







台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。
这篇文章是学习本课程第7-9课所做的笔记和自己的理解。
Lecture 7: Backpropagation
神经网络可能有百万数量级的参数,为了在梯度下降时有效地计算梯度,使用反向传播。
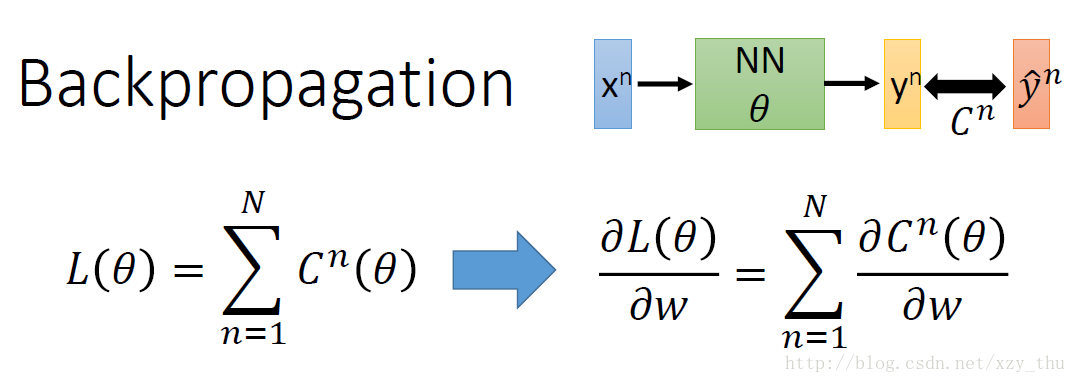
下面只考虑一笔data对参数的偏微分。
根据链式法则, ∂C∂w=∂z∂w∂C∂z” role=”presentation” style=”position: relative;”>∂C∂w=∂z∂w∂C∂z∂C∂w=∂z∂w∂C∂z 称为后向过程。
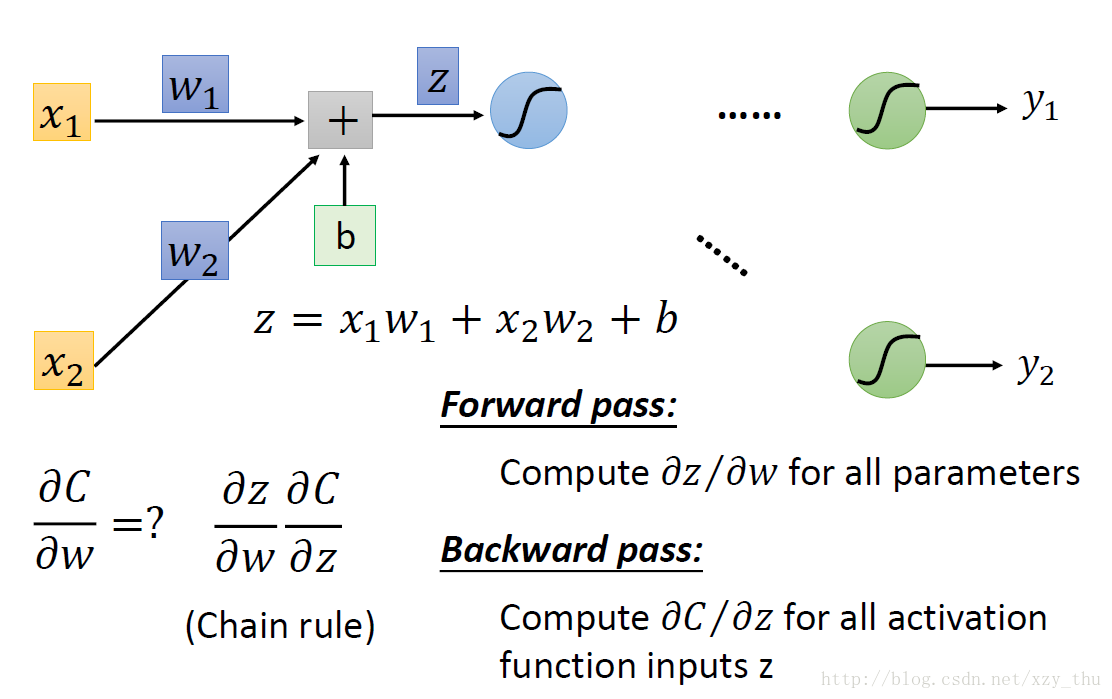
前向过程
前向过程:∂z∂wi=” role=”presentation” style=”position: relative;”>∂z∂wi=∂z∂wi=
后向过程
后向过程:根据链式法则, ∂C∂z=∂a∂z∂C∂a” role=”presentation” style=”position: relative;”>∂C∂z=∂a∂z∂C∂a∂C∂z=∂a∂z∂C∂a 。
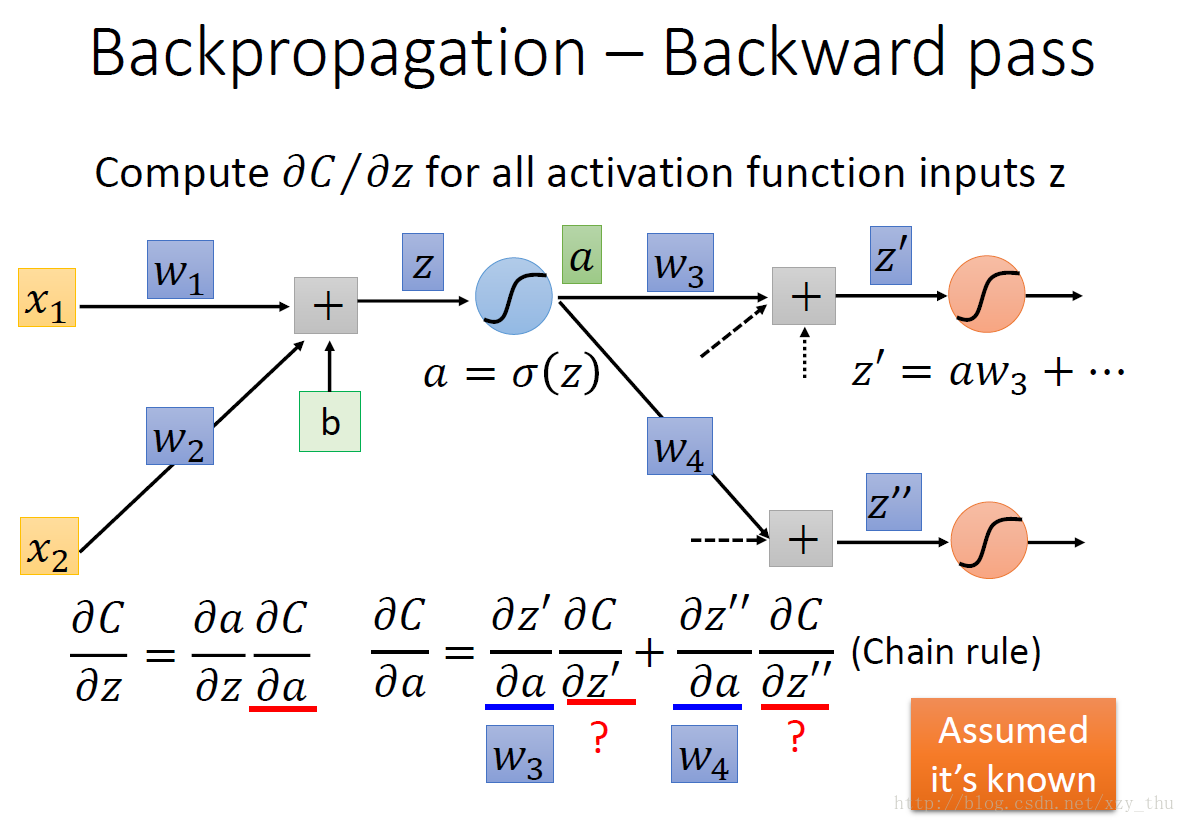
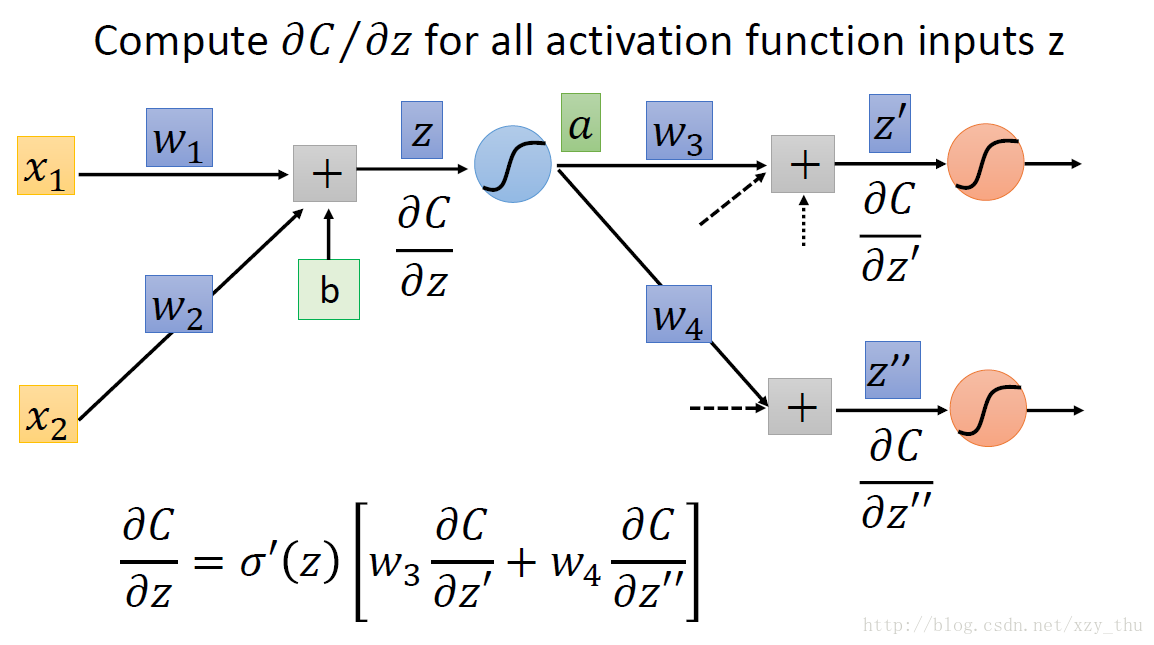
