在本文中,我们提出了深度上下文关系感知网络(DCRAN),它允许基于两个模块(即方面和意见传播以及显式自我监督策略)具有深层上下文信息的子任务之间的交互关系。特别是,我们为 ABSA 设计了新颖的自监督策略,它在处理多个方面具有优势。实验结果表明,DCRAN 在三个广泛使用的基准测试中显着优于以前的最先进方法。
针对问题
现存方法只考虑子任务之间的词级关系,没有明确利用整个序列的上下文信息。(例如表1中的E1,评价术语“更好”似乎代表了对“日本食品”的正面评价。E1的真实含义是“我在food court吃的日本料理比我在这家餐厅吃的日本料理更美味”。因此,以前的方法倾向于根据方面和观点术语的字面意义来分配极性(E2)。)

解决方法
为了解决上述问题,我们提出了用于ABSA的深度上下文关系感知网络(Deep Contextualized relationship - aware Network, DCRAN)。DCRAN不仅隐式地允许ABSA子任务之间的交互关系,而且通过上下文信息明确地考虑它们之间的关系。
DCRAN: Deep Contextualized Relation-Aware Network
2.1 Task Definition
我们的目标是解决三个子任务: aspect term extraction (A TE), opinion term extraction (OTE), and aspect-based sentiment classification (ASC) 作为序列标记问题。{B, I, O},那种。

2.2 Task-Shared Representation Learning
在现有工作的基础上,我们利用预训练的语言模型,如BERT和ELECTRA (Clark et al., 2020)作为共享编码器来构建上下文表示,并由子任务A TE、OTE和ASC共享。
给定一个句子S = {w1, w2,…, wn},预训练的语言模型取输入序列,Xabsa= [[CLS]w1w2,…wn[SEP]],输出共享上下文表示序列,H = {h[CLS], h1, h2, …, hn, h[SEP]} ∈ Rdh×(n+2),利用单层前馈神经网络(FFNN),

【字母含义】We represent the parameters of the shared encoder as Θs
The parameters of a single-layer FFNN are represented as Θa或Θo for ATE OR OTE.
2.3 Aspect and Opinion Propagation
当在预测序列极性时,我们利用transformer-decoder考虑aspect和opinion的关系.。我们的transformer-decoder主要由一个多头自注意层、两个多头交叉注意层和一个前馈层组成。a multi-head self-attention, two multi-head cross attention, 和 a feed-forward layer.
(相关公式解释如下,不好打字)结构如下图(a)所示


2.4 Explicit Self-Supervised Strategies
为了进一步挖掘aspect–opinion的关系用句子的上下文信息,我们提出了由两个辅助任务组成的显式自我监督策略: 1) type-specific masked termdiscrimination (TSMTD) and 2) pairwise relations discrimination (PRD).

Type-Specific Masked Term Discrimination
我们mask掉aspects,和 opinions, 以及terms that do not correspond to both,输入序列被表示成Xtsmtd=[[CLS]w1…[MASK]i… wn[SEP]],然后扔给预训练语言模型,输出[CLS]用来分类哪类term被masked
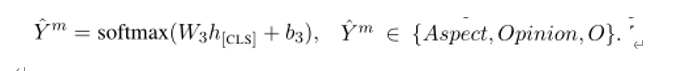
type-specific masked term discrimination NLLLoss
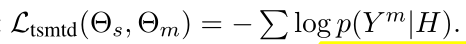
这就让model明确的利用句子信息,通过区分什么类型term被masked掉。
Pairwise Relations Discrimination
在这个任务中,我们使用特殊令牌[REL]统一替换方面和意见术语。如此一来,输入表示成Xprd= [[CLS]w1…[REL]i…[REL]j… wn[SEP]],然后通样扔进预训练语言模型中,输出的[CLS]被用来区分被替换的标记[REL]是否有成对的关系。
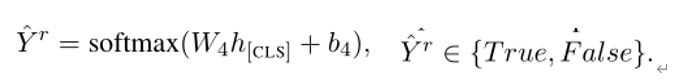
同理 pairwise relations discrimination的NLLLoss
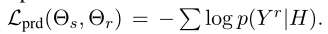
2.5 Joint Learning Procedure
联合训练都加起来
注意,参数Θs针对所有子任务进行了优化。特别是通过Ltsmtd和Lprd进一步优化的参数Θs,明确利用了aspect和opinion之间的关系(不好翻译,原句是:Especially, the parameters Θsare further optimized through Ltsmtd and Lprd to explicitly exploit the relations between aspect and opinion with context meaning.)
3 Experiments
3.1 Experimental Setup
数据集:laptop reviews (LAP14), restaurant reviews (REST14) and restaurant reviews (REST15)
设置了四个评估指标A TE-F1,OTE-F1, ASC-F1, and ABSA-F1.(只有当A TE和ASC预测都是正确的)
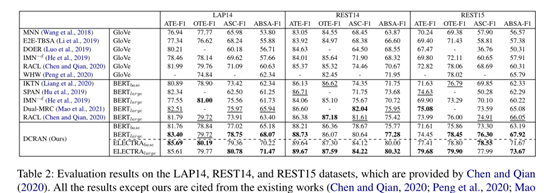
3.2 Quantitative Results
预训练语言模型我们用了两种BERT和 ELECTRA
3.3 Ablation Study
为了研究aspect propagation (AP), opinion propagation (OP), type-specific masked term discrimination (TSMTD), and pair-wise relations discrimination (PRD),的有效性,我们在REST14数据集上进行消融实验

我们观察到AP比OP更有效,当不使用AP和OP时得分显著下降。
在explicit self-supervised strategies中,PRD 比 TSMTD.更有效。
【启发】由于PRD的目标是判别替换符号是否具有成对的方面-意见关系,这使得模型可以在句子水平上更多地利用方面和意见之间的关系。
3.4 Aspect Analysis
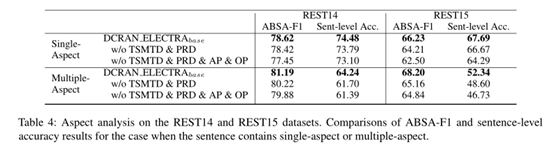
分析主要是两点(1) Aspect and Opinion Propagation使当句子包含一个方面时,性能会较大提高,而当句子包含多个方面时,性能会有小的提高。(2)Explicit Self-Supervised Strategies很有效,当句子包含多个方面时,能有效地正确识别ABSA
4 Conclusion
在本文中,我们提出了基于方面的情感分析的深度上下文化关系感知网络(DCRAN)。DCRAN允许子任务之间以一种更有效的方式隐式交互和两种显式的自我监督策略进行深度上下文和关系感知学习。我们在三个广泛使用的基准上获得了最新的研究结果。
主要贡献:
1)我们设计了aspect和opinion propagation decoder,使模型对整个上下文有全面的理解,从而更好地预测极性。2)我们提出了新的ABSA自监督策略,该策略在处理多个方面和考虑方面和观点术语的深层语境信息方面非常有效。据我们所知,这是第一次尝试为ABSA设计显式的自我监督方法。3)实验结果表明,在三个广泛使用的基准测试中,DCRAN的性能显著优于之前最先进的方法。
另2篇ACL2021的阅读笔记
Towards Generative Aspect-Based Sentiment Analysis.
A Unified Generative Framework for Aspect-Based Sentiment Analysis论文速看.
不足之处请指正多包含,谢谢~















 1139
1139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









