






前言
BitNet是微软近期推出的极限精简的推理框架,官方的介绍里,详细介绍了它的架构优势,以及和其他模型的对比实验,总结起来就是不挑设备,不占资源,不减性能!俩字儿牛x,仨字儿很牛x,四个字儿…
但毕竟还是小尺寸模型,笔者在本地试了一下,多数情况下基本是不可用的哈,但在边缘计算场景可能会很有用武之地的,算是个小灵通吧。大家感兴趣可以到官方仓库看一下。
地址:https://github.com/microsoft/BitNet
这里呢,咱们就从开发者角度,0帧起手,在本地跑一下他这个模型小灵通~
环境配置
虽然咱这是0帧起手,但一些常见的环境安装和配置,也会一笔带过,给出官方文档地址,不过多赘述。也正犹豫是0帧起手,所以各路大神们可以略过啦
此外,这里笔者的演示环境是在Windows环境。
c++相关环境
windows环境下,官方文档推荐大家安装Visual Studio 2022,在Installer中,包含了运行本模型需要的大部分运行环境,包括CMake,clang等,安装步骤如下。
打开Visual Studio Installer,点击【修改】按钮,如果没有安装Visual Studio 2022的话,直接进入安装窗口。
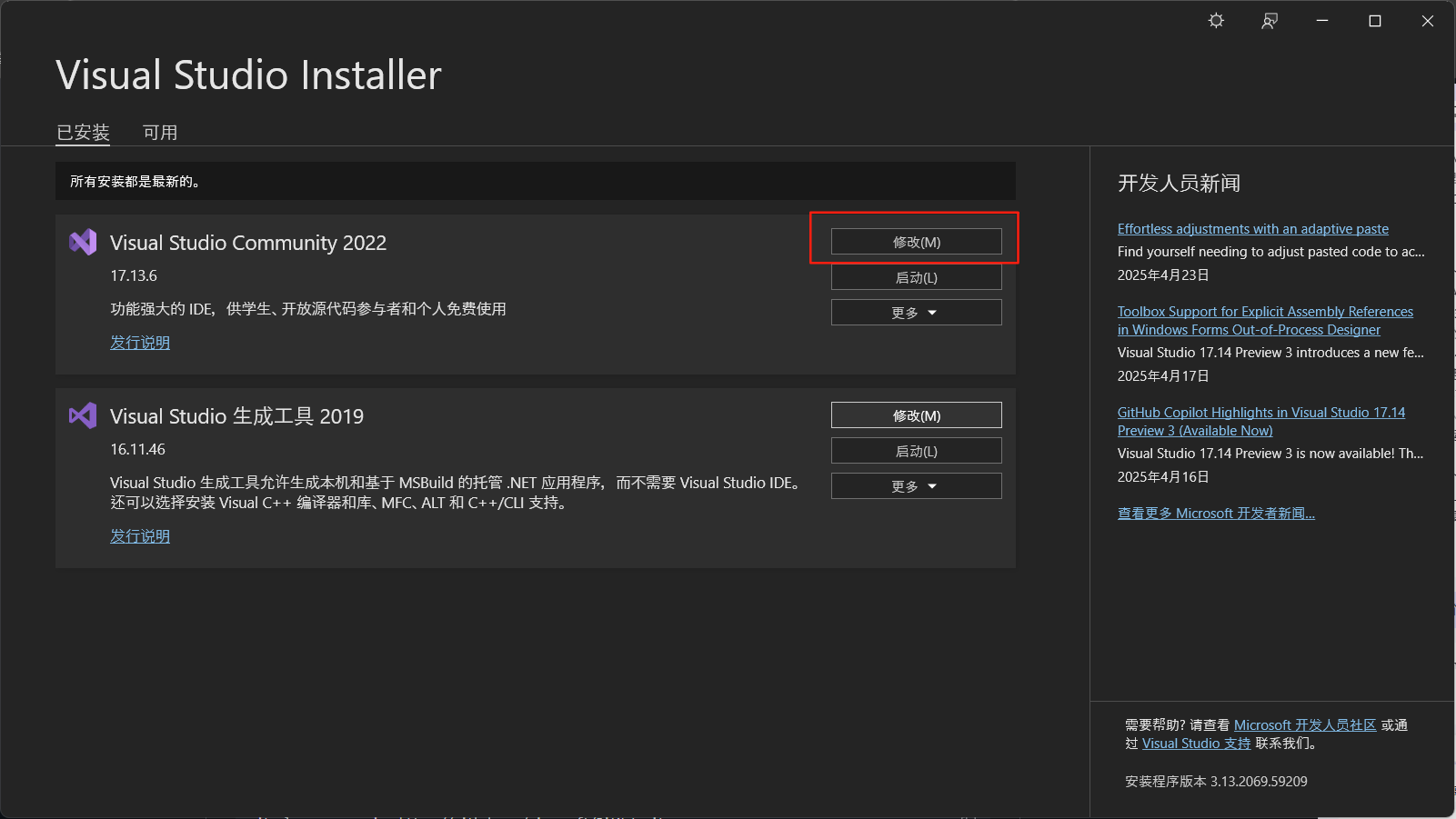
勾选“使用C++的桌面开发”选项
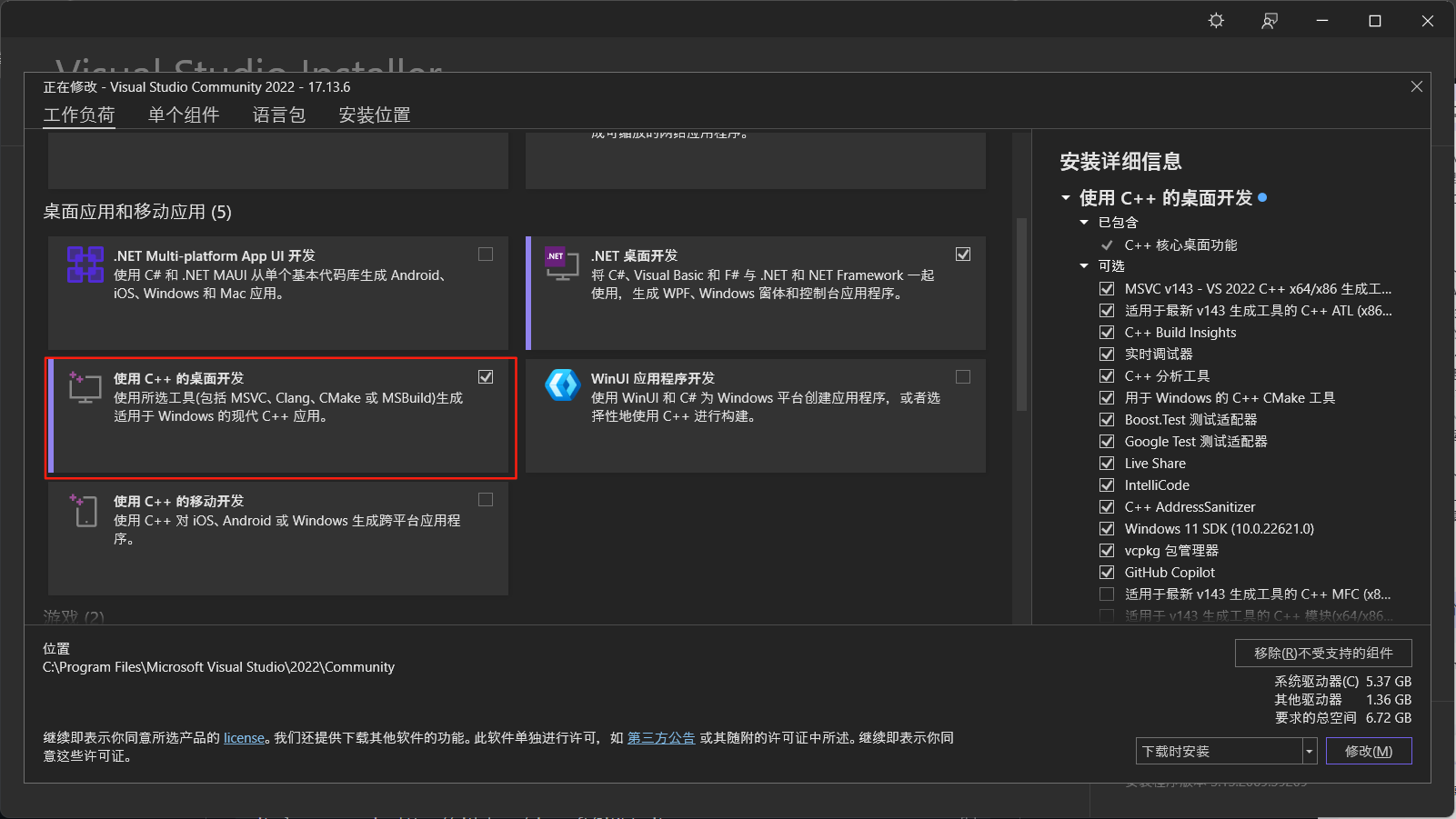
切换到“单个组件”选项卡,检索并勾选“适用于Windows的C++ CMake工具”,“对LLVM(clang-cl)工具集的MSBuild支持”以及“适用于Windows的C++ Clang编译器(版本号)”
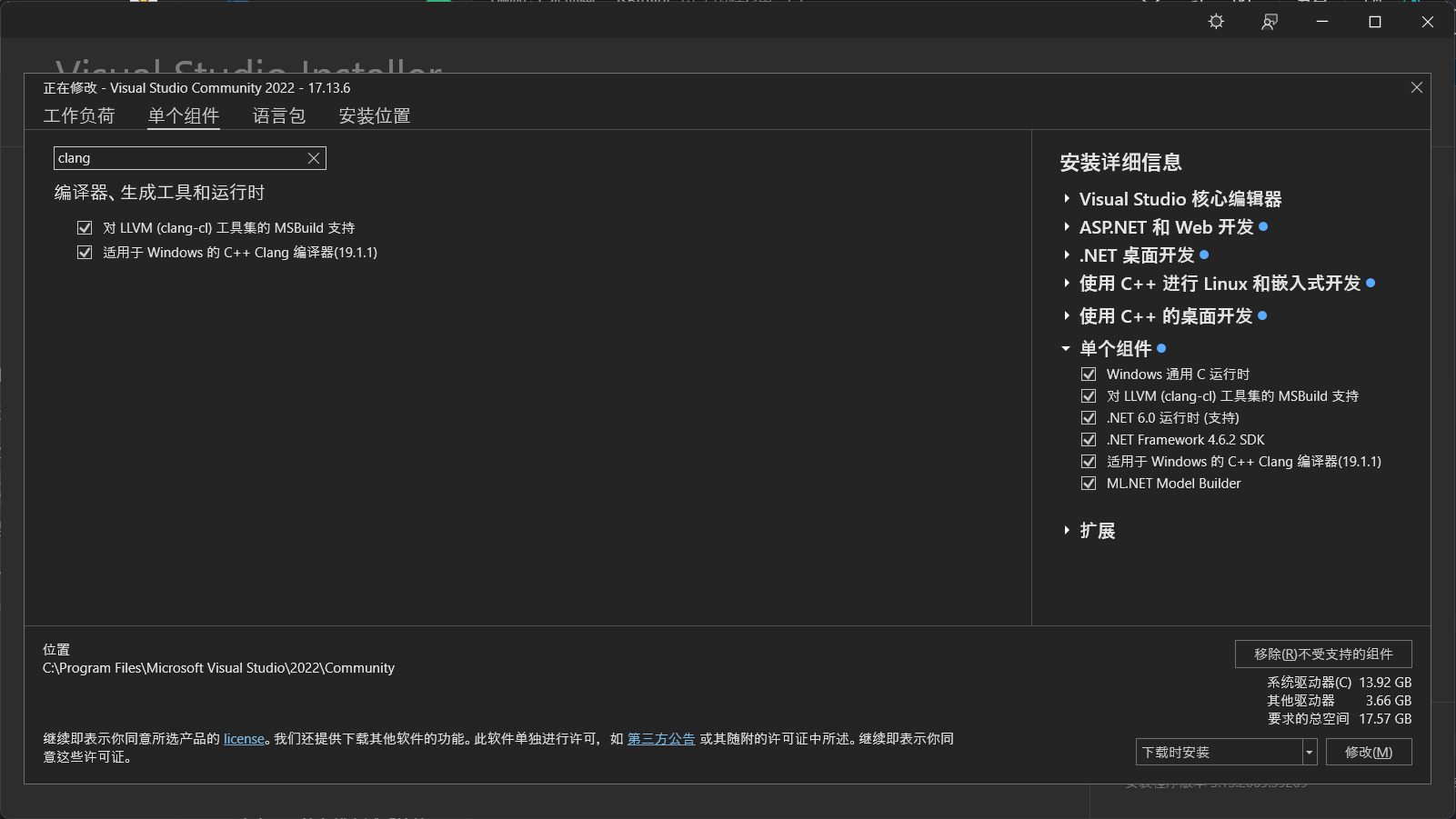
完成之后,点击“修改”或者“安装”即可。
注意,这样一通操作下来,空间占用会超过10G,要提前查看自己机器的存储空间是否吃紧。
