










原文标题:ATMOL:Attention-wise masked graph contrastive learning for predicting molecular property
代码:GitHub - moen-hyb/ATMOL: A model named ATMOL for predicting molecular property
一、问题提出
由于标记数据有限,基于监督学习的分子表示算法只能搜索有限的化学空间,泛化能力较差。
基于特征工程的化学指纹,其中每一位代表某种生化特性或子结构的有无,将结构信息或特性转换为固定长度的向量。例如,PubChem指纹和extended connectivity fingerprints是常用的分子表征。然而,大多数化学指纹依赖于领域知识,只包含特定于任务的信息,这通常导致应用于下游任务时性能有限。例如具有已知性质的分子预训练,当下游应用于小数据集时,全监督模型容易出现过拟合和泛化性差的问题。
生成方法通过建立特定的预训练任务,鼓励encoder提取高阶结构信息来学习embedding。
MG-BERT【MG-BERT: leveraging unsupervised atomic representation learning for molecular property prediction】通过将图神经网络(GNNs)的局部消息传递机制集成到BERT中,来学习分子图中的表示学习,从而学会了预测被掩盖的原子。
MolGPT【Molgpt: Molecular generation using a transformer-decoder model】训练一个transformer-decoder模型,用于预测下一个token任务,使用masked self-attention生成新分子。
对比学习鼓励相同分子的增强(对比视图),使其具有比由不同分子生成的更相似的embedding。例如:
MolCLR【Molclr: molecular contrastive learning of representations via graph neural networks】通过mask节点或边或子图,提出了三种不同的graph增强方法,从而最大化来自同一分子的增强的一致性,同时最小化不同分子的一致性。
CSGNN【CSGNN: improving graph neural networks with contrastive semi-supervised learning】设计了一个deep mix-hop GNN来捕获高阶依赖,并引入了一个自监督对比学习框架。
MolGNet【An effective self-supervised framework for learning expressive molecular global representations to drug discovery】使用配对子图识别和属性屏蔽(AttrMasking)来实现节点级和图级预训练,这被证明可以提高从分子图中提取特征的能力。
MoTSE【MoTSE: an interpretable task similarity estimator for small molecular property prediction tasks】通过将单个任务投射到一个潜在空间中,计算任务相似度并选择相似任务进行多任务学习,同时考虑多个相似任务,通过迁移学习提高分子预测性能。
MV-GNN【Multi-view graph neural networks for molecular property prediction】采用multi-view GNNs进行分子性质预测,从节点(原子)和边(键)构建两个分子视图,然后运行交叉依赖的消息传递,加强两个视图的信息通信。
然而,随机mask的方式不能指导编码器检测最重要的子结构!!!!
二、模型方法
1、Data source
从ZINC数据库(substance channel)下载了两个分子集。一种是体外组,其中包括在直接结合试验中报告或推断在10 μM或更高温度下具有生物活性的306 347种独特物质。评价实验中使用了体外组中的所有分子。另一组是由ZINC的现有组建造的,其中包括所有的库存和直接交付的代理物质。该数据集包含9814569个独特的分子。对于分子,使用RDkit将SMILES描述符转换为分子graph,其中节点表示一个原子,边表示一个化学键。
下游任务的性能评估,从MoleculeNet中选择了7个数据集,该数据集包含40多个分子特性预测任务:
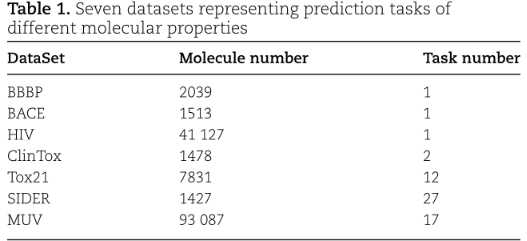
对于每个数据集,使用从DeepChem scaffold split来创建80/10/10的训练/验证/测试子集。scaffold split根据分子骨架将分子分离,这使得预测任务更具有挑战性,但也更现实。
2、Method
两个阶段:预训练和微调。首先对大规模无标记数据集进行对比学习,获得分子表示,然后应用到下游任务的分子性质预测任务。
将分子graph作为输入,用GAT encoder映射到隐空间。同时,一个attention-wise masking module密切跟踪GAT encoder,通过mask一些节点或边来使用注意力评分生成增强视图(masked graph):
故意设计masking module来生成增强图,这对GAT编码器区分正样本和负样本提出了挑战,使得来自相同分子的图被赋予了相似的embedding,但不同于其他分子的embedding。因此,对比学习模型被迫捕捉重要的化学结构和更高阶的语义信息。在几个分子性质预测任务上验证了通过对比学习得到的分子表示。
1)Molecule graph embedding:GAT是基于多头注意的学习graph embedding的体系结构。GAT体系结构由multiple graph attention layers组成,每一layer对节点级表示进行线性变换,计算attention分数。设hi为节点i的embedding,W为learnable的注意参数矩阵。计算节点i与其一阶邻居节点j之间的注意评分αi,j为:

其中a为可学习向量,elu为指数线性单元激活函数,N(i)表示节点i的一阶邻居,注意评分αij实际上是节点i与其邻居之间的softmax归一化message。一旦计算出了注意分数,节点i的输出特征通过聚合其相邻的以相应的注意分数加权的特征来计算:
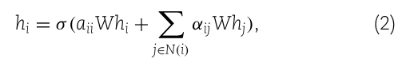
其中σ(.)为ReLU激活函数。
使用两个GAT层。第一层采用多头注意机制,heads为10。考虑到节点级的特征,使用全局最大池化层来获得图embedding。hidden_size设置为128。将第一层的多头注意权重矩阵平均为第二层的注意矩阵,并将其用于注意掩码模块,生成一个augmentation graph。
2)Attention-wise mask for graph augmentation:
根据GAT编码器学习到的注意力分数掩盖了输入分子图的一定比例的节点(边)。当一个节点(边)被屏蔽时,在图卷积运算中将其embedding置为0。如果一条边缘被屏蔽,沿着这条边缘传递的信息就会被屏蔽。设定mask ratio为r,迭代的进行mask,mask策略:
Max-attention masking:r % attention scores最大的节点(边)被mask。这种mask产生的增强图,与输入分子图的current view有最大的不同。
Min-attention masking:r % attention scores最小的节点(边)被mask。这种mask产生的增强图与输入分子图current view的差异最小。
Random masking:从输入图中随机选取r%节点(边)进行mask,忽略学习到的注意分数。这种掩盖策略在以前的研究中被普遍使用;
Roulette masking:每个节点或边被mask的概率与其注意力得分成正比。注意权重矩阵W通过softmax函数归一化得到概率分布。一个节点(或边)被mask的可能性与它的概率成正比
由于GAT的attention weight matrix在预训练阶段是变化的,因此根据attention weight matrix得到的augmented graphs也是动态变化的。特别是,max-attention masking实际上类似于图对抗学习,它已被证明可以增强深度神经网络对扰动的鲁棒性和泛化能力。
3)Contrastive learning:
GAT编码器将input molecule graph及其augmented graph转换为embedding hi和h'i,然后非线性投影层映射到zi和z'i。接下来,相似度sim(zi, z'i)在两个projector之间进行计算。对比损失函数:
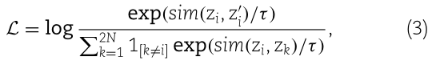
在1 [k ≠ i]∈{0,1}是一个indicator函数,其值为1 if k ≠ i, τ表示温度参数;N为mini-batch size。余弦距离 评估来自一个分子的两个视图的相似性。
负样本的数量和多样性在自我监督表征学习中起着至关重要的作用,有研究证实大量的负样本有助于提高学习表现。因此,除了mini-batch中的负样本外,还对负样本池注意掩模生成的augmented graphs进行了补充,使负样本数量得到了极大的扩展。更重要的是,augmented graphs丰富了负样本的多样性。
4)Pretraining and transfer learning
Pretraining:Adam、lr= 1e-4、batch_size=128、epoch=20、 RTX 3090 24G、
transfer learning:GAT encoder+ head(两层全连接)。冻结了GAT的权值,只调整了head。所有分类任务均采用cross-entropy loss,learning_rate=1e-7。Adam,batch_size=100。ROC-AUC对性能进行评价。采用 early stopping 和dropout防止过拟合。按8:1:1分训练、验证和测试。为避免随机偏差,重复五次,每次都在测试集上进行评估。平均AUC值作为最终性能。
三、实验
1、Contrastive learning boosted performance
首先验证对比学习是否能提高下游任务的表现。为了系统地评估预训练的有效性,还考虑由mask节点、边或节点和边同时产生的不同分子增强图(mask ratio r始终为25%)。
 显示在7个基准任务下的ROC-AUC值。预训练显著提高了在各种分子性质预测任务中的表现。
显示在7个基准任务下的ROC-AUC值。预训练显著提高了在各种分子性质预测任务中的表现。
2、Masking strategy affected feature extraction
探索4中不同augmented graphs method对特征提取的影响:
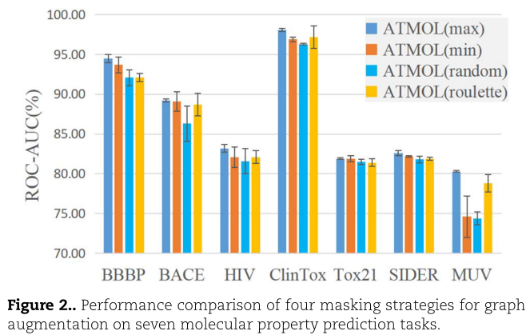
Max-attention masking的预测性能最好。Random masking的性能最差。Max-attention masking给对比学习带来了挑战,从一组来自其他分子的负样本中区分一对正样本。这个挑战鼓励模型学习有用的分子表示。
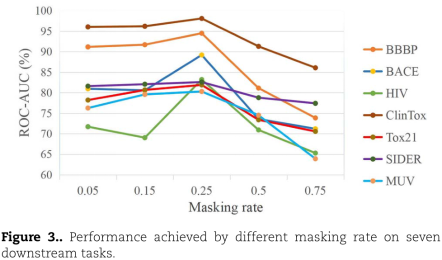
3、Influence of masking rate
评估了在不同百分比被mask时的性能。mask ratio从5-75%,下游7个任务的性能首先提高,并在mask ratio为25%时达到最高的ROC-AUC值:
4、Large-scale dataset improved representation learning
更大规模的无标记数据是否会改善表示学习?从ZINC中选择3000万个分子作为另一个数据集,这大约是实验数据集的10倍。为了便于比较,将它们分别称为small set和big set。分别对这两个数据集进行表示学习,然后比较下游任务的性能:

5、Performance comparison to other methods
将其与其他五种具有竞争力的方法进行了比较:

6、Exploration of model interpretability Spatial localization of molecular representations
分子表征的空间分布有助于验证该方法的有效性。使用UMAP(降维集成学习算法)对预训练前后的分子表示进行可视化:

上图显示了分子在BBBP和SIDER集合中的二维embedding。最初的分子表征在空间上分布混乱,而经过预训练后,属于同一类的分子聚集在一起,与其他类分子明显分离。结果表明,该方法能有效地从化学结构中检测出分子的理化性质,从而使具有相似理化性质的分子获得相似的潜在表征
7、Attention weight revealed important chemical substructure
在分子图中可视化了注意权重。从BBBP数据集中,随机选择一个分子作为样本,其SMILES为CS(=O)c1ccc(cc1)C@@HC@@HNC(=O)C(Cl)Cl。计算每对原子的注意权重的Pearson相关系数,并将相关矩阵可视化为热图。如图5A所示,热图显示了几个高度相关的原子团,表明它们共同作用,影响特定的分子性质。进一步观察可以发现,该分子中的苯环可能在决定膜通透性方面起着重要作用。

同样从BACE数据集中随机选择一个分子FC1(F)COC(=NC1(C)c1cc(NC(=O)c2nn(cc2)C)cc c1F)N,其热图也显示了几个重要的原子团,如图5B所示。
可视化原子级别的注意权重。记住BBBP任务关注的是膜的通透性,发现范例分子中的两个Cl原子具有很高的注意权重,如图5C所示。由于Cl原子具有较强的电子吸引力,认为它在很大程度上影响分子的极性,从而影响膜的通透性。同时,由于羟基促进亲水性,相应地发现羟基被给予相对较高的重视权重
同样,从BACE数据集中选择的人类β -分泌酶1 (BACE-1)抑制剂。研究表明,heterocytosine aromatic family对BACE-1有抑制作用。如图5D所示,该分子的isocytosine component 受到了更多的关注。可视化和可解释性的探索说明了模型如何从分子性质预测任务的角度关注相关特征。
构建负样本进行对比学习的方法主要有两种。一些方法维护了一个负样本队列,并以FIFO方式迭代更新它,而另一些方法只使用当前小批中的样本作为负样本。在作者研究中,除了将mini-batch中的样本作为负样本外,还将通过attention mask策略生成的graph augmentation 加入到负样本队列中,使负样本得到了极大的扩展和多样化。















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









