







llama.cpp控制参数有哪些?有什么作用?
一、大模型推理参数
1.1 LLM解码理论基础
LLM在有限的词汇表V上进行训练,该词汇表包含模型可识别和输出的所有可能标记x。一个标记可以是单词、字符或介于两者之间的任何语言单位。
LLM接收一系列标记**x** = (x_1, x_2, x_3, ..., x_n)作为输入提示,其中每个x都是_V_中的元素。
随后LLM基于输入提示输出下一个标记的概率分布P。从数学角度,这可表示为P(x_t | x_1, x_2, x_3, ..., x_t-1)。从这个分布中选择哪个标记是由我们决定的。在此过程中可以选择不同的采样策略和采样参数。
模型将尝试基于输入提示预测下一个标记。
采样本质上是一种概率选择过程。选定下一个标记将其附加到输入提示中并重复这个循环。在LLM领域,这些概率分布通常用对数概率表示,称为logprobs。
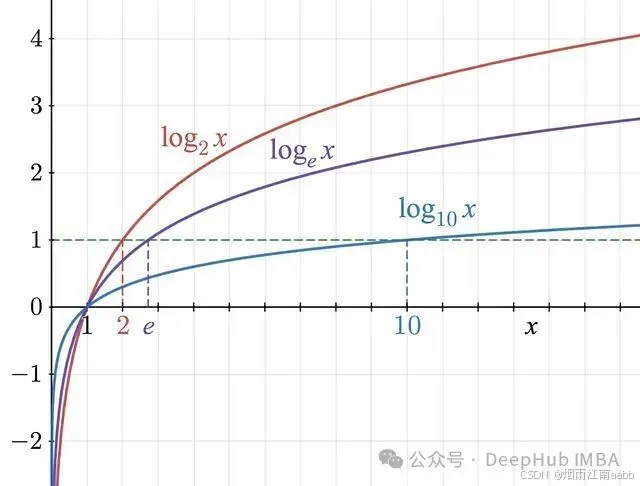
如下图所示,对数函数在0到1之间的值域内恒为负。
这就解释了为什么logprobs是负值。接近零的logprob对应极高的概率(接近100%),而绝对值较大的负logprob则表示接近0的概率。
2.2 贪婪解码策略
最基本的采样策略是贪婪解码。该方法在每一步简单地选择概率最高的标记。
贪婪解码是一种确定性采样策略,因为它不涉及任何随机性。给定相同的概率分布,模型每次都会选择相同的下一个标记。
贪婪解码的主要缺点是生成的文本往往重复性高且创意性不足。这类似于在写作时总是选择最常见的词汇和最标准的表达方式。
与确定性的贪婪解码相对的是随机解码。这种方法从分布中进行采样,以产生更具创意性的、基于概率的文本。随机解码是通常应用于LLM输出的方法。
2.3 温度参数
温度是LLM中最广为人知的参数之一。
采样温度的取值范围在0到2之间。较高的值(如0.8)会使输出更加随机,而较低的值(如0.2)会使输出更加聚焦和确定。
在LLM输出下一个标记的概率分布后,我们可以通过温度参数调整其分布形状。温度T是一个控制下一个标记概率分布尖锐度或平滑度的参数。
从数学角度看,经温度缩放后的新概率分布P_T可以通过以下公式计算。z_v是LLM为标记v输出的logprob或logit,它被温度参数T除。
温度缩放公式本质上是一个带有额外缩放参数T的softmax函数。
温度缩放的数学公式 [1]