当C++相关环境配置完成后,后续的步骤,都需要在**开发者的命令提示符或者PowerShell环境**下进行,这点官方文档也给出了重点说明

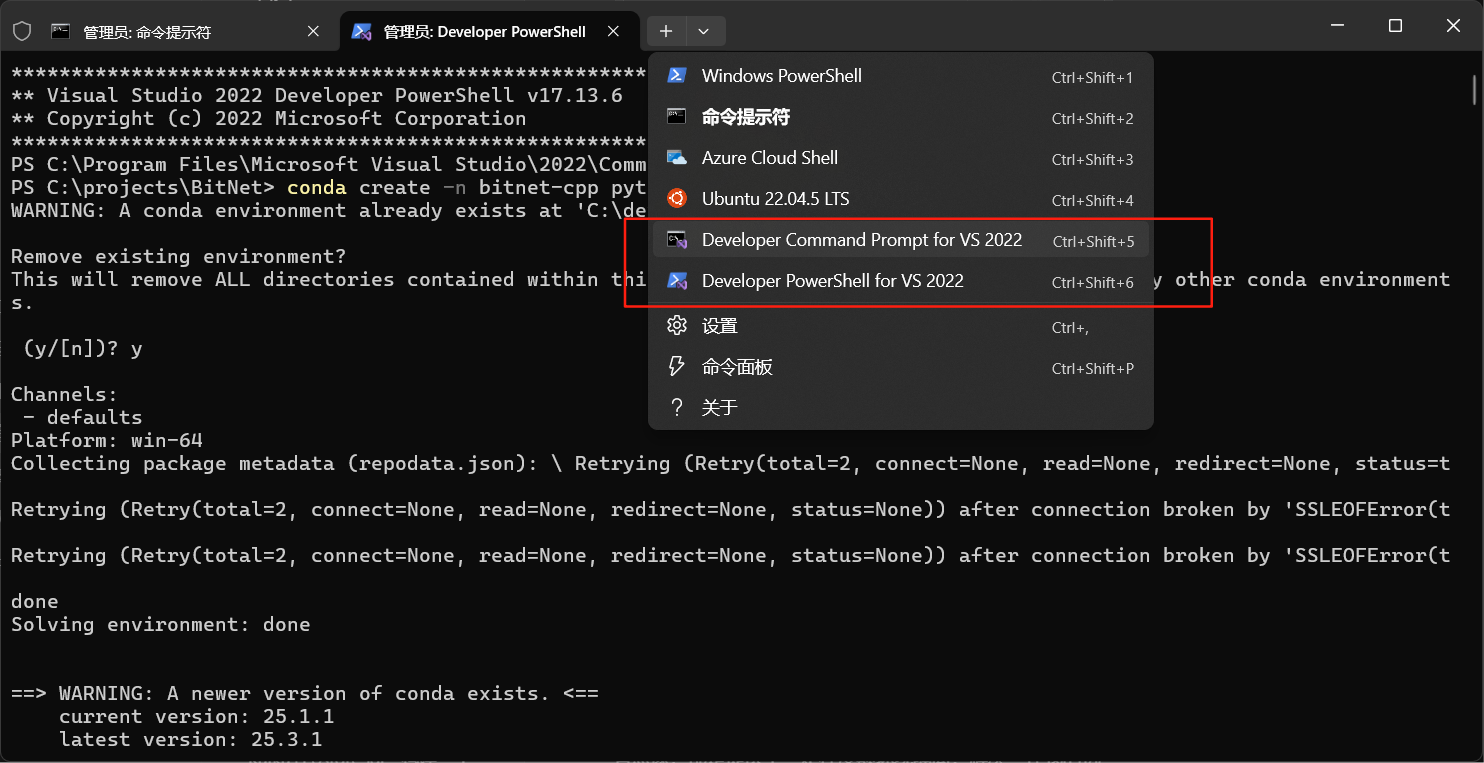
Conda
Conda是一个开源的软件包管理和环境管理系统,主要用于管理软件包和创建独立的计算环境。它跟Docker的设计理念有点像,都是提供了一定程度额环境隔离,解决“在我的机器上可以运行”的问题。
更具体的概念,大家可以自行Gpt或者到Conda官网看一下哈,咱们只说配置。
下载
首先,咱们到Conda的官网进行下载,这里呢,官方提供了2种下载模式,一个是大而全的Anaconda Installer,另一种是精简的Miniconda Installer,均提供了Win,Mac和Linux三种的安装包。
关于选择哪种安装模式,官方也给出了专门的介绍文档,大家可以参考一下,地址:https://www.anaconda.com/docs/getting-started/getting-started
