







本文以《中国金融》银行间市场金融科技标准化建设一文为原始材料,对该文章做了自定义分词,并统计词频,最后绘制词云。以期通过机器来认识机器思维和人的思维之间存在的一些差异。对《杀死一只知更鸟》中律师阿蒂克斯的这句话自己有了很深的认同感--------去掉那些形容词,剩下的就是事实了!名词在人们思维中确实是扮演了非常重要的角色,因为名词往往用来说明时间、地点、人物、事情、概念、实体、类、关系或联系、属性等等重要信息!
目录
1.效果图
2.代码
3.中英文去停用词词集
4.自定义字典
5.最终效果:

1.效果图

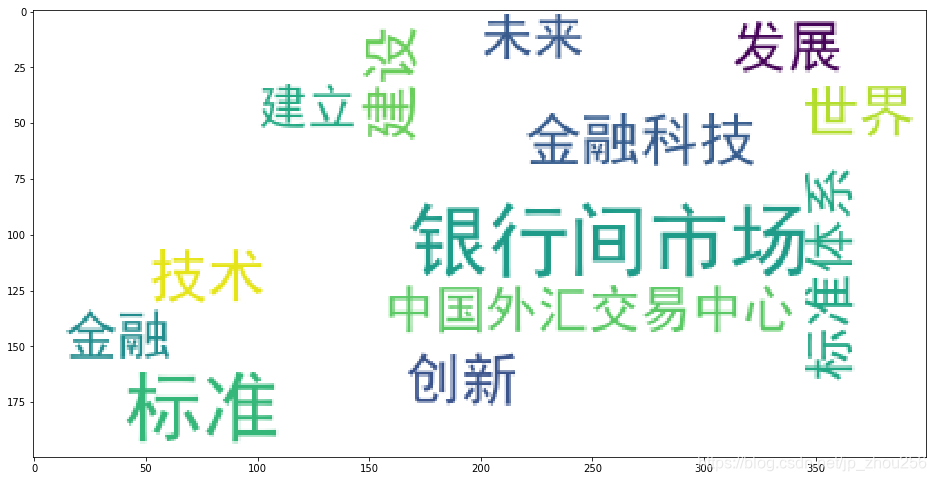
2.代码
# -*- coding: utf-8 -*-
__author__ = 'jp_zhou'
import warnings
warnings.filterwarnings("ignore")
import jieba #分词包
import numpy #numpy计算包
import codecs #codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['figure.figsize'] = (16.0, 16.0)
from scipy.misc import imread
bimg=imread('C:/Users/Administrator/Desktop/timg.jpg') #读取背景图片
from wordcloud import WordCloud,ImageColorGenerator #词云包
jieba.load_userdict("C:/Users/Administrator/Desktop/cefts_dict.txt") # 加载字典
with open('C:/Users/Administrator/Desktop/外汇.txt','r') as fp:
content=fp.readlines()
segment=[]
for line in content:
try:
segs=jieba.lcut(line)
for seg in segs:
if len(seg)>1 and seg!='\r\n':
segment.append(seg)
except:
print(line)
continue
#去停用词
import pandas as pd
words_df=pd.DataFrame({'segment':segment})
#words_df.head()
stopwords=pd.read_csv("F:/Datasets/NLP_project/NLP_project/data/stopwords.txt",index_col=False,quoting=3,sep="\t",names=['stopword'], encoding='utf-8')#quoting=3全不引用
#stopwords.head()
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
#统计词频
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":np.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
#words_stat.head()
#1.传统词云绘制
wordcloud=WordCloud(font_path="data/simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
wordcloud=wordcloud.fit_words(word_frequence)
#plt.imshow(wordcloud)
bimgColors=ImageColorGenerator(bimg)
plt.axis("off")
wordcloud=wordcloud.fit_words(word_frequence)
plt.imshow(wordcloud.recolor(color_func=bimgColors)) #用词汇填充背景图片
#2.对词频字典进行排序
#对字典进行排序功能
wordcloud=WordCloud(font_path="data/simhei.ttf",background_color="white",max_font_size=36)
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
list1= sorted(word_frequence.items(),key=lambda x:x[1]) #这样形式的字典排序后,返回的结果是一个list(),list中的元素是tuple对象,tuple对象的元素分别是字典的key和value。
#将排好序的list(tuple())转换成dict
word_frequence11={}
for i in range(len(list1)):
word_frequence11[list1[i][0]]=list1[i][1]
wordcloud=wordcloud.fit_words(word_frequence11)
plt.imshow(wordcloud)
#3.对词频字典做排序并进行过滤处理
wordcloud=WordCloud(font_path="data/simhei.ttf",background_color="white",max_font_size=36)
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
list1= sorted(word_frequence.items(),key=lambda x:x[1]) #这样形式的字典排序后,返回的结果是一个list(),list中的元素是tuple对象,tuple对象的元素分别是字典的key和value。
#将排好序的list(tuple())转换成dict
word_frequence11={}
for i in range(len(list1)):
if list1[i][1]>7: #过滤规则:只取词频大于1,2,3,4,5,6,7等等的词汇做展示
word_frequence11[list1[i][0]]=list1[i][1]
wordcloud=wordcloud.fit_words(word_frequence11)
plt.imshow(wordcloud)
#4.查看词频最高的Top 20词汇
from collections import Counter
c = Counter(word_frequence).most_common(20)
print(c)
TOP 20 词汇列表
[('银行间市场', 26), ('标准', 25), ('技术', 12), ('金融科技', 12), ('建设', 12), ('世界', 11), ('创新', 11),
('发展', 11), ('标准体系', 10), ('金融', 10), ('中国外汇交易中心', 9), ('未来', 9), ('建立', 8), ('国际 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 558
558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









