









# 数据结构与算法绪论


逻辑结构




物理结构





谈谈算法









算法时间复杂度

















就是告诉你要注重看最高阶次,然后常数和阶次的常数乘积忽略掉,注意数据要足够多。

执行次数就是时间























算法空间复杂度



线性表





抽象数据类型










void unionL(List* La, List* Lb)//此伪代码是来依次将Lb中与La不同的数据插入到La的后面
{
int La_len, Lb_len, i;
ElemType e;
La_len = ListLength(*La);
Lb_len = ListLength(*Lb);
for (int i=1;i<=Lb_len;i++)//这里写成一因为只是数据结构算法重点是过算法流程,而不是让编译器看懂
{
GetElem(Lb, i, &e);
if (!Locate(*La,e))
{
ListInsert(La, ++La_len, e);
}
}
}
线性表的顺序存储结构



地址计算方法


这里应该是O(1),而不是0(1)。
获得元素操作


typedef int Status;
Status GetElem(Sqlist L,int i,ElemType *e)
{
if (L.length == 0 || i<i || i>L.length)//线性表从1开始
{
return ERROR;
}
*e = L.data[i - 1];
return OK;
}
插入操作



Status ListInsert(Sqlist *L, int i, ElemType e)
{
int k;
if (L->length == MAXSIZE)//顺序表已经满了
{
return ERROR;
}
if (i<1 || i>L->length + 1)//i不在范围内
{
return ERROR;
}
if (i <= L->length)
{
for (k = L.length - 1; k >= i - 1; k--)
{
L->data[k + 1] = L->data[k];//元素后移
}
}
L->data[i - 1] = e;
L->length++;
return OK;
}
删除操作

//删除
//输出L的第i个元素,并用e来返回删除的值。
Status ListDelete(Sqlist* L, int i, ElemType e)
{
if (L - length == 0)
{
return ERROR;
}
if (i<1 || i>L->length )//i不在范围内
{
return ERROR;
}
e = L->data[i - 1];
if (i <= L->length)
{
for (k = i; k < L->length; k++)
{
L->data[k - 1] = L - data[k];
}
}
L->length--;
return e;
}

线性表顺序存储结构的优缺点


线性表的链式储存结构






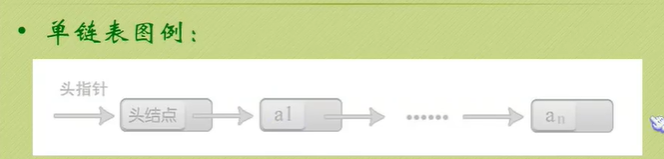

可以看到空指针指向头节点。
头节点后面的节点才是真正存放数据的。



单链表读取

//获取
Satus GetElem(LinkList *L, int i, ElemType* e)
{
int j;
LinkList p;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i)//跳出循环的时候,正常情况下应该是i==j
{
p = p->next;
++j;
}
if (p! || j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
*e = p->data;
return OK;
}

单链表插入




//单链表插入
//在L中第i个位置之后插入新的元素e,L的长度加1
Status ListInsert(LinkList* L, int i, ElemType* e)
{
int j;
LinkList* p;
LinkList* s;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i)//跳出循环的时候,正常情况下应该是i==j
{
p = p->next;
++j;
}
if (p!|| j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
s = (LinkList)malloc(sizeof(Node));//分配一个内存空间给新的节点S
s->data = *e;
//下面两句千万不能写反,前面ptt有讲这个后果。
s->next = p->next;
p->next = s;
return OK;
}



//单链表删除
//删除第i个Node 并把里面的data返回
Status ListDelete(LinkList* L, int i, ElemType* e)
{
int j;
LinkList* p;
LinkList* q;
p = L->next;//p指向第一个节点
j = 1;
while (p && j < i-1)//跳出循环的时候、
{
p = p->next;
++j;
}
if (p!|| j > i)//如果p指向空或者你想要查找的根本不存在
{
return ERROR;
}
q = p->next;//q指向第i个节点
p -> next = q -> next;
*e = q->data;
delete q;
return OK;
}
效率PK


可以看到单链表在插入删除多个数据的时候优势明显大于顺序存储结构。
单链表的整表创建


头插法建立单链表



在这里插入代码片
//单链表头插
void CreateListHead(LinkList* L, int n)
{
LinkList p;
int i;
srand(time(0));//初始化随机数种子
*L = (LinkList)malloc(sizeof(Node));
(*L)->next = NULL;
for (int i = 0; i < n; i++)
{
p = (LinkList)malloc(sizeof(Node));//生成新节点
p->data = rand() % 100 + 1;
p->next = (*L)->next;
(*L)->next = p;
}
}
//这里面为什么 *L 另一个则是p ,说明L是二级指针,函数传进来的是*L,我们直接认为*L是指向链表的指针就行了
//这个代码是头插,但是表头*L还是在最前面。
代码流程图

尾插法建立单链表



//单链表尾插
void CreateListTail(LinkList* L, int n)
{
LinkList p,r;
int i;
srand(time(0));//初始化随机数种子
*L = (LinkList)malloc(sizeof(Node));
r = *L;
for (int i = 0; i < n; i++)
{
p = (Node *)malloc(sizeof(Node));//生成新节点
p->data = rand() % 100 + 1;
r->next = p;
r = p;
}
r->next = NULL;
}
代码流程

单链表的整表删除

//单链表整表删除
Status ClearList(LinkList* L)
{
LinkList p, q;
p = (*L)->next;//p指向第一个节点
while (p)
{
q = p->next;
free(p);
p = q;
}
(*L)->next = NULL;
return OK;
}

单链表结构和顺序存储结构的优缺点


对于查找来说,顺序存储结构有下标,一下就找到了。单链表要一个一个找,因为下一个节点的地址要从上一个节点的next来找寻。
插入删除就很明显了,因为顺序存储结构要对其他元素移位,而单链表只需移动指针指向。



回顾




静态链表







游标指向下一个下标


就是第一个space的游标指向空闲space的下标。
也就是最开始第一个space里面的游标是5,也就是下标为5的space是空闲,之后再让第一个space的游标变成6.
最后一个非空闲space用的游标用0表示


静态链表的插入操作
首先获得空闲元素的下标

//在静态链表L中的第i个元素之前插入新的元素e
//这里面代码理解难一点,结合下面的图比较好理解
Status ListInsert(StaticLinkList L.int i,ElemType e)
{
int j, k, l;
k = MAX_SIZE - 1;//最后一个元素,最后一个元素的游标是第1个元素的的下标
if (i<1 || i>ListLength(L)+1)//i超出正常范围
{
return ERROR;
}
j = Mlloc_SLL(L);//获得空闲元素的下标
if(j)
{
L[j].data = e;
for (l=1;l<=i-1;l++)
{
k = L[k].cur;
}
L[j].cur = L[k].cur;
L[k].cur = j;
return OK;
}
return ERROR;
}
代码流程
以 i=2 为例




静态链表的删除操作



//删除L中的第i个元素
Status ListDelete(StaticLinkList L.int i)
{
int j, k;
if (i<1 || i>ListLength(L) + 1)//i超出正常范围
{
return ERROR;
}
k = MAXSIZE - 1;
for (j = 1; j <= i - 1; j++)
{
k = L[k].cur;//k1 =1.k2=5
}
j = L[k].cur;//j=2
L[k].cur = L[j].cur;//L[5].cur=3
Free_SLL(L.j);//这里是把备用空闲元素连接起来
return OK;
}
//将下标为k的空闲节点会受到备用链表
void Free_SLL(StaticLinkList space,int k)
{
space[k].cur = space[0].cur;
space[0].cur = k;
}
//返回L中元素个数
int ListLength(StaticLinkList L)
{
int j = 0;
int i = L[MAXSIZE - 1].cur;
while (i)
{
i = L[i].cur;
j++
}
rturn j;
}
代码流程





静态链表的优缺点

单链表小结 腾讯面试题


//腾讯面试题,找到中间节点
Status GetMidNode(LinkList L.ElemType* e)
{
LinkList search, mid;
search = mid = L;
while (search->next!=NULL)
{
if (search->next->next != NULL)
{
search = search->next->next;
mid = mid->next;
}
else
{
search = search->next;
}
}
*e = mid->data;
return OK;
}

循环链表




//循环链表
#include<iostream>
namespace xunhuanLinkList
{
#include<stdio.h>
#include<stdlib.h>
#include<iostream>
using namespace std;
typedef struct cLinkList
{
int data;
struct cLinkList * next;
}node;
/*
*插入节点
* 参数:链表的第一个节点,插入的位置
*/
void ds_insert(node **pNode,int i)
{
node *temp;
node* target;
node* p;
int item;
int j = 1;
cout<<"输入要插入的节点的值"<<endl;
cin >> item;
if (i == 1)
{//新插入的节点作为第一个节点
temp= (node*)malloc(sizeof(struct cLinkList));
if (!temp)
{
exit(0);
}
temp->data = item;
//寻找最后一个节点
for (target = (*pNode); target->next != (*pNode); target = target->next)
;
temp ->next = (*pNode);
target->next = temp;
*pNode = temp;//第一个节点变为temp
}
else
{
target = *pNode;
for (; j < (i - 1); ++j)
{
target = target->next;
}
//target指向第i-1个元素
temp = (node*)malloc(sizeof(struct cLinkList));
if (!temp)
{
exit(0);
}
temp->data = item;
p = target ->next;//指向原来的第i个元素
target->next = temp;//第i-1个元素的next指向新的第i个元素
temp->next = p;//新的第i个元素指向原来的第i个元素
}
}
/*
* 删除节点
* 参数:链表的第一个节点,删除的位置
*/
void ds_delete(node** pNode, int i)
{
node* temp;
node* target;
int j = 1;
if (i == 1)
{//删除第一个节点
//寻找最后一个节点
for (target = (*pNode); target->next != (*pNode); target = target->next)
;
temp = *pNode;
*pNode = (*pNode)->next;
target->next = *pNode;
free(temp);
}
else
{
target = *pNode;
for (; j < (i - 1); ++j)
{
target = target->next;
}
temp = target->next;//
target->next = temp->next;
free(temp);
}
}
/*
* search 返回该节点值所在的位置
* 参数:链表的第一个节点,返回的链表的值
*/
int ds_search(node* pNode, int elem)
{
node* target;
int i = 1;
for (target = pNode; target->data != elem && target->next != pNode; ++i)
{
target = target->next;
}
if (target->next != pNode)//感觉有问题,因为target->next == pNode的时候 也可以target->data == elem
//if(target->data == elem)
{
return i;//表中不存在该元素
}
else if(target->next == pNode &&target->data==elem)
{
return i;
}
else
{
return 0;
}
}
/*
* 遍历
* 参数:链表的第一个节点
*/
void ds_traverse(node *pNode)
{
node* temp;
temp = pNode;
cout<<""<<endl;
do
{
cout<<temp->data<<endl;
} while ((temp = temp->next) != pNode);
cout<<endl;
}
/*
* //初始化链表
* 参数:链表的第一个节点
*/
void ds_init(node **pNode)
{
int item;
node *temp;
node* target;
cout<<"输入节点的值,输入0完成初始化"<<endl;
while (1)
{
cin >> item;
fflush(stdin);//清楚缓冲区
if (item == 0)
{
return ;
}
if ((*pNode) == NULL)
{//循环链表里面只有一个节点
//这代码里面没有什么头节点,头节点就是第一个节点,里面一样存放着值
*pNode = (node*)malloc(sizeof(struct cLinkList));
if (!(*pNode))//*pNode为空就退出
exit(0);
(*pNode)->data = item;
(*pNode)->next = *pNode;
}
else
{
//寻找最后一个节点
for (target = (*pNode); target->next != (*pNode); target = target->next)
;
temp = (node*)malloc(sizeof(struct cLinkList));
//生成一个新的节点
if (!item)
exit(0);
temp->data = item;
temp->next = *pNode;
target->next = temp;
}
}
}
void test()
{
node* pHead = NULL;
char opp;
int find;
int search;
cout<< "1.初始化链表"<<endl;
cout << "2.插入节点" << endl;
cout << "3.删除节点" << endl;
cout << "4.返回节点位置" << endl;
cout << "5.遍历节点" << endl;
cout << "0.退出" << endl;
cout << "请选择您的操作" << endl;
while (opp!='0')
{
cin >> opp;
switch (opp)
{
case '1':
ds_init(&pHead);//
cout<<endl;
ds_traverse(pHead);
break;
case '2':
cout<<"请输入要插在哪个位置(第几个节点):"<<endl;
cin>>find;
ds_insert(&pHead,find);//
cout<<endl;
ds_traverse(pHead);
break;
case '3':
cout<<"请输入要删除的位置(第几个节点):"<<endl;
cin>>find;
ds_delete(&pHead,find);//
cout<<endl;
ds_traverse(pHead);
break;
case '4':
cout<<"请输入要要查询的值:"<<endl;
cin>>find;
search=ds_search(pHead,find);
cout<<"查询到"<<find<<"的位置在第"<<search<<"个节点"<<endl;
cout<<endl;
ds_traverse(pHead);
break;
case '5':
ds_traverse(pHead);
break;
case '0':
exit(0);
}
}
}
}
int main()
{
xunhuanLinkList::test();
}
约瑟夫问题



#include <iostream>
//约瑟夫问题
namespace josephus
{
#include<stdlib.h>
#include<stdio.h>
#include <iostream>
using namespace std;
typedef struct node
{
int data;
struct node *next;
}node;
node* creat(int n)
{
node* p = NULL, * head;
head = (node*)malloc(sizeof(node));
p = head;
node* s;
int i = 1;
if (0 != n)
{
while (i<=n)
{
s= (node*)malloc(sizeof(node));
s->data = i++;
p->next = s;
p = s;
}
s->next = head->next;//s->next就是第一个节点
}
free(head);//释放头节点不需要
return s->next;
}
void test()
{
int n = 41;
int m = 3;
int i;
node* p = creat(n);
node* temp;
m %= n;
while (p!=p->next)
{
for (i = 1; i < m - 1; i++)
{
p = p->next;
}
cout<<p->next->data<<"->";
temp = p->next;
p->next = temp->next;
free(temp);
p = p->next;
}
cout << p->data << endl;
}
}
int main(int argc, char** argv)
{
josephus::test();
return 0;
}
循环链表的特点





判断链表是否有环




两种方法的代码实现




整体代码—还未完成
#include<stdio.h>
#include<stdlib.h>
#include <time.h>
#include<iostream>
using namespace std;
typedef struct Node
{
int data;
struct Node * next;
}Node;
typedef struct Node *LinkList;//意思就是用LinkList定义出来的是指针
//单链表头插无环
void CreateListHead(LinkList * L, int n)
{
LinkList p;
int i;
srand(time(0));//初始化随机数种子
*L = (LinkList)malloc(sizeof( Node));
(*L)->next = NULL;
for (int i = 0; i < n; i++)
{
p = (Node *)malloc(sizeof(Node));//生成新节点
p->data = rand() % 100 + 1;
p->next = L->next;
(*L)->next = p;
}
}
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
魔术师发牌






代码如下:
#include <iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
static int CardNumber=13;
typedef struct Node
{
int data;
struct Node * next;
}sqlist,*LinkList;
typedef struct Node *LinkList;//意思就是用LinkList定义出来的是指针
/**
* 循环链表的生成
*/
LinkList CreatLinkList()
{
LinkList head=NULL;
LinkList s ,r;
int i;
r=head;
for(int i=0;i<CardNumber;i++)
{
s=(LinkList) malloc(sizeof (sqlist));
s->data=0;
if(head==NULL)
head=s;
else
r->next=s;
r=s;
}
r->next=head;
return head;
}
/**
* 销毁工作
*/
void DestoryList(LinkList *List)
{
LinkList ptr=*List;
LinkList buff[CardNumber];
int i=0;
while (i<CardNumber)
{
buff[i++]=ptr;
ptr=ptr->next;
}
for(i=0;i<CardNumber;i++)
{
free(buff[i]);
}
*List=0;
}
/**
* 发牌顺序计算
* @return
*/
void Magician(LinkList head)
{
LinkList p;
int j;
int Countnumber=2;
p=head;
p->data=1;
while (1)
{
for(j=0;j<Countnumber;j++)
{
p=p->next;
if(p->data!=0)//该位置有牌的话,则下一个位置
{
p->next;//p=p->next;??
j--;
}
}
if(p->data==0)
{
p->data=Countnumber;
Countnumber++;
if(Countnumber==14)
break;;
}
}
}
int main() {
LinkList p;
int i;
p=CreatLinkList();
Magician(p);
cout<<"按如下顺序排列:"<<endl;
for(i=0;i<CardNumber;i++)
{
cout<<"黑桃"<<p->data;
p=p->next;
}
DestoryList(&p);
return 0;
}
拉丁方阵问题–作业



其实就是按照环的顺序打印出来.
代码如下。我把发牌和拉丁方阵放在一个文件里实现的。
#include <iostream>
#include<stdio.h>
#include<stdlib.h>
using namespace std;
static int CardNumber=13;
typedef struct Node
{
int data;
struct Node * next;
}sqlist,*LinkList;
typedef struct Node *LinkList;//意思就是用LinkList定义出来的是指针
/**
* 循环链表的生成
*/
LinkList CreatLinkList(int n)
{
LinkList head=NULL;
LinkList s ,r;
int i;
r=head;
for(int i=0;i<n;i++)
{
s=(LinkList) malloc(sizeof (sqlist));
s->data=0;//默认都是0
if(head==NULL)
head=s;
else
r->next=s;
r=s;
}
r->next=head;
return head;
}
/**
* 销毁工作
*/
void DestoryList(LinkList *List)
{
LinkList ptr=*List;
LinkList buff[CardNumber];
int i=0;
while (i<CardNumber)
{
buff[i++]=ptr;
ptr=ptr->next;
}
for(i=0;i<CardNumber;i++)
{
free(buff[i]);
}
*List=0;
}
/**
* 发牌顺序计算
* @return
*/
void Magician(LinkList head)
{
LinkList p;
int j;
int Countnumber=2;
p=head;
p->data=1;
while (1)
{
for(j=0;j<Countnumber;j++)
{
p=p->next;
if(p->data!=0)//该位置有牌的话,则下一个位置
{
p->next;//p=p->next;??
j--;
}
}
if(p->data==0)
{
p->data=Countnumber;
Countnumber++;
if(Countnumber==14)
break;;
}
}
}
/**
* 发牌问题test
*/
void Magician_Problem()
{
LinkList p;
int i,n;
//这是发牌的解决
p=CreatLinkList(CardNumber);
Magician(p);
cout<<"按如下顺序排列:"<<endl;
for(i=0;i<CardNumber;i++)
{
cout<<"黑桃"<<p->data;
p=p->next;
}
cout<<endl;
cout<<endl;
//DestoryList(&p);
}
/**
* 拉丁方阵问题
* 就是用循环链表来实现
* 比如3x3的拉丁方阵,第一行从第一个节点输出,第二行从第二个节点输出,第三行vong第三个节点输出。每行输出3个数据。
* @return
*/
void LatinMatrix(LinkList head,int n)
{
LinkList p;
p=head;
int j,i=1;
for(j=0;j<n;j++,i++)
{
if(p->data==0)
{
p->data=i;
}
p=p->next;//指向
}
p=head;
//输出
/* debug 看看链表是不是按照我们想的那样
for(int k=0;k<n;k++)
{
cout<<p->data<<" ";
p=p->next;
}*/
int count=0;
for(int k=0;k<n;k++)
{
for(int l=0;l<n;l++)
{
cout<<p->data;
p=p->next;
}
p=head;
count++;
for(int m=0;m<count;m++)
{
p=p->next;
}
cout<<endl;
}
}
/**
* 拉丁矩阵问题test
* @return
*/
void LatinMatrix_Problem()
{
LinkList p;
int n;
cout<<"请输入拉丁方阵的维数:"<<endl;
cin>>n;
p=CreatLinkList(n);
LatinMatrix(p,n);
cout<<endl;
//DestoryList(&p);
}
int main() {
int choice=1;
while(choice)
{
cout<<"选择发牌问题请输入1"<<endl;
cout<<"选择拉丁矩阵问题请输入2"<<endl;
cout<<"退出请输入0"<<endl;
cin>>choice;
switch (choice) {
case 1 :
Magician_Problem();
break;
case 2 :
LatinMatrix_Problem();
break;
case 0 :
exit(0);
break;
}
}
return 0;
}
双向链表




双向链表的插入


双向链表的删除



双线循环链表实践



#include <iostream>
#include <stdio.h>
#include <stdlib.h>
using namespace std;
typedef char ElemType;
typedef int Status;
#define ERROR 0;
#define OK 1;
typedef struct DualNode
{
ElemType data;
struct DualNode *prior;//前驱节点
struct DualNode *next;//后驱节点
}DualNode ,*DuLinkList;
/**
* 初始化链表
* *L代表指针 那么L则是指向指针的指针?
*/
Status InitList(DuLinkList *L)
{
DualNode*p,*q;
int i;
*L=(DuLinkList) malloc(sizeof (DualNode));
if(!(*L))
{
return ERROR;
}
(*L)->next=(*L)->prior=NULL;
p=(*L);//现在是头节点 不给它赋值
for(i=0;i<26;i++)
{
q=(DuLinkList) malloc(sizeof (DualNode));
if(!q)
{
return ERROR;
}
q->data='A'+i;
q->prior=p;
q->next=p->next;//这里指向啥也没有
p->next=q;
p=q;
}
p->next=(*L)->next;
(*L)->next->prior=p;
return OK;
}
void Caesar(DuLinkList *L,int i)
{
if(i>0)
{
do
{
(*L)=(*L)->next;
}while(--i);
}
if(i<0)//这里值得思考 源码这一块有问题 我改了一下
{
(*L)=(*L)->next;
do
{
(*L)=(*L)->prior;
}while(i++);
}
}
int main() {
DuLinkList L;
int i,n;
InitList(&L);//传入指针L的地址,函数的参数是*L,那么在函数内部*L就是指向链表的指针了
cout<<"请输入整数n:"<<endl;
cin>>n;
cout<<endl;
Caesar(&L,n);
for( i=0;i<26;i++)
{
L=L->next;
cout<<L->data;
}
cout<<endl;
return 0;
}
Vingenre加密–作业

代码如下,我把Vigenere和字母表排序的问题放在一起了。
#include <iostream>
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <vector>
using namespace std;
typedef char ElemType;
typedef int Status;
#define ERROR 0;
#define OK 1;
typedef struct DualNode
{
ElemType data;
struct DualNode *prior;//前驱节点
struct DualNode *next;//后驱节点
}DualNode ,*DuLinkList;
/**
* 初始化链表
* *L代表指针 那么L则是指向指针的指针?
* 包含头节点 头节点没有值
*/
Status InitList(DuLinkList *L)
{
DualNode*p,*q;
int i;
*L=(DuLinkList) malloc(sizeof (DualNode));
if(!(*L))
{
return ERROR;
}
(*L)->next=(*L)->prior=NULL;
p=(*L);//现在是头节点 不给它赋值
for(i=0;i<26;i++)
{
q=(DuLinkList) malloc(sizeof (DualNode));
if(!q)
{
return ERROR;
}
q->data='A'+i;
q->prior=p;
q->next=p->next;//这里指向啥也没有
p->next=q;
p=q;
}
p->next=(*L)->next;
(*L)->next->prior=p;
return OK;
}
/**
* 字母表问题的解法
* @param L
* @param i
*/
void Caesar(DuLinkList *L,int i)
{
if(i>0)
{
do
{
(*L)=(*L)->next;
}while(--i);
}
if(i<0)
{
(*L)=(*L)->next;
do
{
(*L)=(*L)->prior;
}while(i++);
}
}
/**
* 字母表按指定位置输出
* @return
*/
void alpha_cout()
{
DuLinkList L;
int i,n;
InitList(&L);//传入指针L的地址,函数的参数是*L,那么在函数内部*L就是指向链表的指针了
cout<<"请输入整数n:"<<endl;
cin>>n;
cout<<endl;
Caesar(&L,n);
for( i=0;i<26;i++)
{
L=L->next;
cout<<L->data;
}
cout<<endl;
}
//密匙和密文
struct mmWen
{
int mishi;//密匙
char miwen='0';//密文
};
/**
* Vingenre加密问题解法
* 会对每个字母随机生成一个数(令这个数在0-49这个范围内)
* 然后把每个字母的密匙和铭文都保存在每一个字母对应mmWen数据结构里
* @return
*/
void Vingenre()
{
vector<mmWen> mmWem_;//存放A-Z对应的密文和密匙
DuLinkList L,p;
InitList(&L);//传入指针L的地址,函数的参数是*L,那么在函数内部*L就是指向链表的指针了
//明文如下
//debug一下 看看输出是不是想要的26个字母
cout<<"明文和对应的密匙如下"<<endl;
for(int i=0;i<26;i++)
{
L=L->next;
cout<<L->data<<" ";
}
p=L->next;p指向字母A的节点
cout<<endl;
srand((int)time(NULL));
for(int i = 0; i < 26;i++ )
{
int j= rand()%9;
cout <<j << " ";
mmWen t;
t.mishi=j;
mmWem_.push_back(t);//保存密匙
}
cout<<endl;
/* //debug 用来测试密匙有没有存入到对应的struct里面
for(auto a:mmWem_)
{
cout<<a.mishi<<" ";
}*/
//直接把密文和密匙放在容器里
for(int i=0;i<26;i++)
{
//int m=(p->data)-'A';//明文对应的序号
int n=i+mmWem_[i].mishi;//得到密匙对应字母序号
for(int j=0;j<n;j++)//找到密文对应的节点
{
p=p->next;
}
mmWem_[i].miwen=p->data;
p=L->next;//p重新指向字母A
}
for(auto a:mmWem_)
{
cout<<"密文:"<<a.miwen<<" "<<"密匙:"<<a.mishi;
cout<<endl;
}
char c;
cout<<"按0退出!!!"<<endl;
cout<<"输入明文:"<<endl;
while(1)
{
cin>>c;
if(c=='0')
{
break;
}
else
{
int m=c-'A';//明文对应的序号
for(int i=0;i<m;i++)//找到明文的位置
{
p=p->next;
}
cout<<"明文"<<p->data<<" "<<"密文:"<<mmWem_[m].miwen<<" "<<"密匙:"<<mmWem_[m].mishi;
p=L->next;
}
cout<<endl;
cout<<endl;
cout<<"按0退出!!!"<<endl;
cout<<"输入明文:"<<endl;
}
}
int main() {
int choice=1;
while(choice)
{
cout<<endl;
cout<<"选择字母表输出问题请输入1"<<endl;
cout<<"选择Vingenre加密问题请输入2"<<endl;
cout<<"退出请输入0"<<endl;
cin>>choice;
switch (choice) {
case 1 :
alpha_cout();
break;
case 2 :
Vingenre();
break;
case 0 :
exit(0);
break;
}
}
return 0;
}
栈和队列

栈的定义

按三次push

按一下pop


栈的顺序存储结构




入栈操作


出栈操作

栈顶的位置是没数据的,是准备存放数据的。







清空栈

销毁栈



实例






代码如下:
#include <iostream>
#include <math.h>
using namespace std;
#define STACK_INIT_SIZE 20
#define STACKINCREMENT 10
typedef char ElemType;
typedef struct {
ElemType *base;
ElemType *top;
int stackSize;
}sqStack;
/**
* 创建一个栈
* @param s
*/
void initStack(sqStack *s)
{
s->base=(ElemType *) malloc(STACK_INIT_SIZE*sizeof (ElemType));
if(!s->base)
{
exit(0);
}
s->top=s->base;
s->stackSize=STACK_INIT_SIZE;
}
/**
* 入栈
* @return
*/
void Push(sqStack *s,ElemType e)
{
//如果栈已经满了,就要扩充空间
if(s->top-s->base>=s->stackSize)
{
s->base=(ElemType *) realloc(s->base,(s->stackSize+STACKINCREMENT)*sizeof (ElemType));//realloc就是右边创建一个空间并复制到左边
if(!s->base)
{
exit(0);
}
s->top= s->base+s->stackSize;//栈顶的位置
s->stackSize=s->stackSize+STACKINCREMENT;//重新设置栈的容量
}
*(s->top)=e;
s->top++;
}
/**
* 出栈
* @return
*/
void pop(sqStack *s,ElemType *e)
{
if(s->top==s->base)
{
return ;
}
*e=*--(s->top);//因为top里卖弄不存放数据,它是用来准备存放下一个数据的
}
/**
* 栈的大小
*/
int StackLen(sqStack s)
{
return (s.top-s.base);
}
/**
* 清空
* @return
*/
void ClearStack(sqStack *s)
{
s->top=s->base;
}
/**
* 销毁栈
* @return
*/
void DestroyStack(sqStack *s)
{
int i,len;
len=s->stackSize;
for(i=0;i<len;i++)
{
free(s->base);
s->base++;
}
s->base=s->top=NULL;
s->stackSize=0;
}
/**
* 二进制转换十进制
* @return
*/
void TwoToTen()
{
ElemType c;
sqStack s;
initStack(&s);
int len ,i,sum=0;
cout<<"请输入二进制数,输入#符号表示结束!"<<endl;
cin>>c;
while(c!='#')//别用‘/n’ 因为/n的Assic是10 你输入一个就要按下换行符,也会把换行作为输入Push进去
{
Push(&s,c);
cin>>c;
}
getchar();//全部接受完毕后,键盘还会接受一个‘/n’ /n的Assic是10 ,所以要过滤掉这个10 ,用getchar()得到‘/n’;
len= StackLen(s);
cout<<"栈的当前容量:"<<len<<endl;
for(i=0;i<len;i++)
{
pop(&s,&c);
sum=sum+(c-48)*pow(2,i);
}
cout<<"转换为十进制: "<<sum<<endl;
}
/**
* 二进制转换八进制 只需要再建一个栈就行 用一个三次循环计算八进制
* @return
*/
int main() {
TwoToTen();
return 0;
}
栈的链式存储结构