通过加入温度参数,可以从新的概率分布P_T中采样,而不是原始概率分布P。
下图展示了对输入提示"1+1="的四种不同概率分布。在这种情况下,下一个标记应该是2。
(注意:这些并非完整分布,仅绘制了部分值)。
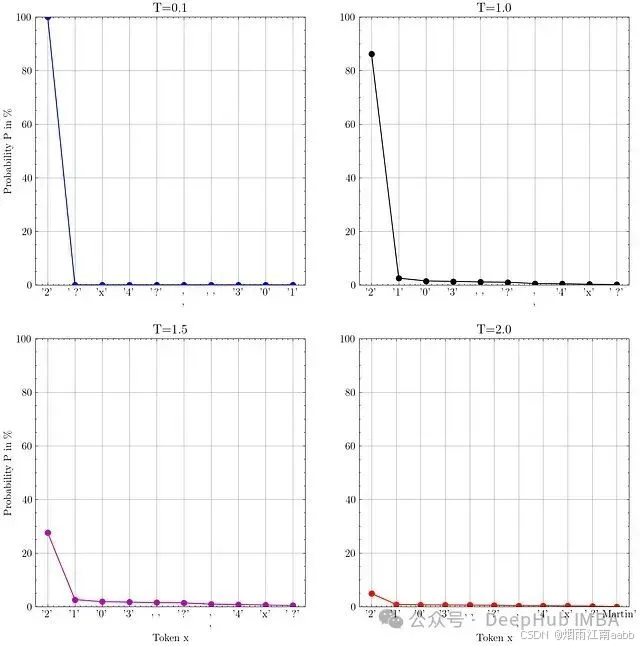
微软Phi-3.5-mini-instruct LLM对输入提示"1+1="的四种不同概率分布图,展示了不同温度T参数的效果。
可以观察到,温度T越高,分布就越趋于平坦。这里的"平坦"意味着各个结果的概率趋于均等。
值得注意的是,在默认温度T=1.0下,明显的正确答案2只有约85%的概率被选中,这意味着如果进行足够多次的采样,得到不同答案的可能性并非微乎其微。
在温度T=2.0时,尽管标记"2"仍然是最可能的选择,但其概率已降至约5%。这意味着此时采样的标记几乎完全随机。所以在实际应用中很少有理由将温度设置得如此之高。
这里我们引用OpenAI文档所述,温度是一种调节输出随机性或聚焦度的方法。由于我们只是在调整概率分布,始终存在采样到完全不相关标记的非零概率,这可能导致事实性错误或语法混乱。
2.4 Top-k采样策略
Top-k采样策略简单地选取概率最高的k个标记,忽略其余标记。
当k=1时,top-k采样等同于贪婪解码。
更准确地说,top-k采样在概率最高的前k个标记之后截断概率分布。这意味着我们将词汇表V中不属于前k个标记的所有标记的概率设为零。
将非top-k标记的概率设为零后,需要对剩余的分布进行重新归一化,使其总和为1:
重新归一化概率分布的公式 [2]
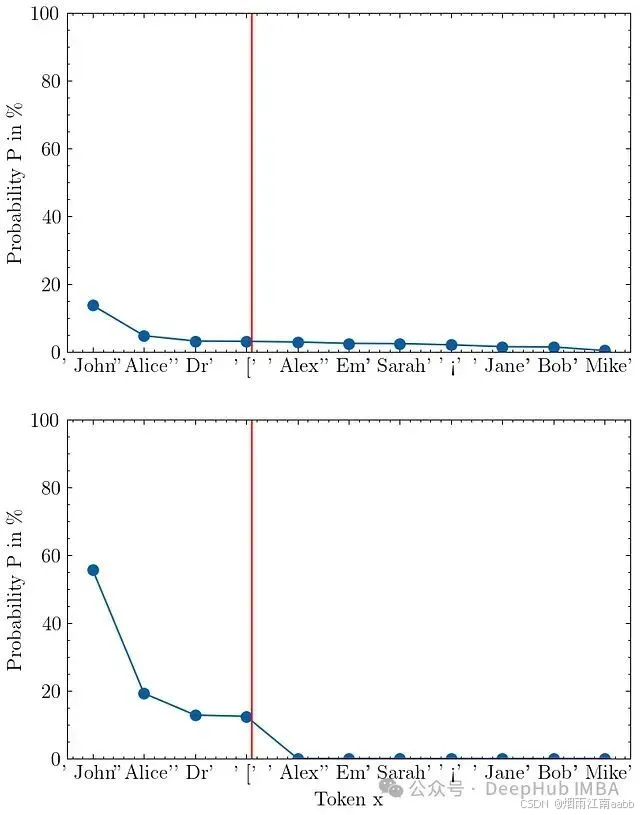
输入提示"My name is"的top-k采样可视化,k=4。上图显示模型的原始输出概率,下图展示top-k截断和重新归一化后的概率分布。
上图展示了模型的原始输出分布。红线将图分为左侧的top-k标记和右侧的其余部分。下图显示了截断和重新归一化后的新top-k分布P_K。
需要注意的是,top-k采样目前不是OpenAI API的标准参数,但在其他API中,如Anthropic的API,确实提供了top_k参数。
Top-k采样的一个主要问题是如何设置参数k。对于非常尖锐的分布,我们倾向于使用较小的k值,以避免在截断的词汇表中包含大量低概率标记。而对于较为平坦的分布,我们可能需要较大的k值,这样可以包含更多合理的标记可能性。实际使用的样本选择为0~100.
