






UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning
目录
2.Cross-Modal Contrastive Learning
3.Mutual Enhancement of Text and Vision
总结
已有的预训练模型主要是单独地针对单模态或者多模态任务,但是无法很好地同时适应两类任务。同时,对于多模态任务,目前的预训练模型只能在非常有限的多模态数据(图像-文本对)上进行训练。本文提出了一个统一模态预训练框架UNIMO,能够有效地同时进行单模态和多模态的内容理解和生成任务。UNIMO的优点在于可以利用大量的开放域文本语料和图片集来提高视觉和文本理解能力,同时采用了跨模态的对比学习(CMCL)将更多的文本和视觉信息映射到一个统一的语义空间。得益于使用了丰富的non-paired单模态数据,UNIMO能够学习到更广义的特征表示。实验表明UNIMO大幅度提高了多项单模态和多模态任务的性能指标。
一、Introduction
大规模预训练由于其强大的泛化能力和对大规模数据的高效利用,在CV和NLP领域都受到了广泛的关注。在ImageNet上设计和预训练一系列CV模型,如AlexNet、VGG、ResNet。它们有效地提高了模型对图像识别的能力。NLP的预训练如BERT、RoBERTa、XLNet、UniLM等涌现,极大地提高了语言理解和生成能力。
但上述研究集中在单模态学习上,只能在单模态(即仅文本或图像)场景中有效使用。为了适应多模态场景,提出了一系列多模态预训练方法,如ViLBERT、VisualBERT、UNITER,大大提高了多模态信息的处理能力。然而,这些模型只能利用有限的图像-文本对,不能有效适应单模态场景。
图像知识和文本知识通常可以相辅相成。如图1所示,仅凭图像中的视觉信息很难正确回答问题。然而,如果将视觉信息与描述棒球比赛背景的文本信息联系起来,就很容易确定正确答案。此外,视觉信息可以使人们更容易理解文本所描述的场景。基于此,作者提出一个统一模态体系结构模型UNIMO,旨在用一个模型处理多场景、多模态的数据(文本数据、视觉数据和视觉-语言数据),如图2所示。


统一不同的模态的最大挑战是将它们对齐并统一到相同的语义空间中。现有的跨模态预训练模型试图在有限的图像-文本对数据中通过简单的图像-文本匹配和MLM来学习跨模态表示。它们只能学习图像-文本对的特定表示,因此无法推广到单模态场景。因此,当应用于语言任务时,它们的表现将急剧下降。UNIMO有效地利用大量的文本语料库和图像集来学习一般的文本和视觉表示。CMCL将视觉表示和文本表示对齐,并基于图像-文本对将它们统一到相同的语义空间中。