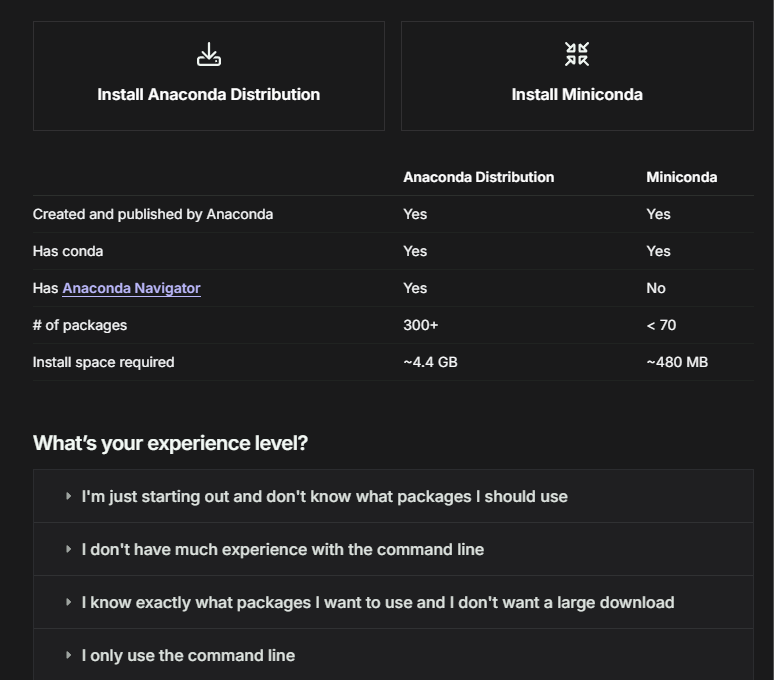
我这里呢,使用的是Miniconda的安装方式。
安装配置
安装过程比较简单,就是双击安装包,一路下一步即可!
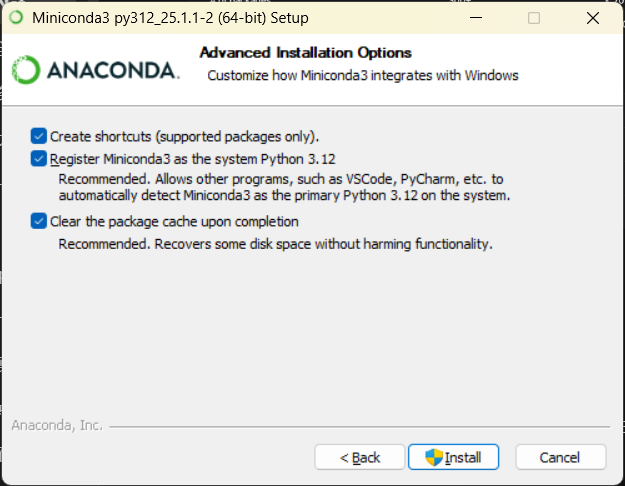
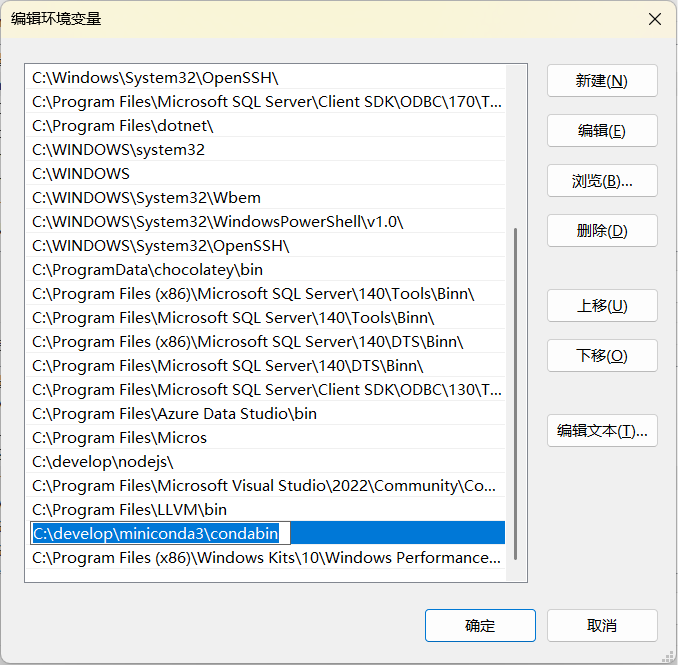
注意,由于我这里使用的精简版安装包,所以有一些配置是需要手动进行的,这里主要是配置一下环境变量,把Miniconda安装路径下的condabin配置到环境变量的path里。
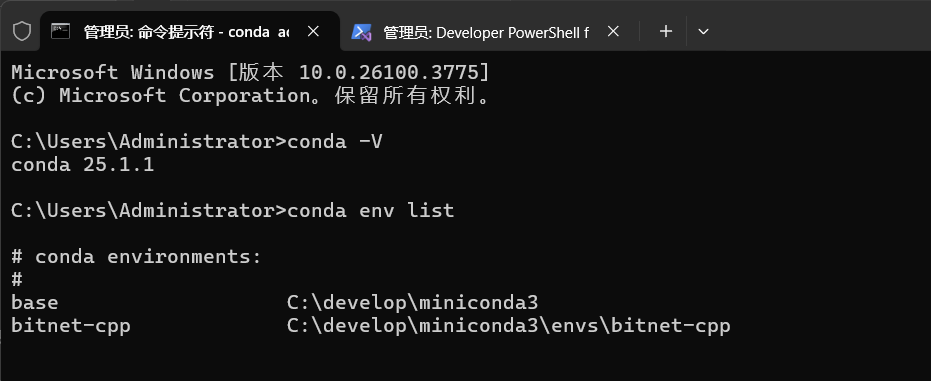
安装完成后,在控制台里验证一下安装
# 输出一下版本信息
conda -V
# 列一下环境列表
conda env list
正确输出信息即为安装成功