从另一观点看待上面的式子:有另外一个neuron(下图中的三角形,表示乘法/放大器),input是∂C∂z′” role=”presentation” style=”position: relative;”>∂C∂z′∂C∂z′。
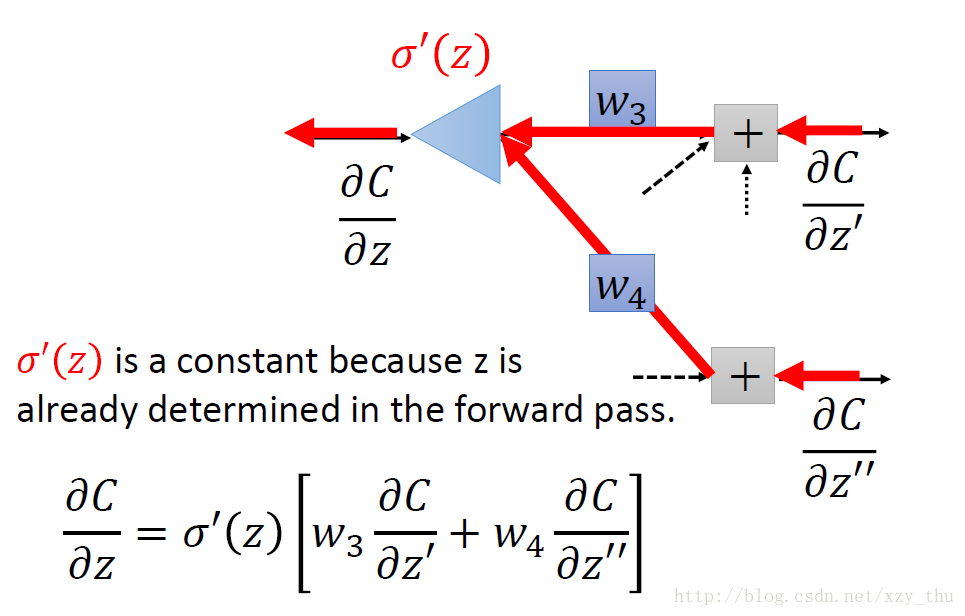
现在的问题是,如何计算∂C∂z′” role=”presentation” style=”position: relative;”>∂C∂z′∂C∂z′ 。
第一种情况,z′,z″” role=”presentation” style=”position: relative;”>z′,z′′z′,z″ 所接的neuron是output layer的neuron。
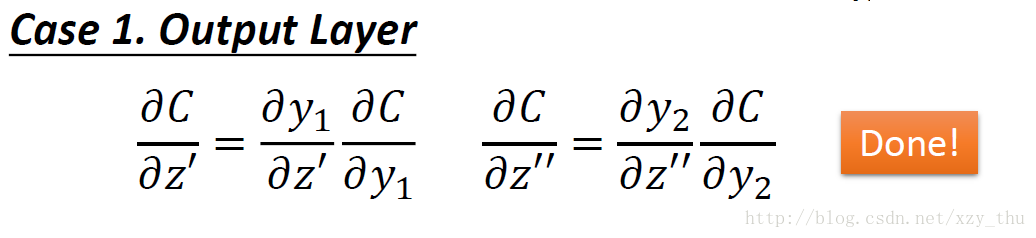
第二种情况,z′,z″” role=”presentation” style=”position: relative;”>z′,z′′z′,z″ 所接的neuron不是output layer的neuron。
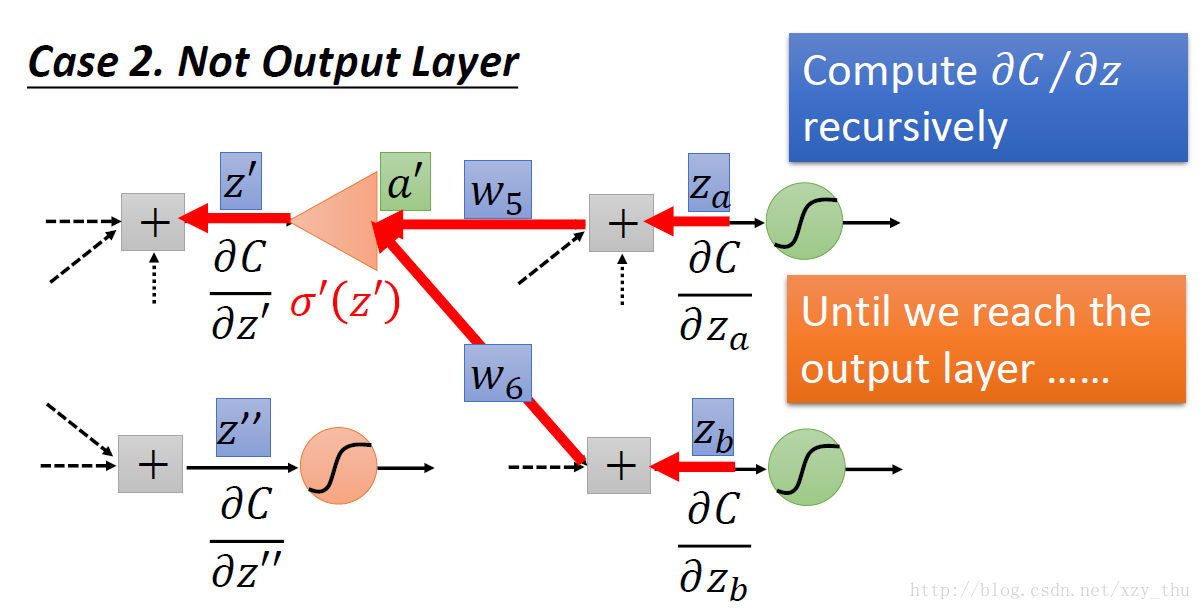
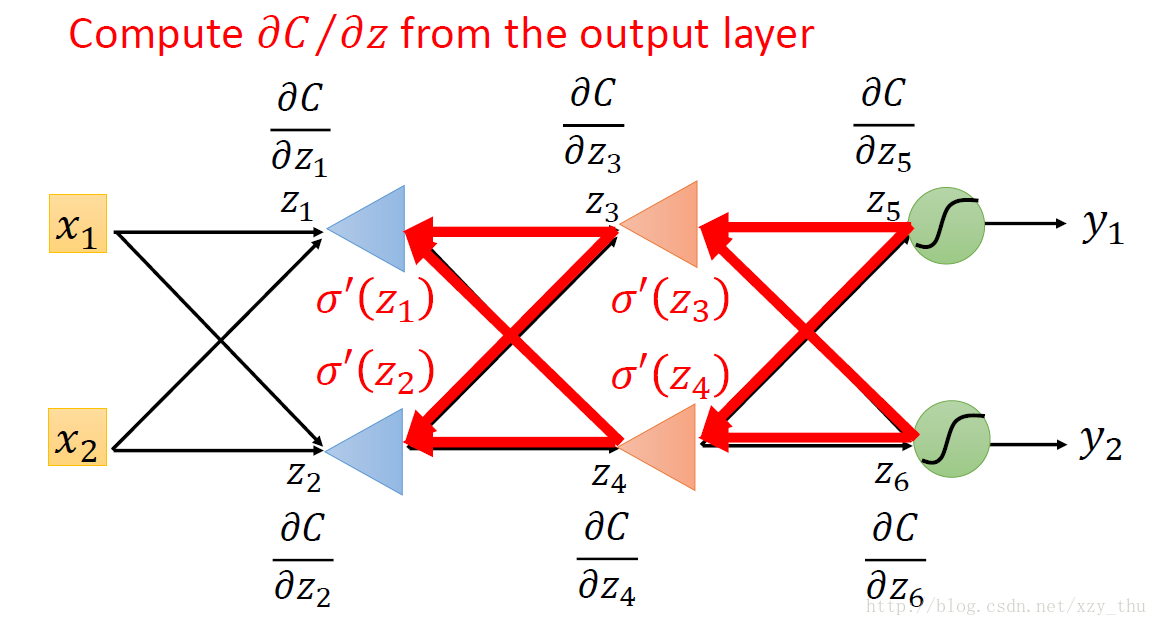
实际上在做Backword Pass的时候,建立一个反向的neural network:
总结
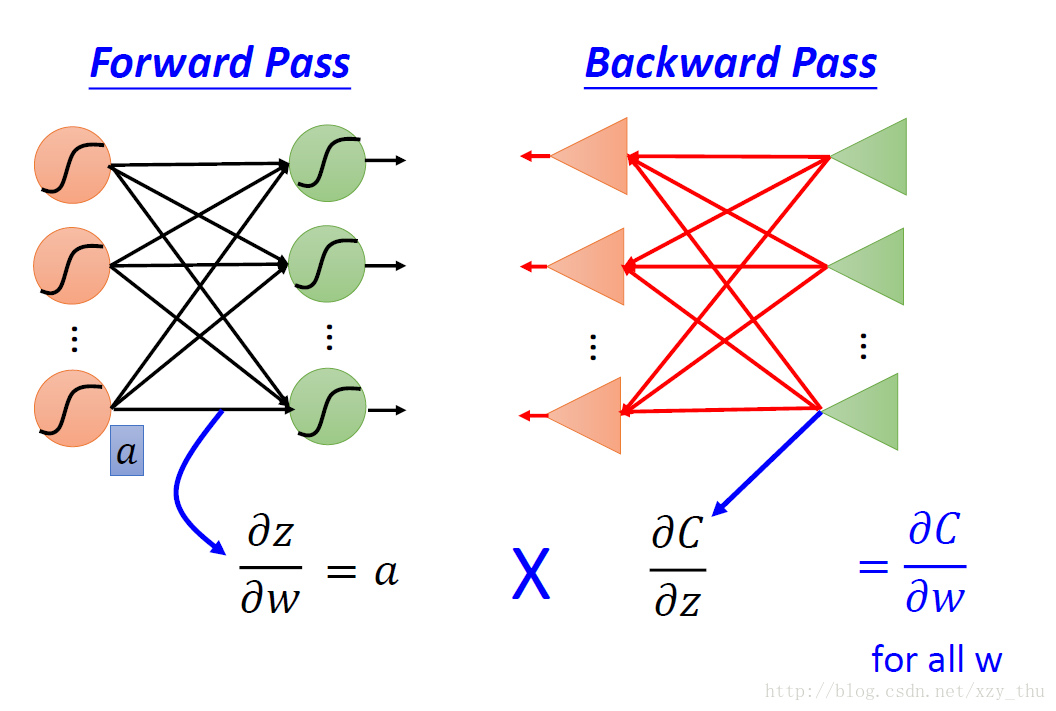