作者主要贡献总结如下:
作者利用Web上大规模的非配对文本语料库和图像集,学习更多可泛化的文本和视觉表示,提高视觉和语言理解和生成能力。
UNIMO可以有效地对单模态和多模态的理解和生成的下游任务进行微调
视觉知识和文本知识可以相互增强,在多个单模态和多模态任务中实现了更好的性能。
二、UNIMO
1.Input
UNIMO采用多层self-attention的Transformer来学习图像和文本输入的语义特征。
- 文本输入:对于文本W,首先通过BPE编码得到分词序列
,然后通过自注意机制获得基于上下文的token特征表征
。
- 图像输入:对于图片V,首先通过预训练的目标检测模型提取图像特征得到
,然后通过自注意机制获得基于上下文的图像特征表征
。
- 图像-文本对:其输入类似地可以表示为
,将输入送入到Transformer中进行编码得到特征表示,其中
和
可以作为图像V和文本W的语义特征。
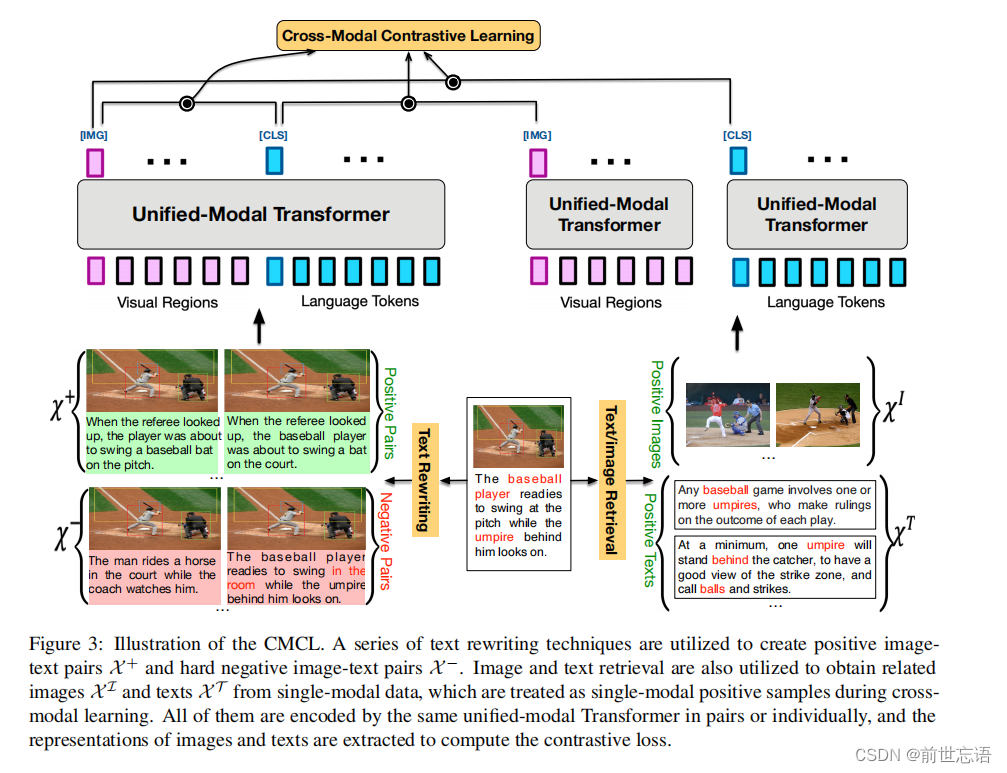
2.Cross-Modal Contrastive Learning
统一模态理解的最大挑战在于如何在同一个语义空间去学习这些单模态、多模态信息。如图2所示,模型不仅需要将整张图片和一篇描述baseball的文章联系起来,而且需要将图中的两个人以及他们的位置关系分别和文本中的“baseball player”、“umpire"和”behind“联系起来。本文提出了跨模态的对比学习方法来尝试解决这一问题。
主要解决思路是让成对的图像和文本数据在特征空间上的距离尽量接近而让非成对的图像文本数据在特征空间上的距离尽量远离。图像V和文本W的特征表示用来计算二者之间的相似度d(V,W)。如图3所示,为了实现图像和文本在不同级别的语义联合,作者设计了Text Rewriting 技术来对原始的图像描述文本进行词级别、片段级别和句子级别的改写。通过这种方式,可以为每一个图像-文本对(V, W)生成大量的正样本 和负样本
。此外,为了增强在单模态数据基础上的跨模态学习,作者还采用了图像检索和文本检索技术来为每一个图像-文本对(V, W)获得多个相关的文本样本
和图像样本
。和图像文本对的正负样本不同的是,检索出来的图像和文本因为只有弱相关性,所以是单独编码的,如图3所示。基于上述正负样本,对比学习的损失函数如下:
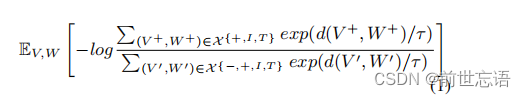