2.5 Top-p采样策略
Top-p采样,也称为核采样,是另一种通过从词汇表中剔除低概率标记来截断概率分布的随机解码方法。
我们还是引用OpenAI对top_p参数给出的定义:
这是一种替代温度采样的方法,称为核采样,模型考虑累积概率达到top_p的标记集合。例如,0.1意味着只考虑累积概率达到前10%的标记。
随后对截断后的概率分布进行重新归一化,使其总和为1。
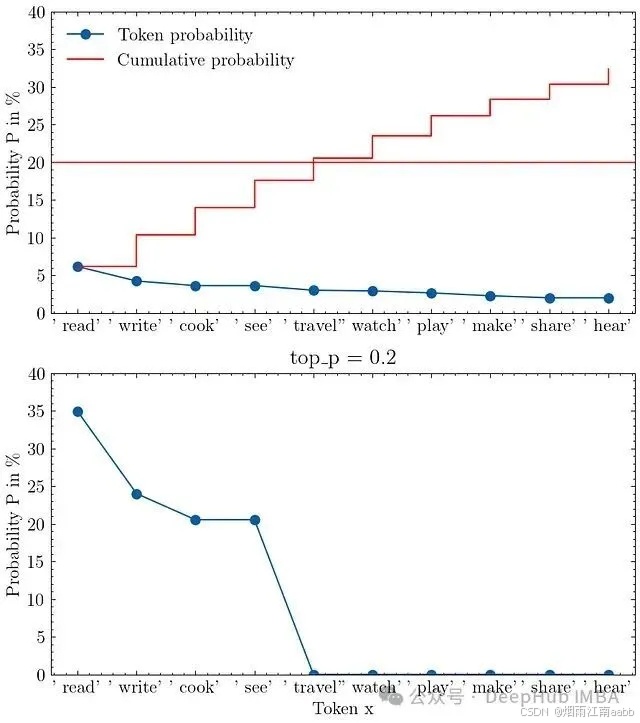
输入提示"I love to"的top-p采样可视化,top_p=0.2。上图显示模型的原始输出概率,下图展示top-p截断和重新归一化后的概率分布。
上图展示了模型的原始输出分布,其中红线标记了20%的累积概率阈值,将图分为下方的top-p标记和上方的其余部分。重新归一化后,下图显示我们只保留了四个标记,其余标记的概率被置为零。
从理论角度来看,从logprobs的长尾分布中剔除极低概率的标记通常是合理的。因此top_p参数通常应设置为小于1.0的值。
但是top-p采样也并非完美无缺。下图展示了一个案例,其中top-p采样为了达到累积概率阈值而包含了大量低概率标记,这可能导致不理想的结果。
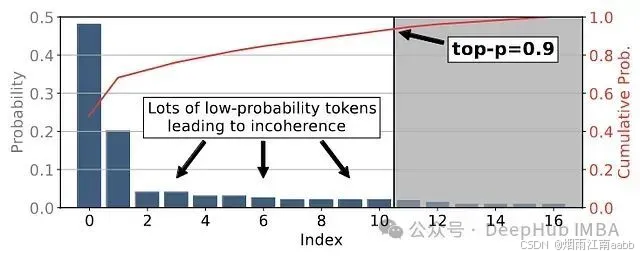
Top-p采样可能包含过多低概率标记的示例。
2.6 结合Top-p和温度的策略
尽管OpenAI的官方文档中没有明确说明,但根据社区的测试结果,似乎top_p参数在温度参数之前应用。
一般情况下通常不建议同时设置top_p和温度参数,但在某些场景下,这种组合可能会带来优势。
仅调整温度参数会使概率分布变得更加平坦或尖锐。这会使输出要么更加确定(低温度),要么更具创意性(高温度)。但是模型仍然是从概率分布中随机采样。所以会始终存在采样到高度不可能标记的风险。
例如,模型可能会采样到外语字符或罕见的Unicode字符。理论上模型词汇表中的任何内容(现在通常非常庞大且多语言)都有可能被采样到。
作为一种解决方案,可以首先应用top-p采样来剔除这些极端情况,然后通过较高的温度从剩余的合理标记池中进行创造性采样。这种方法可以在保持输出多样性的同时,有效控制输出质量。
2.7 Min-p采样策略
最近一种新的采样方法被提出,称为min-p采样,源自论文"Min P Sampling: Balancing Creativity and Coherence at High Temperature"[1]。
Min-p同样是一种基于截断的随机解码方法,它试图通过引入动态阈值p来解决top-p采样的某些局限性。
计算min-p采样动态最小阈值的数学公式 [1]
Min-p采样的工作原理如下:
-
首先从概率分布中找出最大概率
p_max,即排名最高的标记的概率。 -
将这个最大概率乘以一个参数
p_base,得到一个最小阈值p_scaled。 -
采样所有概率大于或等于
p_scaled的标记。 -
最后,对截断后的概率进行重新归一化,得到新的概率分布
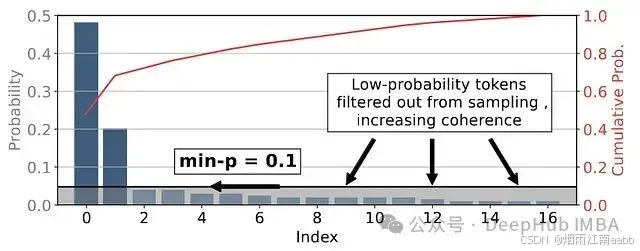
Min-p采样使用相对最小概率的示意图。(图片来源:[1])
Min-p采样已在一些后端实现,如VLLM和llama.cpp。下图展示了min-p采样的可视化结果,其中p_base = 0.1,输入提示为"I love to read a"。