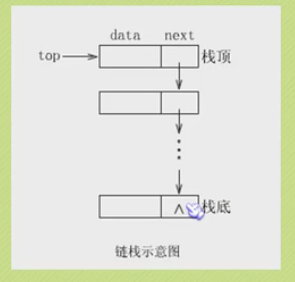

链式栈的入栈

链式栈的出栈

实践






逆波兰计算器


目前这个代码在自己的电脑运行存在问题,这个和小甲鱼的代码是一样实现的,但是不知道哪里出错了。
找到问题了,是输入语句的问题,不能用cin,因为cin自动忽略了空格,我操了!
参考博客
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
#include <math.h>
#include <ctype.h>
using namespace std;
#define STACK_INIT_SIZE 20
#define STACKINCREMENT 10
#define MAXBUFFER 10
typedef float ElemType;
typedef struct {
ElemType *base;
ElemType *top;
int stackSize;
}sqStack;
/**
* 创建一个栈
* @param s
*/
void initStack(sqStack *s)
{
s->base=(ElemType *) malloc(STACK_INIT_SIZE*sizeof (ElemType));
if(!s->base)
{
exit(0);
}
s->top=s->base;
s->stackSize=STACK_INIT_SIZE;
}
/**
* 入栈
* @return
*/
void Push(sqStack *s,ElemType e)
{
//如果栈已经满了,就要扩充空间
if(s->top-s->base>=s->stackSize)
{
s->base=(ElemType *) realloc(s->base,(s->stackSize+STACKINCREMENT)*sizeof (ElemType));//realloc就是右边创建一个空间并复制到左边
if(!s->base)
{
exit(0);
}
s->top= s->base+s->stackSize;//栈顶的位置
s->stackSize=s->stackSize+STACKINCREMENT;//重新设置栈的容量
}
*(s->top)=e;
s->top++;
}
/**
* 出栈
* @return
*/
void Pop(sqStack *s,ElemType *e)
{
if(s->top==s->base)
{
return ;
}
*e=* --(s->top);//因为top里面不存放数据,它是用来准备存放下一个数据的
}
/**
* 栈的大小
*/
int StackLen(sqStack s)
{
return (s.top-s.base);
}
/**
* 清空
* @return
*/
void ClearStack(sqStack *s)
{
s->top=s->base;
}
/**
* 销毁栈
* @return
*/
void DestroyStack(sqStack *s)
{
int i,len;
len=s->stackSize;
for(i=0;i<len;i++)
{
free(s->base);
s->base++;
}
s->base=s->top=NULL;
s->stackSize=0;
}
/**
* 波兰计算器
*/
int main() {
sqStack s;
char c;
int i=0;
float d,e;
char str[MAXBUFFER];
initStack(&s);
cout<<"请按逆波兰表达式输入带计算数据,数据与运算符之间用空格隔开,以#作为结束标志:"<<endl;
cin>>c;
while(c != '#')
{
while(isdigit(c) || c=='.')//用于过滤数字
{
str[i++]=c;
str[i]='\0';
if(i>=10)
{
cout<<"出错:输入的单个数据过大!"<<endl;
return -1;
}
cin>>c;
if(c==' ')
{
d=atof(str);//转化为double
Push(&s,d);
i=0;
break;
}
}
switch(c)
{
case '+':
Pop(&s,&e);//注意这里的Stack里面的data是double型
Pop(&s,&d);
Push(&s,d+e);
break;
case '-':
Pop(&s,&e);//注意这里的Stack里面的data是double型
Pop(&s,&d);
Push(&s,d-e);
break;
case '*':
Pop(&s,&e);//注意这里的Stack里面的data是double型
Pop(&s,&d);
Push(&s,d*e);
break;
case '/':
Pop(&s,&e);//注意这里的Stack里面的data是double型
Pop(&s,&d);
if(e!=0)
{
Push(&s,d/e);
}
else
{
cout<<"出错:除数为零!"<<endl;
return -1;
}
break;
}
cin>>c;
}
Pop(&s,&d);
cout<<"最终的计算结果:"<<d<<endl;
return 0;
}
下面是正确代码:
#include <stdio.h>
#include <ctype.h>
#include <stdlib.h>
#include <iostream>
using namespace std;
#define STACK_INIT_SIZE 20
#define STACKINCREMENT 10
#define MAXBUFFER 10
typedef double ElemType;
typedef struct
{
ElemType *base;
ElemType *top;
int stackSize;
}sqStack;
void InitStack(sqStack *s)
{
s->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base;
s->stackSize = STACK_INIT_SIZE;
}
void Push(sqStack *s, ElemType e)
{
// 栈满,追加空间,鱼油必须懂!
if( s->top - s->base >= s->stackSize )
{
s->base = (ElemType *)realloc(s->base, (s->stackSize + STACKINCREMENT) * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base + s->stackSize;
s->stackSize = s->stackSize + STACKINCREMENT;
}
*(s->top) = e; // 存放数据
s->top++;
}
void Pop(sqStack *s, ElemType *e)
{
if( s->top == s->base )
return;
*e = *--(s->top); // 将栈顶元素弹出并修改栈顶指针
}
int StackLen(sqStack s)
{
return (s.top - s.base);
}
int main()
{
sqStack s;
char c;
double d, e;
char str[MAXBUFFER];
int i = 0;
InitStack( &s );
printf("请按逆波兰表达式输入待计算数据,数据与运算符之间用空格隔开,以#作为结束标志: \n");
scanf("%c", &c);
//cin>>c ;
while( c != '#' )
{
while( isdigit(c) || c=='.' ) // 用于过滤数字
{
str[i++] = c;
str[i] = '\0';
if( i >= 10 )
{
printf("出错:输入的单个数据过大!\n");
return -1;
}
scanf("%c", &c);
//cin>>c ;
if( c == ' ' )
{
d = atof(str);
Push(&s, d);
i = 0;
break;
}
}
switch( c )
{
case '+':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d+e);
break;
case '-':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d-e);
break;
case '*':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d*e);
break;
case '/':
Pop(&s, &e);
Pop(&s, &d);
if( e != 0 )
{
Push(&s, d/e);
}
else
{
printf("\n出错:除数为零!\n");
return -1;
}
break;
}
scanf("%c", &c);
//cin>>c;
}
Pop(&s, &d);
printf("\n最终的计算结果为:%f\n", d);
return 0;
}
// 5 - (6 + 7) * 8 + 9 / 4
// 5 - 13 * 8 + 9 / 4
// 5 - 104 + 2.25
// -99 + 2.25
// 5 6 7 + 8 * - 9 4 / +
中缀表达式变为后缀表达式











中缀表达式转为后缀表达式+逆波兰计算器完整代码如下:
#include <stdio.h>
#include <ctype.h>
#include <stdlib.h>
#include <iostream>
#include <string>
using namespace std;
/**
* 中缀表达式转化为后缀表达式
*/
namespace mToL
{
#define STACK_INIT_SIZE 20
#define STACKINCREMENT 10
#define MAXBUFFER 10
typedef char ElemType;
typedef struct
{
ElemType *base;
ElemType *top;
int stackSize;
}sqStack;
void InitStack(sqStack *s)
{
s->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base;
s->stackSize = STACK_INIT_SIZE;
}
void Push(sqStack *s, ElemType e)
{
// 栈满,追加空间,鱼油必须懂!
if( s->top - s->base >= s->stackSize )
{
s->base = (ElemType *)realloc(s->base, (s->stackSize + STACKINCREMENT) * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base + s->stackSize;
s->stackSize = s->stackSize + STACKINCREMENT;
}
*(s->top) = e; // 存放数据
s->top++;
}
void Pop(sqStack *s, ElemType *e)
{
if( s->top == s->base )
return;
*e = *--(s->top); // 将栈顶元素弹出并修改栈顶指针
}
int StackLen(sqStack s)
{
return (s.top - s.base);
}
/**
* 中缀表达式转换为后缀表达式
*/
string mToL_test()
{
//把中缀表达式转为后缀表达式
sqStack s;
InitStack( &s );
string str;
printf("请输入中缀表达式,以#作为结束标志:");
char c;
char e;
scanf("%c",&c);
while(c!='#')
{
while(isdigit(c) )
{
printf("%c", c);
str+=c;
scanf("%c", &c);
if(!isdigit(c) )//
{
printf(" ");
str+=' ';
}
}
if(')'==c)
{
Pop(&s,&e);//
while('('!=e)
{
printf("%c ", e);//输出字符后面带一个空格
str+=e;
str+=' ';
Pop(&s,&e);//
}
}
else if('+'==c||'-'==c)
{
if(!StackLen(s))//如果stack为空
{
Push(&s,c);
}
else
{
do
{
Pop(&s,&e);
if('('== e)//先判断一下里面有没有左括号,如果有,说明此时的c肯定包含在括号里面 因此左括号还是要要放在里面 直到用右括号来匹配弹出括号里面的运算符
{
Push(&s,e);//
}
else//如果不是左括号直接弹出 比如 9+3+(1+3) ---- 9 3 - 1 3 +
{
printf("%c ", e);//输出字符后面带一个空格
str+=e;
str+=' ';
}
}
while(StackLen(s) && '('!=e);//
Push(&s,c);
}
}
else if('*'==c|| '/'==c ||'('==c)
{
Push(&s,c);
}
else if( '#'== c )
{
break;
}
else
{
cout<<"输入格式错误!"<<endl;
//return -1;
}
scanf("%c",&c);
}
while( StackLen(s) )
{
Pop(&s, &e);
printf("%c ", e);
str+=e;
str+=' ';
//printf("%c ", e);
}
return str+'#';
}
}
/**
* 逆波兰计算器
*/
namespace PolanCaulatuer
{
#define STACK_INIT_SIZE 20
#define STACKINCREMENT 10
#define MAXBUFFER 10
typedef double ElemType;
typedef struct
{
ElemType *base;
ElemType *top;
int stackSize;
}sqStack;
void InitStack(sqStack *s)
{
s->base = (ElemType *)malloc(STACK_INIT_SIZE * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base;
s->stackSize = STACK_INIT_SIZE;
}
void Push(sqStack *s, ElemType e)
{
// 栈满,追加空间,鱼油必须懂!
if( s->top - s->base >= s->stackSize )
{
s->base = (ElemType *)realloc(s->base, (s->stackSize + STACKINCREMENT) * sizeof(ElemType));
if( !s->base )
exit(0);
s->top = s->base + s->stackSize;
s->stackSize = s->stackSize + STACKINCREMENT;
}
*(s->top) = e; // 存放数据
s->top++;
}
void Pop(sqStack *s, ElemType *e)
{
if( s->top == s->base )
return;
*e = *--(s->top); // 将栈顶元素弹出并修改栈顶指针
}
int StackLen(sqStack s)
{
return (s.top - s.base);
}
/**
* 波兰逆计算器
*/
void PolanCaulauter(string strl)
{
sqStack s;
char c;
double d, e;
char str[MAXBUFFER];
int i = 0;
int j = 0;
InitStack( &s );
//printf("请按逆波兰表达式输入待计算数据,数据与运算符之间用空格隔开,以#作为结束标志: \n");
//scanf("%c", &c);
//cin>>c ;
c=strl[0];
cout<<"size: "<<strl.size()<<endl;
while( c != '#')
{
while( isdigit(c) || c=='.' ) // 用于过滤数字
{
str[i++] = c;
str[i] = '\0';
if( i >= 10 )
{
printf("出错:输入的单个数据过大!\n");
//return -1;
}
c=strl[++j];
//scanf("%c", &c);
//cin>>c ;
if( c == ' ' )
{
d = atof(str);
Push(&s, d);
i = 0;
break;
}
}
switch( c )
{
case '+':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d+e);
break;
case '-':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d-e);
break;
case '*':
Pop(&s, &e);
Pop(&s, &d);
Push(&s, d*e);
break;
case '/':
Pop(&s, &e);
Pop(&s, &d);
if( e != 0 )
{
Push(&s, d/e);
}
else
{
printf("\n出错:除数为零!\n");
//return -1;
}
break;
default:
break;
}
c=strl[++j];
//scanf("%c", &c);
//cin>>c;
}
Pop(&s, &d);
printf("\n最终的计算结果为:%f\n", d);
// 5 - (6 + 7) * 8 + 9 / 4
// 5 - 13 * 8 + 9 / 4
// 5 - 104 + 2.25
// -99 + 2.25
// 5 6 7 + 8 * - 9 4 / +
}
}
int main()
{
string s;
s=mToL::mToL_test();
cout<<endl;
cout<<s<<endl;
PolanCaulatuer::PolanCaulauter(s);
return 0;
}
队列queue




创建一个队列

入队列操作


出队列操作



销毁一个队列

#include <iostream>
using namespace std;
typedef char ElemType;
typedef struct QNode
{
ElemType data;
struct QNode *next;
}QNode,*QueuePtr ;
typedef struct {
QueuePtr front,rear;//指向对头和对尾节点,对头不存放数据
}LinkQueue;
/**
* 初始化queue
* @param q
*/
void initQueue(LinkQueue *q)
{
q->front=q->rear=(QueuePtr) malloc(sizeof (QNode));
if(!q->front)
{
exit(0);
q->front->next=NULL;
}
}
/**
* 入queue
* @param q
* @param e
*/
void InsertQueue(LinkQueue *q,ElemType e)
{
QueuePtr p;
p=(QueuePtr) malloc(sizeof (QNode));
p->data=e;
p->next=NULL;
q->rear->next=p;
q->rear=p;
}
/**
* 出队列
* @param q
* @param e
*/
void DeleteQueue(LinkQueue *q,ElemType *e)
{
QueuePtr p;
if(q->front==q->rear)//空的queue
return;
p=q->front->next;
*e=p->data;
q->front->next=p->next;
if(q->rear==p)//只有一个元素
{
q->rear=q->front;
}
free(p);
}
/**
* 销毁queue
* @param q
*/
void DestoryQueue(LinkQueue *q)
{
while(q->front)
{
q->rear=q->front->next;//指向每次要被销毁掉的节点的后一个节点
free(q->front);
q->front=q->rear;//第一个节点后移
}
}
int main() {
ElemType c;
LinkQueue q;
initQueue(&q);
cout<<"请输入一个字符串,以#号结束输入。"<<endl;
scanf("%c", &c);
while('#'!=c)
{
InsertQueue( &q, c );
scanf("%c", &c);
}
cout<<"打印队列中的元素:"<<endl;
while(q.front!=q.rear)
{
DeleteQueue( &q, &c );
cout<<c;
}
cout<<endl;
return 0;
}
队列的顺序存储




循环队列







定义循环队列

初始化循环队列

入队列操作



#include <iostream>
using namespace std;
#define MAXSIZE 100
typedef int ElemType;
typedef struct cycleQueue
{
ElemType *base;
int front;
int rear;//表示可以用的位置
}cycleQueue;
/**
* 初始化循环队列
* @param q
*/
void initLoopQueue(cycleQueue *q)
{
q->base=( ElemType *) malloc(MAXSIZE*sizeof (ElemType));
if(!q->base)
{
exit(0);
}
q->front=q->rear=0;
}
/**
* 入队列
* @param q
* @param e
*/
void InsertQueue(cycleQueue *q,ElemType e)
{
if((q->rear+1)%MAXSIZE==q->front)
{
return;//队列满了
}
q->base[q->front]=e;
q->rear=(q->rear+1)%MAXSIZE;
}
/**
* 出队列
* @param q
* @param e
*/
void DeleteQueue(cycleQueue *q,ElemType *e)
{
if(q->front==q->rear)
{
return;//队列空的
}
*e=q->base[q->front];
q->front=(q->front+1)%MAXSIZE;
}
int main() {
std::cout << "Hello, World!" << std::endl;
return 0;
}
递归和分治


斐波那契数列的递归实现






#include <iostream>
using namespace std;
void iter()
{
int a[40];
a[0]=0;
a[1]=1;
cout<<a[0]<<" ";
cout<<a[1]<<" ";
for(int i=2;i<40;i++)
{
a[i]=a[i-1]+a[i-2];
cout<<a[i]<<" ";
}
}
int DiGui_Fib(int n)
{
if(n<2)
{
return n==0?0:1;
}
else
{
return DiGui_Fib(n-1)+ DiGui_Fib(n-2);
}
}
int main() {
iter();
int a =DiGui_Fib(39);
cout<<a<<endl;
return 0;
}
递归定义



实例



void DiGui_StrInverse()
{
char c;
scanf("%c",&c);
if('#'!=c) DiGui_StrInverse();
if('#'!=c) cout<<c;
}
分治思想

折半查找法的递归实现



#include <iostream>
using namespace std;
void iter()
{
int a[40];
a[0]=0;
a[1]=1;
cout<<a[0]<<" ";
cout<<a[1]<<" ";
for(int i=2;i<40;i++)
{
a[i]=a[i-1]+a[i-2];
cout<<a[i]<<" ";
}
}
int DiGui_Fib(int n)
{
if(n<2)
{
return n==0?0:1;
}
else
{
return DiGui_Fib(n-1)+ DiGui_Fib(n-2);
}
}
void DiGui_StrInverse()
{
char c;
scanf("%c",&c);
if('#'!=c) DiGui_StrInverse();
if('#'!=c) cout<<c;
}
/**
* 二分递归查找
* @param str
* @param low
* @param high
* @param k
* @return
*/
int binary_Search_DiGui(int str[],int low,int high,int k)
{
if(low>high)
{
return -1;
}
else
{
int mid = (low+high)/2;
if(str[mid]==k)
{
return mid;
}
if(str[mid]<k)
{
return binary_Search_DiGui(str,mid+1,high,k);
}
else
{
return binary_Search_DiGui(str,low,mid-1,k);
}
}
}
int main() {
/*iter();斐波那契数列迭代
int a =DiGui_Fib(39);//斐波那契数列递归
cout<<a<<endl;*/
//DiGui_StrInverse();
//二分查找递归
int str[11] = {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89};
int n, addr;
printf("请输入待查找的关键字: ");
scanf("%d", &n);
addr= binary_Search_DiGui(str,0,10,n);
if( -1 != addr )
{
printf("查找成功,可喜可贺,可口可乐! 关键字 %d 所在的位置是: %d\n", n, addr);
}
else
{
printf("查找失败!\n");
}
return 0;
}
汉诺塔







#include <iostream>
using namespace std;
void iter()
{
int a[40];
a[0]=0;
a[1]=1;
cout<<a[0]<<" ";
cout<<a[1]<<" ";
for(int i=2;i<40;i++)
{
a[i]=a[i-1]+a[i-2];
cout<<a[i]<<" ";
}
}
int DiGui_Fib(int n)
{
if(n<2)
{
return n==0?0:1;
}
else
{
return DiGui_Fib(n-1)+ DiGui_Fib(n-2);
}
}
/**
*
*/
void Febonaci_test()
{
iter();
int a =DiGui_Fib(39);//斐波那契数列递归
cout<<a<<endl;
}
/**
*
*/
void DiGui_StrInverse()
{
char c;
scanf("%c",&c);
if('#'!=c) DiGui_StrInverse();
if('#'!=c) cout<<c;
}
/**
* 二分递归查找
* @param str
* @param low
* @param high
* @param k
* @return
*/
int binary_Search_DiGui(int str[],int low,int high,int k)
{
if(low>high)
{
return -1;
}
else
{
int mid = (low+high)/2;
if(str[mid]==k)
{
return mid;
}
if(str[mid]<k)
{
return binary_Search_DiGui(str,mid+1,high,k);
}
else
{
return binary_Search_DiGui(str,low,mid-1,k);
}
}
}
void binary_Search_DiGui_test()
{
//二分查找递归
int str[11] = {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89};
int n, addr;
printf("请输入待查找的关键字: ");
scanf("%d", &n);
addr= binary_Search_DiGui(str,0,10,n);
if( -1 != addr )
{
printf("查找成功,可喜可贺,可口可乐! 关键字 %d 所在的位置是: %d\n", n, addr);
}
else
{
printf("查找失败!\n");
}
}
/**
* 将n个盘子 从 x 借助 y 移动到 z
* @param n
* @param x
* @param y
* @param z
*/
void move(int n,char x,char y,char z)
{
if(1==n)
{
cout<<x<<"-->"<<z<<" ";
}
else
{
move(n-1,x,z,y);//先将前n-1个从x 借助 z 移动到y
cout<<x<<"-->"<<z<<" ";//再将底下的第n个移动到z
move(n-1,y,x,z);//最后将y上的n-1个盘子借助x移动到z
}
}
/**
* 汉诺塔
*/
void HanNuoTa()
{
cout<<"请输入汉诺塔的层数:"<<endl;
int n;
cin>>n;
cout<<"移动步骤如下:"<<endl;
move(n,'X','Y','Z');
}
int main() {
HanNuoTa();
return 0;
}
//以三层汉诺塔为例,递归的流程如下:
3 x y z
{
2 x z y
{
1 x y z x-->z
x-->y
1 z x y z-->y
}
x-->z
2 y x z
{
1 y z x y-->x
y-->z
1 x y z x-->z
}
}
//最终的结果是:
x-->z
x-->y
z-->y
x-->z
y-->x
y-->z
x-->z
无论多少层数,本质上它都可以递归到1的时候,然后返回到2,再一次返回到n-1。
八皇后问题

#include <iostream>
using namespace std;
int count=0;//计数八皇后的个数
/**
* 判断[row,j]这个位置的行 列 还有斜线位置有没有皇后
* @param row
* @param j
* @param chess
* @return
*/
int notDanger(int row,int j,int (*chess)[8])
{
int i,k,flag1=0,flag2=0,flag3=0,flag4=0,flag5=0;
//判断各方向有没有危险
// 判断列方向
for( i=0; i < 8; i++ )
{
if( *(*(chess+i)+j) != 0 )
{
flag1 = 1;
break;
}
}
//判断左上方
for(i=row,k=j;i>=0&&k>=0;i--,k--)
{
if( *(*(chess+i)+k) != 0 )
{
flag2 = 1;
break;
}
}
// 判断右下方
for( i=row, k=j; i<8 && k<8; i++, k++ )
{
if( *(*(chess+i)+k) != 0 )
{
flag3 = 1;
break;
}
}
// 判断右上方
for( i=row, k=j; i>=0 && k<8; i--, k++ )
{
if( *(*(chess+i)+k) != 0 )
{
flag4 = 1;
break;
}
}
// 判断左下方
for( i=row, k=j; i<8 && k>=0; i++, k-- )
{
if( *(*(chess+i)+k) != 0 )
{
flag5 = 1;
break;
}
}
if(flag1 || flag2 || flag3 || flag4 || flag5)
{
return 0;
}
else
{
return 1;
}
}
/**
* 八皇后递归实现,其实好理解就是利用递归自动遍历每行
* @param row 表示起始行
* @param n 表示列数
* @param chess 指向棋盘每行的指针
*/
void EightQueen(int row,int n,int (*chess)[8])//chess指向每行
{
int chess2[8][8],i,j;
//将棋盘chess的值赋值给chess2
for(i=0;i<8;i++)
{
for(j=0;j<8;j++)
{
chess2[i][j]=chess[i][j];
}
}
if(row==8)
{
cout<<"第"<<count+1<<"种"<<endl;
for(i=0;i<8;i++)
{
for(j=0;j<8;j++)
{
cout<<*(*(chess2+i)+j);
}
cout<<endl;
}
cout<<endl;
count++;
}
else
{
//判断这个位置是否有危险
//如果没有危险,就继续往下
for(j=0;j<n;j++)
{
if(notDanger(row,j,chess)) //判断这个位置是否有危险
{
for(i=0;i<8;i++)
{
*(*(chess2+row)+i)=0;//先把整个列标为0
}
*(*(chess2+row)+j)=1;//再把不危险的位置标为1--就是皇后的位置
EightQueen(row+1,n,chess2);
}
}
}
};
void EightQueen_test()
{
int chess[8][8];
for(int i=0;i<8;i++)
{
for(int j=0;j<8;j++)
{
chess[i][j]=0;//初始化棋盘
}
}
EightQueen(0,8,chess);
}
int main()
{
EightQueen_test();
return 0;
}
下面是完整的递归分治代码:
#include <iostream>
using namespace std;
void iter()
{
int a[40];
a[0]=0;
a[1]=1;
cout<<a[0]<<" ";
cout<<a[1]<<" ";
for(int i=2;i<40;i++)
{
a[i]=a[i-1]+a[i-2];
cout<<a[i]<<" ";
}
}
int DiGui_Fib(int n)
{
if(n<2)
{
return n==0?0:1;
}
else
{
return DiGui_Fib(n-1)+ DiGui_Fib(n-2);
}
}
/**
*
*/
void Febonaci_test()
{
iter();
int a =DiGui_Fib(39);//斐波那契数列递归
cout<<a<<endl;
}
/**
*
*/
void DiGui_StrInverse()
{
char c;
scanf("%c",&c);
if('#'!=c) DiGui_StrInverse();
if('#'!=c) cout<<c;
}
/**
* 二分递归查找
* @param str
* @param low
* @param high
* @param k
* @return
*/
int binary_Search_DiGui(int str[],int low,int high,int k)
{
if(low>high)
{
return -1;
}
else
{
int mid = (low+high)/2;
if(str[mid]==k)
{
return mid;
}
if(str[mid]<k)
{
return binary_Search_DiGui(str,mid+1,high,k);
}
else
{
return binary_Search_DiGui(str,low,mid-1,k);
}
}
}
void binary_Search_DiGui_test()
{
//二分查找递归
int str[11] = {1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89};
int n, addr;
printf("请输入待查找的关键字: ");
scanf("%d", &n);
addr= binary_Search_DiGui(str,0,10,n);
if( -1 != addr )
{
printf("查找成功,可喜可贺,可口可乐! 关键字 %d 所在的位置是: %d\n", n, addr);
}
else
{
printf("查找失败!\n");
}
}
/**
* 将n个盘子 从 x 借助 y 移动到 z
* @param n
* @param x
* @param y
* @param z
*/
void move(int n,char x,char y,char z)
{
if(1==n)
{
cout<<x<<"-->"<<z<<" ";
}
else
{
move(n-1,x,z,y);//先将前n-1个从x 借助 z 移动到y
cout<<x<<"-->"<<z<<" ";//再将底下的第n个移动到z
move(n-1,y,x,z);//最后将y上的n-1个盘子借助x移动到z
}
}
/**
* 汉诺塔
*/
void HanNuoTa()
{
cout<<"请输入汉诺塔的层数:"<<endl;
int n;
cin>>n;
cout<<"移动步骤如下:"<<endl;
move(n,'X','Y','Z');
}
int count=0;//计数八皇后的个数
/**
* 判断[row,j]这个位置的行 列 还有斜线位置有没有皇后
* @param row
* @param j
* @param chess
* @return
*/
int notDanger(int row,int j,int (*chess)[8])
{
int i,k,flag1=0,flag2=0,flag3=0,flag4=0,flag5=0;
//判断各方向有没有危险
// 判断列方向
for( i=0; i < 8; i++ )
{
if( *(*(chess+i)+j) != 0 )
{
flag1 = 1;
break;
}
}
//判断左上方
for(i=row,k=j;i>=0&&k>=0;i--,k--)
{
if( *(*(chess+i)+k) != 0 )
{
flag2 = 1;
break;
}
}
// 判断右下方
for( i=row, k=j; i<8 && k<8; i++, k++ )
{
if( *(*(chess+i)+k) != 0 )
{
flag3 = 1;
break;
}
}
// 判断右上方
for( i=row, k=j; i>=0 && k<8; i--, k++ )
{
if( *(*(chess+i)+k) != 0 )
{
flag4 = 1;
break;
}
}
// 判断左下方
for( i=row, k=j; i<8 && k>=0; i++, k-- )
{
if( *(*(chess+i)+k) != 0 )
{
flag5 = 1;
break;
}
}
if(flag1 || flag2 || flag3 || flag4 || flag5)
{
return 0;
}
else
{
return 1;
}
}
/**
* 八皇后递归实现,其实好理解就是利用递归自动遍历每行
* @param row 表示起始行
* @param n 表示列数
* @param chess 指向棋盘每行的指针
*/
void EightQueen(int row,int n,int (*chess)[8])//chess指向每行
{
int chess2[8][8],i,j;
//将棋盘chess的值赋值给chess2
for(i=0;i<8;i++)
{
for(j=0;j<8;j++)
{
chess2[i][j]=chess[i][j];
}
}
if(row==8)
{
cout<<"第"<<count+1<<"种"<<endl;
for(i=0;i<8;i++)
{
for(j=0;j<8;j++)
{
cout<<*(*(chess2+i)+j);
}
cout<<endl;
}
cout<<endl;
count++;
}
else
{
//判断这个位置是否有危险
//如果没有危险,就继续往下
for(j=0;j<n;j++)
{
if(notDanger(row,j,chess)) //判断这个位置是否有危险
{
for(i=0;i<8;i++)
{
*(*(chess2+row)+i)=0;//先把整个列标为0
}
*(*(chess2+row)+j)=1;//再把不危险的位置标为1--就是皇后的位置
EightQueen(row+1,n,chess2);
}
}
}
};
void EightQueen_test()
{
int chess[8][8];
for(int i=0;i<8;i++)
{
for(int j=0;j<8;j++)
{
chess[i][j]=0;//初始化棋盘
}
}
EightQueen(0,8,chess);
}
int main() {
//HanNuoTa();
EightQueen_test();
return 0;
}
/*以三层汉诺塔为例,递归的流程如下:
3 x y z
{
2 x z y
{
1 x y z x-->z
x-->y
1 z x y z-->y
}
x-->z
2 y x z
{
1 y z x y-->x
y-->z
1 x y z x-->z
}
}
最终的结果是:
x-->z
x-->y
z-->y
x-->z
y-->x
y-->z
x-->z
*/
字符串