- Text Rewriting:句子改写主要是对图像的描述文本进行词级别、片段级别和句子级别的改写。句子级别:采用回译的方式,即将描述句子先翻译成其他语言,然后再翻译回源语言。片段级别和词级别:首先将图像描述内容抽象成场景图,然后从词表中随机选择词语随机替换场景图中的实体、属性或者关系节点。
- Image/Text Retrieval:为了在跨模态学习中融入更多的单模态信息,每一个图像文本对会通过从单模态数据中检索相关数据的方式来进行数据增强。具体而言,对于一张目标图片,首先会计算图片集中其他图像和该图片的相似性并进行排序,那些和目标图片有高度重合实体的图片会抽取出来提供辅助的视觉信息。文本的操作也是类似的。检索出来的图像和文本数据会单独地在Transformer中进行编码,然后他们的特征会用来计算对比学习损失。
3.Visual Learning
和BERT中的masked语言模型类似,作者也对每一张图片进行图像区域的采样,并将图像区域特征以15%的概率进行掩码处理。被掩盖的图像区域特征采用零值代替。由于一张图片的某个区域可能和其他区域有高度重叠,所以设置了一个重叠度的阈值(本文设置为0.3),高于该阈值的所有区域都会被掩盖,以防止信息泄露。
4.Language Learning
为了学习到语言理解和生成任务的语言特征,模型采用统一的encoder-decoder结构来预训练两个语言模型任务:双向预测和seq2seq生成。
- Bidirectional prediction:给定一个序列
- Seq2Seq generation:对于给定序列,进行片段级别的反复抽样,直到25%的片段被选中。对于每一次采样,首先假定片段长度满足均匀分布 l~U(4,32)来进行采样。被选中的片段
会在首尾拼接符号[CLS]和[SEP],这些被选中的片段会拼接在一起作为目标序列T,去掉这些片段的原始给定序列作为源序列S。
三、Experimental Settings
1.Pre-training Dataset
训练UNIMO采用的数据集包括三部分:文本数据集,图片集,图片-文本对数据集。文本数据集包括两个大规模的语料BookWiki和OpenWebText,这也是RoBerta训练数据的一部分。图片集包括OpenImanges的一个子集以及COCO数据集。图像-文本对数据集主要包括:COCO,VG,Conceptual Captions(CC)和SBU Captions。数据集统计如表5所示。

2.Implementation Detail
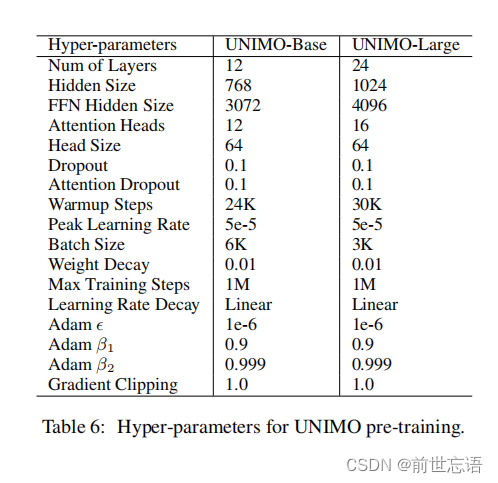