梯度下降时需要计算每笔data的Cost对参数的偏微分∂C∂w” role=”presentation” style=”position: relative;”>∂C∂w∂C∂w 只有一个所指的neuron。
链式法则将计算∂C∂w” role=”presentation” style=”position: relative;”>∂C∂w∂C∂w 拆成前向过程与后向过程。
前向过程计算的是∂z∂w” role=”presentation” style=”position: relative;”>∂z∂w∂z∂w 相连的值。
后向过程计算的是∂C∂z” role=”presentation” style=”position: relative;”>∂C∂z∂C∂z 所指neuron的input,计算结果通过从后至前递归得到。
Lecture 8: “Hello world” of deep learning
Deep Learning的三个步骤
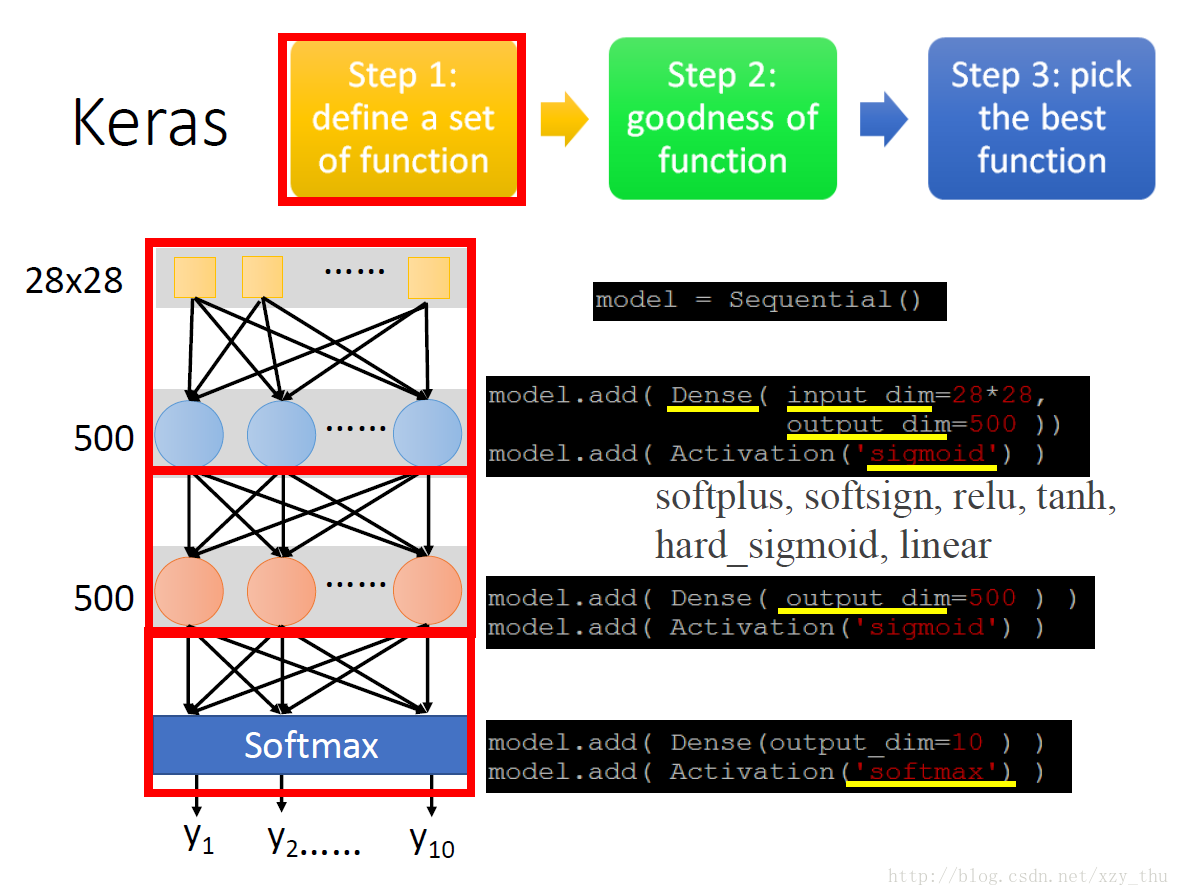
使用Keras做MNIST手写字符识别,第一步定义一个function set。
model = Sequential() 宣告一个model
Dense 代表全连接层
第一个隐层需要设置输入维度、输出维度,之后各层只需设置输出维度
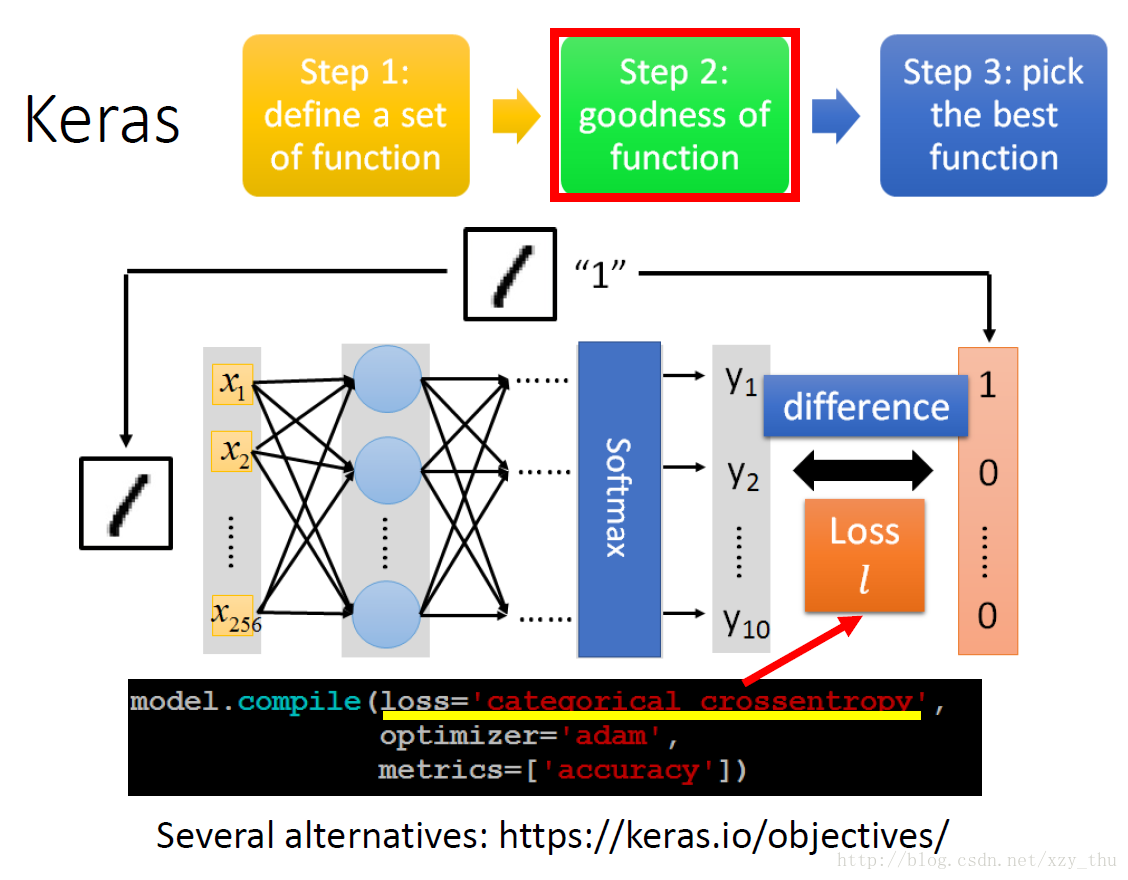
第二步,确定损失函数。图上选的是交叉熵。

第三步,训练。
adam可由机器自己设置学习率。
x_train 与 y_train 都是numpy array.
