









1.论文和代码
- 论文链接:1703.05175.pdf
- 代码1
- 代码2
2.简介
小样本学习不仅仅训练和测试集的样本没有交集,类别也是没有交集的
论文一共做了两个任务:1.小样本;2. 零样本。
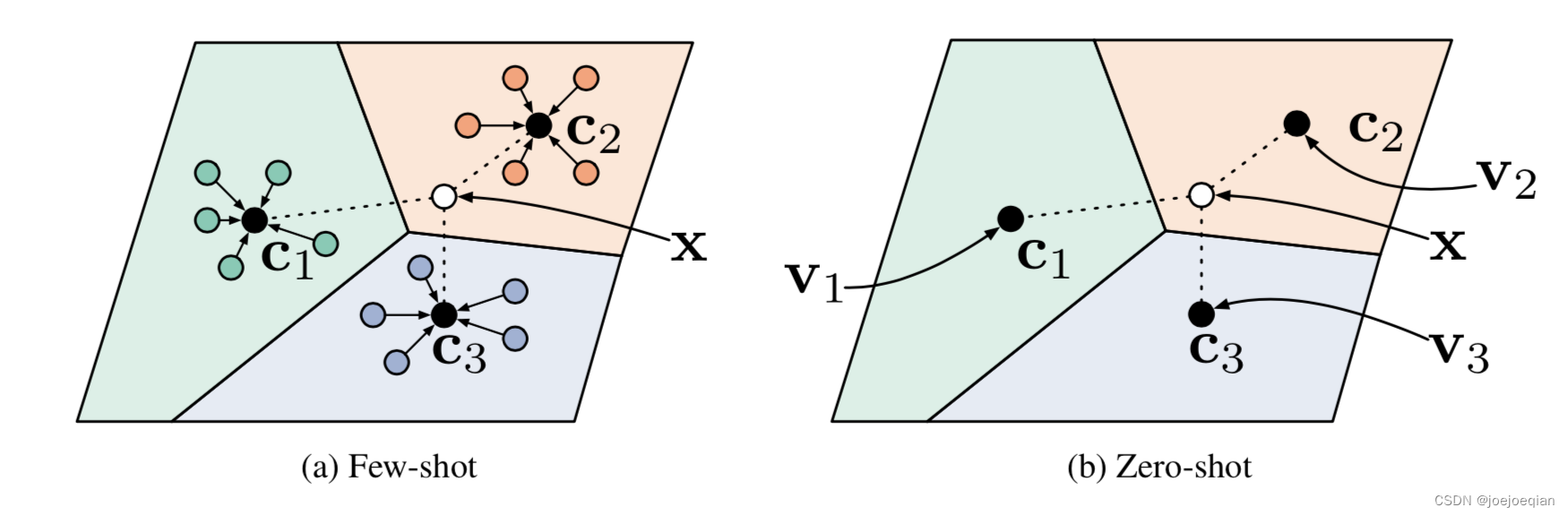
如图左边:
三种颜色代表三个类别(3-way),
c
1
,
c
2
,
c
3
c_1,c_2,c_3
c1,c2,c3分别是三个类别的中心,用类中心表示类别的好处就是某个类别中某些数据存在一些噪声,用类中心来表示这个特征,比较robust,类中心对抗噪声的能力比单个样本生存的这个特征要强很多。
类中心(prototypes)用各类别下所有样本特征的平均值来计算的:
v
c
=
1
∣
S
c
∣
∑
(
x
i
,
y
i
)
∈
S
c
f
θ
(
x
i
)
v_c=\frac{1}{|S_c|}\sum_{(x_i,y_i)\in S_c} f_{\theta}(x_i)
vc=∣Sc∣1(xi,yi)∈Sc∑fθ(xi)
X
X
X为是Query set,要确定它的类别,判断它的类别需要它分别计算与
c
1
,
c
2
,
c
3
c_1,c_2,c_3
c1,c2,c3之间的距离,哪一个距离越小,与哪个类别的相似度就越大,就归为哪一类。
基于度量的元学习,度量类别与类别之间的距离的一些指标(欧式距离或者余弦距离等)。
3.算法流程

3.1 名词解释及符号定义
- episode:表示一个N-way K-shot任务,N为类别数,K为每个类别的数量。 N C N_C NC为每个任务中类别的数量, N S + N Q N_S+N_Q NS+NQ每个类别样本的数量。这里就是 N C N_C NC-way N S N_S NS-shot N Q N_Q NQ-query任务。
- support set:有 N C N_C NC个类别,每个类别包含 N S N_S NS个样本。
- query set:有 N C N_C NC个类别,每个类别包含 N S N_S NS个样本。
- RANDOMSAMPLE(S,N)函数:从集合S上随机抽取N个元素。伪代码中的 R A N D O M S A M P L E ( { 1 , 2 , ⋯ , K } , N C ) RANDOMSAMPLE(\{1,2,\cdots,K\},N_C) RANDOMSAMPLE({1,2,⋯,K},NC)也就是从总类别为K的数据集中随机抽取 N C N_C NC个类别的数据,比如在MiniImageNet数据集上进行 R A N D O M S A M P L E ( I m a g e N e t , 2 ) RANDOMSAMPLE(ImageNet ,2) RANDOMSAMPLE(ImageNet,2),可能就抽到了1000个类别为“猫”的图片和1000个类别为“狗”的图片。
