







LR(逻辑回归浅析)
我这里就简单缕缕LR的思路就好了。
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。
Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
1、 Logistic 分布
Logistic 分布是一种连续型的概率分布,其分布函数和密度函数分别为:
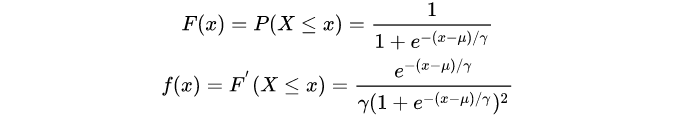
其中
μ
表示位置参数,
γ
>
0
\mu \text { 表示位置参数, } \gamma>0
μ 表示位置参数, γ>0
要是对sigmoid激活函数了解的同学相信一眼就看出来了,其实LR的分布函数(当 μ = 0 , γ = 1 \mu =0, \gamma=1 μ=0,γ=1)就是sigmoid,密度函数就是对上述的sigmoid求导。
2、考虑二分类问题,给定数据集
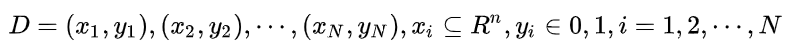
接下来就考虑怎么进行分类了。首先最容易想到的肯定是感知机算法了,来一个决策面把这堆数据分成两堆。但是这时候就有一个问题了,假如我们用
w
T
x
+
b
w^{T} x+b
wTx+b这个函数去拟合上面的数据点的话,
w
T
x
+
b
w^{T} x+b
wTx+b这个函数是连续的,但是我们的点是离散的,所以不能拟合。
那该怎么办呢,聪明的我们想到了条件概率 p ( Y = 1 ∣ x ) p(Y=1 | x) p(Y=1∣x),虽然我们的数据是离散的,但是条件概率一定是连续的啊。
但是问题又来了, w T x + b = R w^{T} x+b=R wTx+b=R其中R的取值不在[0,1]之间啊。没关系,sigmoid的取值范围不就是【0,1】呢。。。。终于这些小障碍清理干净了。
3、LR损失函数的建立
令
P
(
Y
=
1
∣
x
)
=
1
1
+
e
−
(
w
T
x
+
b
)
P(Y=1 | x)=\frac{1}{1+e^{-\left(w^{T} x+b\right)}}
P(Y=1∣x)=1+e−(wTx+b)1其中
w
T
x
+
b
w^{T} x+b
wTx+b就是我们拟合后的输入,真正的输入是x。再令
y
=
1
1
+
e
−
(
w
T
x
+
b
)
那
么
ln
y
1
−
y
=
w
T
x
+
b
\begin{array}{c}y=\frac{1}{1+e^{-\left(w^{T} x+b\right)}} 那么 \ln \frac{y}{1-y}=w^{T} x+b\end{array}
y=1+e−(wTx+b)1那么ln1−yy=wTx+b
将 y 视为类后验概率估计,重写公式有:
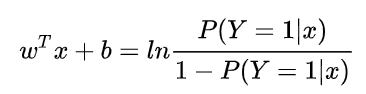
因此逻辑回归的思路是,先拟合决策边界(不局限于线性,还可以是多项式),再建立这个边界与分类的概率联系,从而得到了二分类情况下的概率。
4、求解损失函数
按照求解似然函数的一般方法去求解:
设:
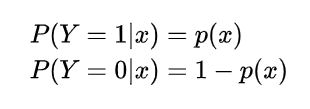
似然函数:
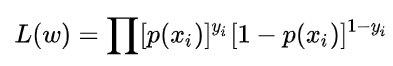
(不知道你们有没有发现,这里的似然函数形式跟我们经常见的有点不同哎,上面的指数项是怎么来的呢?后来想想明白了,上面的指数项其实就是二分类的值啊!!!这一项必须有啊,不然怎么体现你是二分类呢?其实就是0,1分布的似然函数形式呗。)
再转化为对数形式:(留个伏笔,为什么要转化为对数形式呢?)
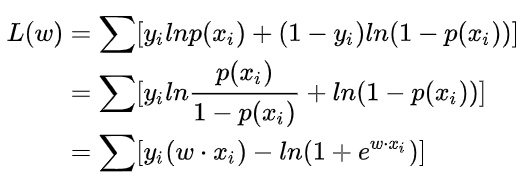
在机器学习中我们有损失函数的概念,其衡量的是模型预测错误的程度。如果取整个数据集上的平均对数似然损失,我们可以得到:
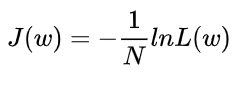
即在逻辑回归模型中,我们最大化似然函数和最小化损失函数实际上是等价的。
若选择用随机梯度下降来进行优化的话:
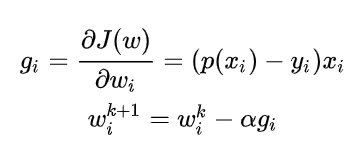
再加点正则化防止过拟合:
L1 正则化
LASSO 回归,相当于为模型添加了这样一个先验知识:w 服从零均值拉普拉斯分布。 首先看看拉普拉斯分布长什么样子:
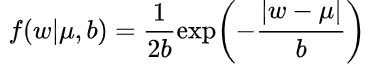
由于引入了先验知识,所以似然函数这样写:
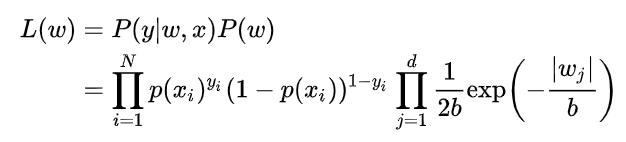
取 log 再取负,得到目标函数:
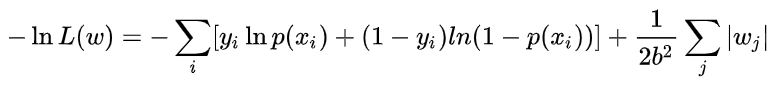
等价于原始损失函数的后面加上了 L1 正则,因此 L1 正则的本质其实是为模型增加了“模型参数服从零均值拉普拉斯分布”这一先验知识。
(看到这里明白为什么损失函数取对数了吧,本来正则是乘在原损失函数上面的,但是经过log作用以后就变成了加了,瞬间简化了不少不是吗?其实log的作用还有简化sigmoid函数求导的作用,因为sigmoid求导计算量很大)
L2类似,就不讲了,有想了解L1和L2的可以看这个链接















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