在已知标签的测试集上测试,与在无标签的测试集上测试:
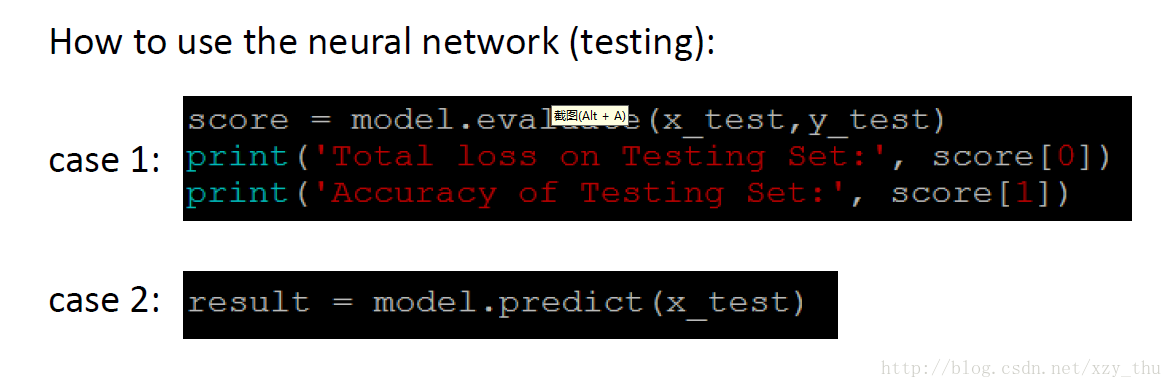
mini-batch 与 epoch
mini-batch与epoch的概念,注意每个batch中的examples都是随机的:

如果batch_size = 1, 则为SGD。
如果batch_size = # training data, 则为(Full Batch) Gradient Descent.
Batch Size会影响训练速度和训练结果,需要tune。
以50000 examples为例,
batch size = 1时,每个epoch更新50000次,用时166s;
batch size = 10时,每个epoch更新5000次,用时17s.
二者在170内都做~5W次更新,且batch size = 10时更稳定。
但是,GPU的平行计算有限度,不能把batch size开得太大。而且Full Batch容易陷入局部最优值。
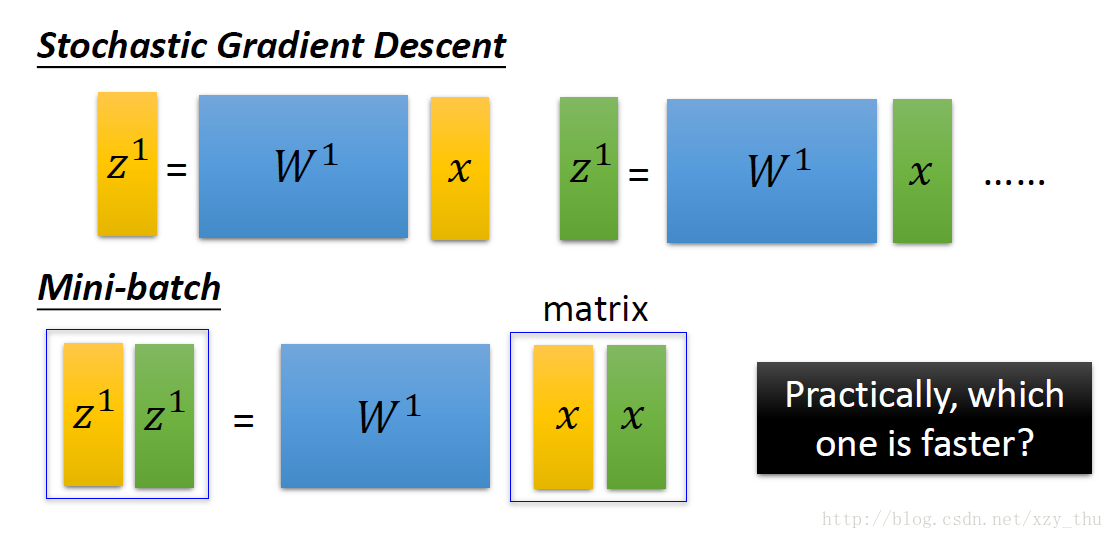
上面做一次矩阵乘法,和下面做一次矩阵乘法,GPU所花时间一样。
有一招叫做Shuffle,在Keras中是默认的,意思是:在各个epoch中每个batch的组成是不一样的。
分析结果
对第一个隐层的neuron,可将其weights排成image:
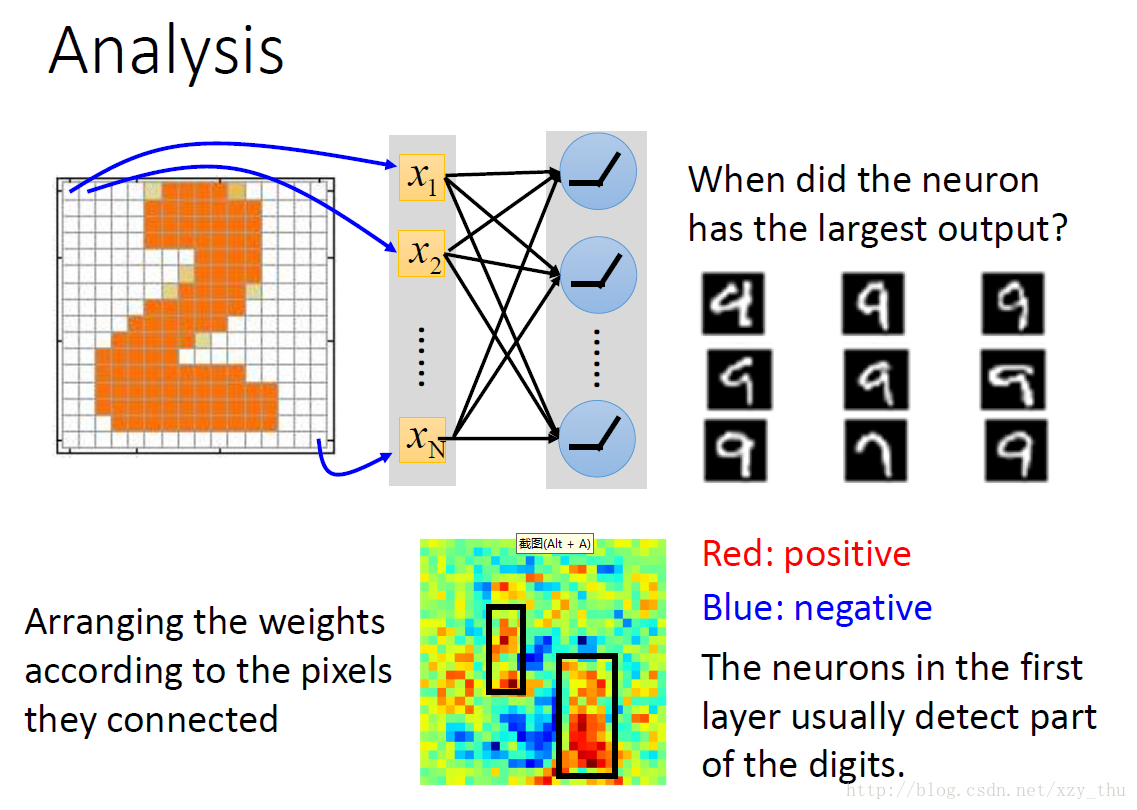
还有一种分析方法,每个隐层的output都是高维向量,将高维向量降维成二维平面上的点,并保持距离关系(在高维空间中远,则在二维空间中也远)。