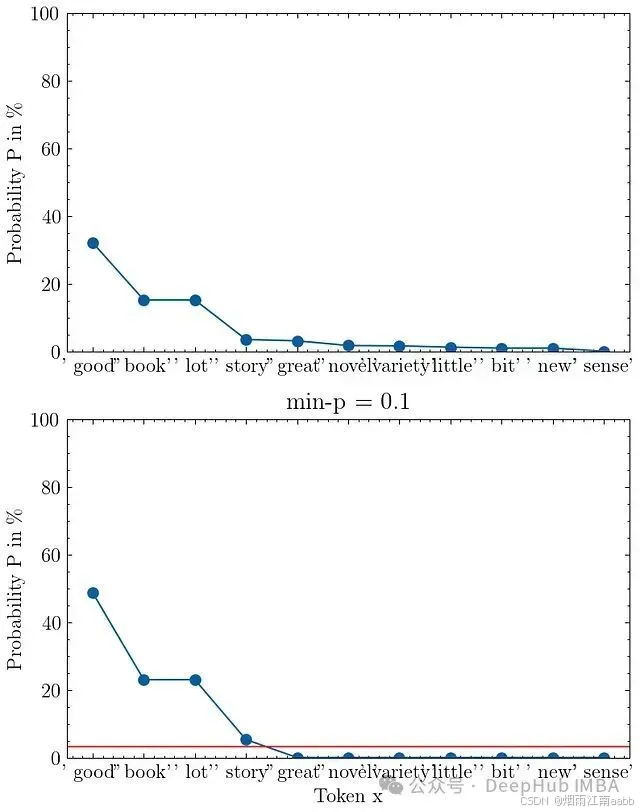
输入提示"I love to read a"的min-p采样可视化,p_base=0.1。上图显示模型的原始输出概率,下图展示min-p截断和重新归一化后的概率分布。
在这个例子中标记"good"的概率为32%。设置p_base = 0.1后,我们得到最小概率阈值p_scaled = 3.2%,即图中的红线位置。
2.8 总结与建议
通过深入理解采样参数的作用机制,我们可以更有针对性地为特定的LLM应用场景优化参数设置。
最关键的参数是温度和top_p。
温度参数调节模型输出概率分布的形状。需要注意的是,无论如何调整,总是存在采样到语义或语法上不合适标记的可能性。在给定概率分布的情况下,我们仍在进行概率性采样。
top_k参数通过截断概率分布来限制可能的候选标记集。但这种方法也存在风险:可能会过度剔除有价值的候选项,或者保留过多不适当的选项。
如果使用的LLM框架支持min-p采样,建议进行实验性尝试,评估其在特定任务中的表现。
在实际应用中,建议采取以下步骤:
-
首先尝试调整温度参数,观察其对输出质量的影响。
-
如果单纯调整温度无法达到理想效果,考虑引入top_p或top_k参数。
-
对不同参数组合进行系统性测试,找出最适合您特定任务的配置。
-
持续关注新的采样策略研究,如min-p采样,并在条件允许时进行评估。
通过精细调整这些参数,可以在保持输出多样性和创造性的同时,显著提高大语言模型生成内容的质量和相关性。
二、控制参数解析
2.2 llama_cli控制参数
以下对 llama_cli的控制参数进行解析。
| 参数 | 取值 | 含义 | 备注 |
| -h/--help | 获取帮助信息 | ||
| --version | 输出版本信息 | 不需要参数 | |
| --verbose-prompt | 打印详细提问信息 | 在生成之前打印详细提问 | |
| --no-display-prompt | 不打印提问信息 | 在生成之前不打印详细提问 | |
| -co/--color | true/false | 是否进行着色 | 对输出进行着色以区分各代的提示和用户输入 |
| -t/--threads | 整型 | 生成期间使用的线程数 | 一般设置为4.也可以根据CPU核心数设置。默认值-1. |
| -tb/--threads-batch | 整型 | 批处理和提示处理期间使用的线程数 | 批处理和提示处理期间使用的线程数(默认值:与 --threads 相同) |
| -td/-threads-draft | 整型 | 生成期间使用的线程数 | 生成期间使用的线程数(默认值:与 --threads 相同) |
| -tbd/--threads-batch-draft | 整型 | 批处理和提示处理期间使用的线程数 | 批处理和提示处理期间使用的线程数(默认值:与 --threads-draft 相同) |
| -C/--cpu-mask | true/false数组 | CPU 亲和性掩码:任意长的十六进制。补充 cpu 范围(默认值:“”) | |
| -Cr/--cpu-range | [<start>]-[<end>] | 取值范围 | 用于亲和力的 CPU 范围。补充 --cpu-mask |