配置依赖
Conda安装完成后,创建Conda环境,并安装依赖,这一段没啥说的,直接按文档来即可。
# (Recommended) Create a new conda environment
conda create -n bitnet-cpp python=3.9
conda activate bitnet-cpp
pip install -r requirements.txt
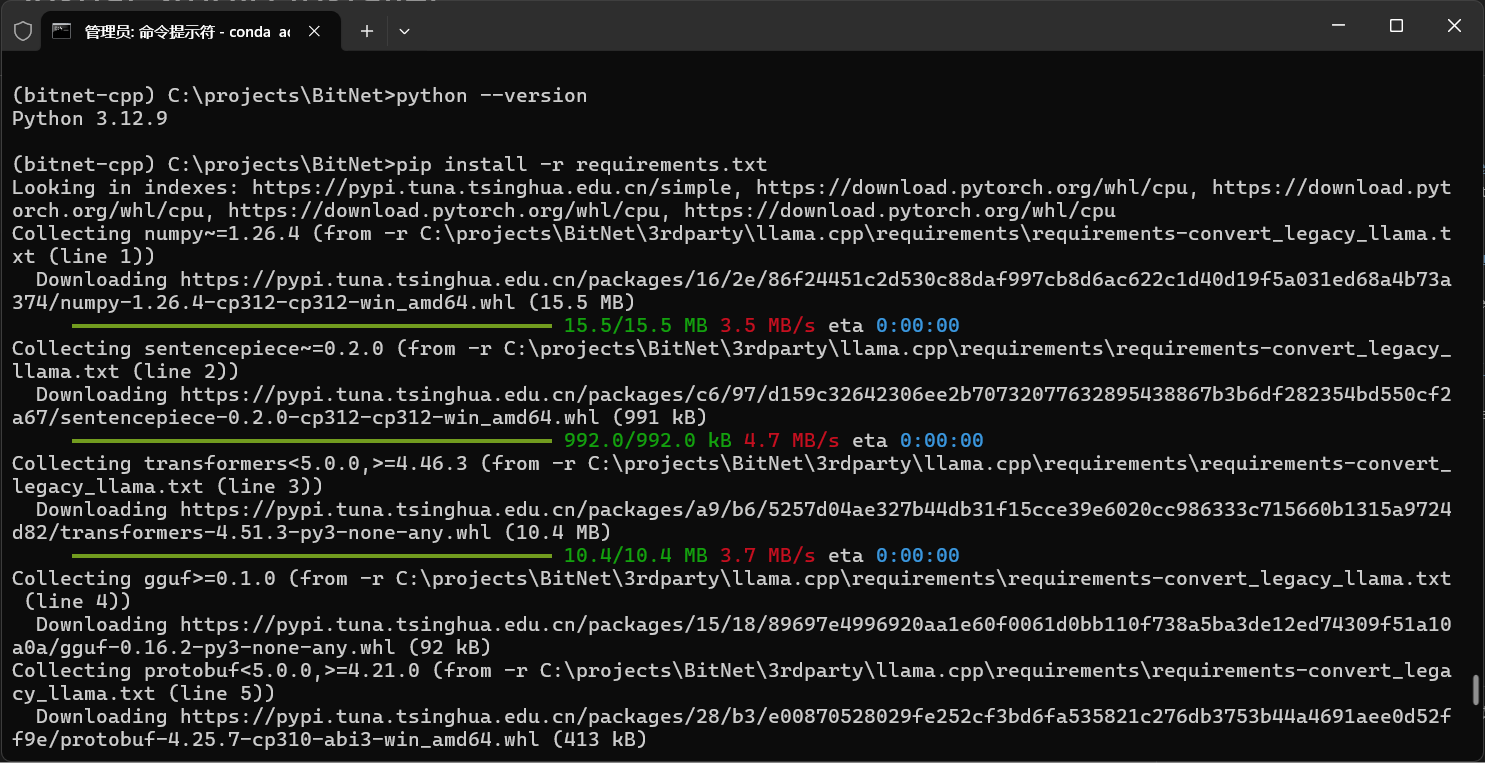
下载模型
文档里介绍的方式是,通过huggingface-cli进行下载,这里我实际测试,是需要科学上网才能正常下载的,大家到这如果进行不下去,可以试试直接到huggingface官网手动把模型下载下来应该也行,这个我自己没有试过,模型地址:https://huggingface.co/microsoft/bitnet-b1.58-2B-4T-gguf/tree/main。
