






摘要 继BNN和XorNet之后,这篇论文提出了DoReFa-Net,它是一种可以使用低位宽参数梯度来训练低位宽权重和激活值的卷积神经网络的方法。特别地,在反向传播传播阶段,参数梯度可以在传递到下一层卷积层之前被随机量化到低位宽。由于前向/反向阶段卷积都是在对低位宽权重和激活值/梯度上操作的,这样DoReFa-Net可以使用低位宽卷积核来加速训练和推理。并且,低位卷积可以在CPU,FPGA,ASIC和GPU上高效实现,因此DoReFa-Net打开了一扇在这些硬件上加速训练低位网络的大门。最后论文在VHN和ImageNet数据集上的实验证明了DoReFa-Net可以达到与32位参数相当的精度。例如,从AlexNet派生出来的1bit权重,2bit激活值,6bit梯度值的DoReFa-Net AlexNet模型从头开始训练可以在ImageNet上达到 46.1%的top-1精度。论文原文见附录。
1. 介绍
我们知道,XORNet以及BNN都没有在反向传播阶段做梯度的量化,之前也没有任何工作可以在反向传播阶段将梯度量化到8位一下并且保持相当的预测精度。在BNN和XORNet中,虽然权重是二值化的,但是梯度仍然是全精度浮点数,因此在反向传播时反卷积依然是1bit和32bit数之间的运算,这导致BNN和XORNet的训练时间主要花在反向传播阶段。
2. 贡献
这篇论文的贡献为:
- 本文泛化了BNN的方法提出了DoReFa-Net,它可以拥有任意位宽的权重,激活值以及梯度。由于前向传播和方向传播都是对低精度的数进行操作,所以DoReFa-Net可以使用位卷积核来加速训练过程中的前向和反向。
- 由于位卷积可以在CPU、FPGA、ASIC和GPU上高效实现,DoReFa-Net打开了一扇在这些硬件上加速训练低位宽神经网络的大门。尤其是FPGA和ASIC的功效很高,可以减少低位宽网络训练的功耗。
- 论文还探索了权重,激活值和梯度的配置空间,比如使用1bit权重,1bit激活值和和2bit梯度可以在SVHN数据集上达到93%的精度。在本文的实验中,梯度通常需要比激活值更大的位宽,而激活值通常需要比权重更大的位宽,这样可以保证与32位浮点数相比精度不会掉很多。
3. DoReFa-Net
在这一节,论文将DoReFa-Net公式化,提出了一种方法来训练低位宽权重,激活值和梯度的方法。需要注意的是,权重和激活值都是确定性量化的,而梯度需要随机量化。
3.1 在低位宽神经网络中使用位卷积核
我们知道,1bit的点积可以如下表示:
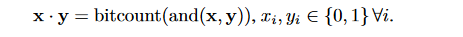 上面的式子同样也可以用在计算低位宽定点整数之间的乘加运算。假设
x
x
x是一个
M
M
M位定点整数序列集合,
x
=
∑
m
=
0
M
−
1
c
m
(
x
)
x=\sum_{m=0}^{M-1}c_m(x)
x=∑m=0M−1cm(x),
y
y
y是一个
K
K
K位定点整数序列集合,
y
=
∑
k
=
0
K
−
1
c
k
(
y
)
y=\sum_{k=0}^{K-1}c_k(y)
y=∑k=0K−1ck(y),这里的
(
c
m
(
x
)
)
m
=
0
M
−
1
(c_m(x))_{m=0}^{M-1}
(cm(x))m=0M−1和
(
c
k
(
y
)
)
k
=
0
K
−
1
(c_k(y))_{k=0}^{K-1}
(ck(y))k=0K−1都是位向量,
x
x
x和
y
y
y的点积可以由位运算来计算:
上面的式子同样也可以用在计算低位宽定点整数之间的乘加运算。假设
x
x
x是一个
M
M
M位定点整数序列集合,
x
=
∑
m
=
0
M
−
1
c
m
(
x
)
x=\sum_{m=0}^{M-1}c_m(x)
x=∑m=0M−1cm(x),
y
y
y是一个
K
K
K位定点整数序列集合,
y
=
∑
k
=
0
K
−
1
c
k
(
y
)
y=\sum_{k=0}^{K-1}c_k(y)
y=∑k=0K−1ck(y),这里的
(
c
m
(
x
)
)
m
=
0
M
−
1
(c_m(x))_{m=0}^{M-1}
(cm(x))m=0M−1和
(
c
k
(
y
)
)
k
=
0
K
−
1