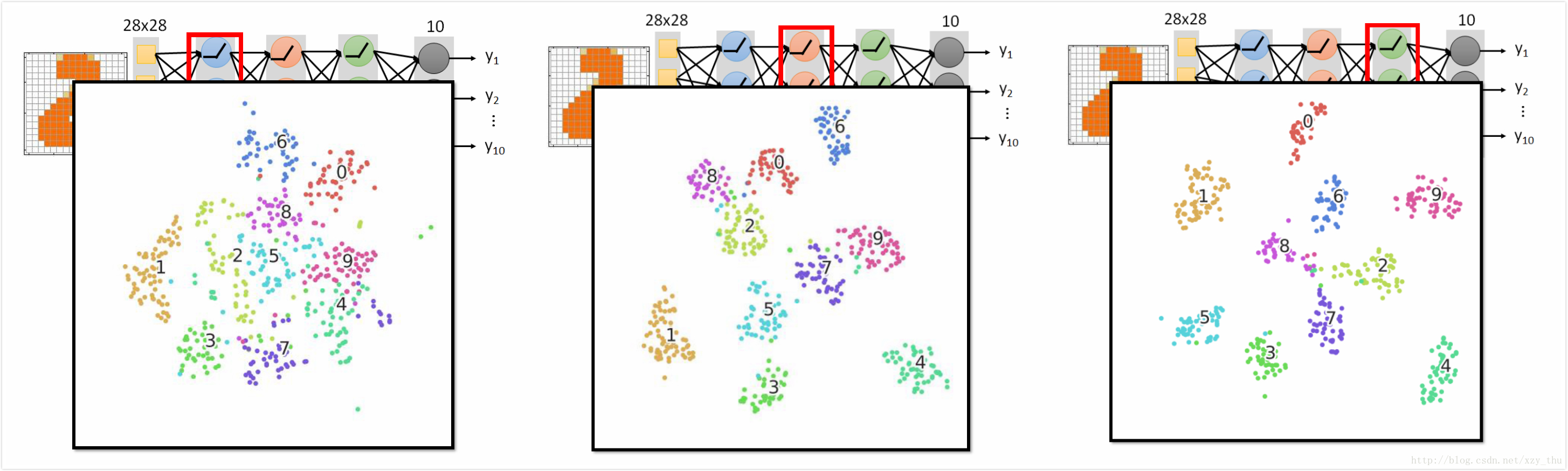
可见,数字分得越来越开。最后的隐层的输出就是得到的feature,分得很开。尽管最后的output layer是线性模型,也可以把数字都分开。
Lecture 9: Tips for Training DNN
明确流程
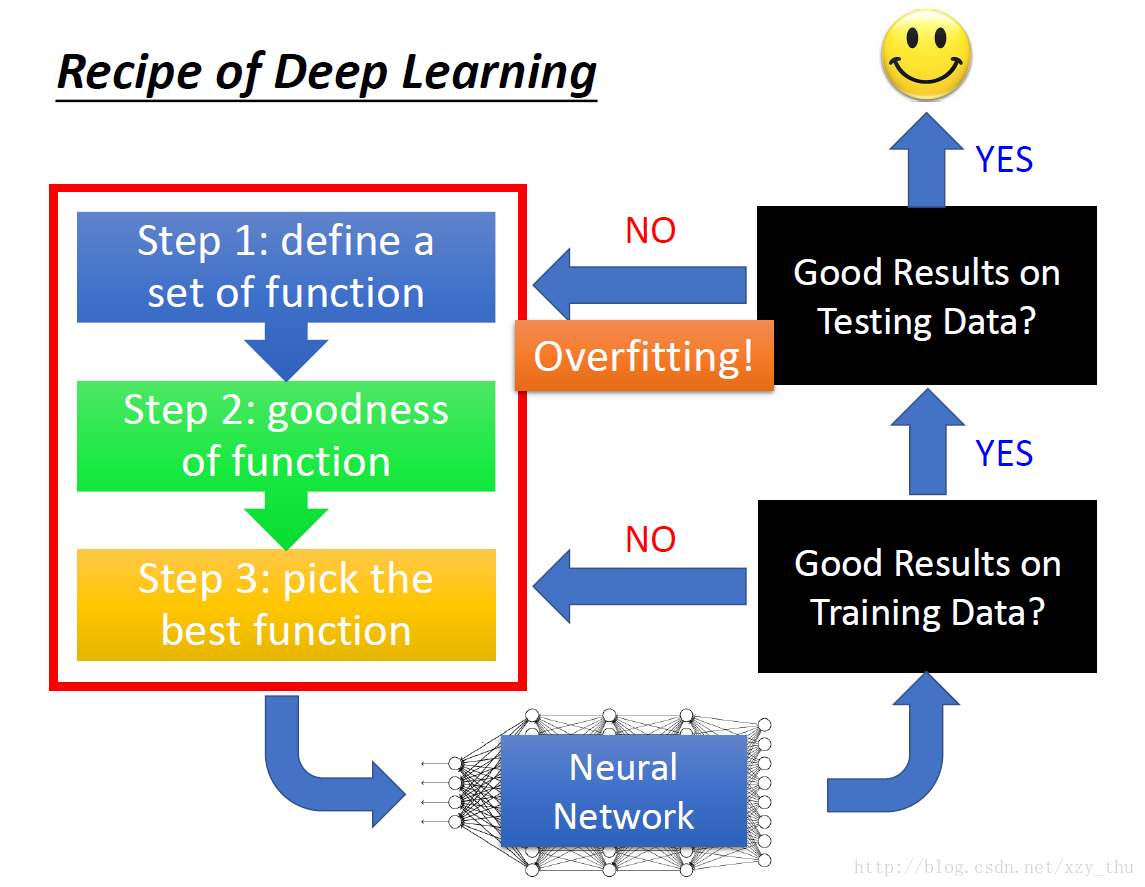
判断overfitting需要看两个数据集上的结果(training set → good, testing set → bad)。
在试图解决overfitting之后仍要再看一下training set上的结果!
不能看见所有不好的performance都归因到overfitting。如只看下右图,不能断言56-layer有overfitting,要看training set上的表现。根据下左图,可以发现原因是train的时候没有train好(也不能叫underfitting,underfitting:参数不够多,模型能力不足)。

对症下药
在读到deep learning的方法时,要思考该方法是解决什么问题。是解决training set上的performance不好,还是解决testing set上的performance不好。比如,Dropout是为了解决testing set上结果不好的问题,如果是training set上结果不好而用Dropout,不会有好的结果。
解决方法与对应的问题:
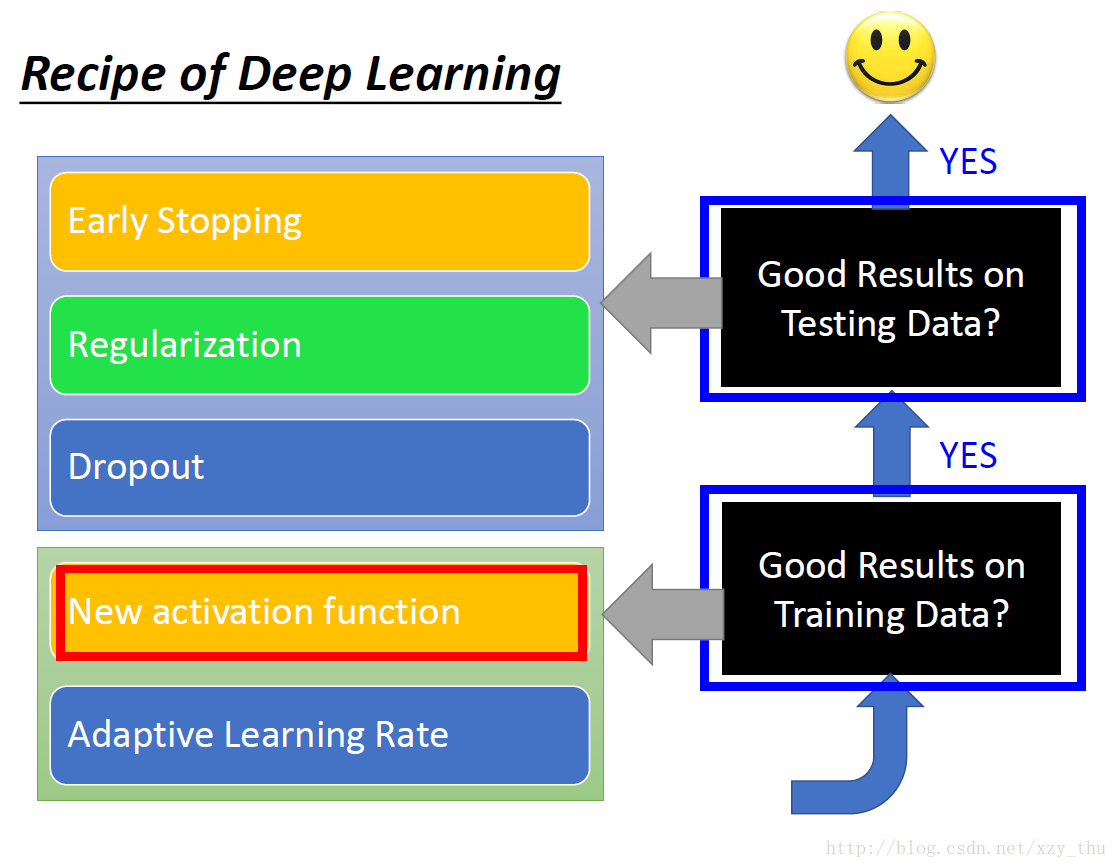
New activation function (for good results on training data)