UNIMO模型训练时考虑了两种模型大小:12层transformer的UNIMO-base模型和24层transformer的UNIMO-large模型,文本序列和图片区域特征的最大长度分别为512和100。UNIMO-base模型的初始化是基于RoBERTa-base模型,UNIMO-large模型的初始化是基于RoBERTa-large模型,两个模型训练步数都大于500K。优化器参数:采用Adam优化器,初始学习率5e-5,然后线性衰减。训练参数如表6。
3.Finetuning Tasks
- 单模态的语言理解和生成:生成任务包括在CoQA数据集上的生成式会话问答任务,在SQuAD1.1数据集上的问题生成任务,CNN/DailyMail数据集上的文本摘要任务,Gigaword数据集上的句子压缩任务;理解任务包括SST-2数据集上的情感分类,MNLI数据集上的自然语言推理,CoLA数据集上的语言可接受性分析以及STS-B数据集上的语义相似度计算任务。
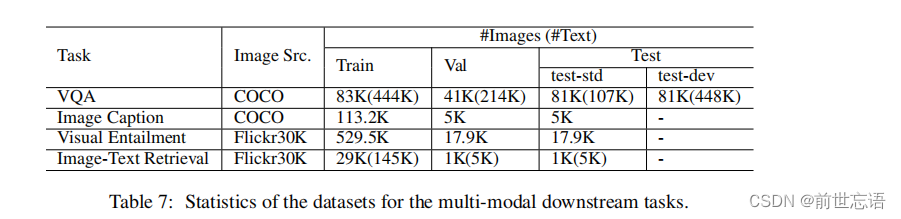
- 多模态的视觉-语言理解和生成:VQA2.0数据集上的VQA,COCO数据集上的图像描述生成,SLNI-VE数据集上的视觉推理任务和Flickr30k数据集上的图像文本检索任务。多模态任务的数据集情况如表7。
四、Results and Analysis
1.Multi-Modal tasks
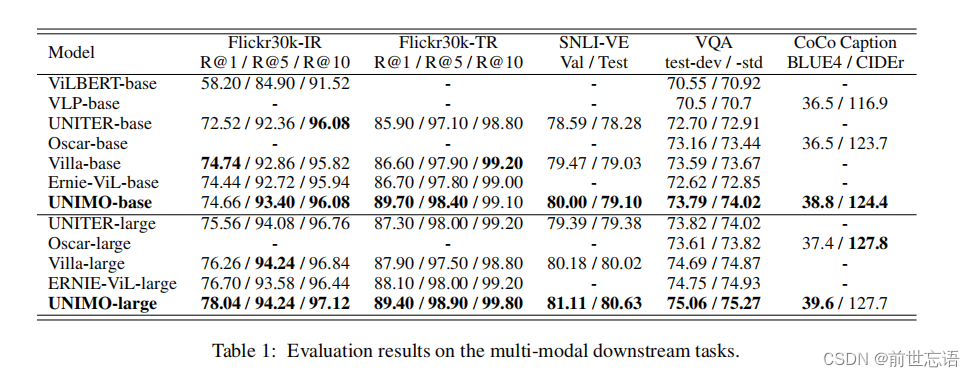
多模态任务的评价结果如表1所示。比较了现有的大多数多模态预训练模型,包括ViLBERT、VLP、UNITER、Oscar、Villa、ERNIE-ViL 。结果表明,UNIMO对几乎所有基准都取得了最佳结果。
2.Single-Modal tasks
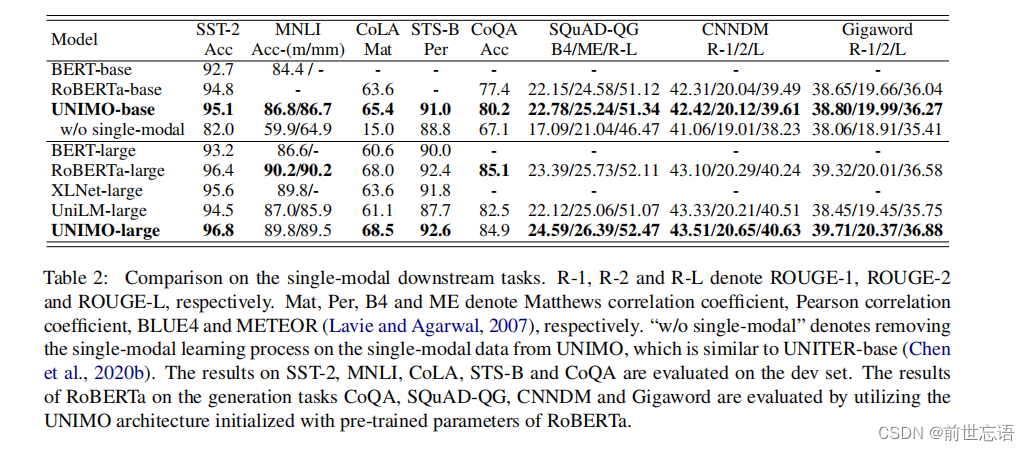
作者比较了现有的预训练语言模型(PLMs),包括BERT、RoBERTa、XLNet、UniLM。表2中的比较结果表明,在语言理解和生成任务上,UNIMO取得了比现有PLM更好或相当的性能。
3.Mutual Enhancement of Text and Vision
作者通过消融研究表明,统一模态体系结构可以帮助文本知识和视觉知识在统一语义空间中相互增强。
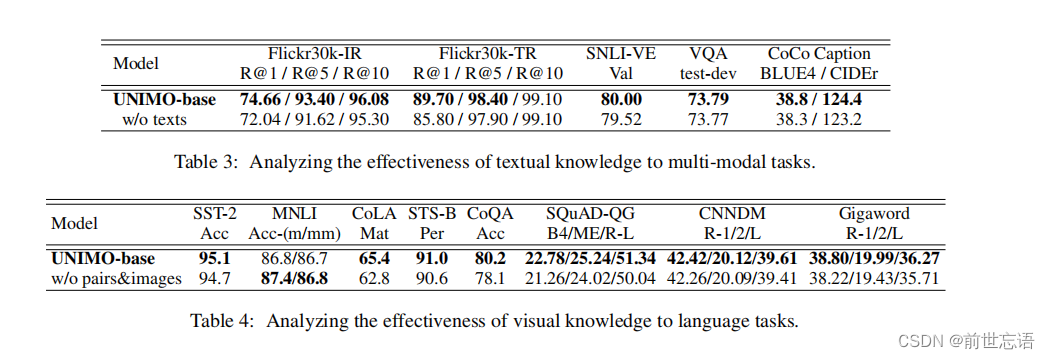
- Text Enhance Vision:将UNIMO的文本语料库中的语言学习过程(即“w/o texts”)删除,并比较它们在多模态任务中的表现。表3总结了比较结果,结果显示“w/o texts”模型的性能在多模态理解和生成任务上一致下降。研究结果表明,语篇语料库中的语义知识通过更多的语义信息增强了视觉语言任务的跨模态学习。