(c_k(y))_{k=0}^{K-1}
(ck(y))k=0K−1都是位向量,
x
x
x和
y
y
y的点积可以由位运算来计算:
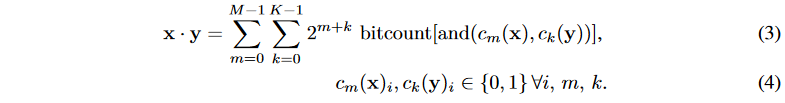
在上面的等式中,计算复杂度为
M
∗
K
M*K
M∗K,和位宽成正比。
3.2 直通估计器
使用直通估计器(STRAIGHT-THROUGHESTIMATOR,STE)的原因可以用一个例子加以说明,假如网络有一个ReLU激活函数,并且网络被初始时即存在一套权重。这些ReLU的输入可以是负数,这会导致ReLU的输出为0。对于这些权重,ReLU的导数将会在反向传播过程中为0,这意味着该网络无法从这些导数学习到任何东西,权重也无法得到更新。针对这一点,直通估计器将输入的梯度设置为一个等于其输出梯度的阈值函数,而不管该阈值函数本身的实际导数如何。
一个简单的例子是在伯努利分布采样中定义的STE为:
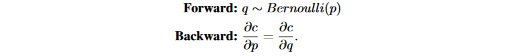
在这里,
c
c
c是目标函数,由于从伯努利分布中采样是一个不可微分的过程,
∂
c
∂
q
\frac{\partial c}{\partial q}
∂q∂c没有定义,因此反向传播中的梯度不能由链式法则直接算出
∂
c
∂
p
\frac{\partial c}{\partial p}
∂p∂c,然而由于
p
p
p和
q
q
q的期望相同,我们可以使用定义好的梯度
∂
c
∂
q
\frac{\partial c}{\partial q}
∂q∂c对
∂
c
∂
p
\frac{\partial c}{\partial p}
∂p∂c做近似,并且构建了一个如上所示的STE,因此STE实际上给出了一个对
∂
c
∂
p
\frac{\partial c}{\partial p}
∂p∂c的定义。在本文的工作中广泛使用的STE是量化器—将一个真实的浮点数输入
r
i
∈
[
0
,
1
]
r_i\in [0,1]
ri∈[0,1]量化未
k
k
k位输出
r
o
∈
[
0
,
1
]
r_o\in [0,1]
ro∈[0,1],定义的STE如下:
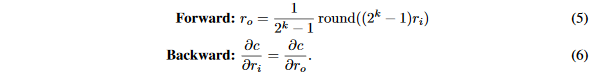
我们可以看到,量化器STE的输出
q
q
q是一个由
k
k
k位表示的真实数,由于
r
o
r_o
ro是一个
k
k
k位定点整数,卷积计算可以由等式(3)高效执行,后面跟着正确的缩放即可。
3.3 权重的低Bit量化
在之前的工作中,STE被用来做二值化权重,比如在BNN中,权重被下面的STE二值化:
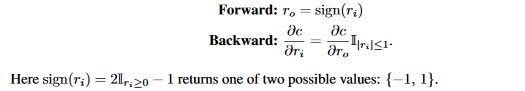
在XNOR-Net中,权重按照下面的STE二值化,不同之处在于权重在二值化之后进行了缩放:
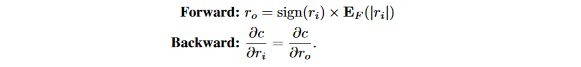
在XOR-Net中,缩放因子
E
F
(
∣
r
i
∣
)
E_{F}(|r_i|)
EF(∣ri∣)是对应卷积核的权重绝对值均值。理由是引入这个缩放因子将会增加权重表达范围,同时仍然可以在前向传播卷积时做位运算。因此,在本文的实验中,使用一个常量缩放因子来替代通道级缩放。在这篇论文中,对于所有的二值化权重使用同一个缩放因子:
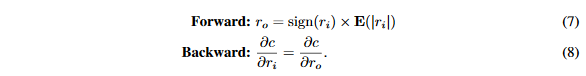
当
k
>
1
k>1
k>1时,论文使用
k
k
k位表达的权重,然后将STE
f
w
k
f_{w}^k
fwk应用在权重上:
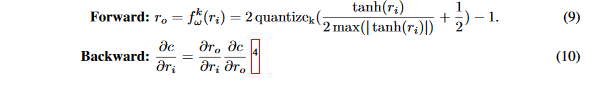
在量化到
k
k
k位之前,论文先使用tanh将权重限制在[-1,1]之间。通过
t
a
n
h
(
r
i
)
2
m
a
x
(
∣
t
a
n
h
(
r
i
)
∣
)
+
1
/
2
\frac{tanh(r_i)}{2max(|tanh(r_i)|)}+1/2
2max(∣tanh(ri)∣)tanh(ri)+1/2将数值约束在[0,1]之间,最大值是相对于整个层的权重而言的。然后通过:
q u a n t i z e k = 1 2 k − 1 r o u n d ( ( 2 k − 1 ) r i ) quantize_k=\frac{1}{2^k-1}round((2^k-1)r_i) quantizek=2k−11round((2k−1)ri)将浮点数转换位 k k k位定点数,范围在 [ 0 , 1 ] [0,1] [0,1],最后通过映射变换将 r o r_o ro约束到 [ − 1 , 1 ] [-1,1] [−1,1]。
需要注意的是,当k=1时,等式9不同于等式7,它提供了一个不同的二值化权重的方法,然而,论文发现在实验中这种区别不重要。
3.4 激活值的低Bit量化
接下来我们将详细描述我们如何获得低Bit的激活值,由于它是下一层卷积的输入,所以对能否使用位操作卷积替代浮点卷积至关重要。在BNN和XNOR-Net中,激活值和权重二值化的方式相同。然而,我们在按照XNOR-Net中二值化激活值的方式量化激活值时并没有复现他们的结果,同时BNN中二值化的方式造成AlexNet在ImageNet上精度直接掉了几个百分点。因此,我们将STE应用再每一层的激活值 r r r上,再这里我们假设前层的输出已经经过了一个有界函数 h h h,可以确保 r ∈ [ 0 , 1 ] r\in [0,1] r∈[0,1]。在DoReFa-Net中,激活值 r r r量化到 k k k位的方式可以简单表示为:
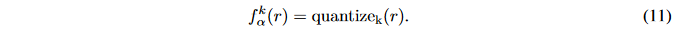
梯度的低Bit量化
本文已经证明了确定性量化可以产生低位宽的权重和激活值。然而,我们发现随机量化对于低Bit梯度是十分必要的,这也和Gupta等人在2015做的关于16位权重和梯度的实验一致。为了将梯度量化到低位宽,保持梯度的无界是非常重要的,同时梯度应该比激活值的范围更广。回顾等式(11),我们通过可微分的非线性激活函数将激活值约束到了 [ 0 , 1 ] [0,1] [0,1],然而,这种构造不存在梯度,因此我们对梯度设计了如下的 k k k位量化方式:
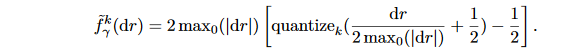 这里的
d
r
=
∂
c
∂
r
dr=\frac{\partial c}{\partial r}
dr=∂r∂c是对一些层的输出
r
r
r的导数,最大值是对梯度张量所有维度(除了
b
a
t
c
h
s
i
z
e
batch size
batchsize)的统计,然后在梯度上用来放缩将结果映射到
[
0
,
1
]
[0,1]
[0,1]之间,然后在量化之后又放缩回去。
这里的
d
r
=
∂
c
∂
r
dr=\frac{\partial c}{\partial r}
dr=∂r∂c是对一些层的输出
r
r
r的导数,最大值是对梯度张量所有维度(除了
b
a
t
c
h
s
i
z
e
batch size
batchsize)的统计,然后在梯度上用来放缩将结果映射到
[
0
,
1
]
[0,1]
[0,1]之间,然后在量化之后又放缩回去。
然后,为了进一步补偿梯度量化引入的潜在偏差,我们引入了额外的函数
N
(
k
)
=
σ
2
k
−
1
N(k)=\frac{\sigma}{2^k-1}
N(k)=2k−1σ,这里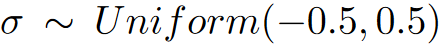
因此,噪声可能具有和量化误差相同的幅值。论文发现,人工噪声对性能的影响很大,最后,论文做 k k k位梯度量化的表达式如下:
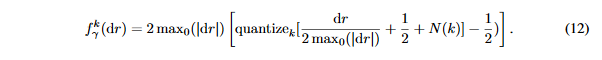
梯度的量化仅仅在反向传播时完成,因此每一个卷积层的输出上的STE是:
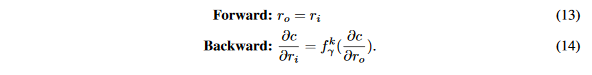
3.6 DoReFa-Net训练算法
论文给出了DoReFa-Net的训练算法,如Algorithm1所示。假设网络具有前馈线性拓扑,像BN层、池化层这样的细节在这里不详细展开。要注意的是,所有昂贵的操作如forward,backward_input,backward_weight(无论是卷积层还是全连接层),都是在低Bit上做的。通过构造,在这些低位宽数字和定点整数之间总是存在仿射映射的,因此,所有昂贵的操作都可以通过定点整数之间的点积等式(3)来加速。