字符串的存储结构

BF算法


#include <iostream>
#include <string>
using namespace std;
//暴力算法 经典体型,判断两个字符串的大小
int compare_Eaual(string &s1,string &s2)
{
int flag=0;
int n1=s1.size();
int n2=s2.size();
n1=max(n1,n2);
for(int i=0;i<n1;i++)
{
if(s1[i]>s2[i])
{
flag=1;
break;
}
else if(s1[i]==s2[i])
{
flag=0;
}
else if(s1[i]<s2[i])
{
flag=-1;
break;
}
}
return flag;
}
int main() {
string s1="aaf";
string s2="abf";
int jue;
jue=compare_Eaual(s1,s2);
if(jue==1)
{
cout<<"s1>s2"<<endl;
}
else if(jue==0)
{
cout<<"s1=s2"<<endl;
}
else if(jue==-1)
{
cout<<"s1<s2"<<endl;
}
return 0;
}
KMP算法






不需要回溯 i
在判断到不等的时候,模式串前面没有一样的字符,,回溯从1开始

模式串里有两个相等的字符,回溯从2开始

模式串里有一对相等的字符,回溯从2开始








就是匹配到不等的时候,起始A到匹配不等的前一个位置构成的字符串的前缀和后缀有几个相等的字符,加入n个相等字符,那么 j 就从n+1的位置开始。(前缀后缀从位置上来说不是一个字符串)
KMP算法之NEXT数组代码原理分析
NEXT数组就是上面的K


void get_next(string T,int *next)
{
int j=0;
int i=1;
next[1]=0;
while(i<T[0])//后缀超过长度的时候,就匹配完成了
{
if(j==0|| T[i]==T[j])
{
i++;
j++;
next[i]=j;
}
else
{
//j回溯
j=next[j];
}
//因为前缀是固定的,后缀是相对的(前缀是其实的字符)
}
}
//返回字串T在主串S第pos个字符后的位置
//若不存在,则返回0
int Index_KMP(string S,string T,int pos)
{
int i=pos;
int j=1;
int next[255];
get_next(T,next);//得到next数组
while(i<=S[0]&&j<=T[0])//S[0]与T[0]存放的是字符串的长度
{
if(j==0|| S[i]==T[j])
{
i++;
j++;
}
else
{
j=next[j];//KMP算法的灵魂,利用next作为最高指引
}
}
//匹配成功后 j肯定比T的字符串要大一位
if(j>T[0])
{
return i-T[0];
}
else
{
return 0;
}
}
KMP算法之实现及优化



这个特殊情况则么办
这样,判断到不等的时候,假如这个位置是 m,那么m-1位置的T的字符和前缀字符都相等的时候,就直接让j回到前缀对应的位置,上图中就是回到0.
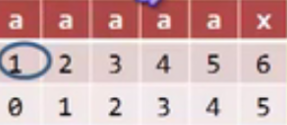
#include <iostream>
#include <string>
using namespace std;
void get_next(string T,int *next)
{
int j=0;
int i=1;
next[1]=0;
while(i<T[0])//后缀超过长度的时候,就匹配完成了
{
if(j==0|| T[i]==T[j])
{
i++;
j++;
//改进
if(T[i]!=T[j])
{
next[i]=j;
}
else
{
next[i]=next[j];//让前缀赋值
}
}
else
{
//j回溯
j=next[j];
}
//因为前缀是固定的,后缀是相对的(前缀是其实的字符)
}
}
//返回字串T在主串S第pos个字符后的位置
//若不存在,则返回0
int Index_KMP(string S,string T,int pos)
{
int i=pos;
int j=1;
int next[255];
get_next(T,next);//得到next数组
while(i<=S[0]&&j<=T[0])//S[0]与T[0]存放的是字符串的长度
{
if(j==0|| S[i]==T[j])
{
i++;
j++;
}
else
{
j=next[j];//KMP算法的灵魂,利用next作为最高指引
}
}
//匹配成功后 j肯定比T的字符串要大一位
if(j>T[0])
{
return i-T[0];
}
else
{
return 0;
}
}
int main() {
char str[255]=" aaaaax";
int next[255];
int i=1;
str[0]=9;
get_next(str,next);
for(i=1;i<10;i++)
{
cout<<next[i]<<" ";
}
return 0;
}
树




上图,整个树最大的节点是3.


上图树的深度为3,因为它有三层。
树的存储结构


// 树的双亲表示法结点结构定义
#define MAX_TREE_SIZE 100
typedef int ElemType;
typedef struct PTNode
{
ElemType data; // 结点数据
int parent; // 双亲位置
}PTNode;
typedef struct
{
PTNode nodes[MAX_TREE_SIZE];
int r; // 根的位置
int n; // 结点数目
}PTree;
双亲表示法

A是根没有双亲,所以为-1



孩子表示法





左边一块是数组,右边的是用链表链起来的

#define MAX_TREE_SIZE 100
typedef char ElemType;
//孩子节点
typedef struct CTNode
{
int child;//给孩子节点的下标
struct CTNode *next;//指向下一个孩子节点的指针
}* Childptr;
//表头结构
typedef struct
{
ElemType data; //存放在树种的节点的数据
int parent;//存放双亲的位置
Childptr firstchild;//指向第一个孩子额指针
}CTBox;
//树结构
typedef struct
{
CTBox nodes[MAX_TREE_SIZE];//节点数组
int r;//根的位置
int n;//树的节点的个数
};
二叉树


要注意区分左子树和右子树
二叉树五种心态



斜树只能全部往左斜或者全部往右斜。





上图依旧是完全二叉树,但是不是满二叉树。
因为上面的序号依然是连在一起的,1 2 3 4 5

上面的特点在上图有体现出来
以下这些都不是完全二叉树



上面三个都只是普通二叉树

二叉树的性质




向上取整和向下取整。




上面太理论了,看看就行,没什么意思。
二叉树的存储结构




此时很浪费资源。


二叉树的遍历






记住大家庭和小家庭概念就简单了



二叉树的建立和遍历算法


#include <iostream>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
typedef char ElemType;
typedef struct BiTNode
{
char data;
struct BiTNode *lchild,*rchild;
}BiTNode ,*BiTree;
//创建一颗二叉树
/**
* 用户用前序遍历的方式输入 根 左 右
* @param *T 是指针
*/
void CreatBiTree(BiTree *T)
{
char c;
scanf("%c",&c);
if(' '==c)//养成良好的代码书写习惯
{
*T=NULL;//字符为空格,就让这个指向空指针
}
else
{
*T= (BiTNode *)malloc(sizeof (BiTNode));//(BiTNode *) 强制转为BiTNode类型的指针
(*T)->data=c;
CreatBiTree(&(*T)->lchild);
CreatBiTree(&(*T)->rchild);
}
}
//访问二叉树节点的具体操作
void visit(char c,int level)
{
cout<<c<<"在第"<<level<<"层"<<endl;
}
//遍历二叉树
void PreOrderTraverse(BiTree T,int level)
{
if(T)
{
//根 左 右 如果是 中序遍历就换位置就行
visit(T->data,level);
PreOrderTraverse(T->lchild,level+1);
PreOrderTraverse(T->rchild,level+1);
}
}
//输入方式为 AB空格D空格空格CE空格空格空格
void test_PreTravese()
{
int level=1;
BiTree T=NULL;
CreatBiTree(&T);
PreOrderTraverse(T,level);
}
int main() {
test_PreTravese();
return 0;
}
线索二叉树



利用中序好像就可以解决这个问题了
因为发现都是隔一个隔一个的规律

前驱用黑色曲线箭头表示
后继用红色直线箭头表示





这个程序比较难以理解,建议用debug调试。
#include <iostream>
#include <stdlib.h>
#include <stdio.h>
using namespace std;
typedef char ElemType;
//线索存储标志位 枚举
//Link(0) 表示指向左右孩子的指针
//Thread(1)表示指向前驱后继的线索
typedef enum{Link,Thread} PointerTag;
typedef struct BiThrNode
{
ElemType data;
struct BiThrNode *lchild,*rchild;
PointerTag ltag;
PointerTag rtag;
}BiThrNode,*BithrTree;
//全局变量始终指向刚刚访问过的节点
BithrTree pre;
//创建一颗二叉树,约定用户遵照前序遍历的方式输入数据
/**
*
* @param *T是指针
*/
void CreatBiTree(BithrTree *T)
{
char c;
scanf("%c",&c);
if(' '==c)//养成良好的代码书写习惯
{
*T=NULL;//字符为空格,就让这个指向空指针
}
else
{
*T= (BiThrNode *)malloc(sizeof (BiThrNode));//(BiTNode *) 强制转为BiTNode类型的指针
(*T)->data=c;
//先设置它有左右孩子
(*T)->ltag=Link;
(*T)->rtag=Link;
CreatBiTree(&(*T)->lchild);
CreatBiTree(&(*T)->rchild);
}
}
//中序遍历线索化
void InThreading(BithrTree T)
{
if(T)
{
InThreading(T->lchild);//递归左孩子线索化 就是先走到最左边的那个,走到最左边的那个就会指向下面的语句
//节点处理
if(!T->lchild)//如果该节点没有左孩子,设置ltag为Thread,并把lchild指向刚刚访问的节点
{
T->ltag=Thread;
T->lchild=pre;
}
if(!pre->rchild)
{
pre->rtag=Thread;
pre->rchild=T;
}
pre=T;
InThreading(T->rchild);//递归右孩子线索化
}
};
void visit(char c)
{
cout<<c<<endl;
}
//中序遍历二叉树 迭代
//这里的T应该是头指针 pre
void InorderTravse(BithrTree T)
{
BithrTree p;
p=T->lchild;
while(p!=T)
{
while(p->ltag==Link)//找到最下面的左节点
{
p=p->lchild;
}
visit(p->data);
while(p->rtag==Thread && p->rchild!=T)
{
p=p->rchild;
visit(p->data);
}
p=p->rchild;//指回到头节点
}
}
void InorderThreading(BithrTree *p,BithrTree T)
{
*p=(BiThrNode *)malloc(sizeof (BiThrNode));
(*p)->ltag=Link;
(*p)->rtag=Thread;
(*p)->rchild=*p;
if(!T)
{
(*p)->lchild=*p;
}
else
{
(*p)->lchild=T;
pre=*p;
InThreading(T);
//递归结束后 pre指向F 执行下面的动作把,C的左孩子的右孩子指向了F
pre->rchild=*p;
pre->rtag=Thread;
(*p)->rchild=pre;
}
}
int main() {
BithrTree p,T=NULL;
CreatBiTree(&T);
InorderThreading(&p,T);
cout<<"中序遍历输出结果为:"<<endl;
InorderTravse(p);
return 0;
}


树、森林及二叉树的相互转换















树与森林的遍历



赫夫曼树


70-90分的人要进行三次判断才知道(这个分数段的人占比最大)。效率有点低



左边树的对应数据
以节点c为例:
C的路径长度:3
树的路径长度:1+2+3+3
C带权路径长度:70*3
树的带权路径长度WPL:1*5+15*2+70*3+10*3
右边树的对应数据
树的带权路径长度WPL:1*10+2*70+3*15+3*5
显然右边树的带权路径长度WPL小于左边树的带权路径长度WPL,所以右边树的效率更高。








赫夫曼编码




代码里面的一些数据结构

//队列的节点
typedef struct _pQueueNode {
TYPE val;//指向树节点
unsigned int priority;//字符出现的次数,也就是赫夫曼编码的权值
struct _pQueueNode *next;//指向下一个队列的节点
}pQueueNode;
// pQueue就是队列的头
typedef struct _pQueue {
unsigned int size; //存放队列的长度,最后一个就是树的根节点
pQueueNode *first; //指向队列的第一个节点
}pQueue;
//赫夫曼树节点
typedef struct _htNode {
char symbol;//存放字符
struct _htNode *left, *right;//左子树 右子树
}htNode;

//The Huffman table nodes (linked list implementation)
typedef struct _hlNode {
char symbol; //存放字符 比如a
char *code;//存放字符a对应的赫夫曼编码 比如,0010
struct _hlNode *next; //指向下一个_hlNode
}hlNode;
//Incapsularea listei
typedef struct _hlTable {
hlNode *first;//指向第一个_hlNode
hlNode *last;//指向最后一个_hlNode
}hlTable;
代码如下:
pQueue.h
#pragma once//防止头文件重复定义
#ifndef _PQUEUE_H
#define _PQUEUE_H
#include "huffman.h"
//We modify the data type to hold pointers to Huffman tree nodes
#define TYPE htNode *
#define MAX_SZ 256
//队列的节点
typedef struct _pQueueNode {
TYPE val;//指向树节点
unsigned int priority;//字符出现的次数,也就是赫夫曼编码的权值
struct _pQueueNode *next;//指向下一个队列的节点
}pQueueNode;
// pQueue就是队列的头
typedef struct _pQueue {
unsigned int size; //存放队列的长度,最后一个就是树的根节点
pQueueNode *first; //指向队列的第一个节点
}pQueue;
void initPQueue(pQueue **queue);
void addPQueue(pQueue **queue, TYPE val, unsigned int priority);
TYPE getPQueue(pQueue **queue);
#endif
huffman.h
#pragma once
#ifndef _HUFFMAN_H
#define _HUFFMAN_H
//The Huffman tree node definition
//赫夫曼树节点
typedef struct _htNode {
char symbol;//存放字符
struct _htNode *left, *right;//左子树 右子树
}htNode;
/*
We "encapsulate" the entire tree in a structure
because in the future we might add fields like "size"
if we need to. This way we don't have to modify the entire
source code.
*/
typedef struct _htTree {
htNode *root;
}htTree;
//The Huffman table nodes (linked list implementation)
typedef struct _hlNode {
char symbol; //存放字符 比如a
char *code;//存放字符a对应的赫夫曼编码 比如,0010
struct _hlNode *next; //指向下一个_hlNode
}hlNode;
//Incapsularea listei
typedef struct _hlTable {
hlNode *first;//指向第一个_hlNode
hlNode *last;//指向最后一个_hlNode
}hlTable;
htTree * buildTree(char *inputString);
hlTable * buildTable(htTree *huffmanTree);
void encode(hlTable *table, char *stringToEncode);
void decode(htTree *tree, char *stringToDecode);
#endif
pQueue.cpp
#include "pQueue.h"
#include <stdlib.h>
#include <stdio.h>
/**
* 初始化队列
* @param queue 对列的头指针
*/
void initPQueue(pQueue **queue)
{
//We allocate memory for the priority queue type
//and we initialize the values of the fields
(*queue) = (pQueue *) malloc(sizeof(pQueue));//(*queue)相当于就是huffmanQueue 给头指针生成了空间
(*queue)->first = NULL;
(*queue)->size = 0;
return;
}
/**
* 加入队列
* @param queue 队列的头指针
* @param val 树的节点
* @param priority 字符出现的次数
*/
void addPQueue(pQueue **queue, TYPE val, unsigned int priority)
{
//If the queue is full we don't have to add the specified value.
//We output an error message to the console and return.
if((*queue)->size == MAX_SZ)//队列已满
{
printf("\nQueue is full.\n");
return;
}
//队列没满
pQueueNode *aux = (pQueueNode *)malloc(sizeof(pQueueNode));//分配一个队列的节点
aux->priority = priority;//字符出现次数
aux->val = val;//指向树的节点的指针
//If the queue is empty we add the first value.
//We validate twice in case the structure was modified abnormally at runtime (rarely happens).
if((*queue)->size == 0 || (*queue)->first == NULL) //队列为空的时候 把东西直接丢进去就行
{
aux->next = NULL;
(*queue)->first = aux;
(*queue)->size = 1;
return;
}
else//如果不是空的 按字符出现次数递增的规律插入到队列
{
//If there are already elements in the queue and the priority of the element
//that we want to add is greater than the priority of the first element,
//we'll add it in front of the first element.
//Be careful, here we need the priorities to be in descending order
if(priority<=(*queue)->first->priority)//比如字符a出现一次 字符b也出现一次,那么把拥有b的这个队列的节点放在a的前面
{
aux->next = (*queue)->first;//
(*queue)->first = aux;
(*queue)->size++;
return;
}
else
{
//We're looking for a place to fit the element depending on it's priority
pQueueNode * iterator = (*queue)->first;//迭代器
while(iterator->next!=NULL)//根据循环来遍历节点,使得此节点按字符出现次数(递增)插入到队列里面
{
//Same as before, descending, we place the element at the begining of the
//sequence with the same priority for efficiency even if
//it defeats the idea of a queue.
if(priority<=iterator->next->priority)
{
aux->next = iterator->next;
iterator->next = aux;
(*queue)->size++;
return;
}
iterator = iterator->next;
}
//If we reached the end and we haven't added the element,
//we'll add it at the end of the queue.
if(iterator->next == NULL)//如果队列只有一个节点,这个的字符的出现次数还比当前节点的字符出现的次数小 就直接让当前节点接在后面
{
aux->next = NULL;
iterator->next = aux;
(*queue)->size++;
return;
}
}
}
}
//从队列里面获取数据,赫夫曼树的生成就是获取两个树节点的priority 然后加起来,生成一个新的树节点,左孩子右孩子分别是那两个树节点
/**
* 获取队列对应树节点,获取一个后,队列头指向的第一个节点都往后移
* @param queue 队列头指针
* @return TYPE 指向树节点的指针
*/
TYPE getPQueue(pQueue **queue)
{
TYPE returnValue;
//We get elements from the queue as long as it isn't empty
if((*queue)->size>0)
{
returnValue = (*queue)->first->val;
(*queue)->first = (*queue)->first->next;//这里改变头指针指向的队列的第一个节点
(*queue)->size--;
}
else
{
//If the queue is empty we show an error message.
//The function will return whatever is in the memory at that time as returnValue.
//Or you can define an error value depeding on what you choose to store in the queue.
printf("\nQueue is empty.\n");
}
return returnValue;
}
huffman.cpp
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include "huffman.h"
#include "pQueue.h"
/**
*
* @param treeNode 丢进去赫夫曼树的节点
* @param table 待填充的赫夫曼表
* @param k 赫夫曼树的层数
* @param code 赫夫曼编码---根据左子树0,右子树1规则填写
*/
void traverseTree(htNode *treeNode, hlTable **table, int k, char code[256])
{
//If we reach the end we introduce the code in the table
if(treeNode->left == NULL && treeNode->right == NULL)//走到最下面了,treeNode就是叶子了
//赫夫曼树里面的字符都是放在叶子
{
code[k] = '\0';//字符串的结束符
hlNode *aux = (hlNode *)malloc(sizeof(hlNode));
aux->code = (char *)malloc(sizeof(char)*(strlen(code)+1));
strcpy(aux->code,code);
aux->symbol = treeNode->symbol;
aux->next = NULL;
//下面就是简单的操作了
if((*table)->first == NULL)
{
(*table)->first = aux;
(*table)->last = aux;
}
else
{
//类似尾插
(*table)->last->next = aux;
(*table)->last = aux;
}
}
//我们利用递归来实现遍历
//We concatenate a 0 for each step to the left
if(treeNode->left!=NULL)
{
code[k]='0';
traverseTree(treeNode->left,table,k+1,code);
}
//We concatenate a 1 for each step to the right
if(treeNode->right!=NULL)
{
code[k]='1';
traverseTree(treeNode->right,table,k+1,code);
}
}
/**
* 生成赫夫曼表
* @param huffmanTree
* @return
*/
hlTable * buildTable(htTree * huffmanTree)
{
//We initialize the table
hlTable *table = (hlTable *)malloc(sizeof(hlTable));
table->first = NULL;
table->last = NULL;
//Auxiliary variables
char code[256];
//k will memories the level on which the traversal is
int k=0;
//We traverse the tree and calculate the codes
traverseTree(huffmanTree->root,&table,k,code);//传进赫夫曼树的很节点,以及待填充的table ,
// k代表第几层,
// code来存放编码,如果走了左子树就加’0‘,走了右子树就加’1‘
return table;
}
/**
* 生成赫夫曼树
* @param inputString---字符串
* @return 赫夫曼树的根节点
*/
htTree * buildTree(char *inputString)
{
//The array in which we calculate the frequency of the symbols
//Knowing that there are only 256 posibilities of combining 8 bits
//(256 ASCII characters)
int * probability = (int *)malloc(sizeof(int)*256);
//初始化
//We initialize the array
for(int i=0; i<256; i++)
probability[i]=0;
//统计待编码字符串各个字符出现的次数
//We consider the symbol as an array index and we calculate how many times each symbol appears
for(int i=0; inputString[i]!='\0'; i++)
probability[(unsigned char) inputString[i]]++;//比如第一个字符是I 它的ASCII是73 那这里也就是 probability[73]++;
//The queue which will hold the tree nodes
//pQueue 队列头节点
pQueue * huffmanQueue;
initPQueue(&huffmanQueue);//初始化 --
//填充队列
//We create nodes for each symbol in the string
for(int i=0; i<256; i++)
if(probability[i]!=0)//这个字符出现过
{
htNode *aux = (htNode *)malloc(sizeof(htNode));//分配一个树的节点
aux->left = NULL;
aux->right = NULL;
aux->symbol = (char) i;//i代表的就是字符的ASCII值 ,(char) i就变成对应的字符,把这个字符传到树节点中
addPQueue(&huffmanQueue,aux,probability[i]);//加入这个队列
}
//We free the array because we don't need it anymore
free(probability);//probability用完了,就释放掉堆空间
//生成赫夫曼树
//We apply the steps described in the article to build the tree
while(huffmanQueue->size!=1)//等于1就是只剩下根节点
{
int priority = huffmanQueue->first->priority;
priority+=huffmanQueue->first->next->priority;//把前两个的字符出现的次数加起来,也就是新节点的次数 这里次数其实就是赫夫曼编码的权值
htNode *left = getPQueue(&huffmanQueue);//左子树 每次获取一次后,头指针自动指向下一个待获取的队列节点
htNode *right = getPQueue(&huffmanQueue);//右子树
//生成一个新的树节点
htNode *newNode = (htNode *)malloc(sizeof(htNode));
newNode->left = left;
newNode->right = right;
addPQueue(&huffmanQueue,newNode,priority);//按照次数递增的规律再把新的树节点查到队列中
}
//建立赫夫曼树的根节点
//We create the tree
htTree *tree = (htTree *) malloc(sizeof(htTree));
//到这里的时候,getPQueue(&huffmanQueue)得到的是对列里的最后一个节点 把它赋给树的赫夫曼树根节点
tree->root = getPQueue(&huffmanQueue);
return tree;
}
/**
* 编码
* 把Input的字符串的赫夫曼编码输出
* @param table 赫夫曼表
* @param stringToEncode 想要编码的字符串---Input--待压缩的文件
*/
void encode(hlTable *table, char *stringToEncode)
{
hlNode *traversal;//遍历赫夫曼表
printf("\nEncoding\nInput string : %s\nEncoded string : \n",stringToEncode);
//For each element of the string traverse the table
//and once we find the symbol we output the code for it
for(int i=0; stringToEncode[i]!='\0'; i++)
{
traversal = table->first;
while(traversal->symbol != stringToEncode[i])//while用来找到对应字符的赫夫曼表节点
traversal = traversal->next;
printf("%s",traversal->code);
}
printf("\n");
}
/**
* 解码
* 其实就是遍历赫夫曼树 0就是向左走一下,1就是向右有以下
* @param tree 赫夫曼树
* @param stringToDecode 待解码的赫夫曼编码 ----Input
*/
void decode(htTree *tree, char *stringToDecode)
{
htNode *traversal = tree->root;//先指向赫夫曼树的根节点
printf("\nDecoding\nInput string : %s\nDecoded string : \n",stringToDecode);
//For each "bit" of the string to decode
//we take a step to the left for 0
//or ont to the right for 1
for(int i=0; stringToDecode[i]!='\0'; i++)
{
if(traversal->left == NULL && traversal->right == NULL)//遍历到叶子了
{
printf("%c",traversal->symbol);//输出字符
traversal = tree->root;//回到根节点
}
if(stringToDecode[i] == '0')
traversal = traversal->left;
if(stringToDecode[i] == '1')
traversal = traversal->right;
if(stringToDecode[i]!='0'&&stringToDecode[i]!='1')
{
printf("The input string is not coded correctly!\n");
return;
}
}
//这里已经遍历了一边待解码的赫夫曼编码
if(traversal->left == NULL && traversal->right == NULL)
{
printf("%c",traversal->symbol);//输出字符
traversal = tree->root;//回到根节点
}
printf("\n");
}
main.cpp
#include <stdio.h>
#include <stdlib.h>
#include "huffman.h"
int main(void)
{
//We build the tree depending on the string
htTree *codeTree = buildTree("beep boop beer!");//build 赫夫曼tree
//We build the table depending on the Huffman tree
hlTable *codeTable = buildTable(codeTree);//赫夫曼table,存放各个字符的编码
//We encode using the Huffman table
encode(codeTable,"beep boop beer!");//编码
//We decode using the Huffman tree
//We can decode string that only use symbols from the initial string
decode(codeTree,"0011111000111");//解码
//Output : 0011 1110 1011 0001 0010 1010 1100 1111 1000 1001
return 0;
}
图

多对多的关系



无序偶里的vi vj的顺序












有向图就是加了强这个字

加两个边就不是生成树了


这个也不是生成树 因为是两个子图

左边的有向图变成右边的森林,右边的森林由两个有向树构成。
图的存储结构



因为是无向图,二维数组是对称的。
邻接矩阵


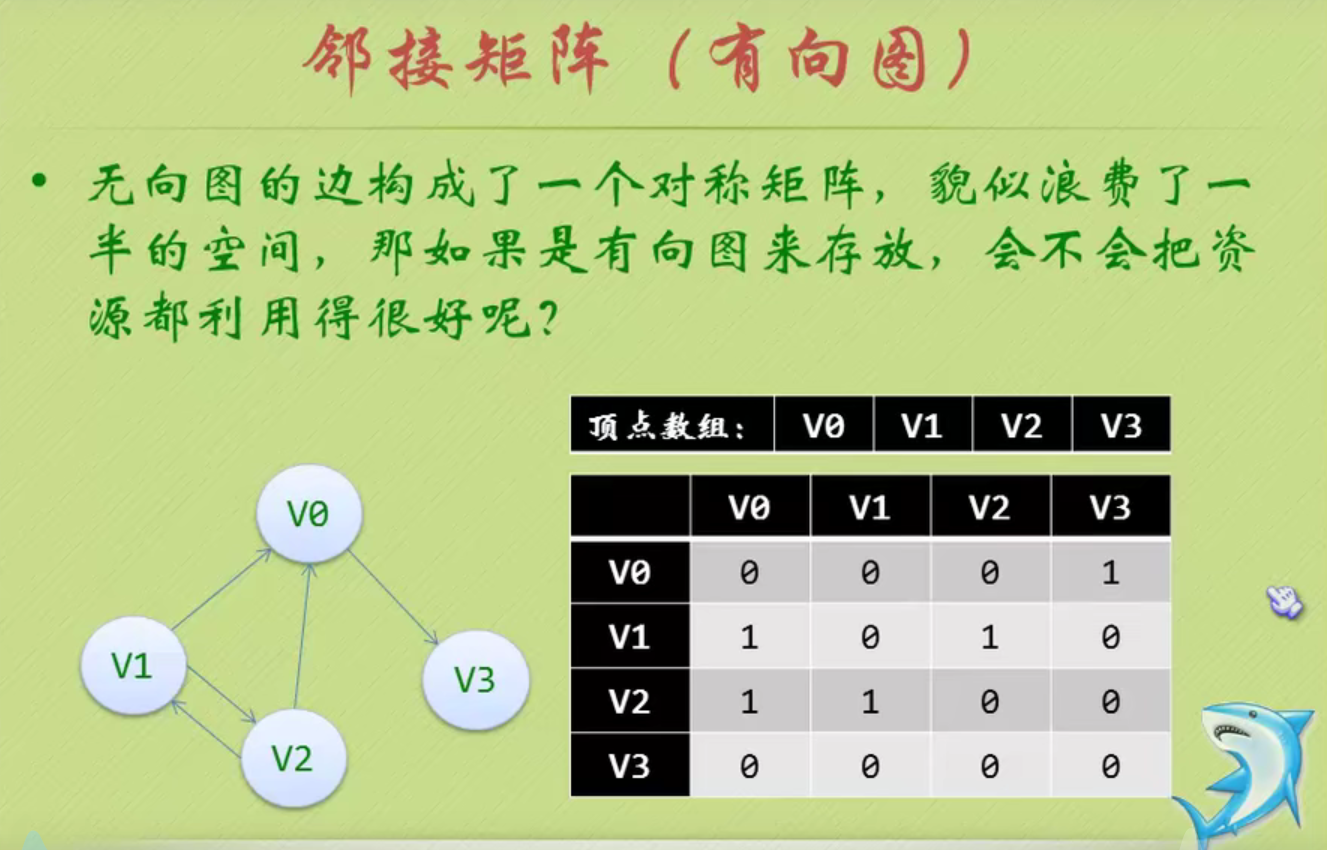

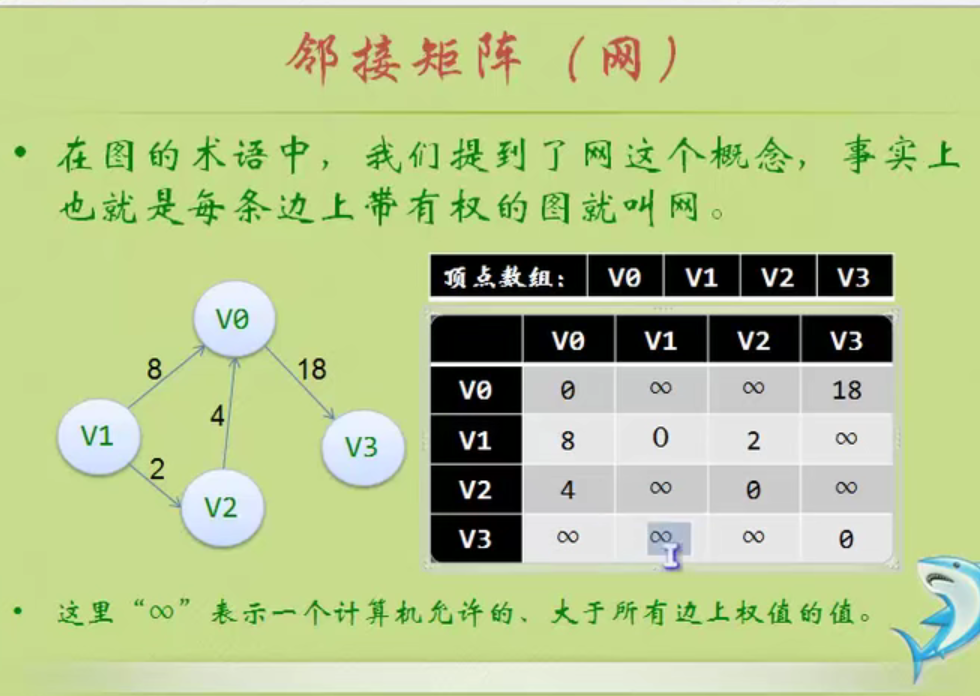

邻接矩阵—无向图和有向图的代码定义
// 时间复杂度为O(n+n^2+e)
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
char flag;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
邻接表
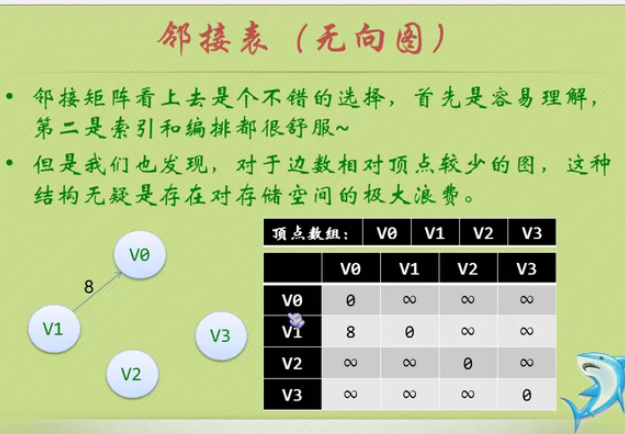