3.2 具体流程
- 1.从一个大的数据集上随机采样一个 N C N_C NC-way K-shot任务,为一个episode。
- 2.将episode中的样本分为support set和query set(和support set没有重合),并且使用均值计算各类的prototypes,也就是 c k c_k ck。
- 3.对于 N C N_C NC个类别,利用每个类别中的query set中的样本计算损失函数。
- 重复抽取不同的episode,循环1、2、3.
3.3 损失函数
- 损失函数更新的规则: J ← J + 1 N C N Q [ d ( f ϕ ( x ) , c k ) + log ∑ k ′ exp ( − d ( f ϕ ( x ) , c k ) ) ] J \leftarrow J+\frac{1}{N_C N_Q}\left[d(f_{\phi}(x), c_k)+\log\sum_{k'}\exp(-d(f_{\phi}(x), c_k))\right] J←J+NCNQ1[d(fϕ(x),ck)+logk′∑exp(−d(fϕ(x),ck))],这是一个Softmax交叉熵损失函数。
Tips:
Softmax函数:是常用的激活函数,将一个向量映射成一个概率分布,形式: y k = e a k ∑ i = 1 n e a i y_{k}=\frac{e^{a_{k}}}{\sum_{i=1}^{n} e^{a_{i}}} yk=∑i=1neaieak。
输入任意k维向量: Φ = [ ϕ 1 , ϕ 2 , ⋯ , ϕ k ] ∈ R k \Phi=[\phi_1,\phi_2,\cdots,\phi_k]\in \mathbb{R}^k Φ=[ϕ1,ϕ2,⋯,ϕk]∈Rk,对向量的每个值进行指数变换,得到 k k k个大于0的数,然后对结果做归一化,让得到的k个数相加等于1: p = n o r m a l i z e ( [ e ϕ 1 , ⋯ , e ϕ k ] ) ∈ R k → p = S o f t m a x ( Φ ) p=normalize([e^{\phi_1},\cdots,e^{\phi_k}])\in \mathbb{R}^k\rightarrow p=Softmax(\Phi) p=normalize([eϕ1,⋯,eϕk])∈Rk→p=Softmax(Φ)
性质:
1. p i > 0 , i = 1 , ⋯ , k . p_i>0,i=1,\cdots,k. pi>0,i=1,⋯,k.
