







文章标题:《Do Pre-trained Models Benefit Knowledge Graph Completion?
A Reliable Evaluation and a Reasonable Approach》ACL 2022
文章地址:
文章介绍
最近,预训练语言模型被广泛用于知识图谱任务当中,但是这些模型却并没有取得SOTA的结果。这篇文章的作者发现导致上述情况的原因一共有两个,(1)错误发评估方式。目前关于知识图谱三元组完整性的判断大多集中于封闭世界假设(closed world assumption,CWA),从而低估了题PLM为代表的KGC模型,因为它们融合了更多的外部知识。(2)PLM的使用不当。现在基于PLM的模型只是简单将实体和关系拼接以后直接输入到模型当中,而这会导致句子不连贯,无法充分利用PLM中的隐含知识。为了解决上述问题,作者设计了开放世界假设(open-world assumption,OWA)下的更准确的评估方式,并通过人工的方式手动检查已有知识图以外的三元组的正确性,此外,在引入了提示学习(prompt learning)基础上提出了PKGC模型。其基本思想为见每个三元组及其支持信息转化为自然语言提示句,再输入到PLM模型中分类。实验证明PKGC在CWA和OWA上均有良好的表现。
现有局限
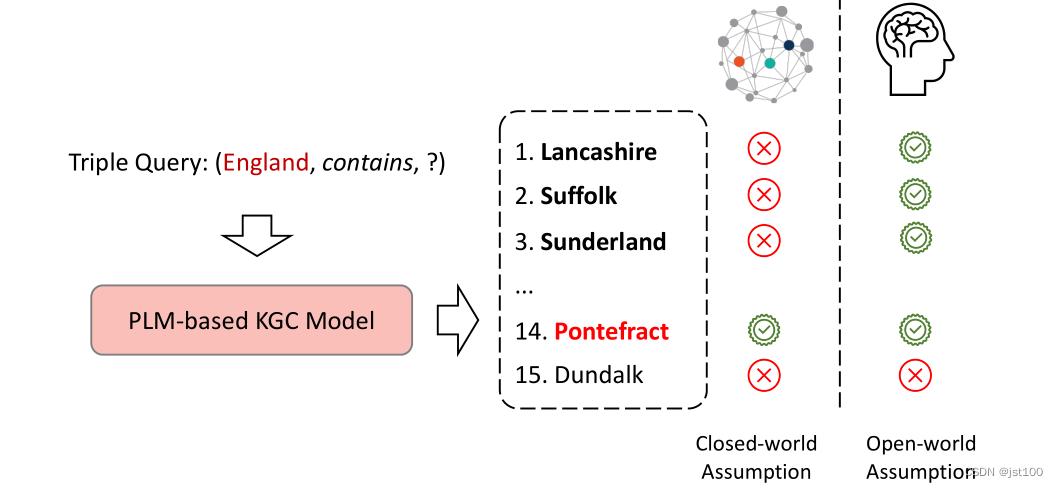
如上图所示,如果是在封闭世界的假设下,很
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