MNIST手写数字识别,激活函数用sigmoid,training data上的accuracy与层数的关系曲线:
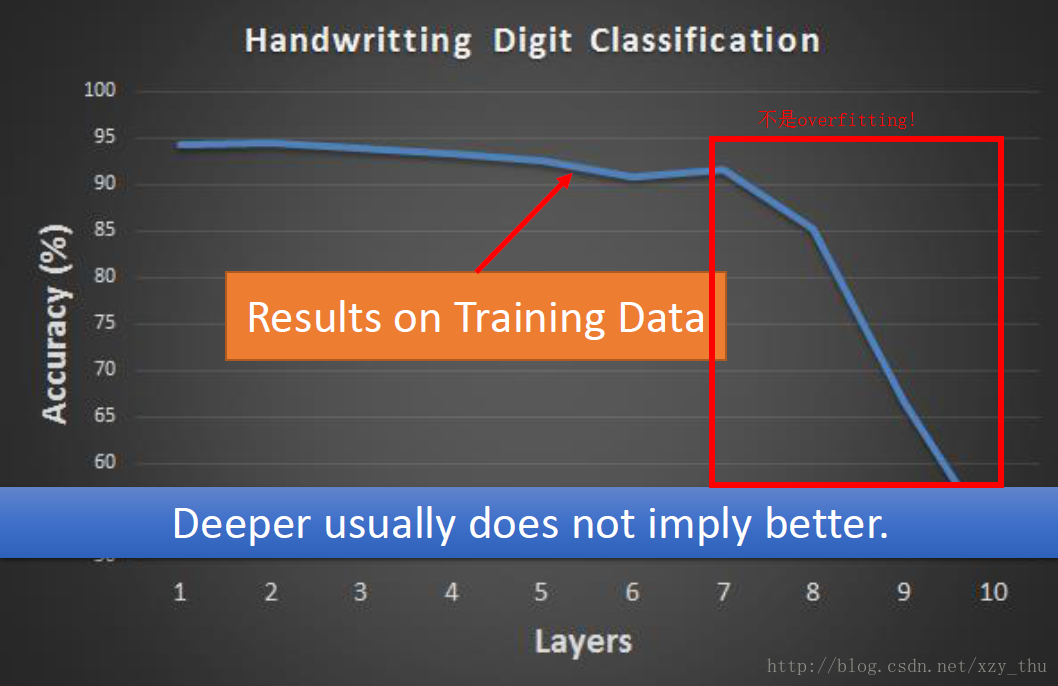
层数>7时,performance下降,原因不是overfitting! train的时候就没train好。
梯度消失的问题:
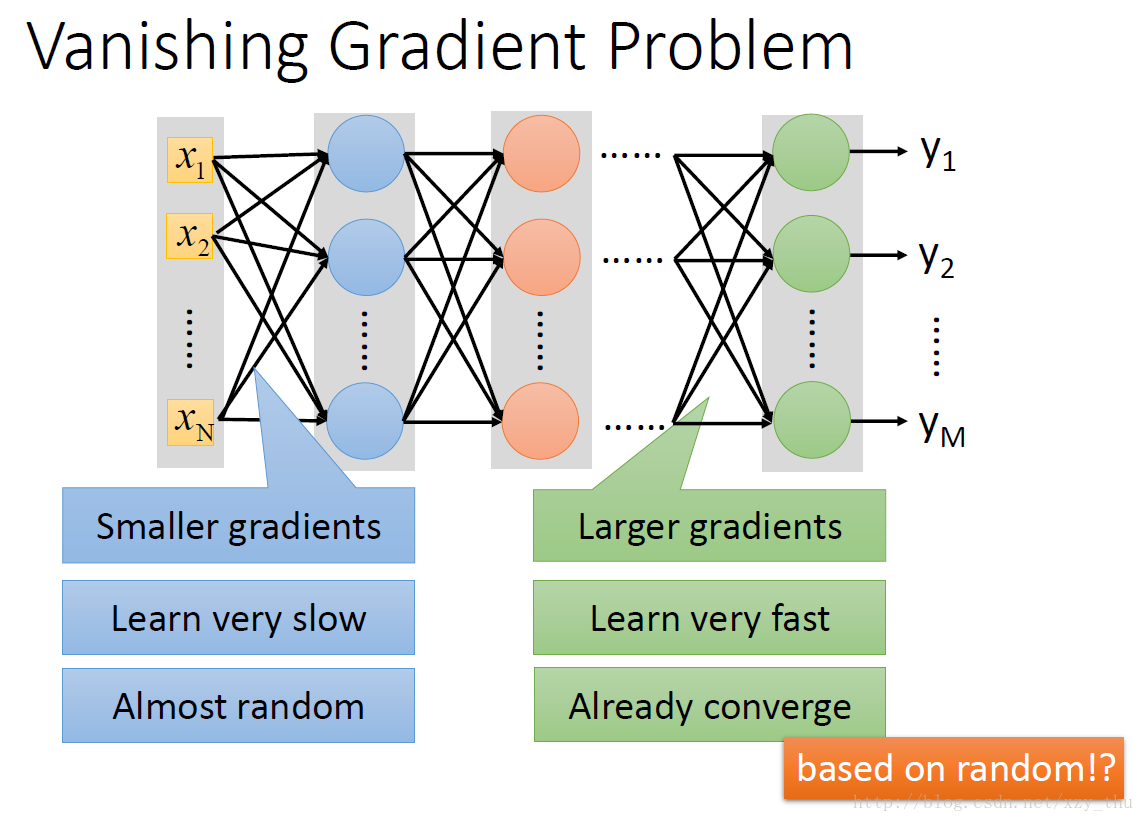
用sigmoid会出现梯度消失的问题(参数的变化经过sigmoid会逐层衰减,对最后的loss影响很小),改用ReLU(计算快,相当于无数sigmoid叠加,解决梯度消失问题)。
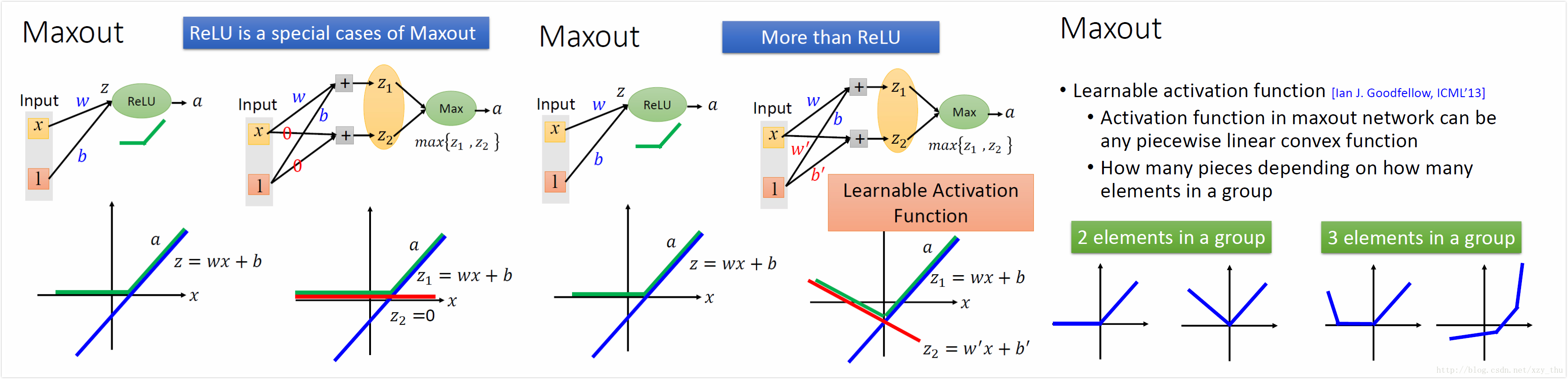
ReLU输出0或x,输出0的ReLU神经元相当于不存在,网络变得瘦长,但是整个网络仍然是非线性的,只有当input改变十分微小的时候才是线性的,因为input不同,输出为0的ReLU神经元也不同。
ReLU是Maxout的特例,Maxout可以学出激活函数。
Adaptive Learning Rate (for good results on training data)
RMSProp

α” role=”presentation” style=”position: relative;”>αα 小,则倾向于相信新的gradient。
Momentum
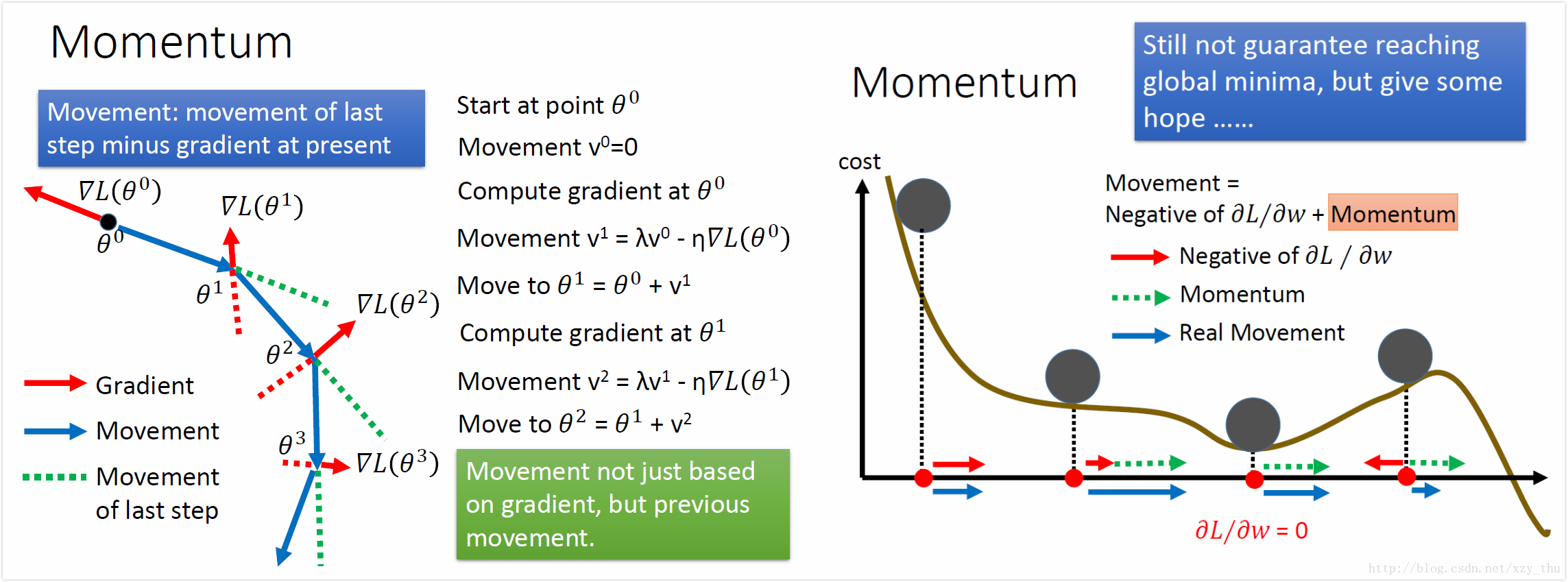
Adam

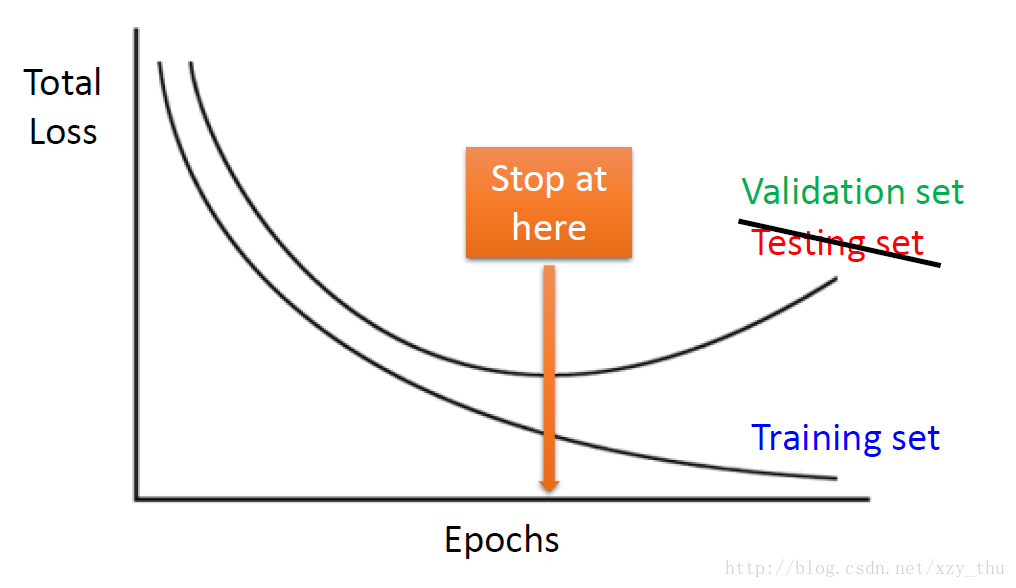