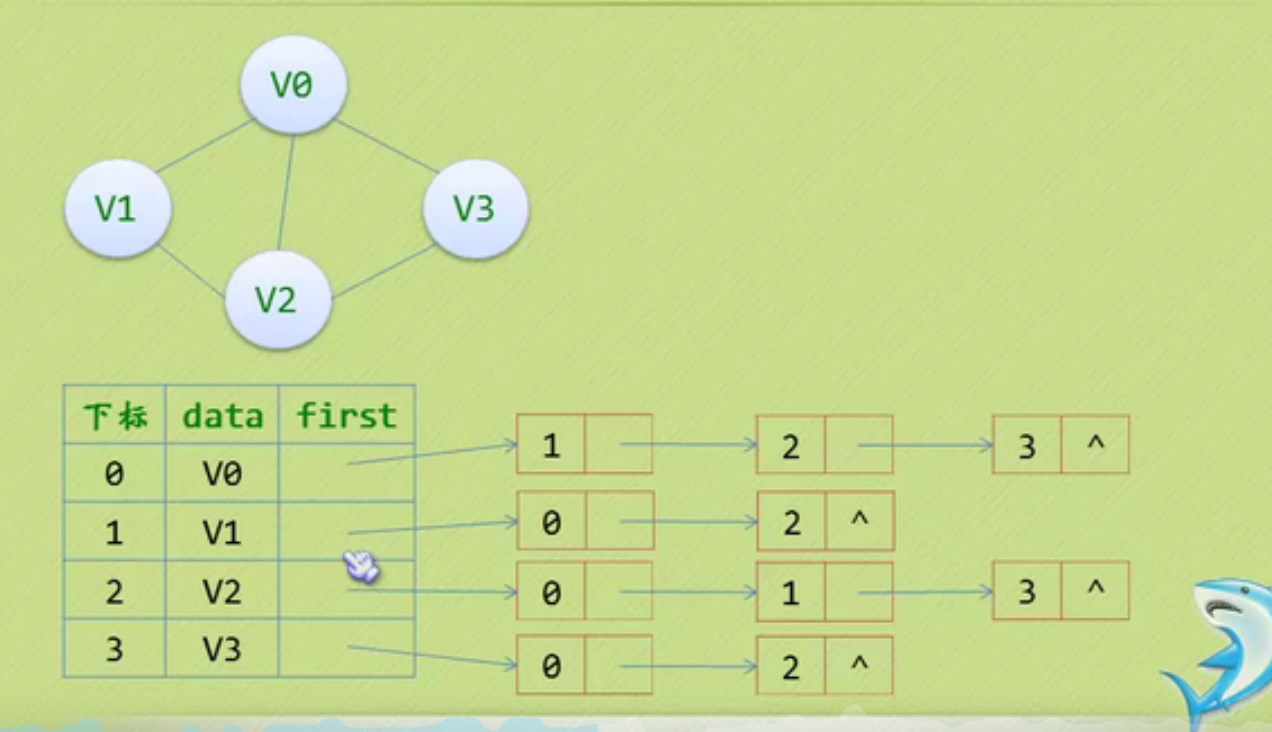
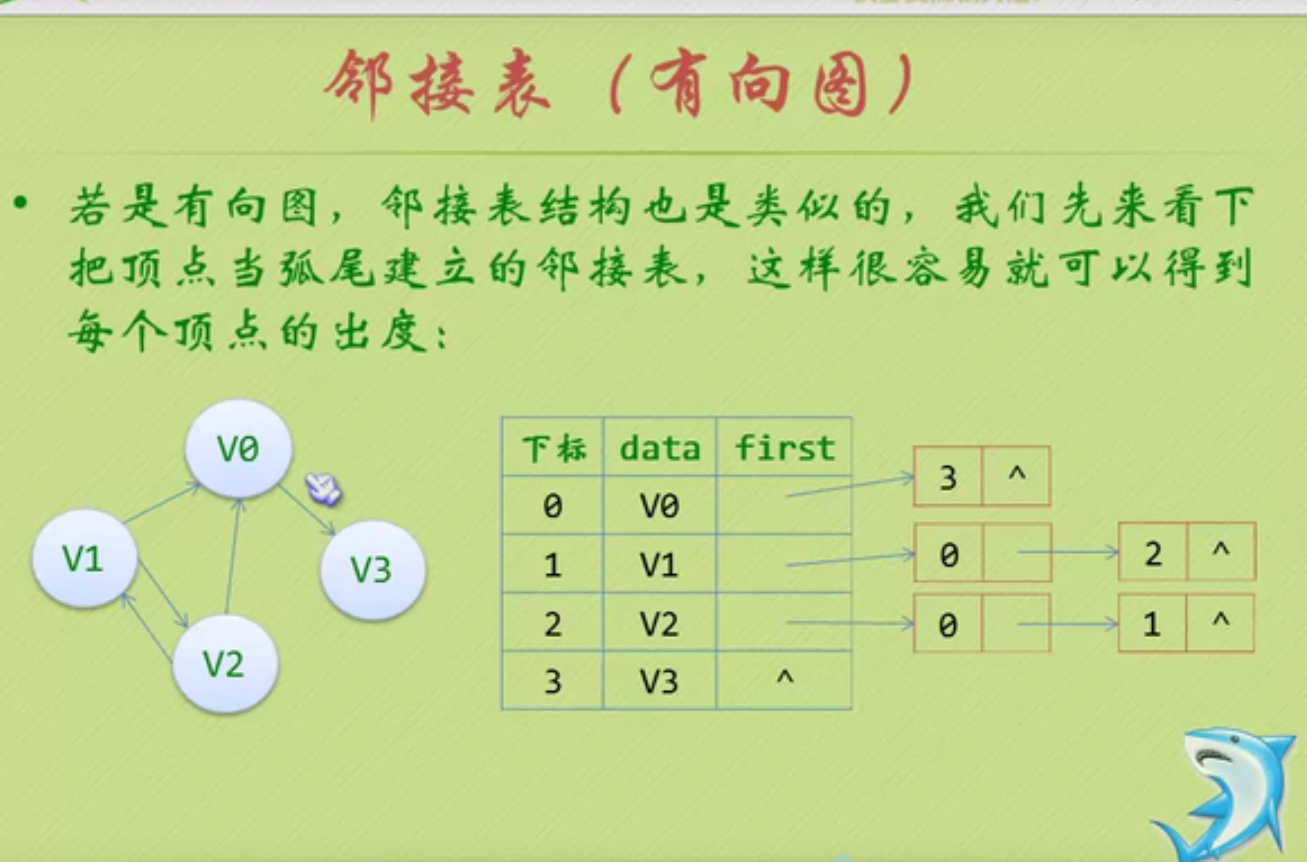
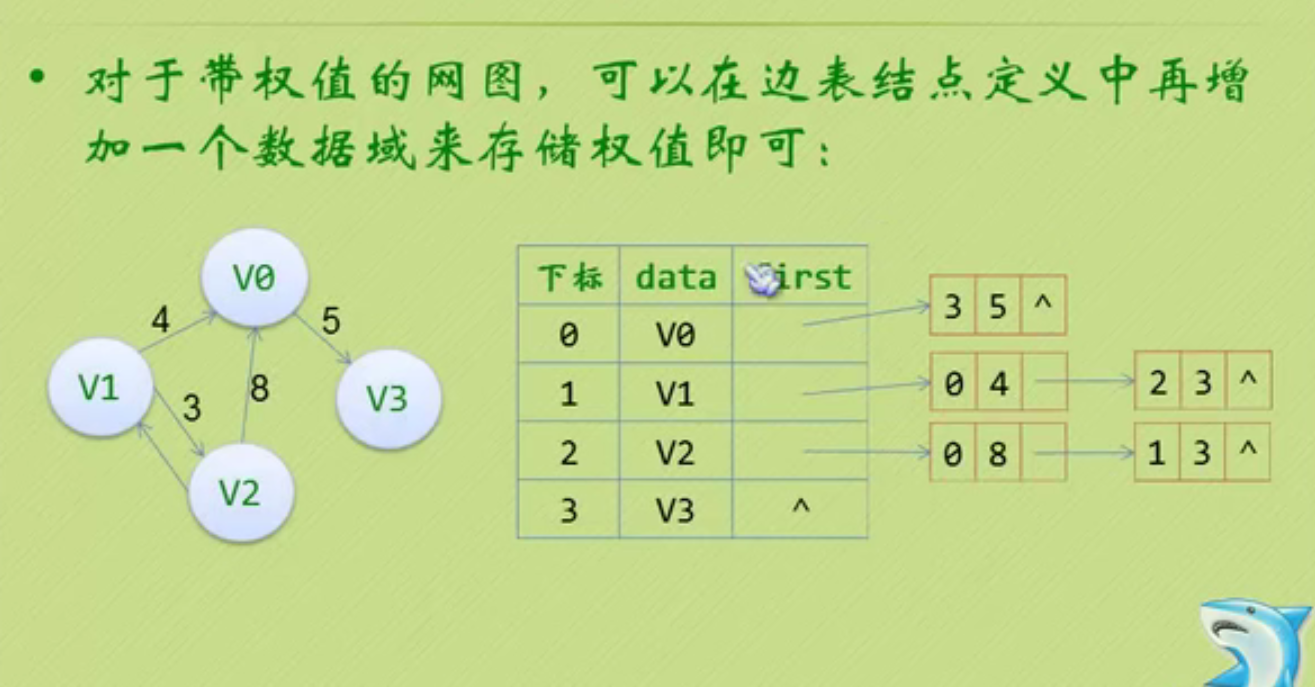
#define MAXVEX 100
//边表节点
typedef struct EdgeTNode
{
int vertx;//邻接顶点
int weight;//权重
EdgeTNode *next;//
}EdgeTNode;
//顶点表节点
typedef struct VertxTNode
{
char data; //顶点域 顶点信息
EdgeTNode *firstedge; // 指向第一个邻接节点
}VertxTNode ,Vertx[MAXVEX];
//整体图
typedef struct
{
Vertx vertx_;
int numVertexes, numEdges; // 图中当前的顶点数和边数
}Graph_LinJieT;
//建立
void CreatLinJie(Graph_LinJieT *G)
{
int i,j ,k;
EdgeTNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0;i<G->numVertexes;i++)
{
G->vertx_[i].firstedge=NULL;//初始化
}
for(k=0;k<G->numEdges;k++)
{
//这里使用的头插,和图中的邻接表是反着来的,但最终也达到了目的
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//i在左边 邻接序号为j
e = (EdgeTNode *)malloc(sizeof(EdgeTNode));
e->vertx=j;
e->next=G->vertx_[i].firstedge;//比如输入(0,1) 1就会指向NULL
G->vertx_[i].firstedge=e;
//若是无向图还得执行下面的语句
//j在左边 邻接序号为i
e = (EdgeTNode *)malloc(sizeof(EdgeTNode));
e->vertx=i;
e->next=G->vertx_[j].firstedge;//比如输入(0,1) 1就会指向NULL
G->vertx_[j].firstedge=e;
}
}
//课本答案:
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G)
{
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
十字链表
首先邻接表有出度,逆邻接表有入度,两个加起来就是十字链表

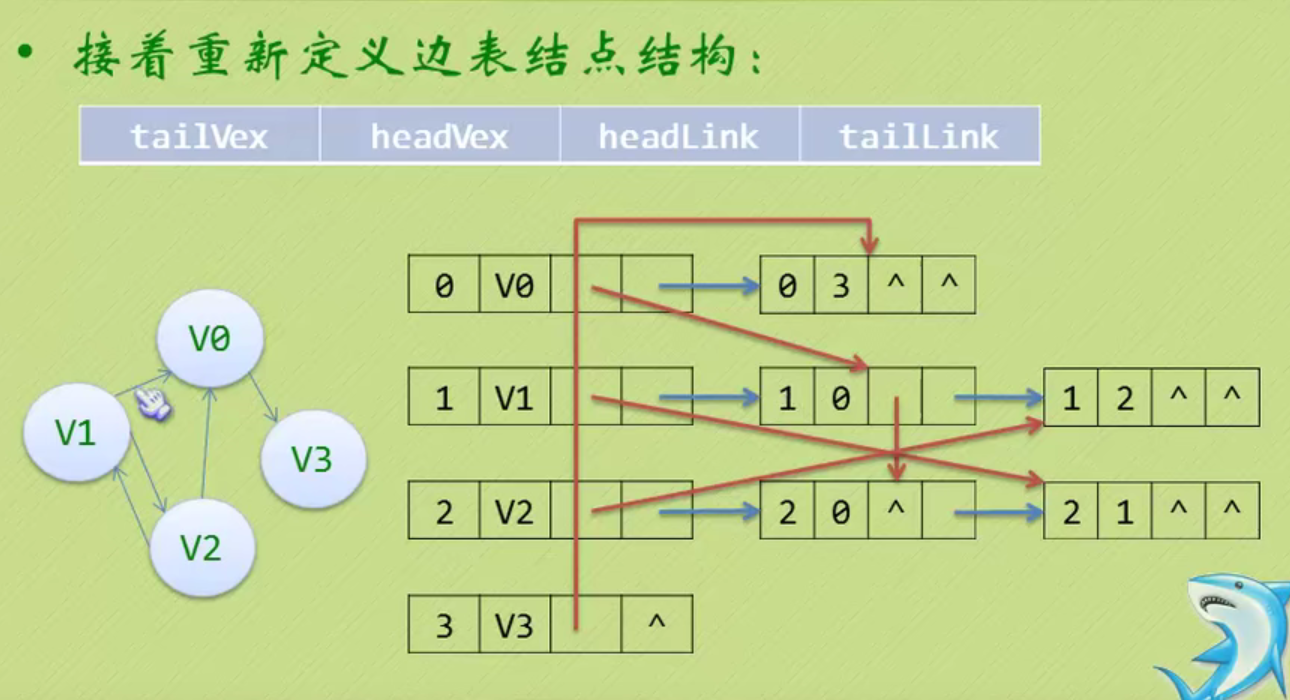
蓝色的代表出度—邻接表
红色的代表入读—逆邻接表


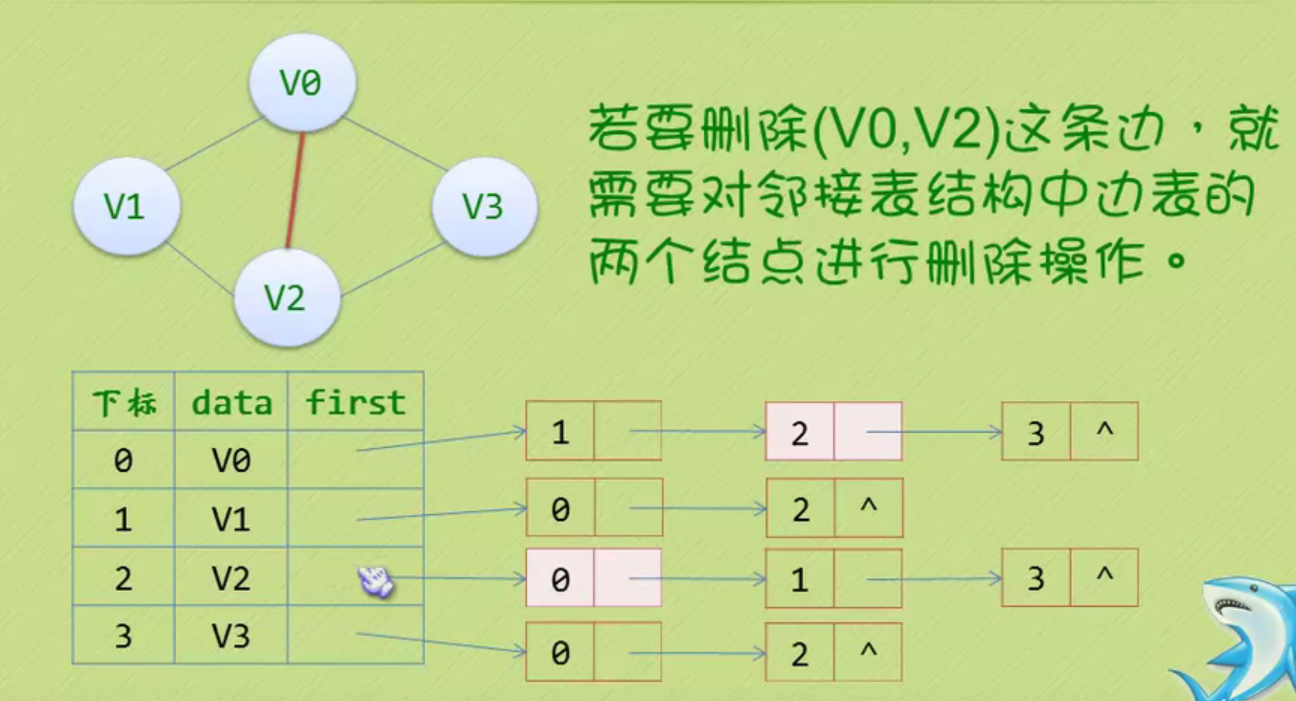
邻接多重表

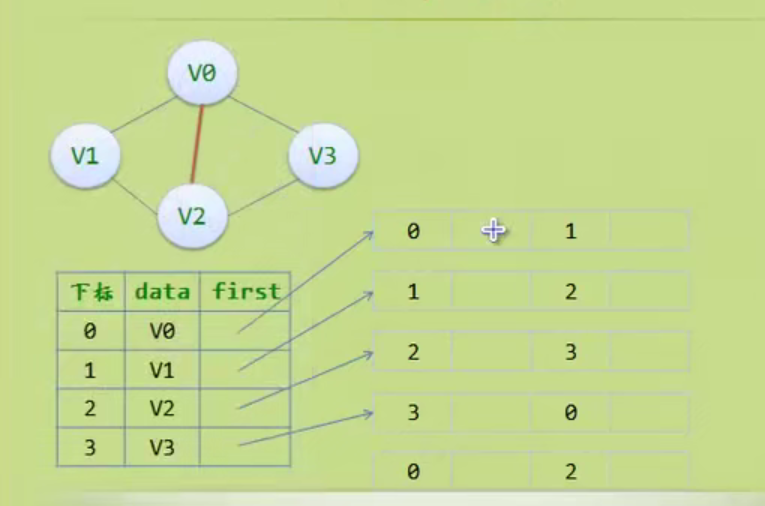
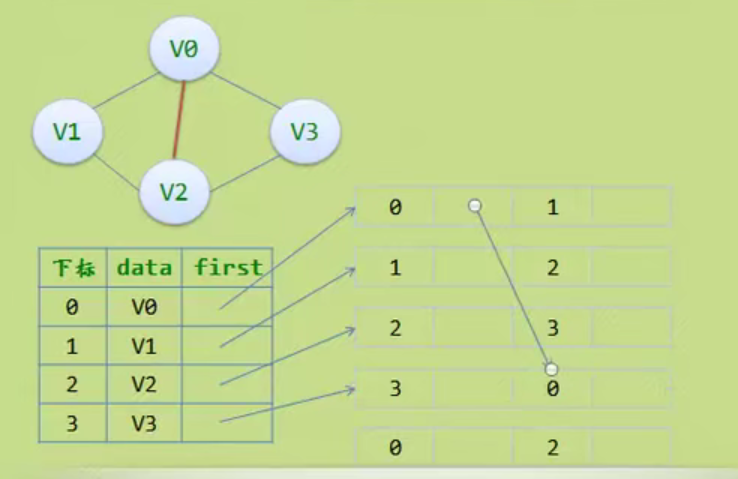

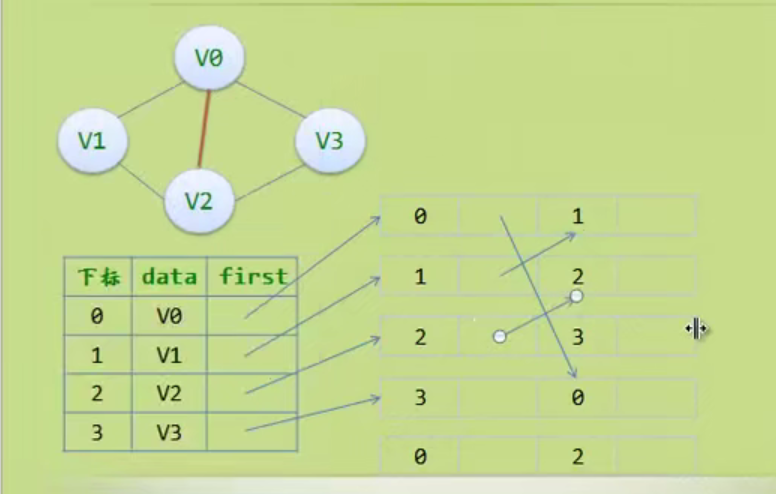
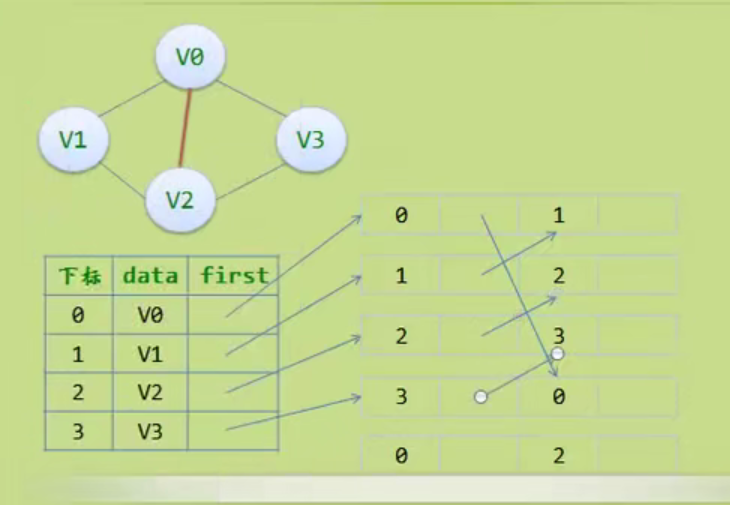
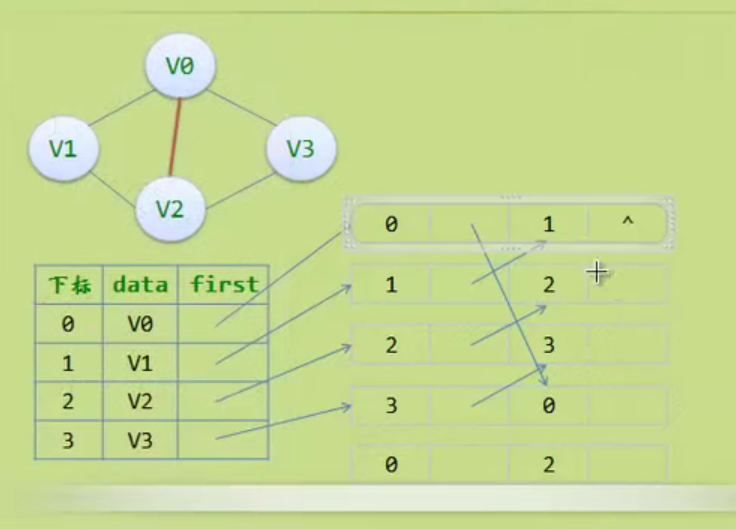
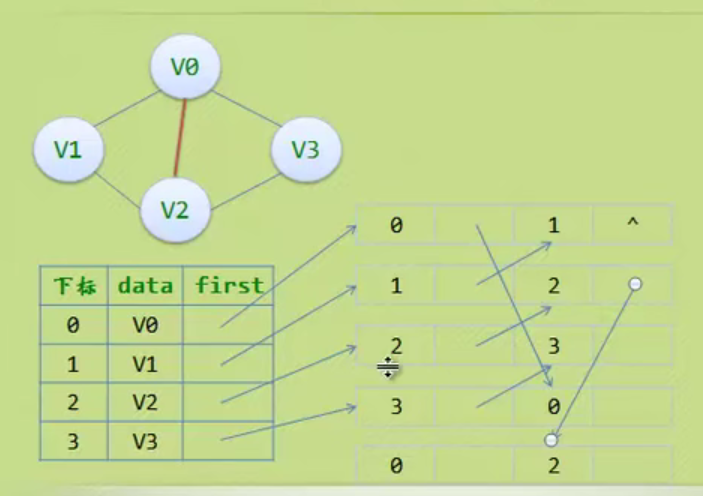
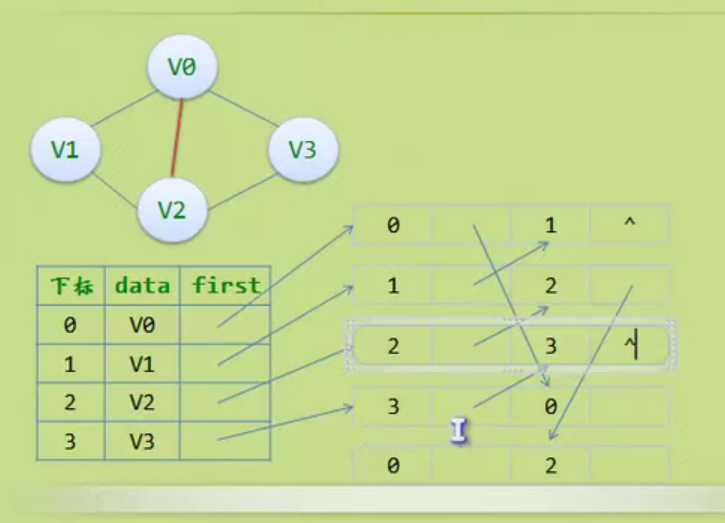

