







一、unimo
1、优点:训练数据包含文本、图像、图文对数据训练,不局限于图文对
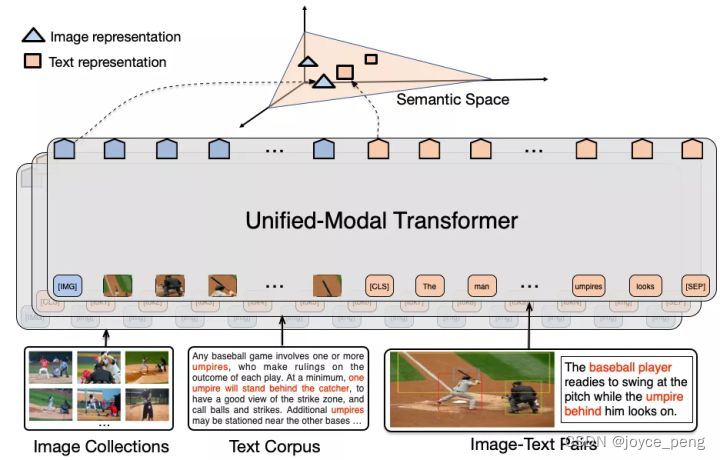
2、策略和模型
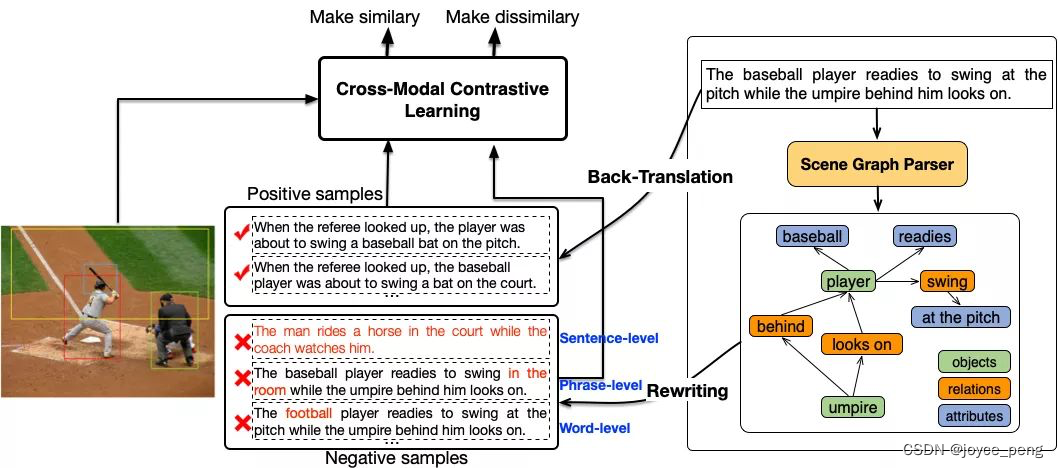
(1)文本改写(Text Rewriting):为了增强图文在多个粒度上的语义对齐能力,论文将图像的文本描述从句子级、短语级和词汇级别三个粒度进行了改写。
在句子级层面,基于回译(Back Translation,即一句话机器翻译模型翻译成多种其他语言,再翻译回来,利用机器翻译模型的能力在不改变句子原始意图的前提下得到相同含义的其他形式句子)的技术来获得一张图片的多个正例文本。
进一步,利用自然语言离散化符号的特性,基于TF-IDF相似度检索得到更多的字面词汇重复率高,但是含义不同的句子作为一张图片的强负样本。
在短语级和词汇级别,首先将文本解析成场景图,然后随机替换掉其中的物体(object)、属性(attribute)和关系(relation)以及它们的组合,获得这两个粒度的强负例。
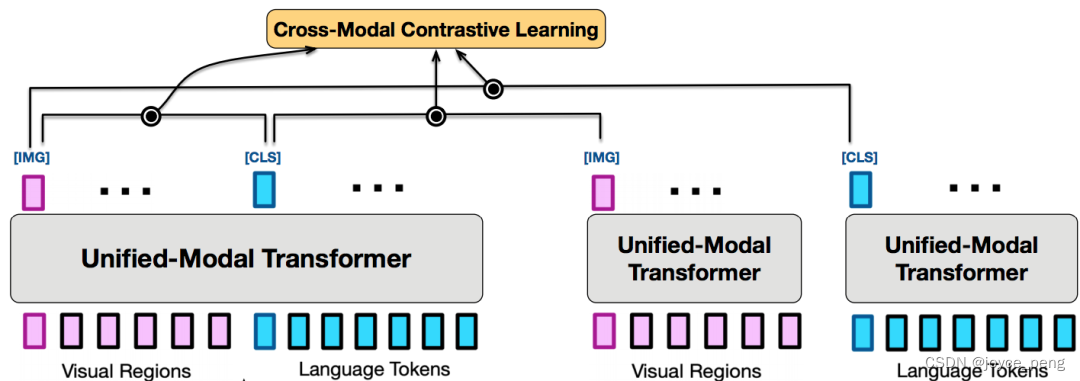
(2)图像/文本检索(Image and Text Retrieval):为了在跨模态学习中融合更多的单模态知识,图文对信息会被从大规模单模态数据中检索出来的背景知识进一步增强和丰富。这部分检索的数据会分别和图文对中的另一种模态数据组成弱相关对加入对比学习。