3.7第一层和最后一层
在Han最近的工作中,当将网络的权重矩阵变为稀疏矩阵时,相同稀疏比例下,第一层卷积相比于其他卷积层对预测精度的影响更大。基于这样的直觉,同时观察到第一层的通道数很小,所以计算量占比很小,所以在接下来的实验中论文不量化第一个卷积层(除非有特别说明)。然而,第一层的输出是会被量化到低位宽的,因为它将作为下一层卷积的输入。
类似地,当网络的输出类别数目较小时,为了保证预测精度,我们通常不量化最后一个全连接层,但是最后一个全连接层的梯度是要被量化的。
3.8 通过融合非线性函数和round来减少运行时的内存占用
低位宽神经网络的一个重要动机就是节省推理时的运行内存占用,Algorithm 1的一个简单实现就是以全精度存储激活值 h a k h_{a_k} hak,将会在运行时占用大量内存。尤其地,如果 h h h涉及到浮点运算,那么非位操作的数量是不可忽视的。比如融合Step 3、Step 4、Step 6这三个步骤,融合Step 11、Step 12和Step 13都将可以节省中间变量需要的内存。这个和MergeBN可以类比。
4. 实验结果
4.1 配置空间搜索

4.2 在ImageNet的对比结果

4.3 训练曲线对比



4.4 量化第一层和最后一层会发生啥?

结论
这篇论文的主要目的是对训练流程进行加速,最大的改进点是对梯度也做了量化,算是BNN和Xor-Net的进一步改善,但是这篇论文也存在一个问题。我们可以在ImageNet上的实验看出,其精度要比XNOR-NET低,但从使用上来说,二者的内存占用和效率几乎无差别。所以这篇文章不能单独和XOR-Net来比,它的最大贡献就是梯度量化了,毕竟这为在算力不高的设备上提供神经网络的训练方式提供了一个新的方案。
附录
- 论文原文:https://arxiv.org/pdf/1606.06160.pdf
- 参考:https://blog.csdn.net/h__ang/article/details/100735692?utm_source=distribute.pc_relevant.none-task
推荐阅读
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
















 783
783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