| --cpu-strict | <0|1> | 使用严格的 CPU 布局(默认值:%u) | |
| -c/--ctx-size | 整型 | 提示上下文的大小 | 提示上下文的大小(默认值:%d,0 = 从模型加载)。一般为2048 |
| -n/--predict/--n-predict | 整型 | 要预测的标记数量 | 要预测的标记数量(默认值:-1,-1 = 无穷大,-2 = 直到上下文填充) |
| -b/--batch-size | 整型 | 逻辑最大批处理量大小 | 逻辑最大批处理量大小(默认值:2048) |
| -ub/--ubatch-size | 整型 | 物理最大批量大小 | 物理最大批量大小(默认值:512) |
| --keep | 整型 | 初始提问中保留的令牌数量 | 初始提问中保留的令牌数量(默认值:0,-1 = 全部) |
| --no-context-shift | true/false | 禁用无限文本生成时的上下文转换 | 禁用无限文本生成时的上下文转换(默认值:true) |
| --chunks | 整型 | 要处理的最大块数 | 要处理的最大块数(-1 = 无限制) |
| -fa/--flash-attn | true/false | 启用 Flash关注 | 启用 Flash关注(默认值:false) |
| -f/--file | 字符串型 | 包含提问的文件路径 | 包含提问的文件(默认值:无) |
| --in-file | 字符串型 | 提问文件路径 | 输入文件(重复指定多个文件) |
| -bf/--binary-file | 字符串型 | 包含提示的二进制文件路径 | 包含提示的二进制文件(默认值:无) |
| -e/--escape | true/false | 处理转义字符 | 处理转义序列 (\n, \r, \t, \', \", \\)。默认值:true |
| --no-escape | 不处理转义字符 | 有此参数的话,不处理转义字符 | |
| -ptc/--print-token-count | 整型 | 每 N 个令牌打印令牌计数 | 每 N 个令牌打印令牌计数(默认值:-1 禁用打印) |
| -cnv/--conversation | true/false | 是否以对话模式运行 | 以对话模式运行:\n" “- 不打印特殊标记和后缀/前缀\n” “- 交互模式也已启用\n” “(默认值:false) |
| -i/--interactive | true/false | 以交互模式运行 | 以交互模式运行(默认:false) |
| -mli/--multiline-input | true/false | 允许您写入或粘贴多行 | 允许您写入或粘贴多行,而无需以“\\”结尾”。默认值:false |
| --in-prefix-bos | true/fals | 在用户输入中添加 BOS 前缀 | 在用户输入中添加 BOS 前缀,位于“--in-prefix”字符串之前。 |
| --in-prefix | 字符串 | 用于为用户输入添加前缀的字符串 | 用于为用户输入添加前缀的字符串(默认值:空) |
| --in-suffix | 字符串 | 用户输入后的字符串后缀(默认:空) | |