Early Stopping (for good results on testing data)
这里的testing set指的是有label的testing set。
如果learning rate设得对的话,training set的loss会逐渐降低,而testing set与training set可能分布不同,所以testing set的loss可能先降后升,这时就不要一直train下去,而是要在testing loss最小的地方停止train。这里的testing set 实际指的是validation set。
Regularization (for good results on testing data)
L2正则化

L2正则化让function更平滑,而bias与函数平滑程度没有关系。
参数更新:

正则化在NN中虽有用但不明显。
NN参数初始值一般接近0,update参数即是要参数原理0。L2正则化(让参数接近0)的作用可能与early stopping类似。
L1正则化

L1 update的速度是|ηλ|” role=”presentation” style=”position: relative;”>|ηλ||ηλ| 很大,那么改变量也很大)。
用L1做training,结果比较sparse,参数中有很多接近0的值,也有很多很大的值。
L2 learn的结果:参数值平均来讲比较小。
Dropout (for good results on testing data)
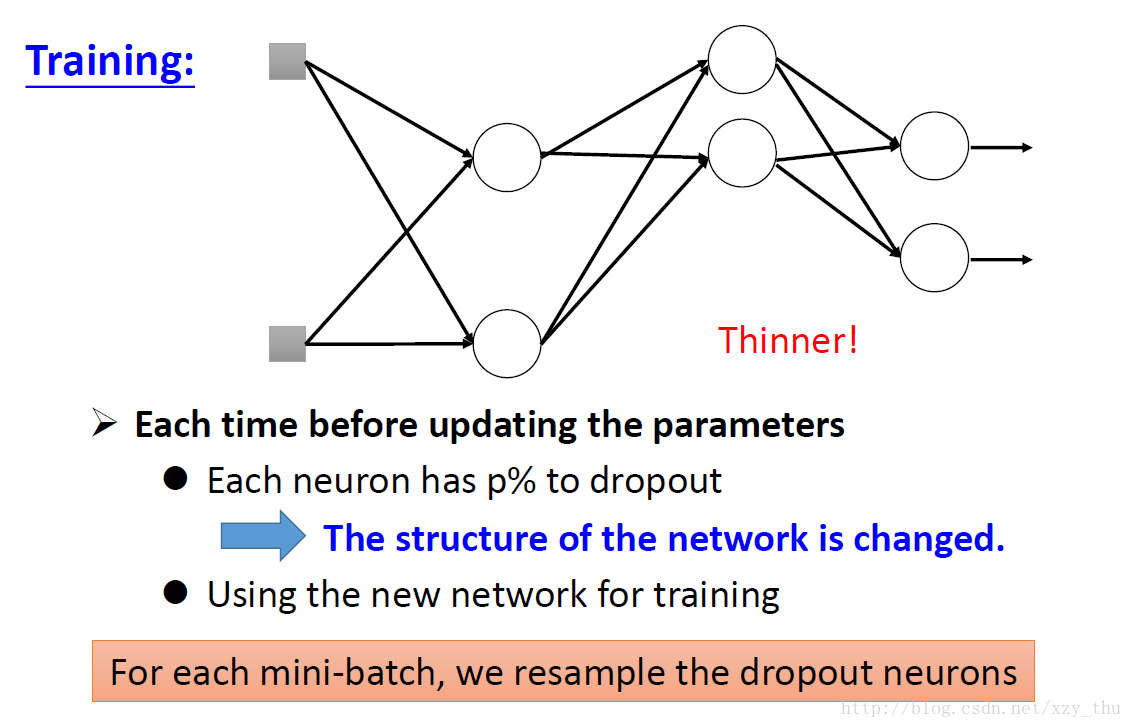
input layer中每个element也算是一个neuron.
每次更新参数之前都要resample.