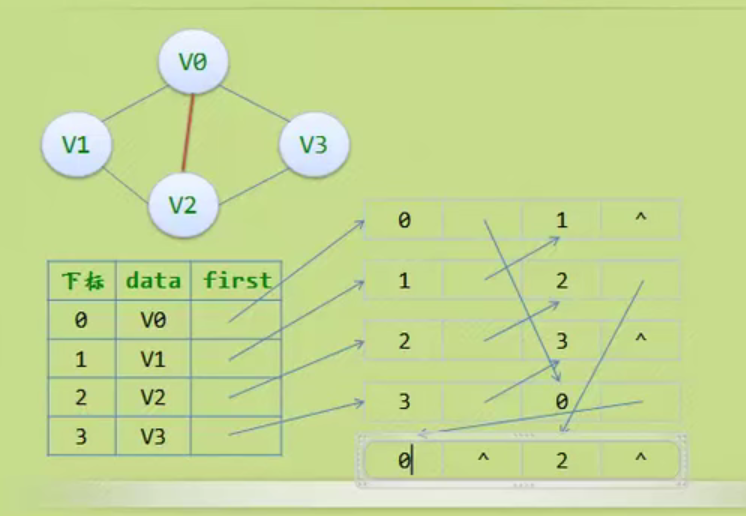
边集数组
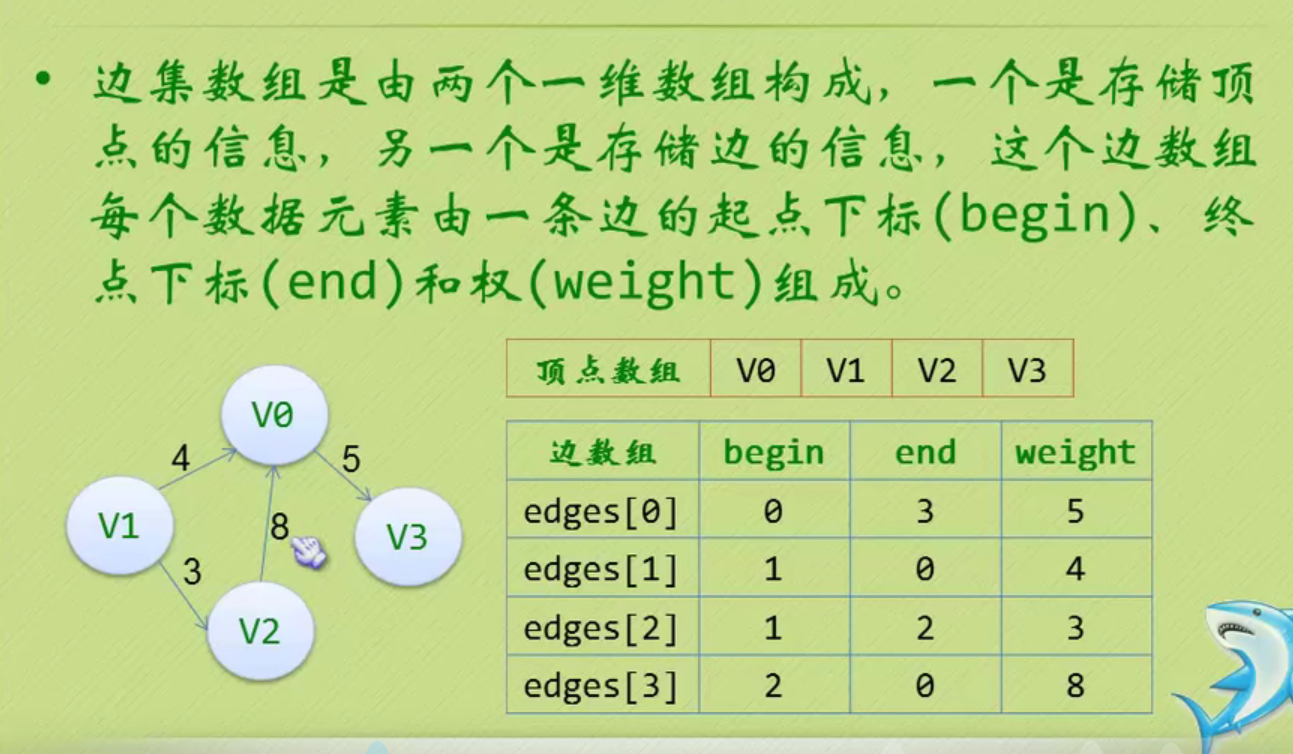
弗洛伊德的冰山理论
图的遍历—深度优先遍历DFS


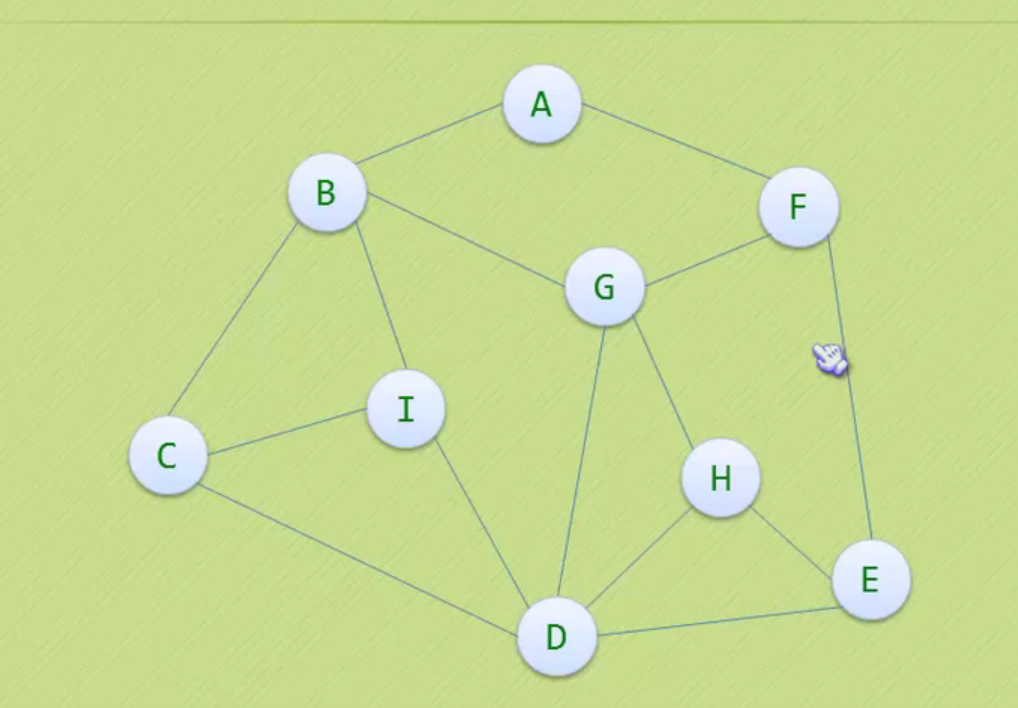

如果在某个点的右边的点已经走过了,那就退到之前的点

行走的路线如下图:
蓝色的是走通的,红色的是访问过的,不能走。
邻接矩阵深度遍历
下面的代码是以邻接矩阵的结构,进行深度遍历
#include <iostream>
using namespace std;
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)//无向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else//有向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
void DFS(MGraph G,int i)
{
visited[i]=true;//已经访问过顶点i
cout<<G.vexs[i]<<endl;//输出访问过的顶点
for(int j=0;j<G.numVertexes;j++)
{
if(G.arc[i][j]==1 && !visited[j])//顶点i与顶点j构成边 且 顶点j没有被访问过
{
DFS(G,j);//递归
}
}
}
邻接表深度遍历
下面的代码是以邻接表的结构,进行深度遍历
#include <iostream>
using namespace std;
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G)
{
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//头插法
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *)malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
//深度遍历 我们以邻接表的规则来遍历
void DFS(GraphAdjList GL,int i)
{
EdgeNode *e;
visited[i]= true;//表示已经访问过了
cout<<GL.adjList[i].data<<endl;//输出访问过的顶点
//这段循环来遍历和顶点i相邻的边
while(e)
{
if(!visited[e->adjvex]);
{
DFS(GL,e->adjvex);
}
e=e->next;//e指向下一个与i相邻的顶点
}
}
void DFSTraverse(GraphAdjList GL)
{
for(int i=0;i<GL.numVertexes;i++)
{
visited[i]=FALSE;//都默认为0
}
//遍历所有顶点
for(int i=0;i<GL.numVertexes;i++)
{
if(!visited[i])// 初始化所有顶点状态都是未访问过状态 没有访问过才能进行下去
{
DFS(GL,i); 若是连通图,只会执行一次 这个点没有访问过
}
}
}
骑士周游问题


#include <iostream>
#include <ctime>
#include "stdio.h"
using namespace std;
//棋盘 8 x 8
#define X 8
#define Y 8
//棋盘
int chess[X][Y];
/**
* 基于找到(x,y)位置的下一个可走的情况
* @param x
* @param y
* @param count
* @return
*/
int nextxy(int *x,int *y,int count)
{
//八种走法
switch (count)
{
case 0:
if(*x+2<=X-1 && *y-1>=0 &&chess[*x+2][*y-1]==0)//往右跳,要在棋盘范围内 判断的是3这个位置 且这个位置没有遍历过
{
*x = *x + 2;
*y = *y - 1;
return 1;
}
break;
case 1:
if(*x+2<=X-1 && *y+1<=Y-1 &&chess[*x+2][*y+1]==0) //判断的是4这个位置
{
*x = *x + 2;
*y = *y + 1;
return 1;
}
break;
case 2:
if(*x+1<=X-1 && *y-2>=0 &&chess[*x+1][*y-2]==0) //判断的是2这个位置
{
*x = *x + 1;
*y = *y - 2;
return 1;
}
break;
case 3:
if(*x+1<=X-1 && *y+2<=Y-1 &&chess[*x+1][*y+2]==0) //判断的是5这个位置
{
*x = *x + 1;
*y = *y + 2;
return 1;
}
break;
case 4:
if(*x-2>=0 && *y-1>=0 &&chess[*x-2][*y-1]==0) //判断的是8这个位置
{
*x = *x - 2;
*y = *y - 1;
return 1;
}
break;
case 5:
if(*x-2>=0 && *y+1<=Y-1 && chess[*x-2][*y+1]==0) //判断的是7这个位置
{
*x = *x - 2;
*y = *y + 1;
return 1;
}
break;
case 6:
if(*x-1>=0 && *y-2>=0 && chess[*x-1][*y-2]==0) //判断的是1这个位置
{
*x = *x - 1;
*y = *y - 2;
return 1;
}
break;
case 7:
if(*x-1>=0 && *y+2<=Y-1 &&chess[*x-1][*y+2]==0) //判断的是6这个位置
{
*x = *x - 1;
*y = *y + 2;
return 1;
}
break;
default:
break;
}
return 0;
}
/**
* 打印棋盘
*/
void print()
{
int i,j;
for(i=0;i<X;i++)
{
for(j=0;j<Y;j++)
{
printf("%2d\t", chess[i][j]);
}
cout<<endl;
}
cout<< endl;
}
/**
* 深度优先遍历棋盘
* (x,y)为起始位置
* @param x
* @param y
* @param tag 标记变量 每走一步tag+1
* @return
*/
int TravelChessBoard(int x,int y,int tag)
{
int x1=x,y1=y,flag=0,count=0;
chess[x][y]=tag;
if(tag == X*Y)
{
//打印棋盘
print();
return 1;
}
//找到马下一个可走的坐标(x1,y1),如果找到 flag=1,否则为0
flag= nextxy(&x1,&y1,count);//找到可行的下一个位置
//这里的while是为了保证第一次能走到下一个位置
while(flag==0 && count<7)//就是在nextxy()函数里面 当有些位置已经走过了,它会返回0 这时候让count++ 尝试另一个可走的下一个位置
{
count++;
flag= nextxy(&x1,&y1,count);
}
while(flag)//表示找到了当前位置的下一个可走的位置
{
if(TravelChessBoard(x1,y1,tag+1))
{
return 1;
}
//如果按照第一个x1 y1走的话,一直走到后面有重复的话,那就返回到最开始,重新找马的下一步
//找到马下一个可走的坐标(x1,y1),如果找到 flag=1,否则为0
x1=x;
y1=y;
count++;
//这里是接着上面继续往下一个走
flag= nextxy(&x1,&y1,count);
while(flag==0 && count<7)
{
count++;
flag= nextxy(&x1,&y1,count);
}
}
if(0==flag)
{
chess[x][y]=0;//重新寻找
}
return 0;
}
void test_KinghtTraverse()
{
int i,j;
clock_t start, finish;
start =clock();
for(i=0;i<X;i++)
{
for(j=0;j<Y;j++)
{
chess[i][j]=0;
}
}
if(!TravelChessBoard(2,0,1))//起始位置 第二行第0列
{
cout<<"抱歉,马踏棋盘失败!!!"<<endl;
}
finish=clock();
cout<<"本次计算一共耗时:"<<(double )(finish-start)/CLOCKS_PER_SEC<<"s"<<endl;//CPU滴哒的次数除以每分钟的CPU滴答数就是秒
}
int main() {
test_KinghtTraverse();
return 0;
}
马的起始位置 第二行第0列
运行结果:
广度优先遍历BFS

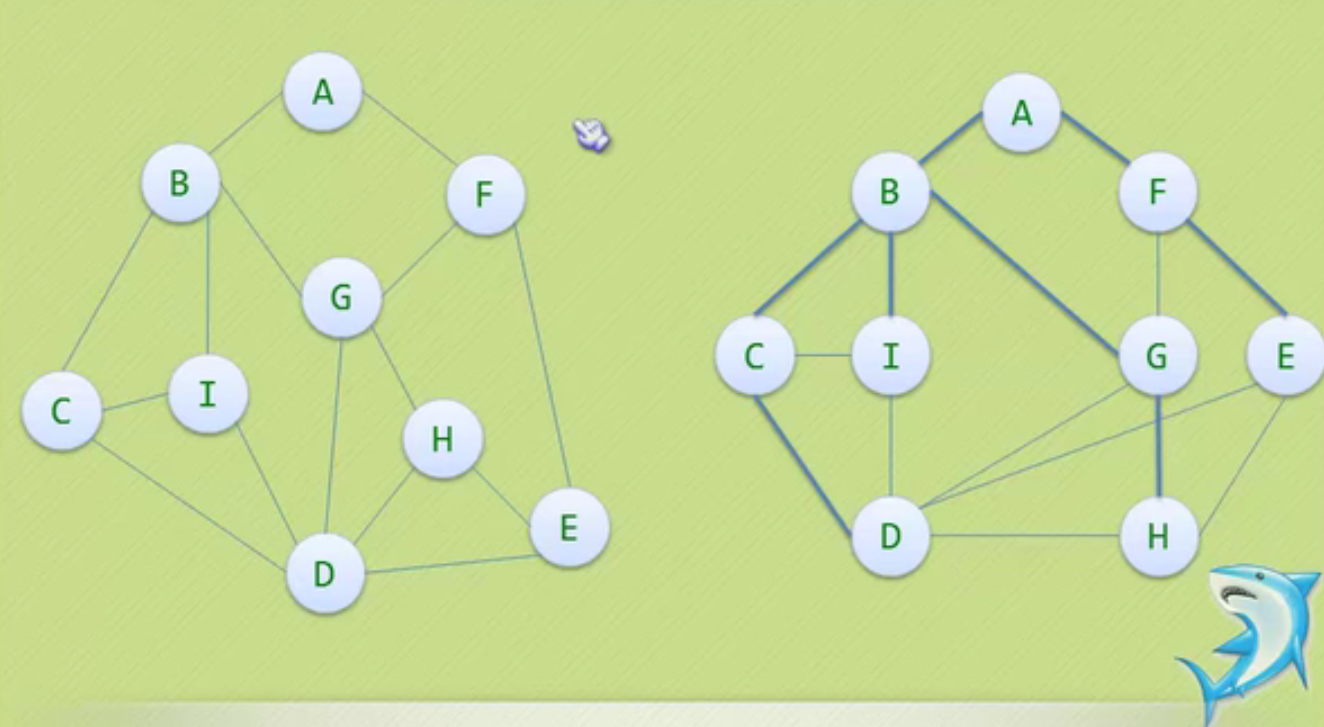
从右图来解释,
我们从A开始,以右边优先原则,先走到B,然后F,因为对于A来说,B F 最近。
因此遍历顺序是ABF CIGE DH
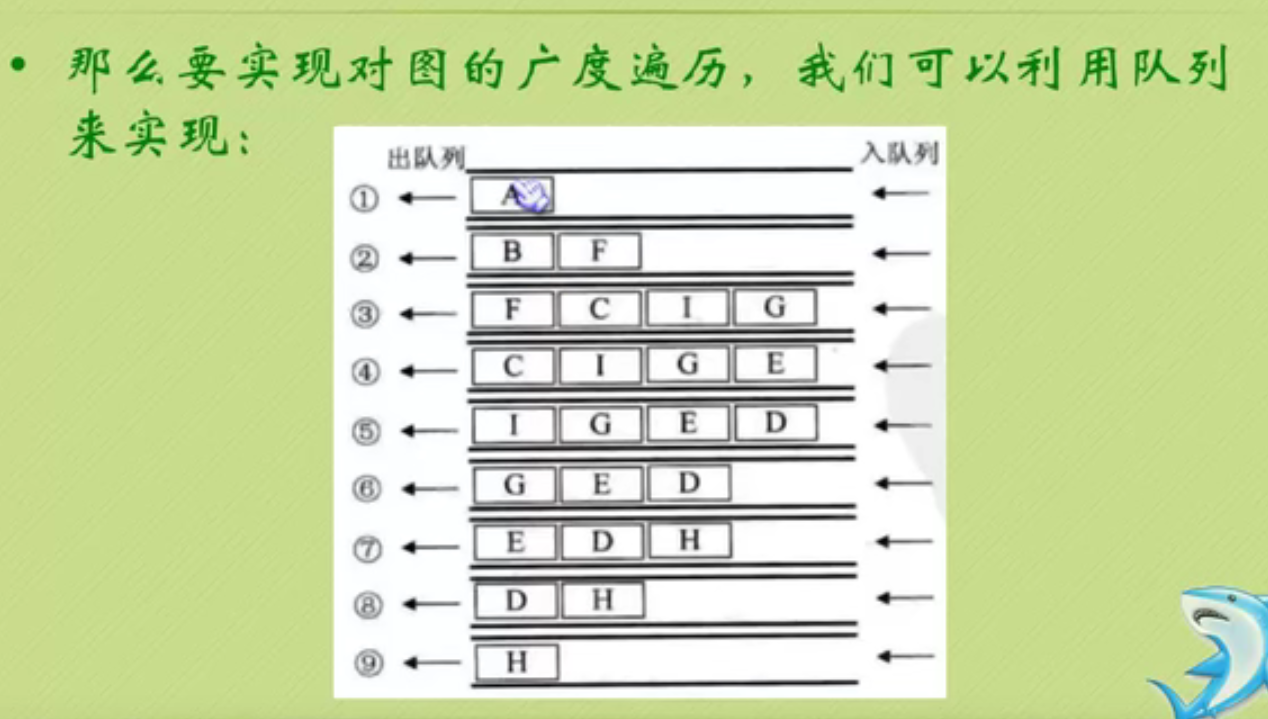
先进先出
邻接矩阵—-广度遍历
//邻接矩阵广度遍历
namespace LinJieMatrix
{
#include <iostream>
using namespace std;
#define MAXVEX 100 // 最大顶点数
#define INFINITY 65535 // 用65535来代表无穷大
typedef struct
{
char vexs[MAXVEX]; // 顶点表
int arc[MAXVEX][MAXVEX]; // 邻接矩阵
int numVertexes, numEdges; // 图中当前的顶点数和边数
} MGraph;
// 建立无向网图的邻接矩阵
void CreateMGraph(MGraph *G)
{
int i, j, k, w;
int flag;
printf("请输入是生成无向还是有向,无向输入0,有向输入1:\n");
cin>>flag;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
for( i=0; i < G->numVertexes; i++ )
{
scanf("%c", &G->vexs[i]);
}
for( i=0; i < G->numVertexes; i++ )
{
for( j=0; j < G->numVertexes; j++ )
{
G->arc[i][j] = INFINITY; // 邻接矩阵初始化
}
}
if(flag==0)//无向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
G->arc[j][i] = G->arc[i][j]; // 是无向网图,对称矩阵
}
}
else//有向
{
for( k=0; k < G->numEdges; k++ )
{
printf("请输入边(Vi,Vj)上的下标i,下标j和对应的权w:\n"); // 这只是例子,提高用户体验需要进行改善
scanf("%d %d %d", &i, &j, &w);
G->arc[i][j] = w;
}
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
// 邻接矩阵的广度遍历算法
void BFSTraverse(MGraph G)
{
int i, j;
Queue Q;
for( i=0; i < G.numVertexes; i++ )
{
visited[i] = FALSE;
}
initQueue( &Q );//初始化队列
for( i=0; i < G.numVertexes; i++ )
{
if( !visited[i] )
{
printf("%c ", G.vexs[i]);
visited[i] = TRUE;
EnQueue(&Q, i);//进入队列
while( !QueueEmpty(Q) )
{
DeQueue(&Q, &i);//出队列
//遍历与顶点i邻接的顶点
for( j=0; j < G.numVertexes; j++ )
{
if( G.arc[i][j]==1 && !visited[j] )//j为i的邻接顶点
{
printf("%c ", G.vexs[j]);
visited[j] = TRUE;
EnQueue(&Q, j);//入队列
}
}
}
}
}
}
}
邻接表—广度遍历
//邻接表广度遍历
namespace LinJieTable_BFS {
#include <iostream>
using namespace std;
#define MAXVEX 100
typedef struct EdgeNode // 边表结点
{
int adjvex; // 邻接点域,存储该顶点对应的下标
int weight; // 用于存储权值,对于非网图可以不需要
struct EdgeNode *next; // 链域,指向下一个邻接点
} EdgeNode;
typedef struct VertexNode // 顶点表结点
{
char data; // 顶点域,存储顶点信息
EdgeNode *firstEdge; // 边表头指针
} VertexNode, AdjList[MAXVEX];
typedef struct {
AdjList adjList;
int numVertexes, numEdges; // 图中当前顶点数和边数
} GraphAdjList;
// 建立图的邻接表结构
void CreateALGraph(GraphAdjList *G) {
int i, j, k;
EdgeNode *e;
printf("请输入顶点数和边数:\n");
scanf("%d %d", &G->numVertexes, &G->numEdges);
// 读取顶点信息,建立顶点表
for (i = 0; i < G->numVertexes; i++) {
scanf("%c", &G->adjList[i].data);
G->adjList[i].firstEdge = NULL; // 初始化置为空表
}
//这里是无向图
for (k = 0; k < G->numEdges; k++) {
printf("请输入边(Vi,Vj)上的顶点序号:\n");
scanf("%d %d", &i, &j);
//头插法
e = (EdgeNode *) malloc(sizeof(EdgeNode));
e->adjvex = j; // 邻接序号为j
e->next = G->adjList[i].firstEdge;
G->adjList[i].firstEdge = e;
e = (EdgeNode *) malloc(sizeof(EdgeNode));
e->adjvex = i; // 邻接序号为i
e->next = G->adjList[j].firstEdge;
G->adjList[j].firstEdge = e;
}
}
#define TRUE 1
#define FALSE 0
#define MAX 256
typedef int Boolean; // 这里我们定义Boolean为布尔类型,其值为TRUE或FALSE
Boolean visited[MAX]; // 访问标志的数组
//广度遍历 我们以邻接表的规则来遍历
void BFS(GraphAdjList G) {
int i, j;
Queue Q;//队列
for (i = 0; i < G.numVertexes; i++) {
visited[i] = FALSE;
}
initQueue(&Q);//初始化队列
for (i = 0; i < G.numVertexes; i++) {
if (!visited[i]) {
printf("%c ", G.adjList[i].data);
visited[i] = TRUE;
EnQueue(&Q, i);//进入队列
while (!QueueEmpty(Q)) {
DeQueue(&Q, &i);//出队列
//遍历与顶点i邻接的顶点
for (j = 0; j < G.numVertexes; j++) {
EdgeNode *e;//邻接边节点
e = G.adjList[i].firstEdge;//e指向i的邻接边节点
if (e && !visited[e->adjvex])//e->adjvex就是顶点j
{
printf("%c ", e->adjvex);
visited[e->adjvex] = TRUE;
EnQueue(&Q, e->adjvex);//入队列
}
e = e->next;//指向下一个与i的邻接边节点
}
}
}
}
}
}
带权最小生成树
普里姆算法
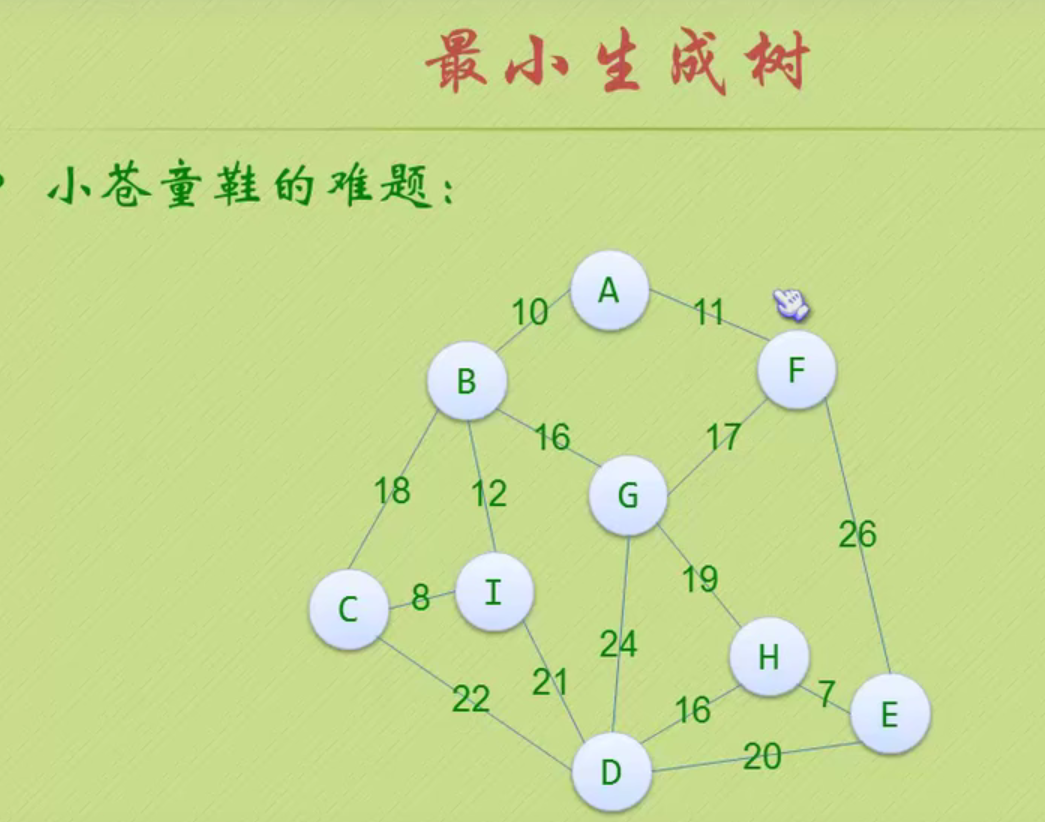
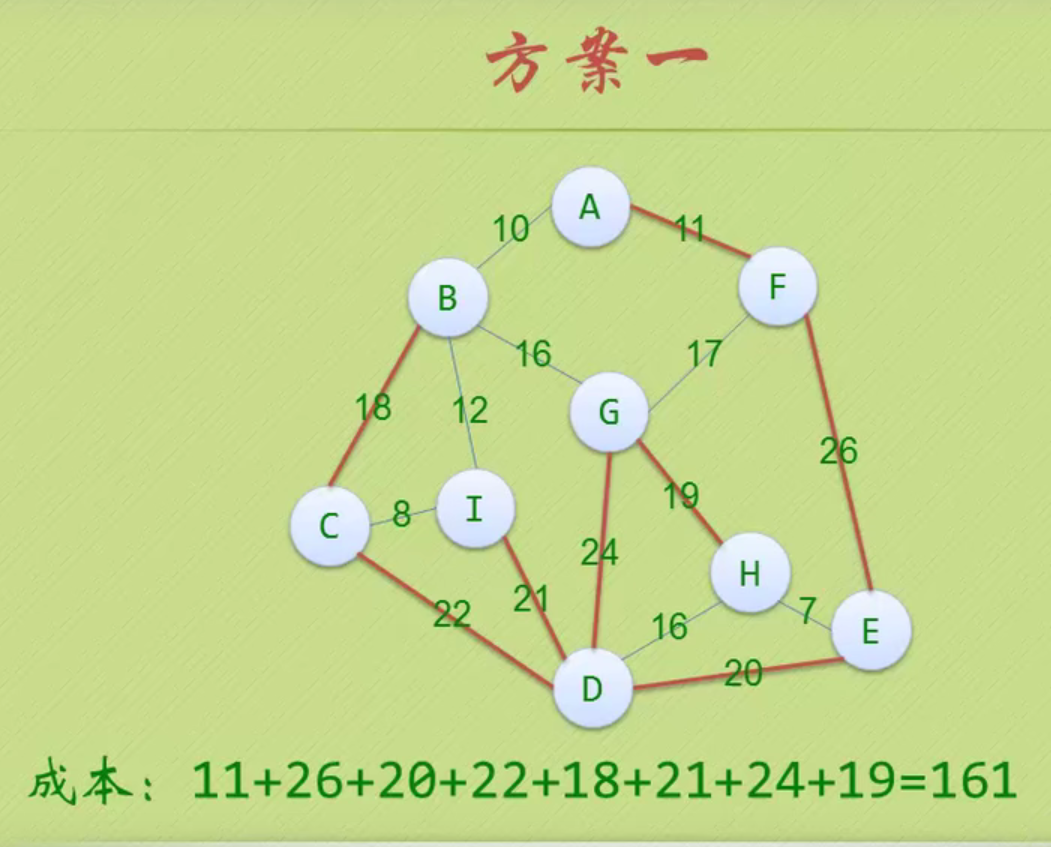