| --no-warmup | true/false | 不预热模型 | 跳过空运行来预热模型 |
| --spm-infill | true/false | 使用后缀/前缀/中间模式进行填充 | 使用后缀/前缀/中间模式进行填充(而不是前缀/后缀/中间),因为某些模型更喜欢这样做。 (默认值:false) |
| --samplers | 采样器类型 | 将用于按顺序生成的采样器,以“;”分隔(默认值:%s) | |
| -p/--prompt | 字符串 | 提问内容 | 用户提问内容 |
| --temp N | 浮点型 0~N | 调整生成文本的随机性(默认值:0.8) | 温度是一个超参数,用于控制生成文本的随机性。它影响模型输出令牌的概率分布。较高的温度(例如1.5)使输出更具随机性和创造性,而较低的温度(如0.5)使输出更有针对性、确定性和保守性。默认值为0.8,它在随机性和确定性之间提供了平衡。在极端情况下,0的温度总是会选择最有可能的下一个令牌,从而在每次运行中产生相同的输出。 |
| --repeat-penalty | 1.0~N | 控制生成的文本中令牌序列的重复(默认值:1.0,1.0=禁用)。 | 默认是1.0,禁用重复输出。“重复惩罚”选项有助于防止模型生成重复或单调的文本。较高的值(例如1.5)将更严厉地惩罚重复,而较低的值(如0.9)将更宽容。默认值为1。 |
| --repeat-last-n N | 整型 -1 0~N | 最后n个用于惩罚重复的令牌(默认值:64,0=禁用,-1=ctx大小)。 | “repeat-last-n”选项控制历史中要考虑惩罚重复的令牌数量。较大的值将在生成的文本中向后看,以防止重复,而较小的值将只考虑最近的令牌。值0禁用惩罚,值-1设置被认为等于上下文大小的令牌数量(“ctx大小”) |
| --penalize-nl | 无 | 在应用重复惩罚时允许对换行符的惩罚。默认是false:禁用。 | 默认的取值是false。 将换行符视为可重复的标记。设置此参数则为true。 |
| --top-k N | 整型 0~N | 将下一个令牌选择限制为K个最可能的令牌(默认值:40)。 | Top-k采样是一种文本生成方法,仅从模型预测的前k个最可能的令牌中选择下一个令牌。它有助于降低生成低概率或无意义代币的风险,但也可能限制输出的多样性。top-k的较高值(例如100)将考虑更多的标记,并导致更多样化的文本,而较低的值(例如10)将关注最可能的标记并生成更保守的文本。默认值为40。 |
| --top-p N | 浮点型 0~1.0f | 将下一个令牌选择限制为累积概率高于阈值P(默认值:0.9)的令牌子集。 | Top-p采样,也称为核采样,是另一种文本生成方法,它从累积概率至少为p的令牌子集中选择下一个令牌。这种方法通过考虑令牌的概率和要采样的令牌数量,在多样性和质量之间实现了平衡。top-p的值越高(例如0.95)将导致文本更加多样化,而值越低(例如0.5)将产生更集中和保守的文本。默认值为0.9。 |
参考文献:
1.《优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略》

















 6780
6780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