用dropout,在training上的结果会变差,但在testing上的结果会变好。
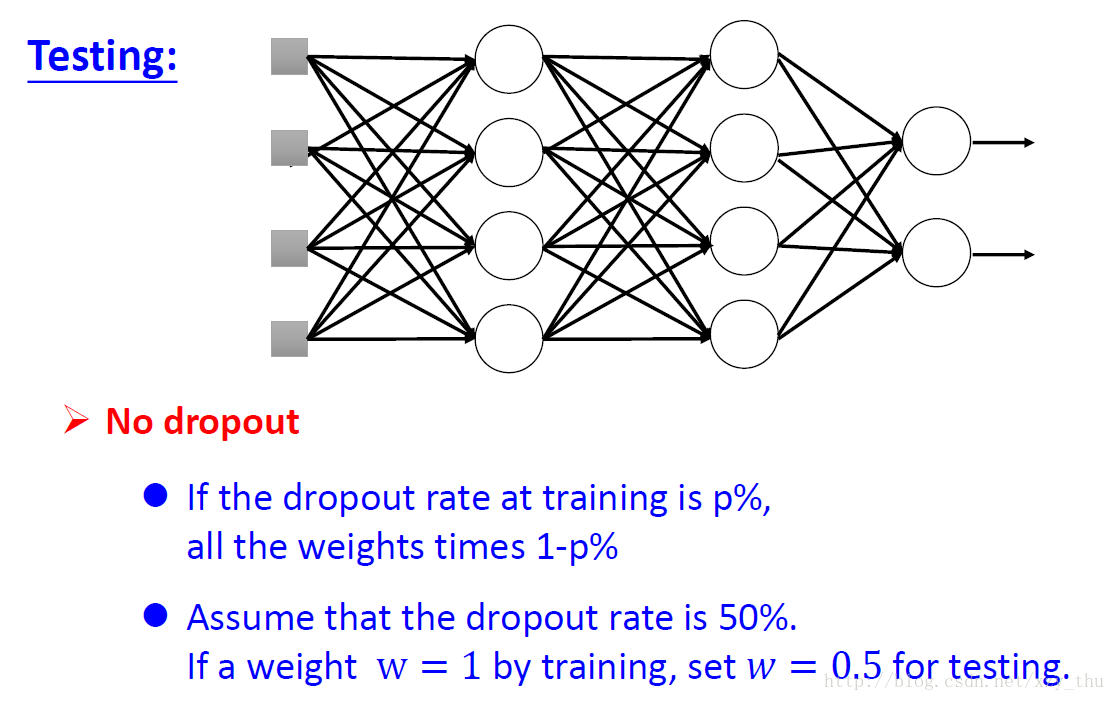
在testing的时候不做dropout,所有neuron都要用。
如果training时dropout rate = p%, 得参数a, 那么testing时参数a要乘(1 - p%).
Dropout是ensemble的一种方式。
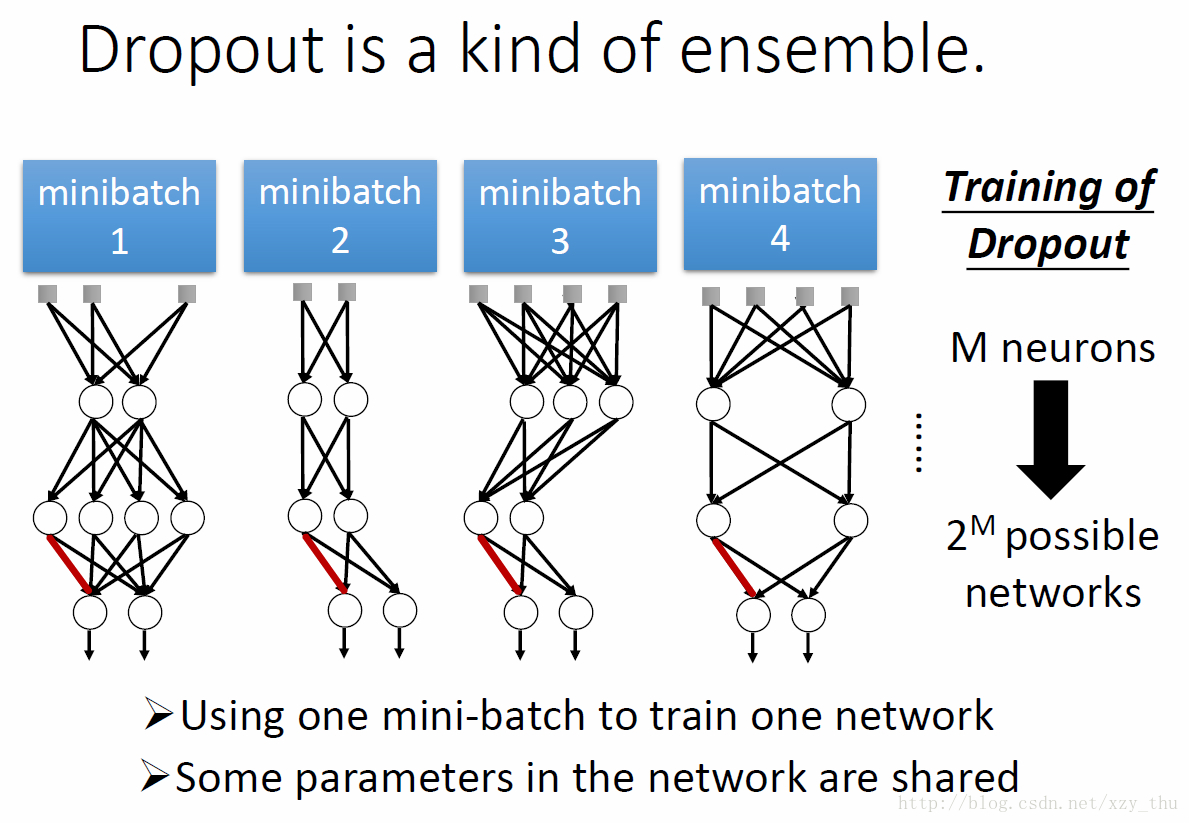
一个复杂model, bias准,但variance大,把多个复杂model ensemble起来,variance变小。
每个dropout后的结构由一个batch来train,但是权重是共享的,每个权重是由多个batch 来train的。
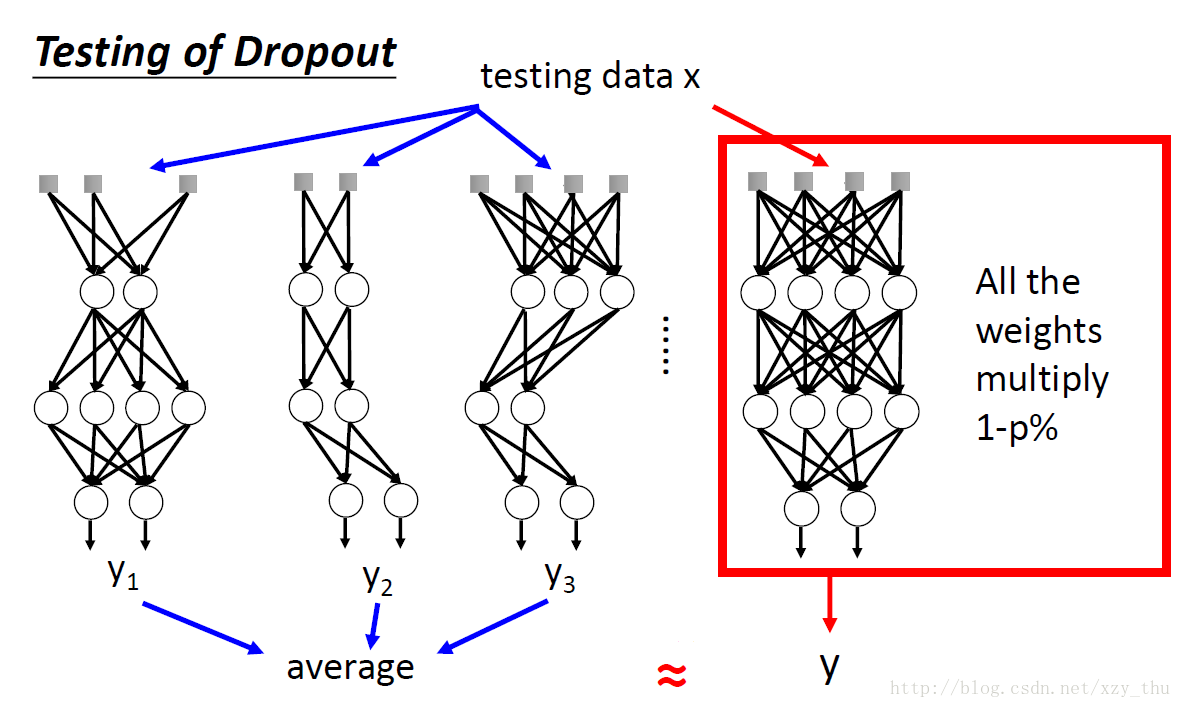
在testing的时候,把多个结构的结果取平均,与把所有参数乘以(1 - p%),效果是近似的。
Dropout用在ReLU、Maxout上效果较好。
李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning
文章转载处:https://blog.csdn.net/xzy_thu/article/details/69680951














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