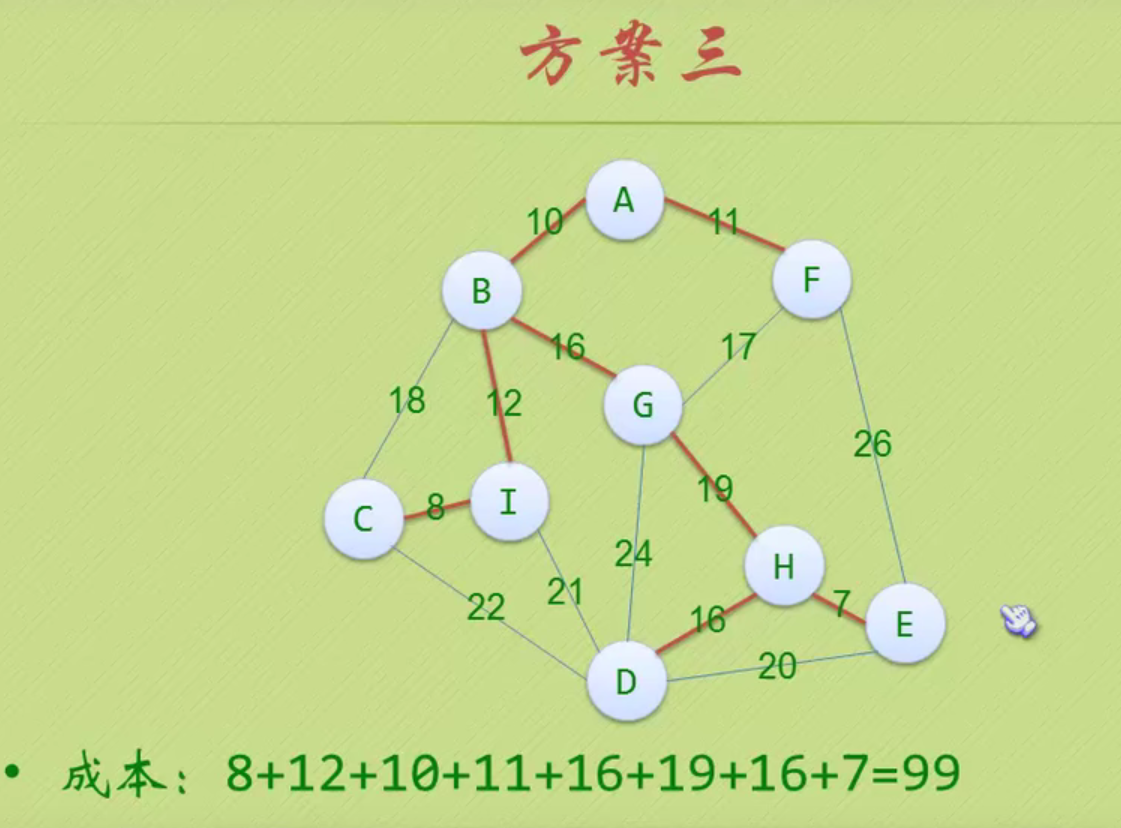
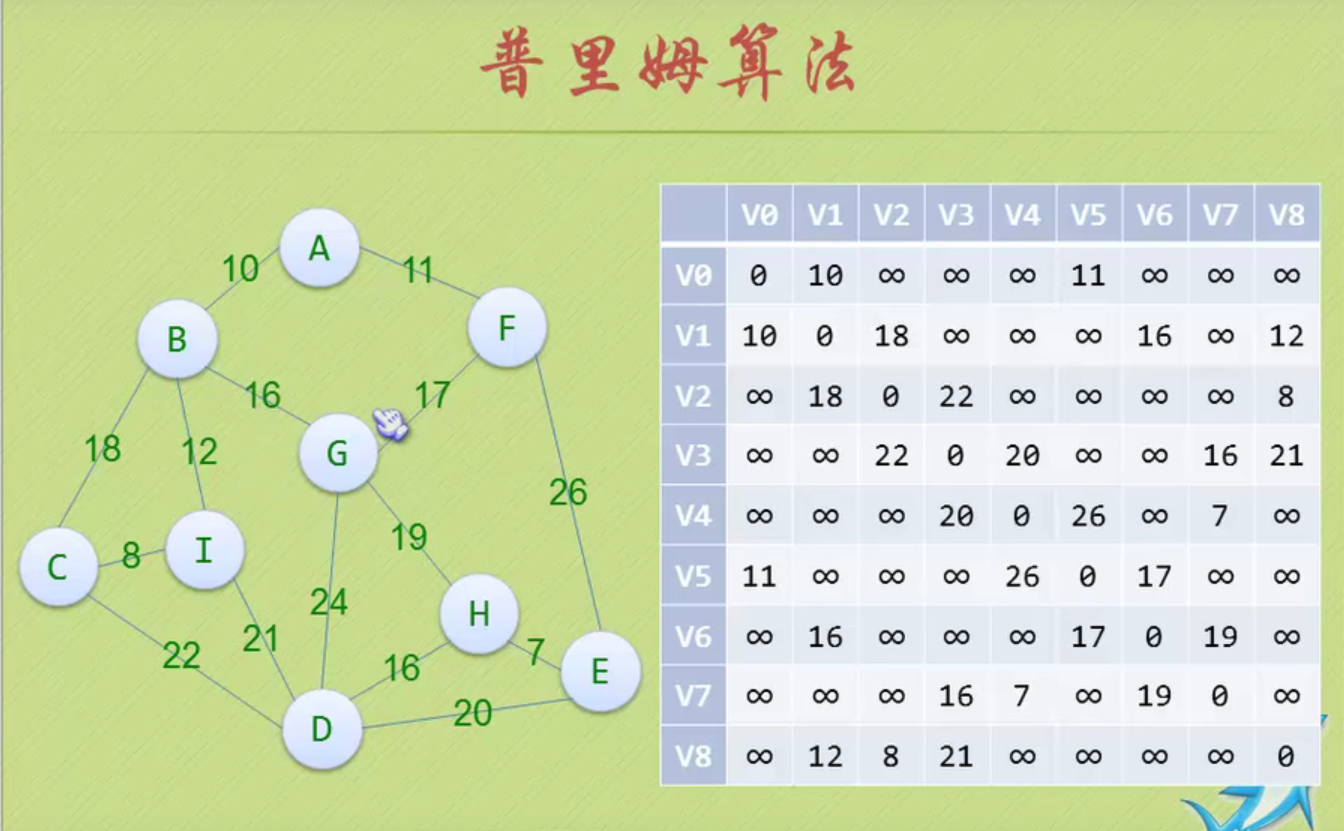
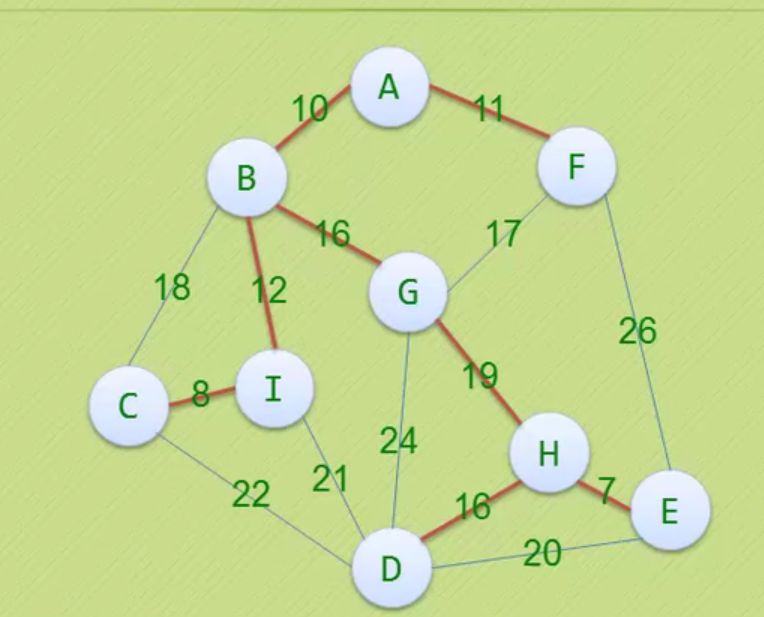
以PPT为例
下标: 0 1 2 3 4 5 6 7 8
初始化:lowcost[]: 0 10 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
每次循环都从下标1开始
--------------
第一次循环:
min=10
k=1
输出:(0,1) 也就是(A,B)
lowcost[1]=0 表示B这个点访问过了。
下标: 0 1 2 3 4 5 6 7 8
lowcost[]: 0 0 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 ∞ ∞ ∞ 11 ∞ ∞ ∞ -----权重
10 0 18 ∞ ∞ ∞ 16 ∞ 12
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 0 0 0 0 0 0 0 ------顶点与顶点的关系 比如: [0 0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
更新 lowcost[] adjvex[]
lowcost[]: 0 0 18 ∞ ∞ 11 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 0 0 1 0 1
--------------
--------------
第二次循环
min=11
k=5
输出:(0,5)也就是(A,F)
lowcost[5]=0 表示F这个点访问过了。
lowcost[]: 0 0 18 ∞ ∞ 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 0 0 1 0 1
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 18 ∞ ∞ 0 16 ∞ 12 -----权重
11 ∞ ∞ ∞ 26 0 17 ∞ ∞
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 1 0 0 0 1 0 1
更新 lowcost[] adjvex[]
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 5 0 1 0 1
--------------
--------------
第三次循环
min=12
k=8
输出:(1,8)也就是(B,I)
lowcost[8]=0 表示I这个点访问过了。
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
adjvex[]: 0 0 1 0 5 0 1 0 1
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 18 ∞ 26 0 16 ∞ 12 -----权重
∞ 12 8 21 ∞ ∞ ∞ ∞ 0
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 1 0 5 0 1 0 1
更新 lowcost[] adjvex[]
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 8 8 5 0 1 0 8
--------------
--------------
第四次循环
min=8
k=2
输出:(8,2)也就是(I,C)
lowcost[2]=0 表示C这个点访问过了。
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 8 8 5 0 1 0 8
邻接矩阵 k行 逐个遍历全部顶点
lowcost[]: 0 0 8 21 26 0 16 ∞ 0 -----权重
∞ 18 0 22 ∞ ∞ ∞ ∞ 8
两个从下标1开始 进行比较 把小的值赋给lowcost[],同时adjvex[j] = k j代表列 代表行
adjvex[]: 0 0 8 8 5 0 1 0 8
更新 lowcost[] adjvex[]
lowcost[]: 0 0 0 21 26 0 16 ∞ 0 -----权重
adjvex[]: 0 0 2 8 5 0 1 0 8
--------------
--------------
第五次循环
min=16
k=6
输出:(1,6)也就是(B,G)
以此类推
源码如下:
// Prim算法生成最小生成树 是以邻接矩阵为结构
void MiniSpanTree_Prim(MGraph G)
{
int min, i, j, k;
int adjvex[MAXVEX]; // 保存相关顶点下标 比如[0 0 1 0 0 0 1 2]表示第第三个顶点、第七个顶点与第一个顶点有联系 ,第八个顶点与第二个顶点有联系
int lowcost[MAXVEX]; // 保存相关顶点间边的权值
lowcost[0] = 0; // V0作为最小生成树的根开始遍历,权值为0
adjvex[0] = 0; // V0第一个加入
// 初始化操作
for( i=1; i < G.numVertexes; i++ )
{
lowcost[i] = G.arc[0][i]; // 将邻接矩阵第0行所有权值先加入数组
adjvex[i] = 0; // 初始化全部先为V0的下标
}
//以PPT为例
//至此 lowcost[]里面的值是 0 10 INFINITY INFINITY INFINITY 11 INFINITY INFINITY INFINITY
// 真正构造最小生成树的过程
for( i=1; i < G.numVertexes; i++ )
{
min = INFINITY; // 初始化最小权值为65535等不可能数值
j = 1;
k = 0;
// 遍历全部顶点
while( j < G.numVertexes )
{
// 找出lowcost数组已存储的最小权值
if( lowcost[j]!=0 && lowcost[j] < min )// lowcost[j]!=0表示不让自己指向自己
{
min = lowcost[j];//找到最小的那个权值
k = j; // 将发现的最小权值的下标存入k,以待使用。k=1 k=5
}
j++;
}
// 打印当前顶点边中权值最小的边
printf("(%d,%d)", adjvex[k], k);//
lowcost[k] = 0; // 将当前顶点的权值设置为0,表示此顶点已经完成任务,进行下一个顶点的遍历
//对于顶点A来说,权值最小的边是B顶点 所以k=1
// 邻接矩阵k行逐个遍历全部顶点
//对于已经走过了的顶点间的边就设为0 更新顶点与顶点之间的联系
for( j=1; j < G.numVertexes; j++ )
{
//比较与k这个顶点相连顶点的权值与上一顶点相关连顶点的权值
if( lowcost[j]!=0 && G.arc[k][j] < lowcost[j] )
{
lowcost[j] = G.arc[k][j];//更新权重 选最小的权 权重的下标就代表着顶点的标号
// 这一步是最关键的,这里更新权重它是这样的原则,我们把第k个顶点与其他顶点边的权重拿出,与原来的权重数组做对比,选小的那个以更新权重数组 为了能够到达第j个顶点是最小的权重
adjvex[j] = k; //更新顶点与顶点之间的联系
//之后会在下一次大循环中用到更新的权重数组,再选最小的那个顶点 而且此时adjvex也是更新过的 ,那么第k个顶点到第adjvex[k]个顶点就是最小权重最小权重
}
}
}
}
克鲁斯卡尔算法
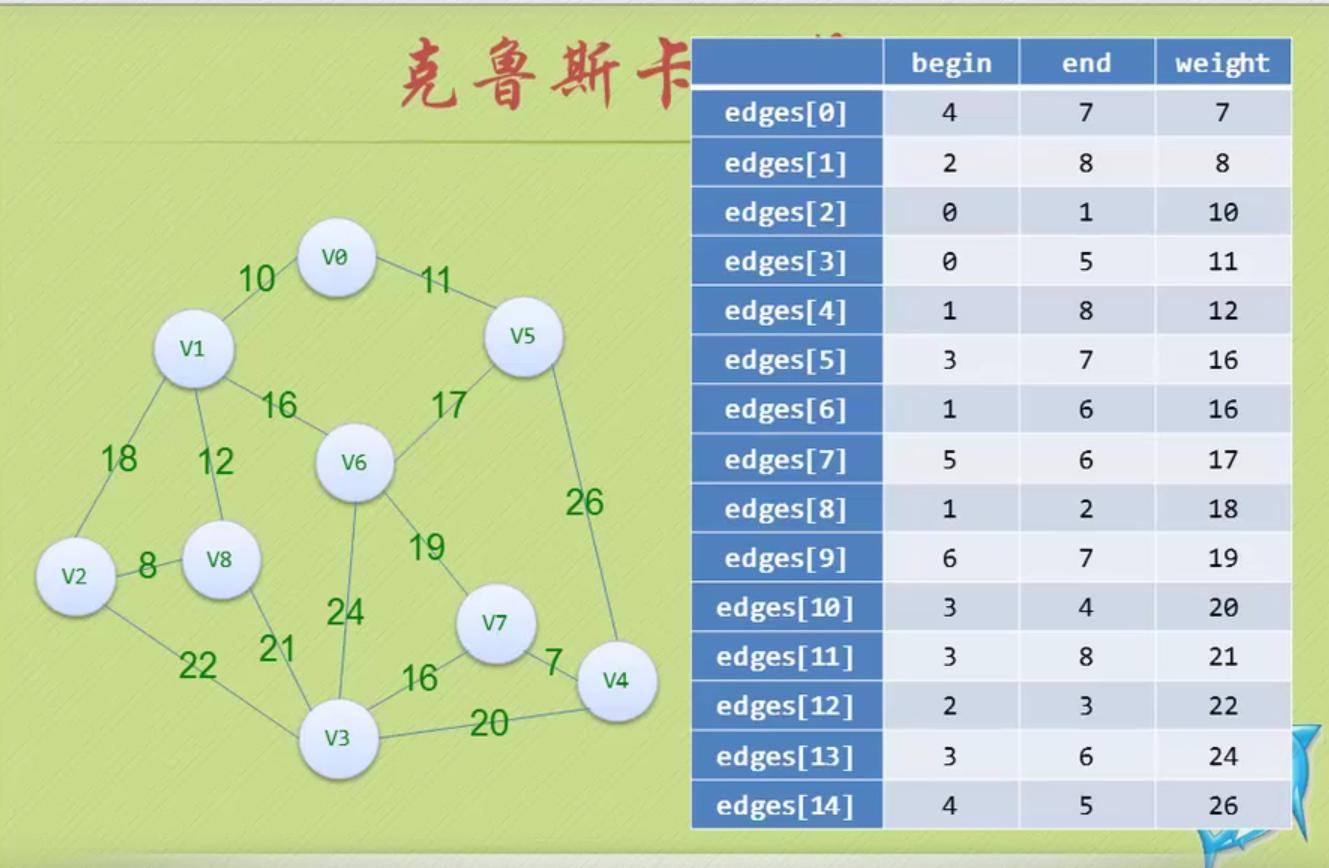
基于边集数组的图结构
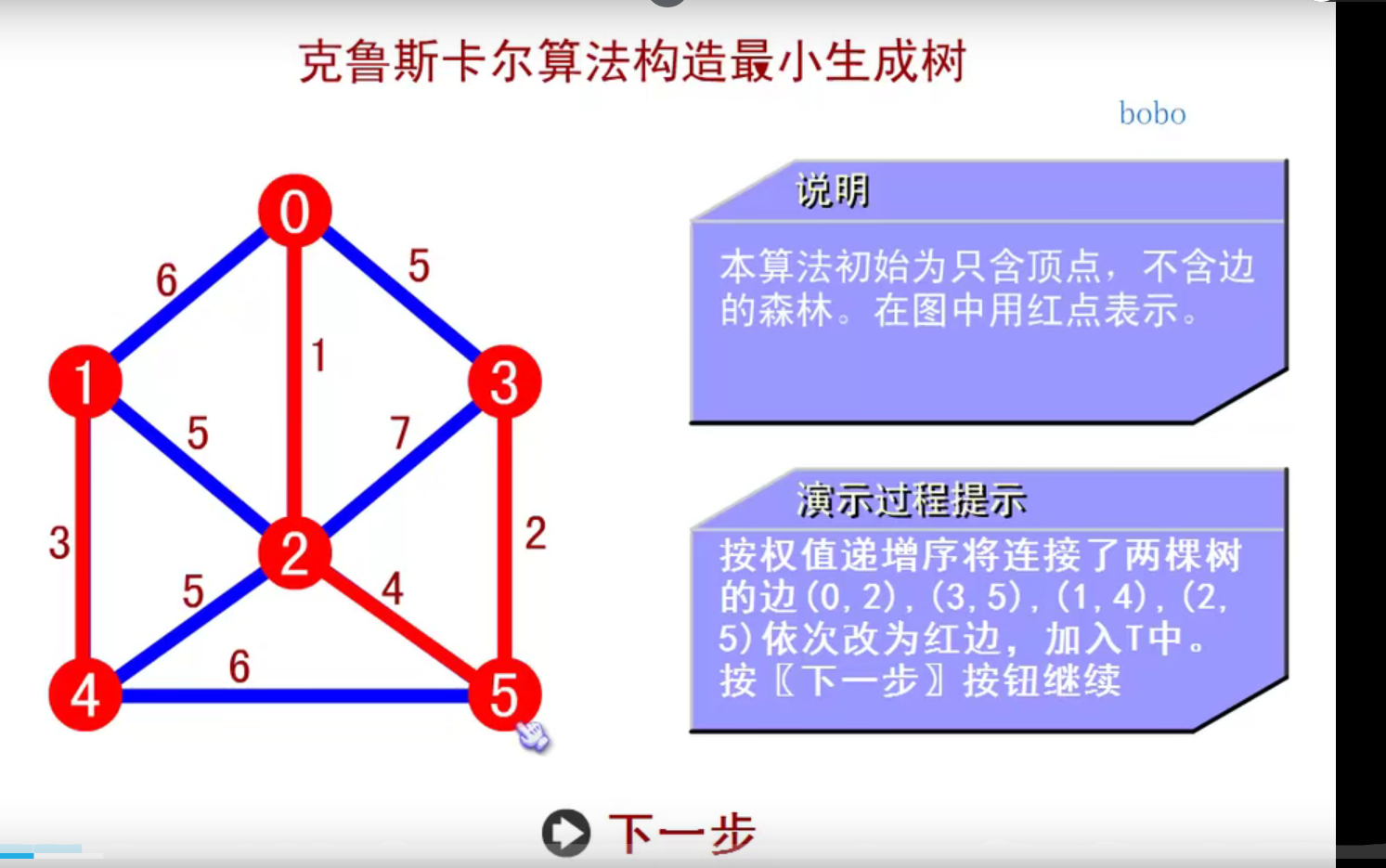
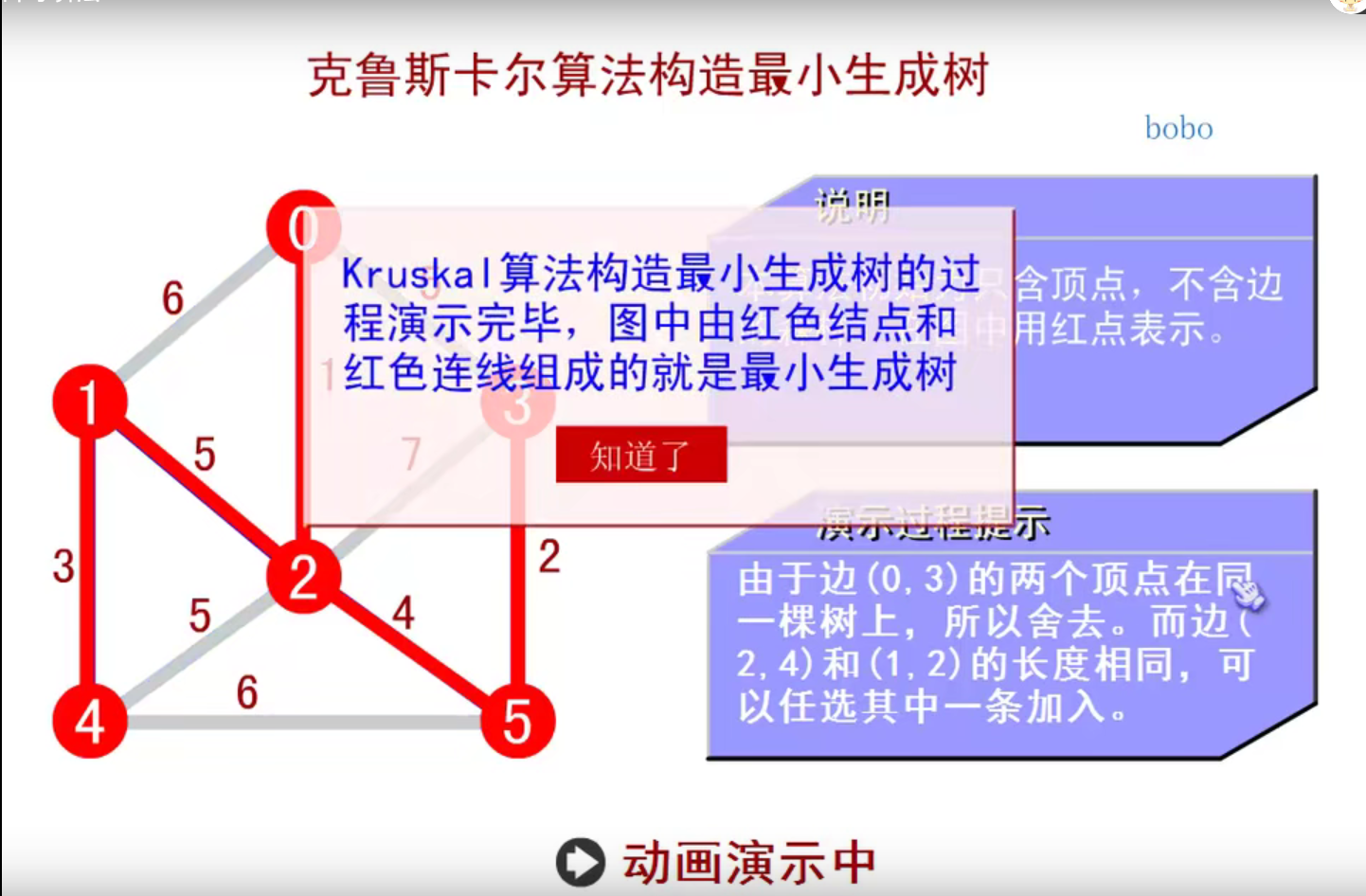
如果把(0,3)这个边加入,这样 0 2 3 5就构成了一个环路,就不是树了。
同理在(1,2) 和(4,2)选一个就行了
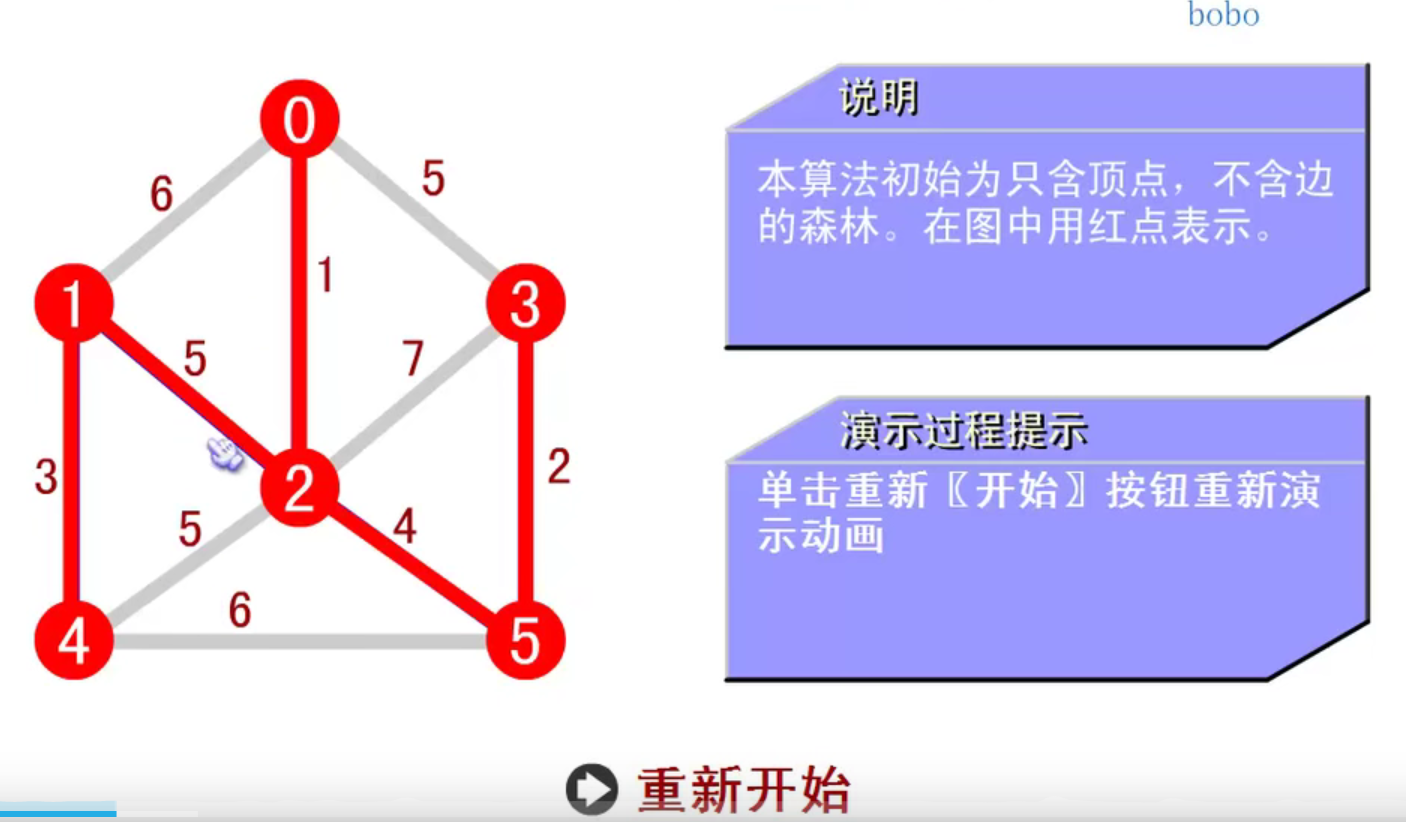
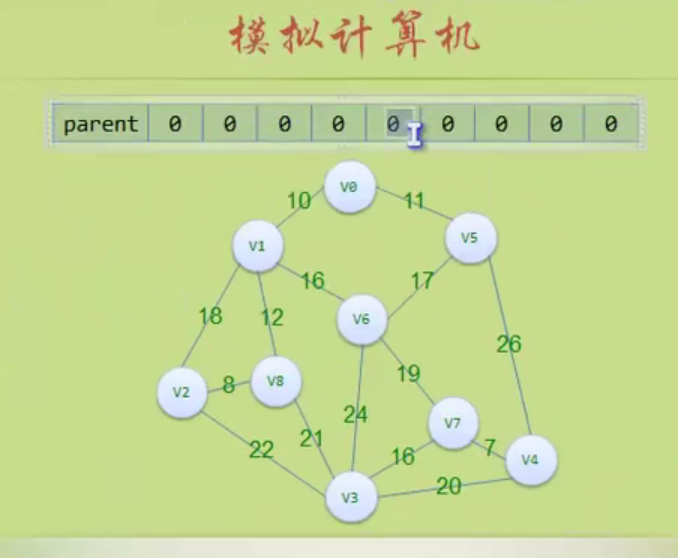
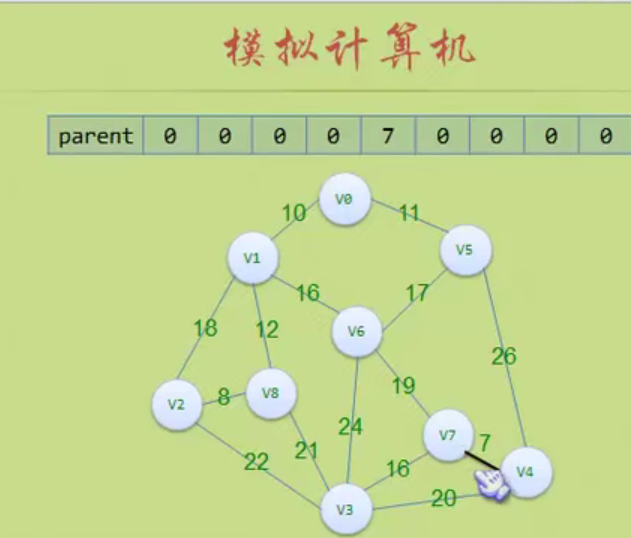
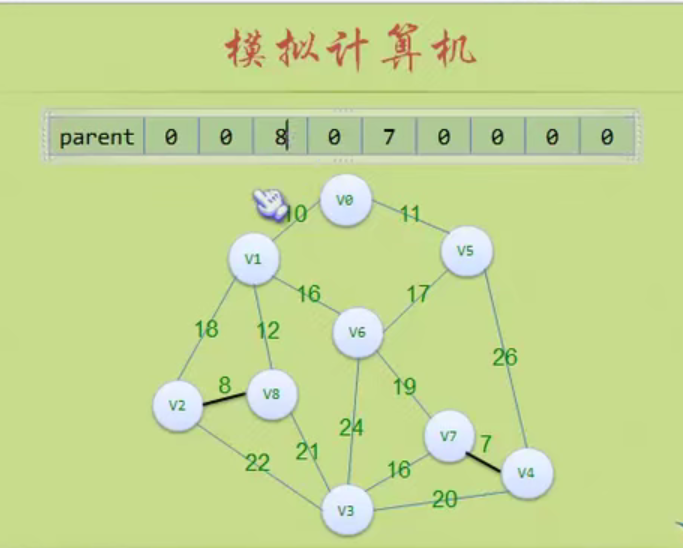
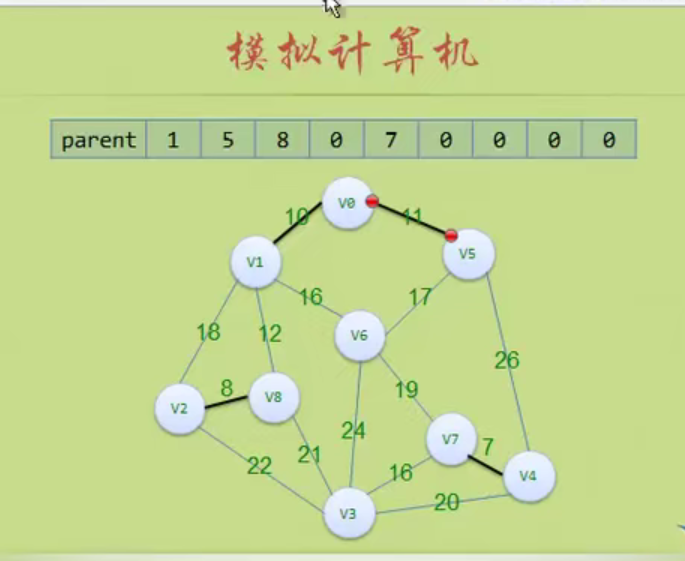
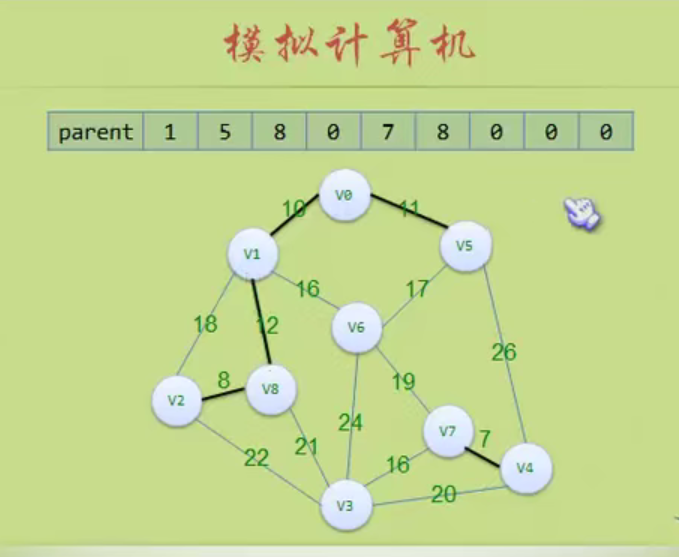
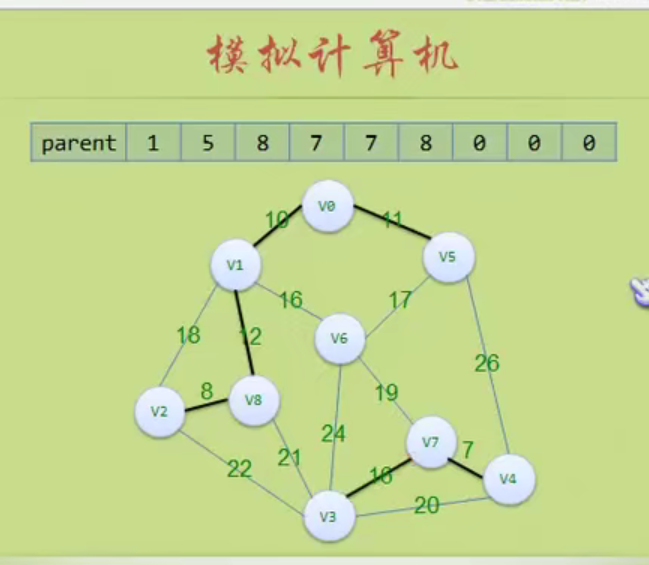
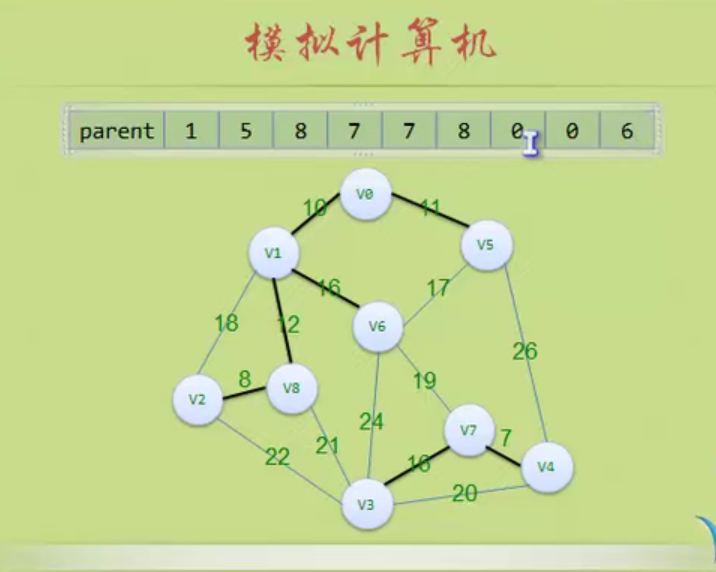
到这里就判断出环路了 (5,6)不能加入
并且下一个(1,2)也被判断为形成环路,不能加入
这里可以看出parent数组的作用,它里面其实是将树的顶点关联了起来。
比如(5,6):
对于5来说 parent[5]=8 parent[8]=6 parent[6]=0 返回6
对于6来说 parent[6]=0 ,返回6,n==m 那就形成环路,不是树了,不加入这个边
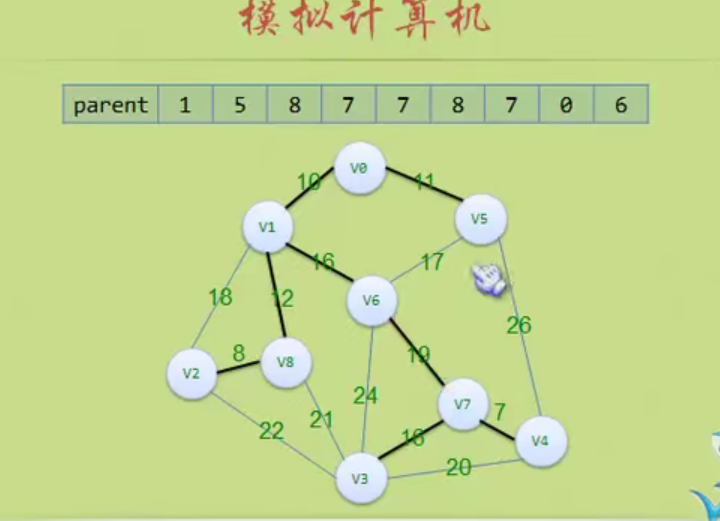
后面(3,4)也构成环路,不加入这个边
然后后面的都会构成环路!
这个算法更好理解!!!因为用的边集结构,好理解一点。
对于稀疏图来说(也就是边不是那么多),克鲁卡尔斯算法有优势。
对于稠密图(顶点比较少,边比较多的),普里姆算法有优势。
代码如下:
int Find(int *parent, int f)
{
while( parent[f] > 0 )
{
f = parent[f];
}
return f;
}
// Kruskal算法生成最小生成树
void MiniSpanTree_Kruskal(MGraph G)
{
int i, n, m;
Edge edges[MAGEDGE]; // 定义边集数组
int parent[MAXVEX]; 定义parent数组用来判断边与边是否形成环路
for( i=0; i < G.numVertexes; i++ )//初始化parent
{
parent[i] = 0;
}
for( i=0; i < G.numEdges; i++ )
{
n = Find(parent, edges[i].begin); // 4 2 0 1 5 3 8 6 6 6 7
m = Find(parent, edges[i].end); // 7 8 1 5 8 7 6 6 6 7 7
if( n != m ) // 如果n==m,则形成环路,不满足!
{
parent[n] = m; // 将此边的结尾顶点放入下标为起点的parent数组中,表示此顶点已经在生成树集合中
printf("(%d, %d) %d ", edges[i].begin, edges[i].end, edges[i].weight);
}
}
}
最短路径