(3)视觉和文本学习

3、实验
预训练数据部分,文本语料包括 Wikipedia、BookCorpus、OpenWebText 等语料;图像数据是从互联网爬取的 300K 图像;而多模图文对数据则包括 COCO Caption、Visual Genome、Conceptual Caption、SBU Caption。
下游任务既包括视觉问答、图描述生成、视觉推断等多模任务,也包括文本分类、文本摘要、问题生成等各种文本任务。
在多模任务上的结果非常亮眼,各大任务都是SOTA,特别是在检索任务上优势很大。从论文给出的Case Show来看,UNIMO着实在精准理解和捕捉细节方面表现更好。
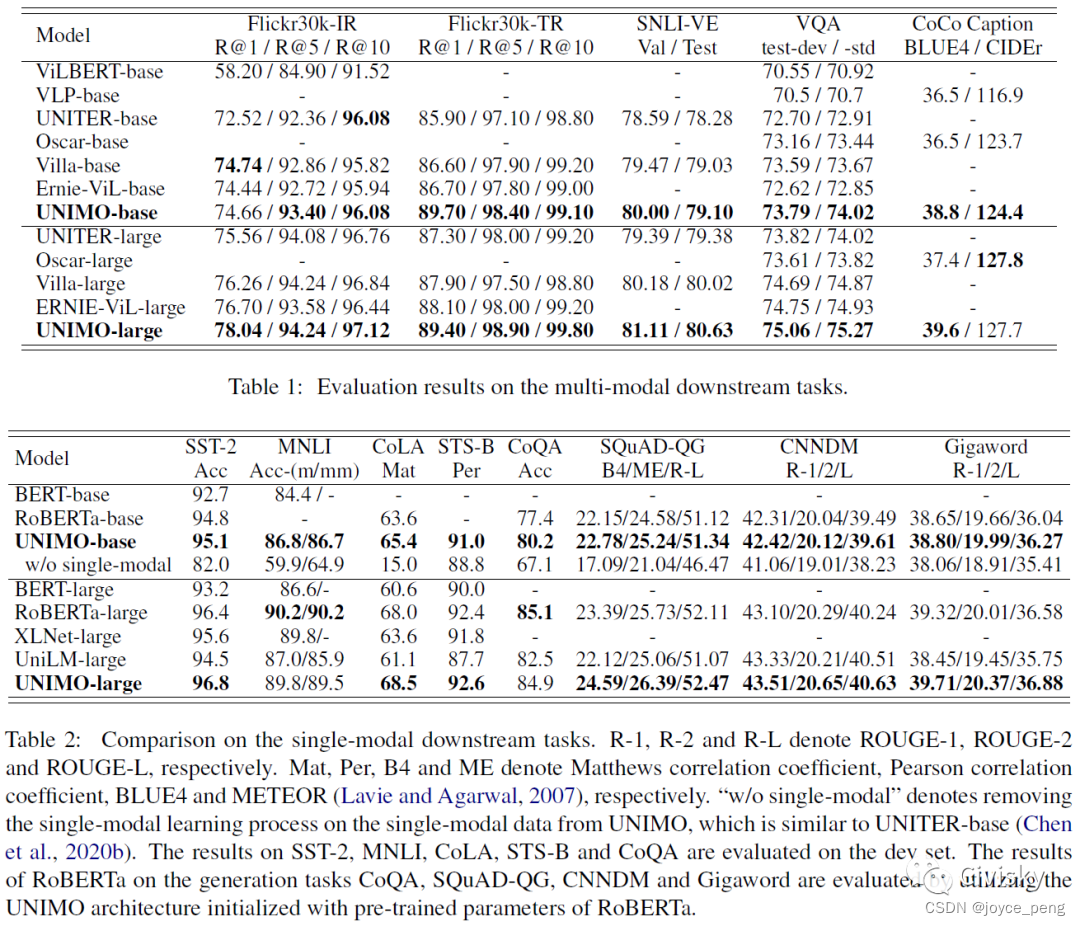
表1:多模态下游任务评估结果。表2:单模态下游任务评估结果。
如表1所示,作者将UNIMO和ViLBERT、VLP、UNITER、Oscar、Villa、ERNIE-ViL多模态预训练模型进行了比较,结果表明,UNIMO总体上取得了最好的成绩。如表2所示,UNIMO在语言理解和生成任务上比BERT、RoBERTa、XLNet和UniLM预训练模型有更好的或相当的表现。UNIMO不仅在多模态任务上取得了最好的成绩,而且在单模态任务上也取得了很好的成绩,这证明了统一模态体系架构的优越性。
reference:https://mp.weixin.qq.com/s/7NYe59gKu6-js32tfy4xBw

















 1730
1730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