我这里因为已经下载好了,所以用huggingface-cli执行下载,就直接显示完成。
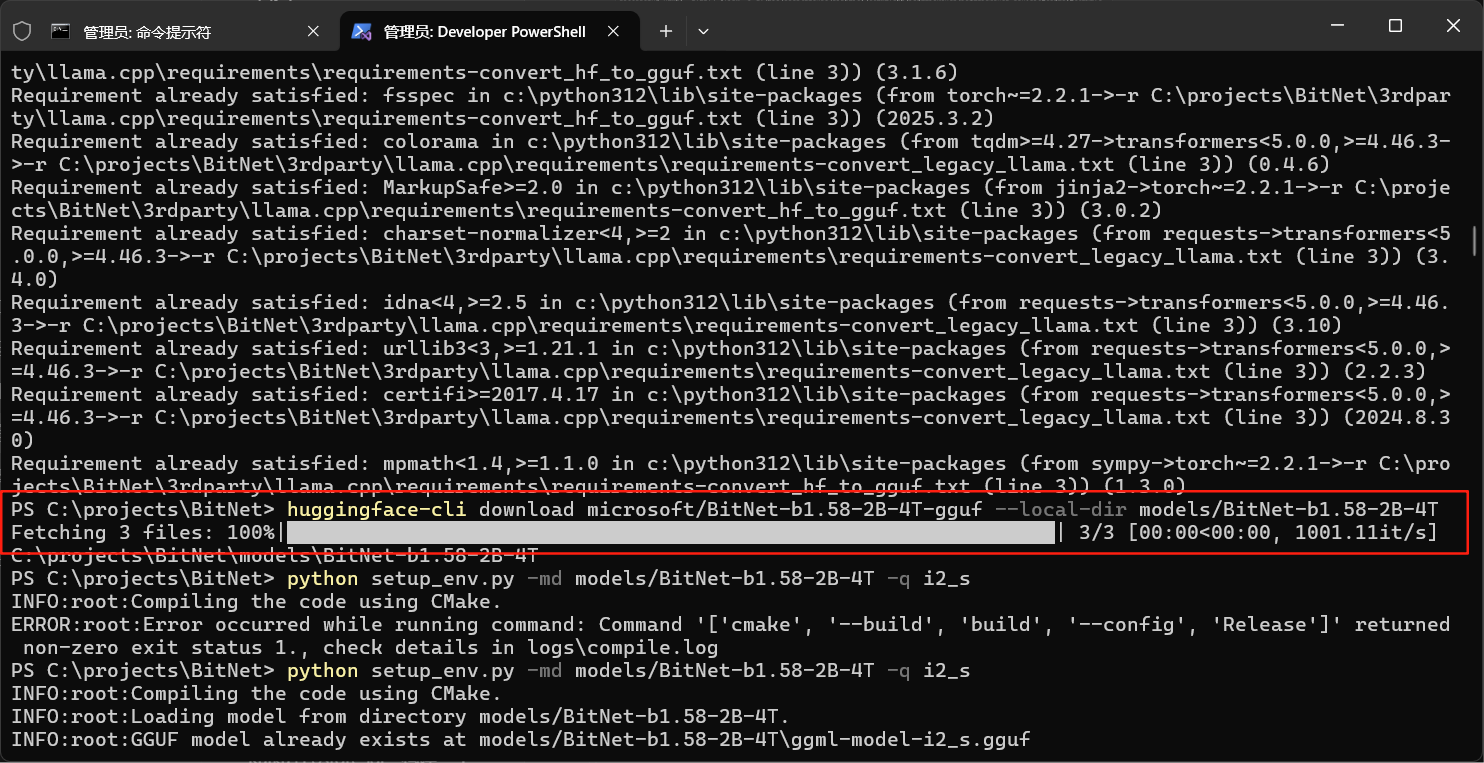
编译
按文档说明执行
python setup_env.py -md models/BitNet-b1.58-2B-4T -q i2_s
这里需要注意的是,截止到2025.4.27号,如果你是在这之前克隆的bitnet库,那到编译这一步大概率是走不通的,这点官方文档里也说明了,由于本项目上游的llama.cpp项目有几个文件存在bug,c++文件丢失了引用,所以我们需要手动的把这几个文件修复一下,官方也给了修复地址在这里:https://github.com/tinglou/llama.cpp/commit/4e3db1e3d78cc1bcd22bcb3af54bd2a4628dd323
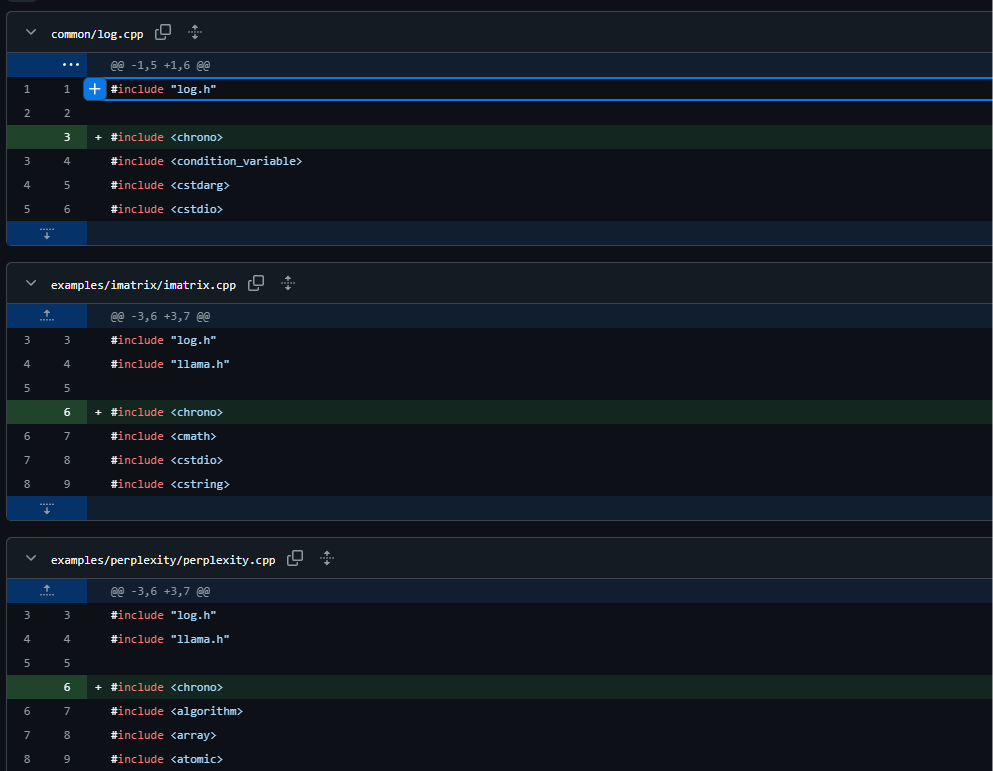