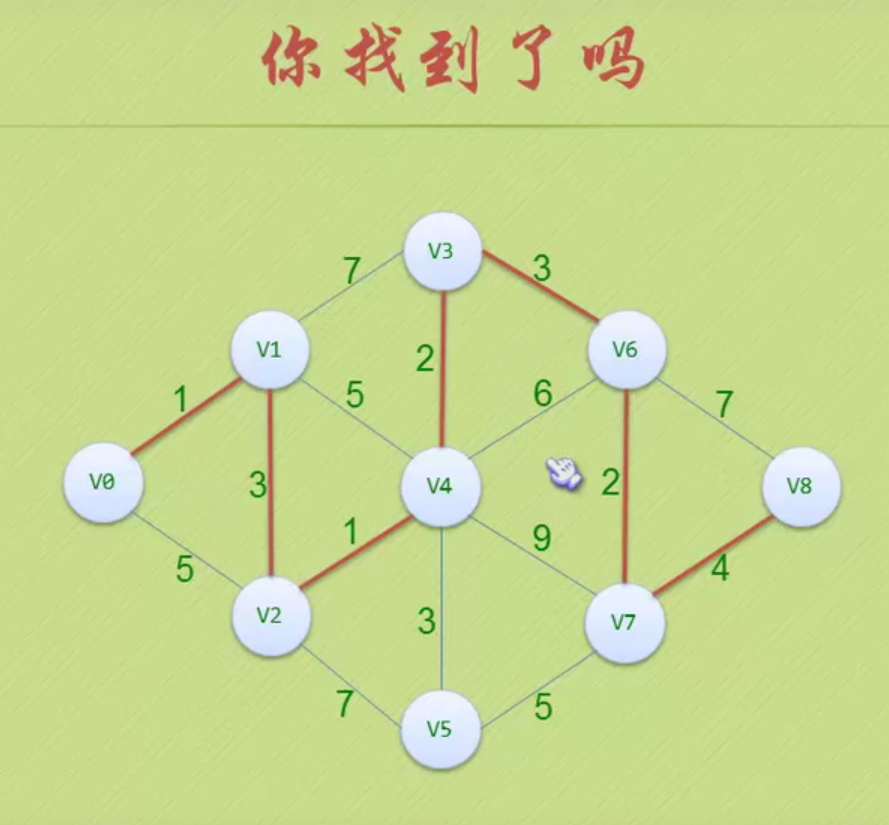
迪杰斯特拉

final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
(*D)[w] = min + G.arc[k][w]; // 修改当前路径长度 用于存储到各点最短路径的权值和
(*p)[w] = k; // 存放前驱顶点 比如 p[2]=1 表示2的前驱顶点是1 也就是从顶点1走到顶点2 用于存储最短路径下标的数组
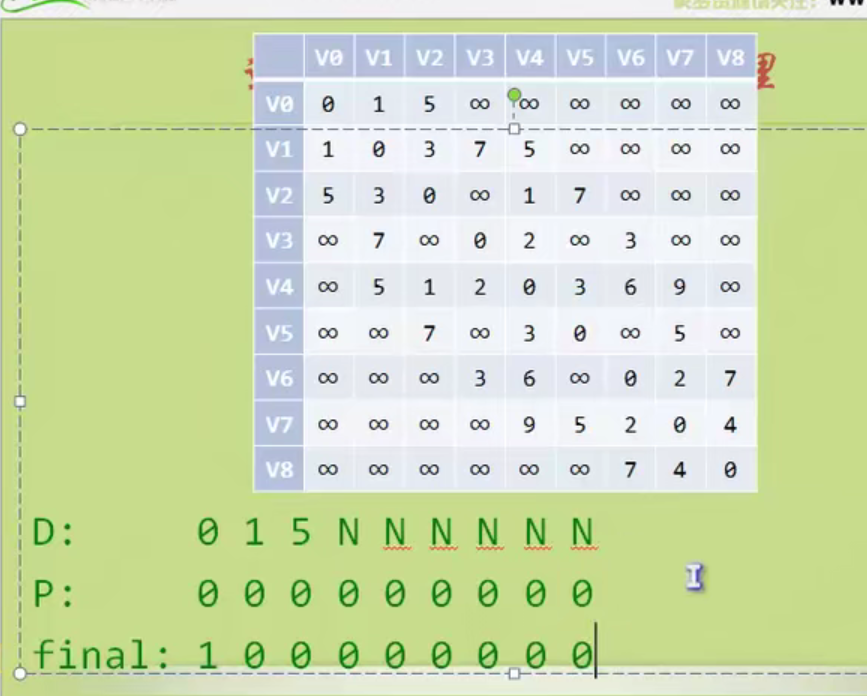


#define MAXVEX 9
#define INFINITY 65535
typedef int Patharc[MAXVEX]; // 用于存储最短路径下标的数组
typedef int ShortPathTable[MAXVEX]; // 用于存储到各点最短路径的权值和
void ShortestPath_Dijkstar(MGraph G, int V0, Patharc *P, ShortPathTable *D)
{
int v, w, k, min;
int final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
// 初始化数据
for( v=0; v < G.numVertexes; v++ )
{
final[v] = 0; // 全部顶点初始化为未找到最短路径
(*D)[V] = G.arc[V0][v]; // 将与V0点有连线的顶点加上权值
(*P)[V] = 0; // 初始化路径数组P为0
}
(*D)[V0] = 0; // V0至V0的路径为0
final[V0] = 1; // V0至V0不需要求路径
// 开始主循环,每次求得V0到某个V顶点的最短路径
for( v=1; v < G.numVertexes; v++ )
{
min = INFINITY;
for( w=0; w < G.numVertexes; w++ )
{
if( !final[w] && (*D)[w]<min )
{
k = w;
min = (*D)[w];
}
}
final[k] = 1; // 将目前找到的最近的顶点置1
// 修正当前最短路径及距离
for( w=0; w < G.numVextexes; w++ )
{
// 如果经过v顶点的路径比现在这条路径的长度短的话,更新!
if( !final[w] && (min+G.arc[k][w] < (*D)[w]) )//这里非常关键 比如 0走到1了 ,现在要选择是从1走到2 还是从0走到2 就要用到 min+G.arc[k][w] < (*D)[w])
{
(*D)[w] = min + G.arc[k][w]; // 修改当前路径长度
(*p)[w] = k; // 存放前驱顶点
}
}
}
}
最终的结果
final[MAXVEX]; // final[w] = 1 表示已经求得顶点V0到Vw的最短路径
(*D)[w] = min + G.arc[k][w]; // 修改当前路径长度 用于存储到各点最短路径的权值和
(*p)[w] = k; // 存放前驱顶点 比如 p[2]=1 表示2的前驱顶点是1 也就是从顶点1走到顶点2 用于存储最短路径下标的数组
N代表无穷也就是代码里的65535
初始化:
final: 1 0 0 0 0 0 0 0 0
D: 0 1 5 N N N N N N
P: 0 0 0 0 0 0 0 0 0
从v=1开始 v表示顶点1
**********第一次主循环
k=1;
min=1;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 0 0 0 0 0 0 0
更新D 、P
D: 0 1 4 N N N N N N
P: 0 0 1 0 0 0 0 0 0
**********第一次主循环
**********第二次主循环
final: 1 1 0 0 0 0 0 0 0
D: 0 1 4 N N N N N N
P: 0 0 1 0 0 0 0 0 0
k=2;
min=4;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 0 0 0 0 0 0
更新D 、P
D: 0 1 4 N 5 N N N N
P: 0 0 1 0 2 0 0 0 0
**********第二次主循环
**********第三次主循环
final: 1 1 1 0 0 0 0 0 0
D: 0 1 4 N 5 N N N N
P: 0 0 1 0 2 0 0 0 0
k=4;
min=5;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 0 1 0 0 0 0
更新D 、P
D: 0 1 4 7 5 N N N N
P: 0 0 1 4 2 0 0 0 0
**********第三次主循环
**********第四次主循环
final: 1 1 1 0 1 0 0 0 0
D: 0 1 4 7 5 N N N N
P: 0 0 1 4 2 0 0 0 0
k=3;
min=7;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 0 0 0
更新D 、P
D: 0 1 4 7 5 N 10 N N
P: 0 0 1 4 2 0 3 0 0
**********第四次主循环
**********第五次主循环
final: 1 1 1 1 1 0 0 0 0
D: 0 1 4 7 5 N 10 N N
P: 0 0 1 4 2 0 3 0 0
k=6;
min=10
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 0 0
更新D 、P
D: 0 1 4 7 5 N 10 12 N
P: 0 0 1 4 2 0 3 6 0
**********第五次主循环
**********第六次主循环
final: 1 1 1 1 1 0 1 0 0
D: 0 1 4 7 5 N 10 12 N
P: 0 0 1 4 2 0 3 6 0
k=7;
min=12;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 1 0
更新D 、P
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第六次主循环
**********第七次主循环
final: 1 1 1 1 1 0 1 1 0
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
k=8;
min=14;
更新final 表示V0到Vk的最短路径找到了
final: 1 1 1 1 1 0 1 1 1
更新D 、P
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第七次主循环
**********第八次主循环
final: 1 1 1 1 1 0 1 1 1
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
**********第八次主循环
结束循环
final: 1 1 1 1 1 0 1 1 1
D: 0 1 4 7 5 N 10 12 16
P: 0 0 1 4 2 0 3 6 7
路线是 0->1->2->4->3->6->7->8
弗洛伊德


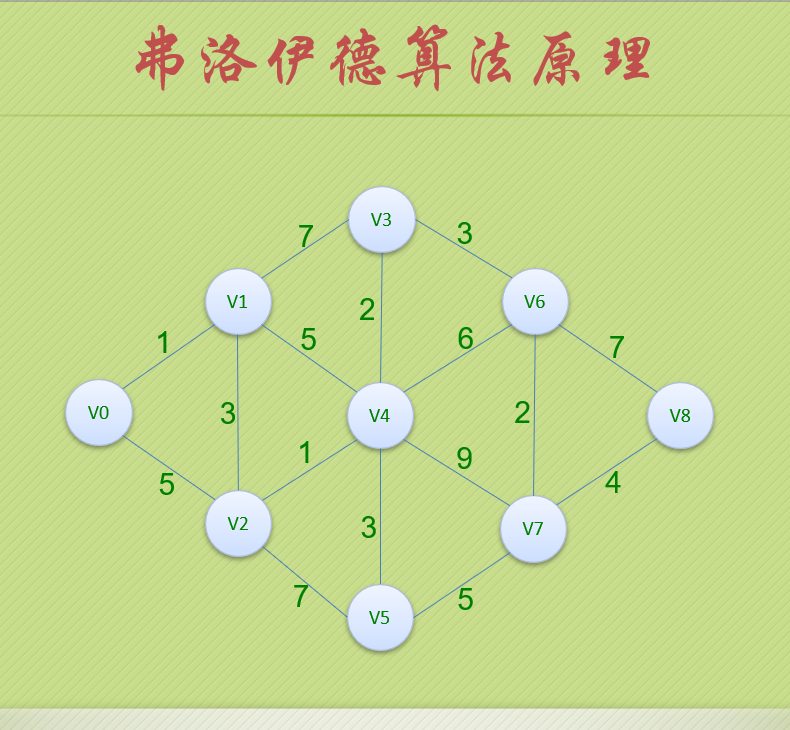
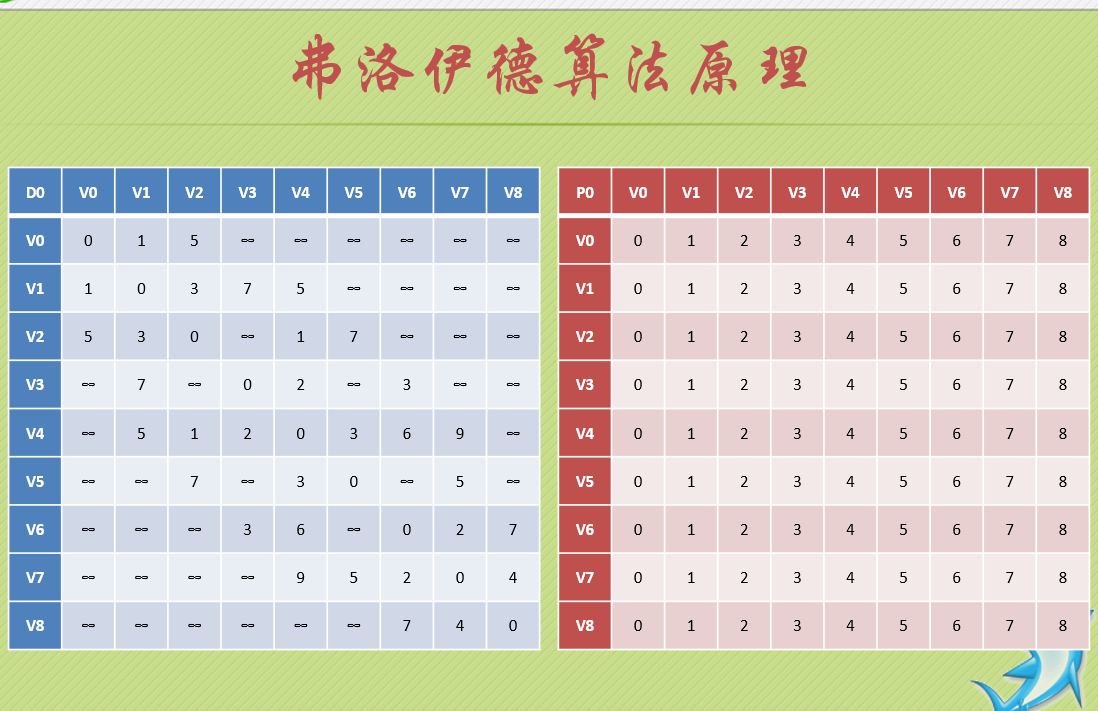
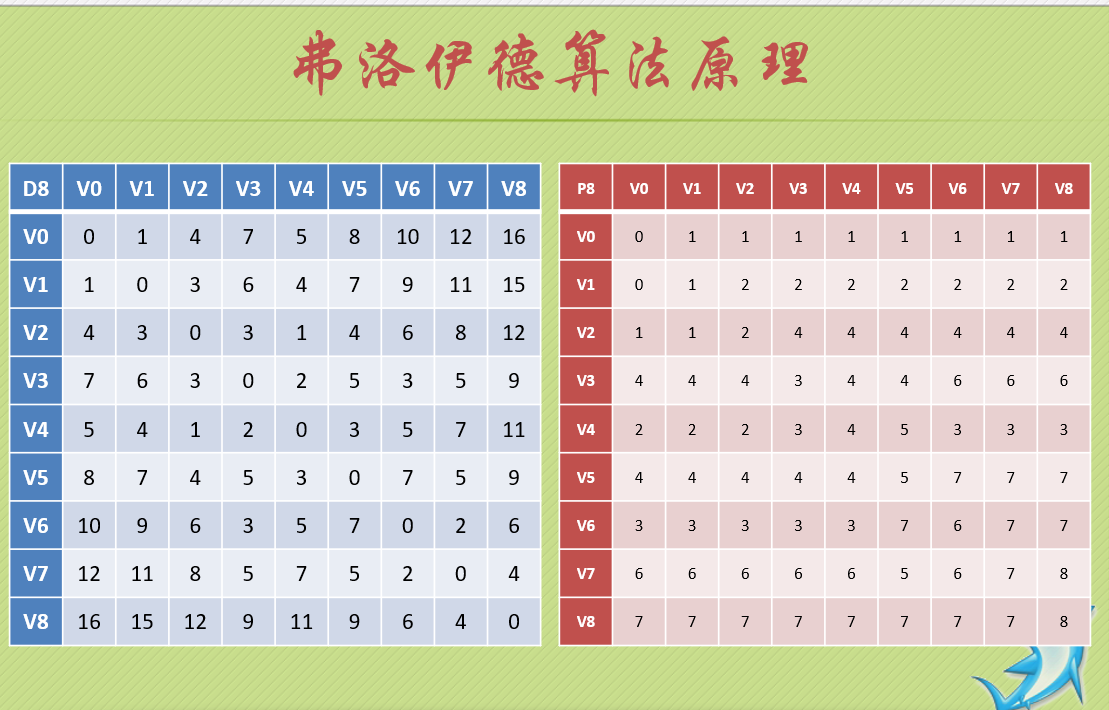
#define MAXVEX 9
#define INFINITY 65535
typedef int Pathmatirx[MAXVEX][MAXVEX];
typedef int ShortPathTable[MAXVEX][MAXVEX];
void ShortestPath_Floyd(MGraph G, Pathmatirx *P, ShortPathTable *D)
{
int v, w, k;
// 初始化D和P
for( v=0; v < G.numVertexes; v++ )
{
for( w=0; w < G.numVertexes; w++ )
{
(*D)[v][w] = G.matirx[v][w]; //获取邻接矩阵
(*P)[v][w] = w;//初始化各个边之间的前驱节点
}
}
// 优美的弗洛伊德算法
//这三层循环将所有边,两两之间都考虑进去了
//对于D数组来说
//需要改变的D的元素有内部由两个变量 v w 控制 也就是边(v,w)
//比如(0,2)也就是0->2这个路线 这时候会对应 以下几种情况 (0,2)>(0 ,0)+(0,2) (0,2)>(0 ,1)+(1,2)
// 也就是从0到2 我们可以这样走:从0到1,再从1到2
// (v,w)>(v,k)+(k,w), k起到了换路线的作用 而v w则是负责边的两端的顶点
//对于P数组来说 (*P)[v][w] = (*P)[v][k]; 也就是说对于(v,w)走向 可以利用(v,k)->(k,w)的路线,所以对于(v,w)的w来说,他的前驱节点就是k啦!!!
//经过三层循环,可以把所有情况考虑进去
//比如0->3 有这么几种走法 0->1 + 1->3
// 0->2 + 2->3 =0->1 + 1->2 + 2->4 + 4->3
// 上面两种情况都会被考虑进去,所以弗洛伊德算法很简单,但事件复杂度高 O(n^3)
for( k=0; k < G.numVertexes; k++ )
{
for( v=0; v < G.numVertexes; v++ )
{
for( w=0; w < G.numVertexes; w++ )
{
if( (*D)[v][w] > (*D)[v][k] + (*D)[k][w] )//这里的 v代表列 k达标
{
(*D)[v][w] = (*D)[v][k] + (*D)[k][w];
(*P)[v][w] = (*P)[v][k]; // 请思考:这里换成(*P)[k][w]可以吗?为什么?
}
}
}
}
}
拓扑排序