2. ∑ i = 1 k p i = 1 \sum_{i=1}^k p_i = 1 ∑i=1kpi=1
3.输出层
4.让大的输入值变大,小的变小,而又不像Max那么暴力
交叉熵损失:将Softmax计算所得概率与理想向量求交叉熵
一般来说理想向量为one-hot向量,即仅在第 y y y个位置为1,其余为0,所以最终只保留了第$ y$ 个位置的交叉熵。此时的Softmax 交叉熵损失函数表示为: l o s s S o f t m a x = − log p y loss_{Softmax}=-\log p_y lossSoftmax=−logpy,此时梯度为: ∂ l o s s ∂ z i = { p y ( 1 − p y ) , y = i − p y p j , y ≠ i \frac{\partial loss}{\partial z_i}=\begin{cases}p_y(1-p_y),& y=i\\ -p_yp_j,&y \neq i\end{cases} ∂zi∂loss={py(1−py),−pypj,y=iy=i
详细推导见:1.Softmax函数与交叉熵;2.# softmax交叉熵损失函数深入理解
- 损失函数的推导:
- 根据下面两个公式:
- S o f t m a x : p ϕ ( y = k ∣ x ) = exp ( − d ( f ϕ ( x ) , c k ) ) ∑ k ′ exp ( − d ( f ϕ ( x ) , c k ′ ) ) Softmax:p_{\phi}(y=k|x)=\frac{\exp(-d(f_{\phi}(x),c_k))}{\sum_{k'}\exp(-d(f_{\phi}(x),c_{k'}))} Softmax:pϕ(y=k∣x)=∑k′exp(−d(fϕ(x),ck′))exp(−d(fϕ(x),ck))
- J ( ϕ ) = − log p ϕ ( y = k ∣ x ) J(\phi)=-\log p_{\phi}(y=k|x) J(ϕ)=−logpϕ(y=k∣x)
- 将 p ϕ ( y = k ∣ x ) p_{\phi}(y=k|x) pϕ(y=k∣x)代入 J ( ϕ ) J(\phi) J(ϕ)即可得: J ← J + 1 N C N Q [ d ( f ϕ ( x ) , c k ) + log ∑ k ′ exp ( − d ( f ϕ ( x ) , c k ) ) ] J \leftarrow J+\frac{1}{N_C N_Q}\left[d(f_{\phi}(x), c_k)+\log\sum_{k'}\exp(-d(f_{\phi}(x), c_k))\right] J←J+NCNQ1[d(fϕ(x),ck)+logk′∑exp(−d(fϕ(x),ck))]
- 根据下面两个公式:
4.与 Match Networks 的区别
不同点如下:
-
- 举例度量方式不一样:前者采用布雷格曼散度的欧几里得距离,后者采用 cosine 余弦相似度度量距离。
- 2.二者在 few-shot 的场景下不同,但在 one-shot 时变得一样
-
- 网络结构上,原型网络将编码层和分类层合并为一层,这样参数更少,鲁棒性更好。
5.实验结果
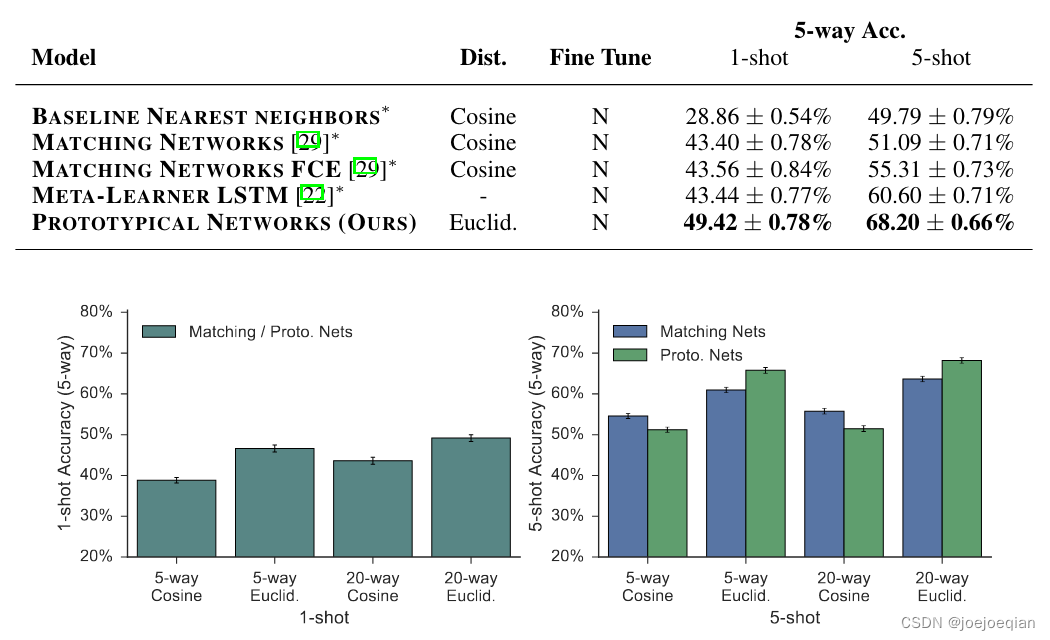
实际上,用 consine 效果更好。















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