这里我们就直接参照他的说明修改一下就行,不会c++也没问题,分别修复一下四个文件
- …\3rdparty\llama.cpp\common\common.cpp
- …\3rdparty\llama.cpp\common\log.cpp
- …\3rdparty\llama.cpp\examples\imatrix\imatrix.cpp
- …\3rdparty\llama.cpp\examples\perplexity\perplexity.cpp
…代表bitnet项目的根目录。
修复的内容是一样的,在头部添加一下引用即可
#include <chrono>
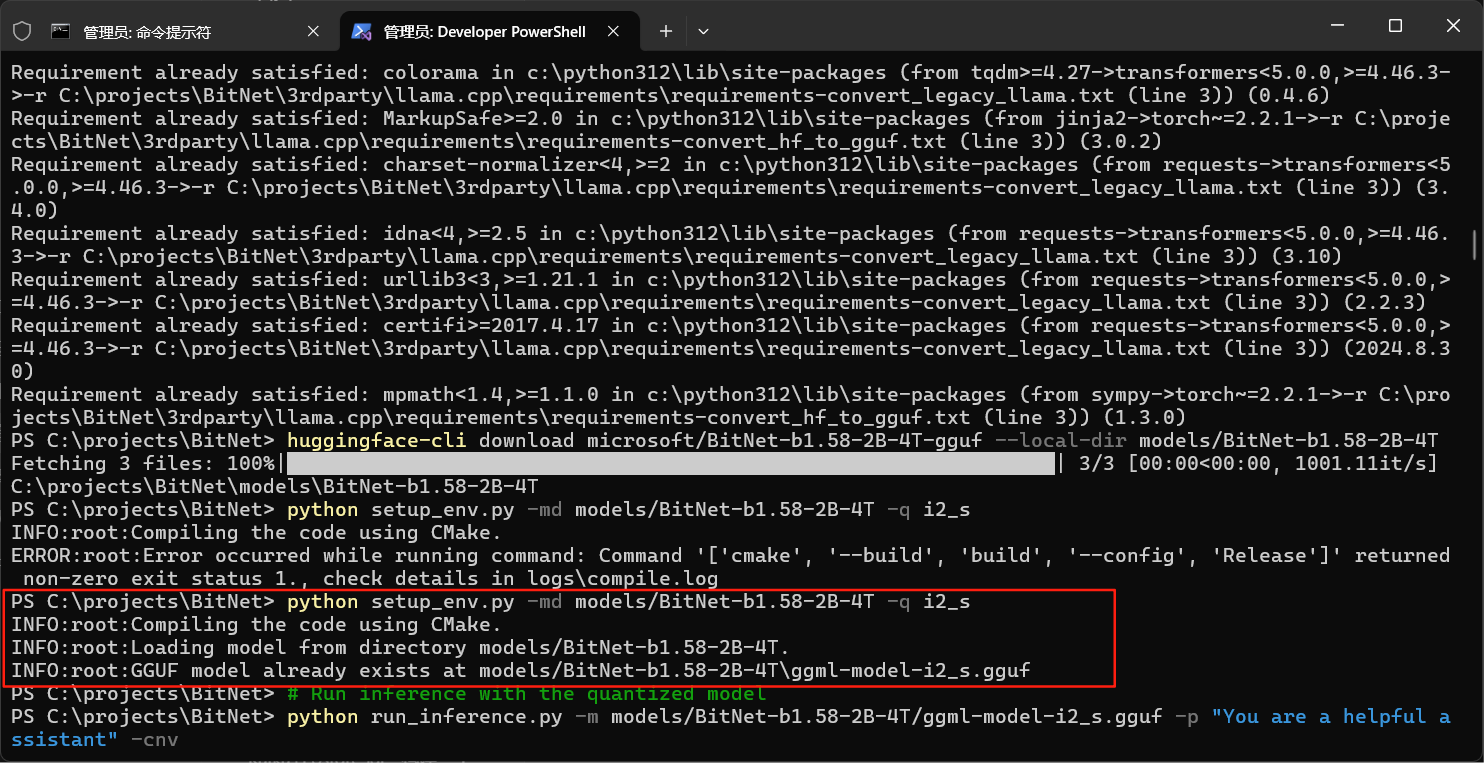
然后,基本就可以通过编译了,这里可能需要稍等一小会儿才会编译完成。
其他环境
本地测试
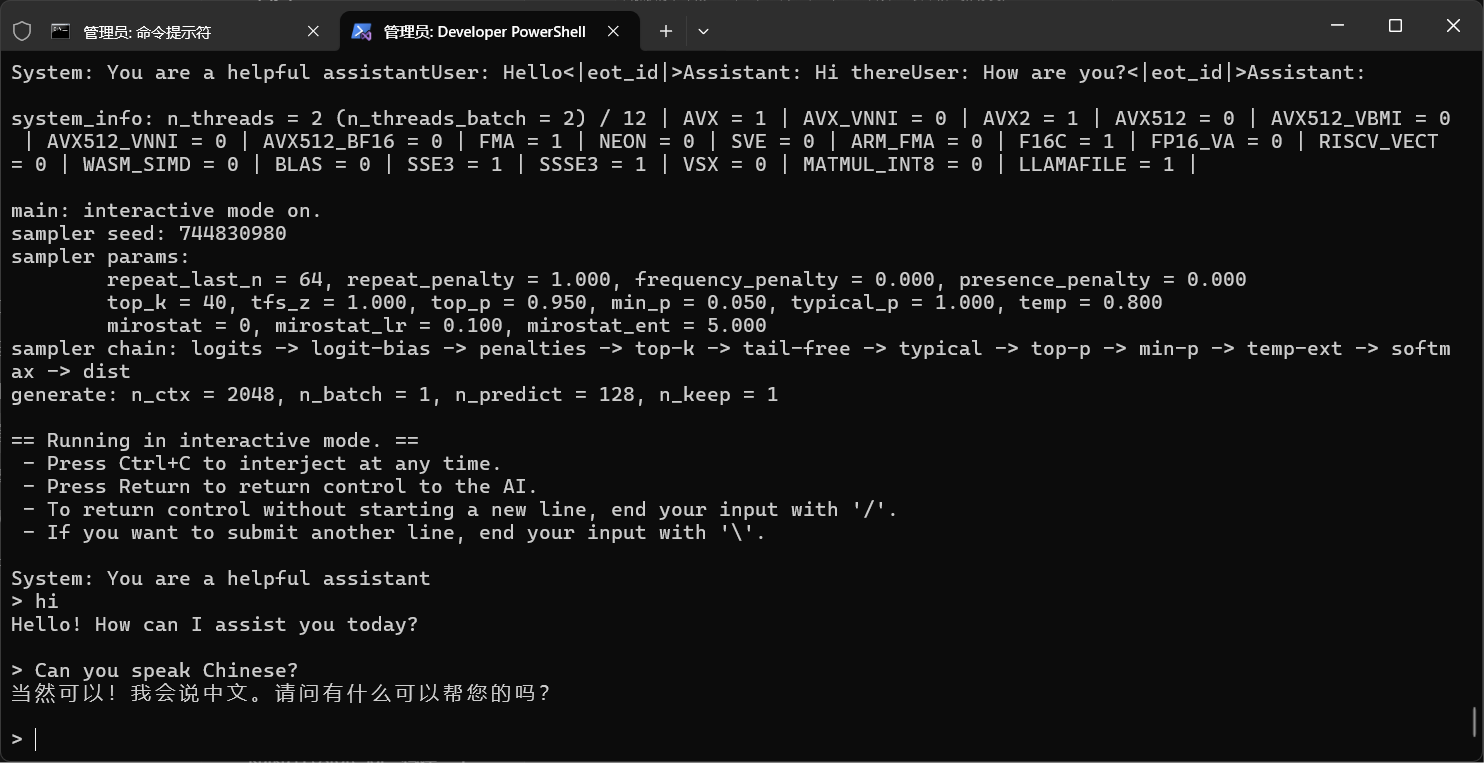
经过漫长的环境配置之后,终于可以测试了,执行以下代码,启动对话窗口。
python run_inference.py -m models/BitNet-b1.58-2B-4T/ggml-model-i2_s.gguf -p "You are a helpful assistant" -cnv
结束语
至此,我们就基本完成了本地部署BitNet的工作了,就像文章开头说过的,目前,本地跑的BitNet模型,并不是一个全精度模型,尺寸很小,所以可以流畅的运行在CPU环境下,且内存占用率极低,但实际测试大部分的对话它是理解错误的,也就是不是很可用,但这东西如果专门用来探索边缘计算的场景,经过调教之后,应该也能发挥很大的用处。
好啦,就这样啦,期待下一篇更有趣的探索。


















 1178
1178

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