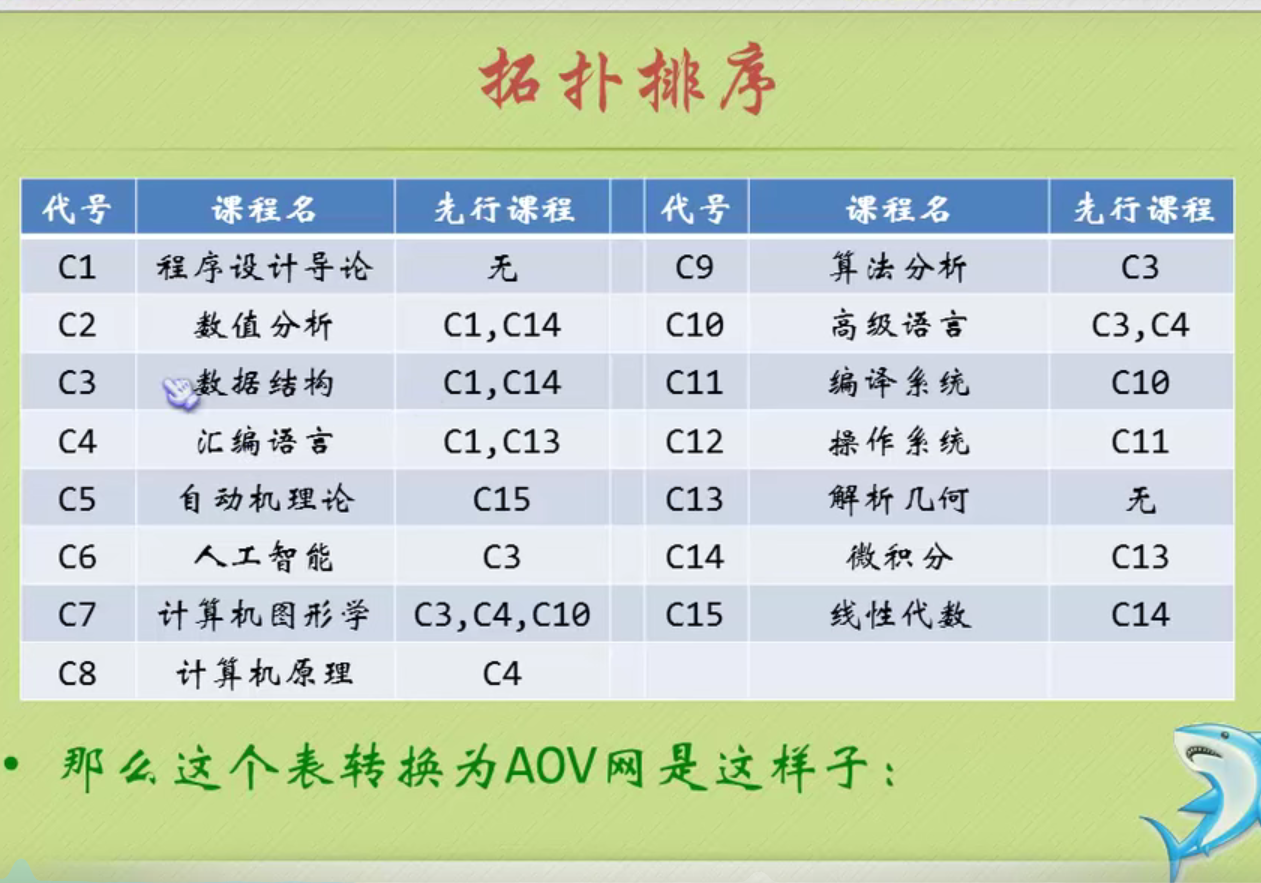
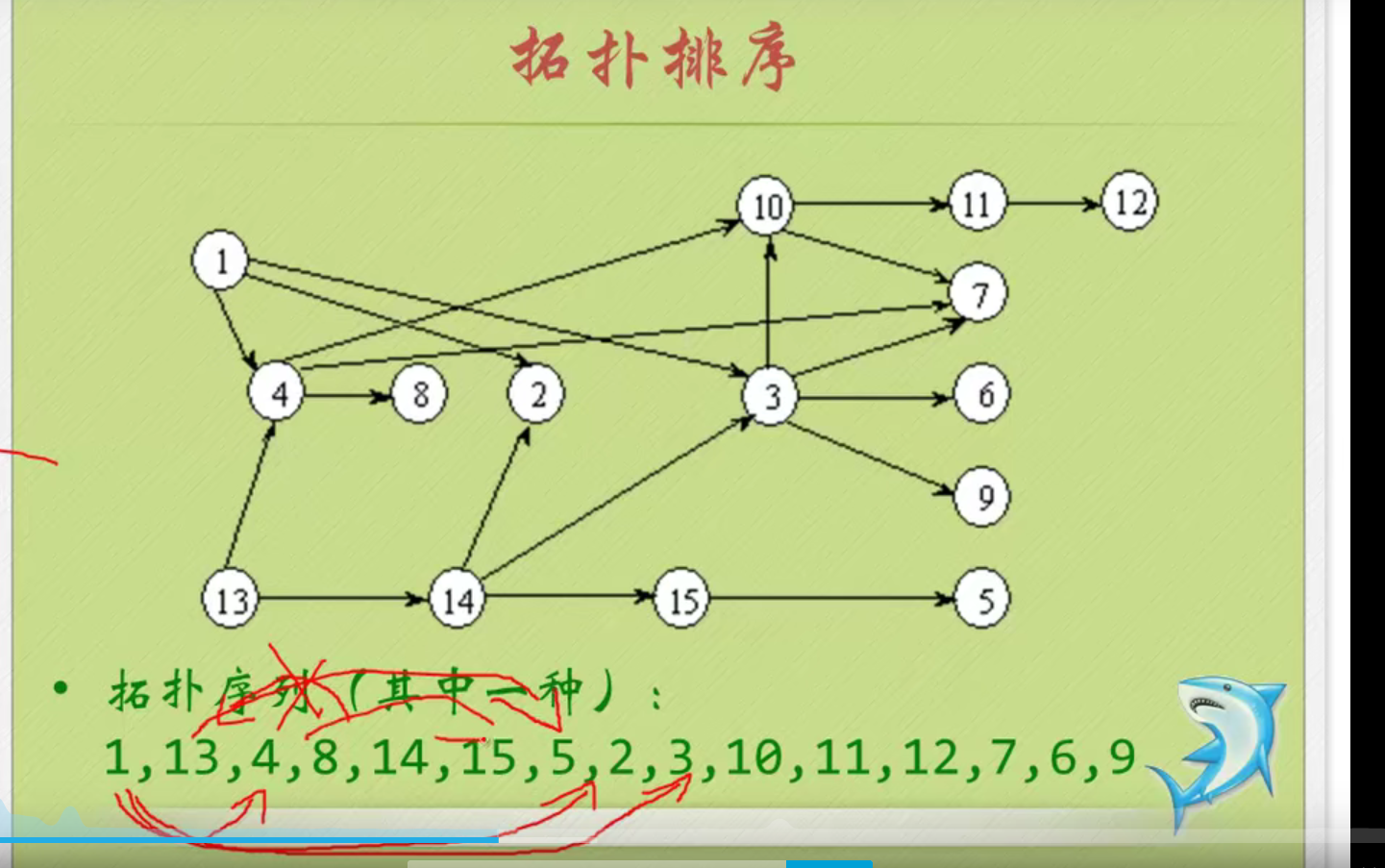
拓扑结构 一定要前面指向后面

采用邻接表
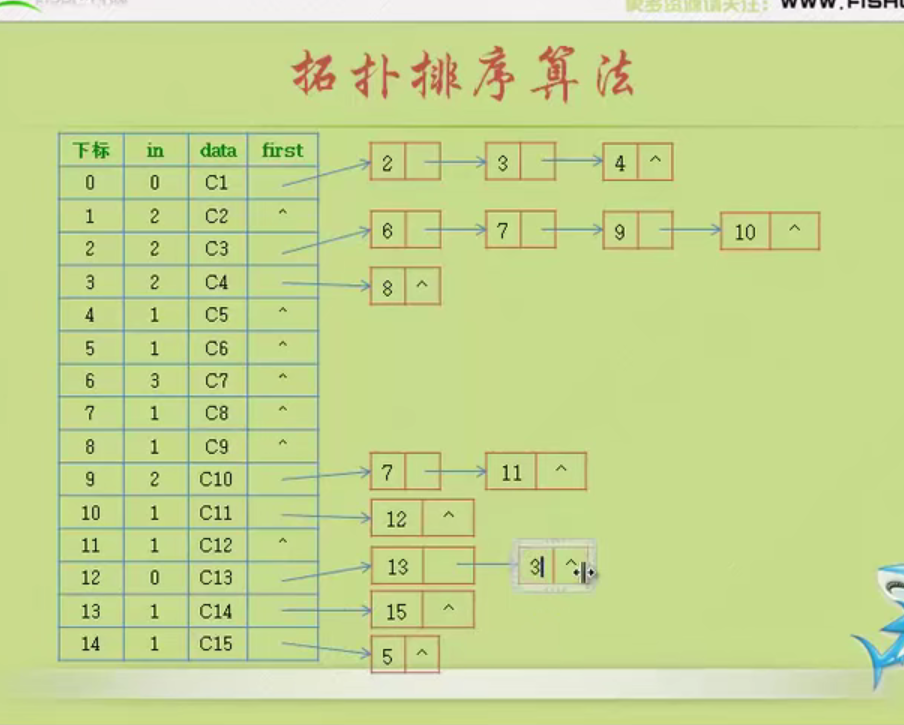

// 边表结点声明
typedef struct EdgeNode
{
int adjvex;
struct EdgeNode *next;
}EdgeNode;
// 顶点表结点声明
//邻接表
typedef struct VertexNode
{
int in; // 顶点入度
int data;
EdgeNode *firstedge;
}VertexNode, AdjList[MAXVEX];
//有向图结构
typedef struct
{
AdjList adjList;
int numVertexes, numEdges;
}graphAdjList, *GraphAdjList;
// 拓扑排序算法
// 若GL无回路,则输出拓扑排序序列并返回OK,否则返回ERROR
Status TopologicalSort(GraphAdjList GL)
{
EdgeNode *e;
int i, k, gettop;
int top = 0; // 用于栈指针下标索引
int count = 0; // 用于统计输出顶点的个数
int *stack; // 用于存储入度为0的顶点
stack = (int *)malloc(GL->numVertexes * sizeof(int));
//对入读为0的顶点下标入栈
for( i=0; i < GL->numVertexes; i++ )
{
if( 0 == GL->adjList[i].in )
{
stack[++top] = i; // 将度为0的顶点下标入栈
}
}
//这里top是12
while( 0 != top )
{
gettop = stack[top--]; // 出栈
printf("%d -> ", GL->adjList[gettop].data);
count++;
//这里是遍历栈里面顶点邻接的顶点
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;
// 注意:下边这个if条件是分析整个程序的要点!
// 将k号顶点邻接点的入度-1,因为他的前驱已经消除
// 接着判断-1后入度是否为0,如果为0则也入栈
if( !(--GL->adjList[k].in) ) //因为按算法原理来说,每拿出一个入读为零的顶点,用完之后,就把它从图中删掉。所以其邻接的顶点入度就会相应-1
//如果对于GL->adjList[k]这个顶点来说,它的入度为0,那么它也要入栈了
{
stack[++top] = k;
}
}
}
if( count < GL->numVertexes ) // 如果count小于顶点数,说明存在环
{
return ERROR;
}
else
{
return OK;
}
}
关键路径


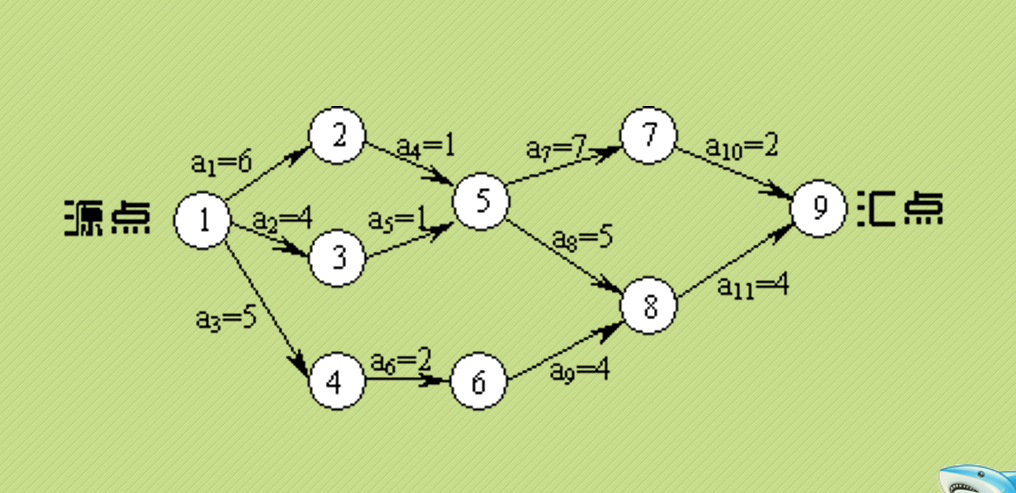
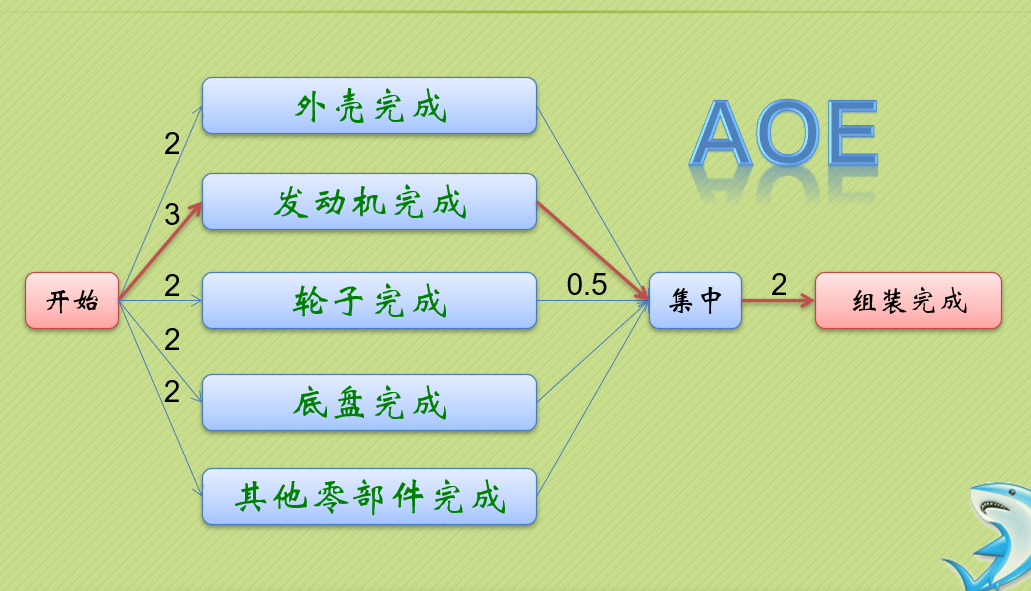


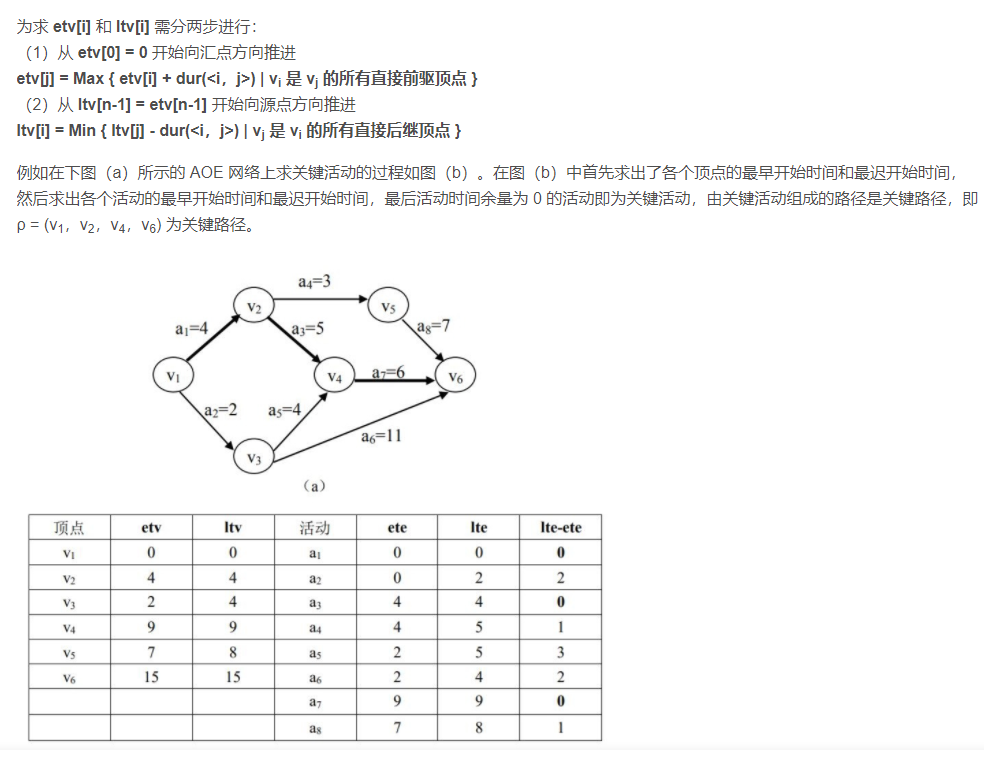

etv是从左往右推的
ltv是从右往左推的
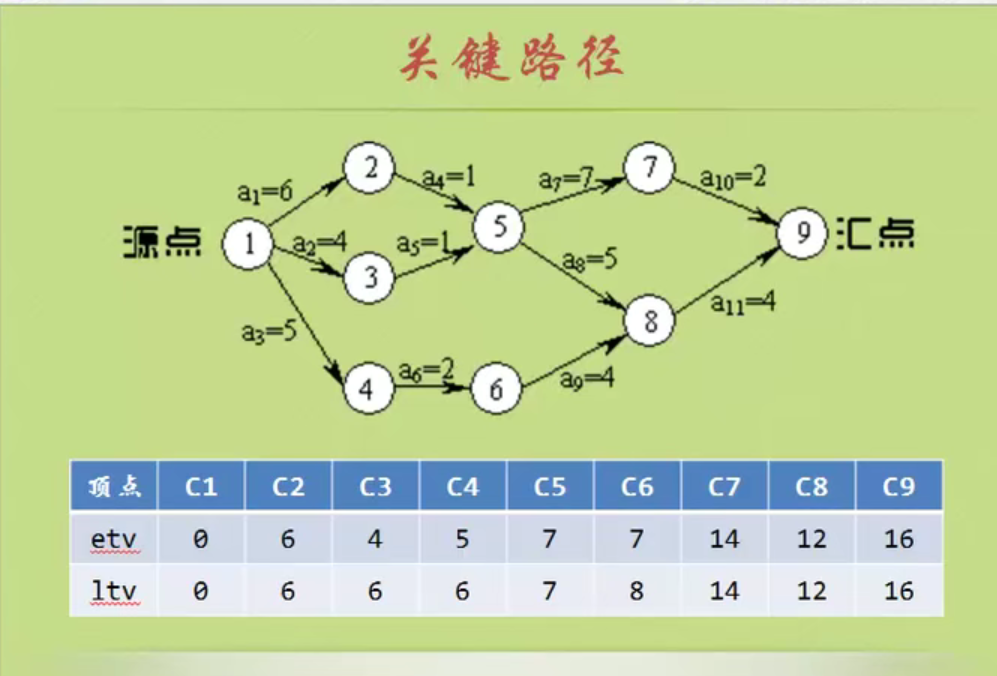
对于顶点来说
顶点j在顶点i的后面,并且是相邻的
顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
顶点 Vj 的最晚发生时间 -(vi,vj)的权 = 顶点i的最晚发生时间
比如:
对于C8的ltv来说 可以这么理解
C8的最晚发生时间是8, 最早发生时间是7 ,说明C8可以 偷懒一个小时,为什么呢,因为顶点5到顶点8 要5个小时,而顶点6到顶点8只要4个小时
顶点8要开始工作,必须两个路线都走了才行,5->8时间久一点,那么6->8当然可以偷懒咯
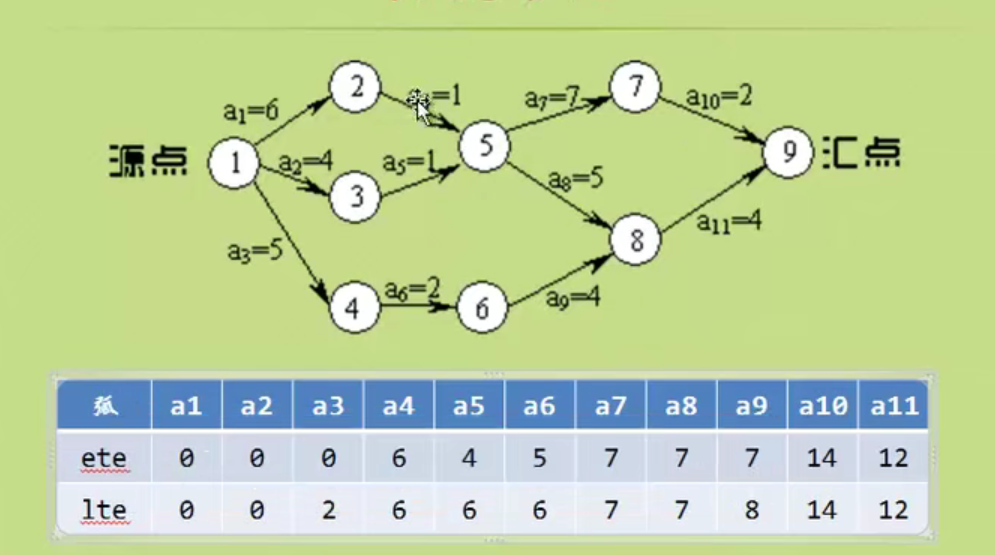
对于弧来说。他们是时间持续的时间
顶点k在顶点j的后面,并且是相邻的
顶点k与顶点j之间的弧的最早发生时间=顶点j的最早发生时间
顶点k与顶点j之间的弧的的最晚发生时间= 顶点k的最晚发生时间- 顶点k与顶点j之间的权
比如:
对于弧a4来说它的ete最早发生时间就是顶点C2的最早发生时间etv。
lte也是从右往左推,比如a11,a11的最晚发生时间lte=顶点C9的最晚发生时间–4 =16-4=12 其他的以此类推。
总结:
对于顶点来说:
顶点j在顶点i的后面,并且是相邻的
顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
顶点 Vj 的最晚发生时间 -(vi,vj)的权 = 顶点i的最晚发生时间
对于弧来说。他们是时间持续的时间:
顶点k在顶点j的后面,并且是相邻的
顶点k与顶点j之间的弧的最早发生时间=顶点j的最早发生时间
顶点k与顶点j之间的弧的的最晚发生时间= 顶点k的最晚发生时间- 顶点k与顶点j之间的权
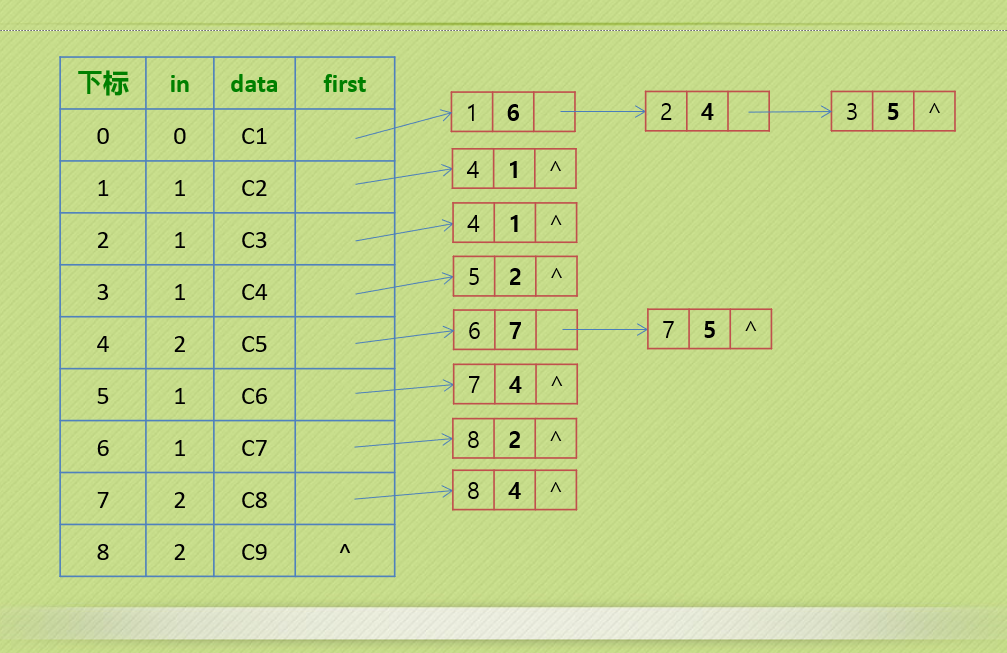
// 边表结点声明
typedef struct EdgeNode
{
int adjvex;
struct EdgeNode *next;
}EdgeNode;
// 顶点表结点声明
typedef struct VertexNode
{
int in; // 顶点入度
int data;
EdgeNode *firstedge;
}VertexNode, AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int numVertexes, numEdges;
}graphAdjList, *GraphAdjList;
int *etv, *ltv;
int *stack2; // 用于存储拓扑序列的栈
int top2; // 用于stack2的栈顶指针
// 拓扑排序算法
// 若GL无回路,则输出拓扑排序序列并返回OK,否则返回ERROR
/**
* 求出了拓扑排序,并且求出了etv
* @param GL
* @return
*/
Status TopologicalSort(GraphAdjList GL)
{
EdgeNode *e;
int i, k, gettop;
int top = 0; // 用于栈指针下标索引
int count = 0; // 用于统计输出顶点的个数
int *stack; // 用于存储入度为0的顶点
stack = (int *)malloc(GL->numVertexes * sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
if( 0 == GL->adjList[i].in )
{
stack[++top] = i; // 将度为0的顶点下标入栈
}
}
// 初始化etv都为0
top2 = 0;
etv = (int *)malloc(GL->numVertexes*sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
etv[i] = 0;
}
stack2 = (int *)malloc(GL->numVertexes*sizeof(int));
while( 0 != top )
{
gettop = stack[top--]; // 出栈
// printf("%d -> ", GL->adjList[gettop].data);
stack2[++top2] = gettop; // 保存拓扑序列顺序 C1 C2 C3 C4 .... C9
count++;
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;//k就是邻接的顶点
// 注意:下边这个if条件是分析整个程序的要点!
// 将k号顶点邻接点的入度-1,因为他的前驱已经消除
// 接着判断-1后入度是否为0,如果为0则也入栈
//这里是拓扑排序
if( !(--GL->adjList[k].in) )
{
stack[++top] = k;
}
//
if( (etv[gettop]+e->weight) > etv[k] )//这一步很关键 这里用来计算顶点的最早发生时间 这个根据PPT的图片来进行理解比较好
//大的值就是顶点k的最早发生时间,相当于就是顶点Vi的最早发生时间 +(vi,vj)的权 = 顶点j的最早发生时间
{
etv[k] = etv[gettop] + e->weight;
}
}
}
if( count < GL->numVertexes ) // 如果count小于顶点数,说明存在环
{
return ERROR;
}
else
{
return OK;
}
}
// 求关键路径,GL为有向图,输出GL的各项关键活动
void CriticalPath(GraphAdjList GL)
{
EdgeNode *e;
int i, gettop, k, j;
int ete, lte;
// 调用改进后的拓扑排序,求出etv和stack2的值
TopologicalSort(GL);
// 初始化ltv都为汇点的时间
ltv = (int *)malloc(GL->numVertexes*sizeof(int));
for( i=0; i < GL->numVertexes; i++ )
{
ltv[i] = etv[GL->numVertexes-1];
}
// 从汇点倒过来逐个计算ltv
while( 0 != top2 )
{
gettop = stack2[top2--]; // 注意,第一个出栈是汇点 第一个出栈的汇点其实没什么卵用,因为它的 firstedge指向空
//当到了C8的时候就开始真正的计算了
for( e=GL->adjList[gettop].firstedge; e; e=e->next )
{
k = e->adjvex;
if( (ltv[k] - e->weight) < ltv[gettop] )//这里要填一个小的,为了不让工期延误 从源点的ltv就可以看懂这个代码了
{
ltv[gettop] = ltv[k] - e->weight;//顶点gettop的最晚发生时间 = 顶点k的最晚发生时间 - 顶点gettop与顶点k之间的权
}
}
}
// 通过etv和ltv求ete和lte
for( j=0; j < GL->numVertexes; j++ )
{
//遍历顶点的左右邻接顶点
for( e=GL->adjList[j].firstedge; e; e=e->next )
{
k = e->adjvex;//获得邻接顶点
ete = etv[j];//换算得到ete 顶点k与顶点j之间的弧的最早发生时间 = 顶点j的最早发生时间
lte = ltv[k] - e->weight;//换算得到lte 顶点k与顶点j之间的弧的的最晚发生时间 = 顶点k的最晚发生时间- 顶点k与顶点j之间的权
if( ete == lte )//如果 ete等于lte就打印
{
printf("<v%d,v%d> length: %d , ", GL->adjList[j].data, GL->adjList[k].data, e->weight );
}
}
}
}
最终的结果
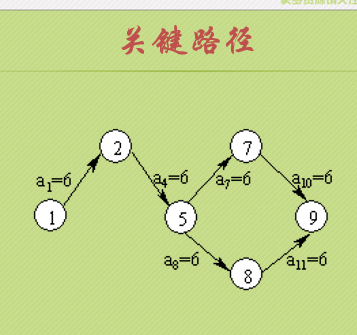
















 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