- Vision Enhance Text:从预训练数据集(即“w/o pairs&images”)中删除了图像和图像-文本对,并比较了它们在单模态语言任务中的表现。表4总结了对比结果,结果表明,去除视觉数据后,“w/o pairs&images”模型在大多数语言理解任务和所有语言生成任务上的性能明显下降。结果表明,视觉知识可以使模型在统一的语义空间中学习更健壮和可泛化的表示,从而增强语言任务。
五、Conclusion
在这项工作中,作者提出了一种统一模态预训练体系结构UNIMO,以利用大规模的非配对文本语料库和图像集合进行跨模态学习。作者验证了UNIMO为文本知识和视觉知识在统一的语义空间中相互促进提供了一种有效的方式,并且UNIMO成功地适应了单模态和多模态的理解和生成任务。通过这种方式,统一模态模型在多模态和单模态下游任务上都优于以往的方法。
在未来的工作中,作者将专注于端到端的视觉和语言统一学习,以及更大规模的模型和数据量。其实就是最近发表的UNIMO-2。
参考(具体细节见原文)
原文链接:https://arxiv.org/pdf/2012.15409![]() https://arxiv.org/pdf/2012.15409
https://arxiv.org/pdf/2012.15409
代码链接:Research/NLP/UNIMO at master · PaddlePaddle/Research · GitHubnovel deep learning research works with PaddlePaddle - Research/NLP/UNIMO at master · PaddlePaddle/Research https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO 参考博客:UNIMO详解:基于跨模态对比学习的统一模态理解和生成 - 知乎 (zhihu.com)
https://github.com/PaddlePaddle/Research/tree/master/NLP/UNIMO 参考博客:UNIMO详解:基于跨模态对比学习的统一模态理解和生成 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/384325550
https://zhuanlan.zhihu.com/p/384325550















 4030
4030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











