







前言

论文地址:https://openreview.net/forum?id=Wj4ODo0uyCF
代码地址:https://github.com/bzhangGo/zero/blob/iclr2021_clsr
前人工作&存在问题
早期的研究关注于增加模型share(迁移、transfer)的能力:
- 做法
- 在one2many translation中共享encoder
- 在many2one translation中共享decoder
- 在many2many translation中共享sub layers
- 使用一个target language token来让单个模型完成many2many translation
- 缺点
- 使用单个language token没有充分提现语种的多样性(language diversity)
目前的研究探究share和不share之间的平衡(trade-off)
- 做法:
- 使神经注意力专门化
- 拓宽(broaden) encoder的输出以及正则化
- 解耦encoder或decoder
- 使用固定的LS(language specific)和shared参数
- 插入轻量级的适配器(adapter)
- 为语种聚类,并单独建模
- 缺点
- 以上工作都依赖于启发式,只能看到下游任务上的性能确实上升了,而不能直接分析模型容量到底是如何分配的
本文贡献
本文借助CLSP(conditional language-specific routing)来让模型学习到基于数据的LS分配。在此基础上,提出了LSScore用于评估不同参数的LS程度,并借此回答了LS的数量、位置对性能的影响;语种对模型参数LS分配的影响。
具体模型
整个模型由公式1-6给出。
训练:
- 公式3:具体来说,对于一个token对应的hidden state z l z_l zl,首先通过公式3得到一个0-1的门控开关系数(其中, G ( z l ) G(z_l) G(zl)是一个实数,再加上一个 α ( t ) N ( 0 , 1 ) α(t)N(0,1) α(t)N(0,1)。该项中的 α ( t ) α(t) α(t)随着训练时间而增大,也就是说,一开始,基本就是一个 s i g m o i d ( G ( z l ) ) sigmoid(G(z_l)) sigmoid(G(zl))来控制开关,使得模型参数主要去学习如何开关让性能最优;后期,随着 α ( t ) α(t) α(t)的增大, G ( z l ) G(z_l) G(zl)必须要给出更加明确的答案,才能经得住高斯噪声的扰动,从而使得模型拥有产生硬输出的能力,个人理解:一方面可以方便测试时的离散化选择,且和训练时类似,尽可能不影响结果;另一方面可以缩小搜索空间,即,就是share or not share的选择)。
- 公式2:得到门控开关分数之后,再把 z l z_l zl经过模型的映射,再分别经过 W l a n g W_{lang} Wlang和 W s h a r e d W_{shared} Wshared的映射,分别得到两种隐藏状态: h l a n g h_{lang} hlang和 h s h a r e d h_{shared} hshared。最后用门控开关分数进行加权求和(share or not share的选择)。
推理:
- 公式4:推理阶段的 g ( ) g() g()退化成了一个狄拉克函数,即,只要G的结果>=0,那么代表着g的结果=1,也就代表着该token所对应的参数选择完全是LS的。
模型优化:
- 公式5:除了NMT的loss,对于一个batch而言,还加上了一个限制项,使得模型拟合到:所有门控开关系数的和(理解为LS的程度)占总搜索空间的比例p。带来的一个好处就是可以通过p的调试,粗略地改变模型的LS程度;另外,宽泛的限制模型在一个batch的所有token上的LS程度,能让不同的层角色分明
模型某一层的LS程度评估:
- 公式6:g上面带一弯表示模型该层,在测试集的所有token上的分数之和(分数要么是0要么是1) 除以 token的个数,理解为在限制项取p时,模型该层的LS程度。然后遍历所有的p,取平均。最后减去输入的参数p。






具体实验
实验采用两个数据集:
- OPUS-100,语言对很多
- WMT-14,语言对很少,数据更加不均衡
shared 和 language-specific中间存在平衡点吗?
存在!如图1所示,对于O2M p=0.3,对于M2O p=0.1,最好。
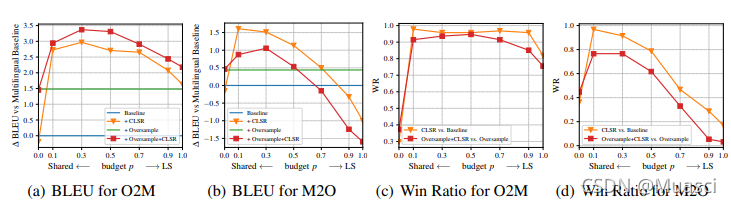
在什么情形下,language-specific是重要的?
还是如图1所示,结论如下:
- 在O2M的情形下,模型需要更强的LS(M2O的情形下,不同的语言对很容易进行迁移);
- 在不平衡、低资源的设置下,LS能带来更高的收益;
在模型的哪些位置,language-specific是重要的?
如图2所示,结论如下:
- 不管是encoder还是decoder,不管是什么类型的层,模型的top、bottom位置更加LS。
- 对于O2M,不管是encoder还是decoder,feedforward更加LS;而对于M2O,decoder部分的CAN更加LS,encoder部分不同的层趋势差不多。
- 总的来说,不管是O2M还是M2O,不管是encoder还是decoder,都有LS的部分存在。但是,M端更为LS(比如:O2M的decoder端、M2O的encoder端),O端LS程度更差(比如:O2M的encoder端、M2O的decoder端)。

模型某一层的LS和不同的语种是否有关系?
其实和上面的分析不矛盾,举个例子说,某一层经过上面的实验,总体是LS的。但也有可能对于不同语种的token,有不同的LS程度。事实是不是这样呢?
如图3所示,x轴是不同的语种,y轴是不同的层,结论如下:
- 同一层,对于不同语种的LS基本相同。
- 不同层之间的LS关系和图2一致。

总体的翻译性能&能否利用上述结论强硬地增加NMT的性能?
如图4所示,利用上述的结论,可以产生两种模型变体:
- 对top\bottom进行LS
- 对LSscore高的层进行LS

以上实验都是在OPUS上,在WMT-14上呢?
如图5所示,方法在WMT-14上的性能提升相对较小,可能的原因是WMT-14的语言对更少,LS的效果没有得到很好的发挥。

心得总结
- 目前的趋势是language transfer、language diversity我全都要。
- 不管是O2M还是M2O,还是结合起来的M2M,encoder和decoder端都需要LS的,我之前的偏见都是对于encoder端,share就代表着transfer,所以share就完事了,事实证明我是错误的。另外M端的LS程度一般都会更大。
- 模型对于LS分配是模型本身和?决定的,而与语种无关。
- 这种方法不能做M2M。















 1037
1037











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









